【论文阅读】2019_Contiual learning with hypernetwork
1. 超网络简介
本文是使用超网络来实现继续学习(CL)的,超网络(hypernetwork)是谷歌在16年提出的一种网络,普通的网络是直接输出是我们想要的结果,而超网路的输出是另一个主网络B的权重,主网络B加载超网络学习到的权重之后,就能输出我们想要的结果了。通常超级网络的权重数是小于网络B的权重数量的,这就是体现了超网络的优点,约束了搜索权重的空间。
hypernetwork 这篇文章中使用超网络实现了 LSTM 和 CNN 网络的权重学习。动态超网络为循环网络生成权重,静态超网络为卷积网络生成权重。
超网络链接(谷歌的论文):hypernework: https://arxiv.org/abs/1609.09106
2. 论文的总体介绍
论文链接:使用超网络实现继续学习:https://arxiv.org/abs/1906.00695
论文的动机:使用超网络的思想来实现CL
论文的方案:
本文提出了一个任务条件超网络( task-conditioned hypernetworks),用于给给定任务id的主网络(主网络)B生成权重。
论文的贡献:
- 拓宽了超网络的应用领域,即使用超网络实现了CL。
- 基于超网络的CL方案不仅在标准CL基准上达到了最佳,而且在长序列任务学习上也表现很好(其他算法都没有在长序列实验上进行测试)
-
3. 相关的介绍
3.1. 一些数学符号
x
(
t
,
i
)
{x}^{(t,i)}
x(t,i):第
t
t
t 个任务的第
i
i
i 个输入数据;
y
(
t
,
i
)
{y}^{(t,i)}
y(t,i):第
t
t
t 个任务的第
i
i
i 个输入数据对应的标签;
X
(
t
)
=
{
x
(
t
,
i
)
}
i
=
1
n
t
{X}^{(t)}=\{x^{(t, i)}\}_{i=1}^{n_{t}}
X(t)={x(t,i)}i=1nt:第
t
t
t 个任务的输入数据是一个集合,由输入数据组成;
Y
(
t
)
=
{
y
(
t
,
i
)
}
i
=
1
n
t
{Y}^{(t)}=\{y^{(t, i)}\}_{i=1}^{n_{t}}
Y(t)={y(t,i)}i=1nt:第
t
t
t 个任务的标签数据是一个集合;
X
(
t
)
{X}^{(t)}
X(t):第
t
t
t 个任务的所有输入数据;
Y
(
t
)
{Y}^{(t)}
Y(t):第
t
t
t 个任务的输入数据对应的数据标签;
n
t
≡
∣
X
(
t
)
∣
n_{t} \equiv\left|{X}^{(t)}\right|
nt≡∣∣X(t)∣∣:第
t
t
t 个任务的数据的个数;
(
X
(
t
)
,
Y
(
t
)
)
({X}^{(t)}, {Y}^{(t)})
(X(t),Y(t)):第
i
i
i 任务提供的所有数据,即输入数据和输入数据对应的标签。
Y
^
(
t
)
\hat{Y}^{(t)}
Y^(t):使用模型(网络)
f
t
r
g
t
(
⋅
,
Θ
(
t
−
1
)
)
f_{trgt}(\cdot, \Theta^{(t-1)})
ftrgt(⋅,Θ(t−1)) 计算出的合成标签(synthetic targets);
Θ
(
t
−
1
)
\Theta(t-1)
Θ(t−1) 或
Θ
t
r
g
t
(
t
−
1
)
\Theta_{trgt}(t-1)
Θtrgt(t−1):在连续(sequentially)学习过程中,完成第
t
−
1
t-1
t−1 个任务之后,主网络(主模型)B的全部权重。
f
h
(
e
(
t
)
,
Θ
h
)
f_h(e^{(t)},\Theta_h)
fh(e(t),Θh):任务条件超网络(task-conditional hypernetwork),网络的输出是主网络B的权重
Θ
(
t
−
1
)
\Theta(t-1)
Θ(t−1) ;
e
(
t
)
e^{(t)}
e(t):嵌入式向量(embedding vectors),即任务条件超网路的输入;
Θ
h
\Theta_h
Θh:任务条件超网路的权重;
3.2. 继续学习从模型角度的理解
所谓的,继续学习就是在学习第
i
i
i 个任务时,不能使用前面的
t
−
1
{t-1}
t−1 个任务(之前任务)的数据,只使用前面的
t
−
1
{t-1}
t−1 个任务(之前任务)学习到的
Θ
(
t
−
1
)
\Theta(t-1)
Θ(t−1) 和第
t
t
t 个任务(当前任务)的数据来得到
Θ
(
t
)
\Theta(t)
Θ(t) 。要求这个
Θ
(
t
)
\Theta(t)
Θ(t) 使网络在第
t
t
t 个任务和前面
t
−
1
t-1
t−1 个任务上都要输出理想的结果。
4. 论文将超网络继续学习模型分成三个部分
4.1. 任务条件超网络(task-conditioned hypernetworks)
网络功能:输入一个嵌入向量(embedding vectors),则任务条件超网络就能输出目标网络B的权重。即任务条件超网络是目标网络B的权重生成器。
图:下图是使用超网路实现 CL 的过程,正则化后的超网络生成目标网络B的权重参数。

loss的定义和计算过程:
用超网络实现CL和普通的CL方案一样,既需要修改权重让网络学会新的任务,也要保证修改权重的网络不能忘记旧的任务。
作者采用两步优化的方法来实现对超网络输出的约束。
第一步:初步计算
Θ
h
\Theta_{h}
Θh 的改变量。只考虑当前任务
T
T
T,使用 Adam 优化器来计算出权重的修改量
Δ
Θ
h
\Delta \Theta_{h}
ΔΘh,计算公式如下:
L
t
a
s
k
(
T
)
=
L
t
a
s
k
(
Θ
h
,
e
(
T
)
,
X
(
T
)
,
Y
(
T
)
)
\mathcal{L}_{\mathrm{task}}^{(T)}=\mathcal{L}_{\mathrm{task}}\left(\Theta_{\mathrm{h}}, \mathbf{e}^{(T)}, \mathbf{X}^{(T)}, \mathbf{Y}^{(T)}\right)
Ltask(T)=Ltask(Θh,e(T),X(T),Y(T))
注释:
L
t
a
s
k
(
T
)
\mathcal{L}_{\mathrm{task}}^{(T)}
Ltask(T):对当前任务
T
T
T 进行学习。
第二步:计算实际
Θ
h
\Theta_{h}
Θh 的改变量。这个时候就需要添加对之前
T
−
1
T-1
T−1 个任务的约束。
L
total
=
L
t
a
s
k
(
T
)
+
L
output
=
L
t
a
s
k
(
T
)
+
L
output
(
Θ
h
∗
,
Θ
h
,
Δ
Θ
h
,
{
e
(
t
)
}
)
=
L
task
(
Θ
h
,
e
(
T
)
,
X
(
T
)
,
Y
(
T
)
)
+
L
output
(
Θ
h
∗
,
Θ
h
,
Δ
Θ
h
,
{
e
(
t
)
}
)
=
L
task
(
Θ
h
,
e
(
T
)
,
X
(
T
)
,
Y
(
T
)
)
+
β
output
T
−
1
∑
t
=
1
T
−
1
∥
f
h
(
e
(
t
)
,
Θ
h
∗
)
−
f
h
(
e
(
t
)
,
Θ
h
+
Δ
Θ
h
)
)
∥
2
\begin{aligned} \mathcal{L}_{\text {total }} &=\mathcal{L}_{\mathrm{task}}^{(T)}+\mathcal{L}_\text {output }\\ &=\mathcal{L}_{\mathrm{task}}^{(T)}+\mathcal{L}_{\text {output }}\left(\Theta_{\mathrm{h}}^{*}, \Theta_{\mathrm{h}}, \Delta \Theta_{\mathrm{h}},\{\mathbf{e}^{(t)}\}\right) \\ &=\mathcal{L}_{\text {task }}\left(\Theta_{\mathrm{h}}, \mathbf{e}^{(T)}, \mathbf{X}^{(T)}, \mathbf{Y}^{(T)}\right)+\mathcal{L}_{\text {output }}\left(\Theta_{\mathrm{h}}^{*}, \Theta_{\mathrm{h}}, \Delta \Theta_{\mathrm{h}},\left\{\mathbf{e}^{(t)}\right\}\right) \\ &\left.=\mathcal{L}_{\text {task }}\left(\Theta_{\mathrm{h}}, \mathbf{e}^{(T)}, \mathbf{X}^{(T)}, \mathbf{Y}^{(T)}\right)+\frac{\beta_{\text {output }}}{T-1} \sum_{t=1}^{T-1} \| f_{\mathrm{h}}\left(\mathbf{e}^{(t)}, \Theta_{\mathrm{h}}^{*}\right)-f_{\mathrm{h}}\left(\mathbf{e}^{(t)}, \Theta_{\mathrm{h}}+\Delta \Theta_{\mathrm{h}}\right)\right)\|^{2} \end{aligned}
Ltotal =Ltask(T)+Loutput =Ltask(T)+Loutput (Θh∗,Θh,ΔΘh,{e(t)})=Ltask (Θh,e(T),X(T),Y(T))+Loutput (Θh∗,Θh,ΔΘh,{e(t)})=Ltask (Θh,e(T),X(T),Y(T))+T−1βoutput t=1∑T−1∥fh(e(t),Θh∗)−fh(e(t),Θh+ΔΘh))∥2
符号注释:
e
(
T
)
e^{(T)}
e(T):当前任务
T
T
T 的嵌入向量,这个嵌入向量和
Θ
h
\Theta_h
Θh 一样,是可以被学习的。
{
e
(
t
)
}
\{e^{(t)}\}
{e(t)}:所有的任务的嵌入向量的集合;
Θ
h
∗
\Theta_h^*
Θh∗:学习任务
T
T
T 之前的超网路B的参数;
Δ
Θ
h
\Delta\Theta_h
ΔΘh:在第一步中计算出的权重改变量;在第二步的时可以看成是固定不变的量;
β
o
u
t
p
u
t
\beta_{output}
βoutput:超参数,用于调节正则化的强度;
L
output
\mathcal{L}_\text {output }
Loutput :添加这一项的原因是希望,更新后的权重
Θ
h
+
Δ
Θ
h
\Theta_h+\Delta\Theta_h
Θh+ΔΘh 与未更新前(学习前
T
−
1
T-1
T−1 个任务之后)的权重
Θ
h
∗
\Theta_h^*
Θh∗ 在前面的
T
−
1
T-1
T−1 个任务上的输出结果尽可能的保持一致(通过最小化
L
output
\mathcal{L}_\text {output }
Loutput 实现)。
L
t
a
s
k
(
T
)
+
L
output
\mathcal{L}_{\mathrm{task}}^{(T)}+\mathcal{L}_\text {output }
Ltask(T)+Loutput :第一项保证对新任务
T
T
T 的学习能力,第二项保证对之前面
T
−
1
T-1
T−1 个任务的记忆能力。
4.2. 分块的超网络(chunked hypernetwork)进行模型压缩
模型说明:一个任务需要的所有权重可以通过多个分块超网络来生成,每一步只需分块网络生成目标网络B种的部分权重,在同一个任务
t
t
t 中的不同块使用同一个嵌入向量
e
(
t
)
e^{(t)}
e(t) 和不同的
c
(
i
)
c^{(i)}
c(i) 生成全部的权重。
使用分块超网络的目标:使用较小的的可重复使用的分块超网络生成大网络的所有参数,即实现模型压缩。
图:下图是分块的超网络模型。
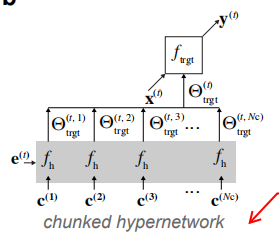
符号注释:
e
(
t
)
e^{(t)}
e(t):任务
t
t
t 的任务嵌入向量;
C
=
{
c
i
}
i
=
1
N
c
C=\{c_i\}^{N_c}_{i=1}
C={ci}i=1Nc:分块模型需要的分块嵌入向量的集合 ;
N
c
Nc
Nc:一个任务中的分块嵌入向量的数量;
f
h
f_h
fh:一个任务的超网络;
Θ
t
r
g
t
(
t
,
i
)
=
f
h
(
e
(
t
)
,
c
(
i
)
)
\Theta^{(t,i)}_{trgt}=f_h(e^{(t)},c^{(i)})
Θtrgt(t,i)=fh(e(t),c(i)):分块超网络通过一个任务嵌入向量
e
(
t
)
e^{(t)}
e(t) 和一个分块嵌入向量
c
(
i
)
c^{(i)}
c(i) 生成的目标网络B的第
i
i
i 部分的参数;
Θ
t
r
g
t
(
t
)
=
[
Θ
t
r
g
t
(
t
,
1
)
,
Θ
t
r
g
t
(
t
,
2
)
,
.
.
.
,
Θ
t
r
g
t
(
t
,
N
c
)
]
\Theta^{(t)}_{trgt}=[\Theta^{(t,1)}_{trgt},\Theta^{(t,2)}_{trgt},...,\Theta^{(t,Nc)}_{trgt}]
Θtrgt(t)=[Θtrgt(t,1),Θtrgt(t,2),...,Θtrgt(t,Nc)]:由任务
t
t
t 的各个分块超级网络生成的权重组成;
4.3. 任务无关推理(context-free inference: unknown task identity):用于确定输入数据属于哪里一个任务id
在测试的时候,超网络需要使用任务嵌入向量
e
t
e^{t}
et 来生成目标网络的权重。当任务id给定时,就需要知道使用哪一个
e
t
e^{t}
et 来生成权重,当任务id不知道时,就需要使用一些方法来确定具体使用哪一个
e
t
e^{t}
et 来生成权重了。这里介绍了两种方法:
-
依赖于任务的预测不确定性(Task-dependent predictive uncertainty):在理想情况下神经网络会为没见过的数据产生平坦的高熵输出(即输入数据属于各类别的概率都相似),反之,为见过的数据产生带峰值的低熵输出(即输入数据属于各类别的概率中有一个值很大)。使用每一个嵌入向量来计算输入数据对应的输出的熵,计算出的熵值最小的那个嵌入向量对应的任务id,就是输入数据对应的任务id,这样便推断出了输入数据对应的任务id,这个方法叫 HNET+ENT。
-
(Hypernetwork-protected synthetic replay)
both synthetic replay and task-conditional metamodelling act in tandem to reduce forgetting.结合数据重放模型来提升指标。
在两种不同的设置中探索受超网络保护的重播。
首先,我们考虑一种极简主义的体系结构(HNET + R),其中超网络仅对重播模型(而非目标分类器)进行参数化。在这里,通过将当前数据与合成数据混合,可以消除目标网络中的遗忘。使用软目标方法生成先前任务的合成目标输出值,即通过在合成输入数据上学习新任务之前简单地评估目标函数。
第二(HNET + TIR),我们引入了辅助任务推理分类器,使用合成重放数据进行保护,并经过训练可以根据输入模式预测任务身份。这种架构需要额外的建模,但是当任务非常不同时,它可能会很好地工作。此外,任务推断子系统可以容易地应用于处理当前输入模式之外的更一般形式的上下文信息。我们在附录B和C中提供了更多详细信息,包括网络体系结构和优化的丢失功能。
5. 实验结果
做这个最后在 MNIST、CIFAR-10 和 CIFAR-100 开源数据集上进行测试,都表现出了网络具有连续学习的能力。
详细的实验结果和代码分析将在后面的文章中说明。
6. 相关链接
6.1. 论文链接:
论文链接:使用超网络实现继续学习_论文:https://arxiv.org/abs/1906.00695
6.2. 论文的代码链接:
代码链接:使用超网络实现继续学习_代码:https://github.com/chrhenning/hypercl
完