MixFormer: End-to-End Tracking with Iterative Mixed Attention
动机:
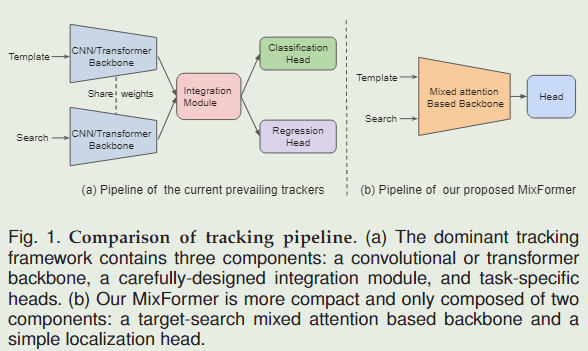
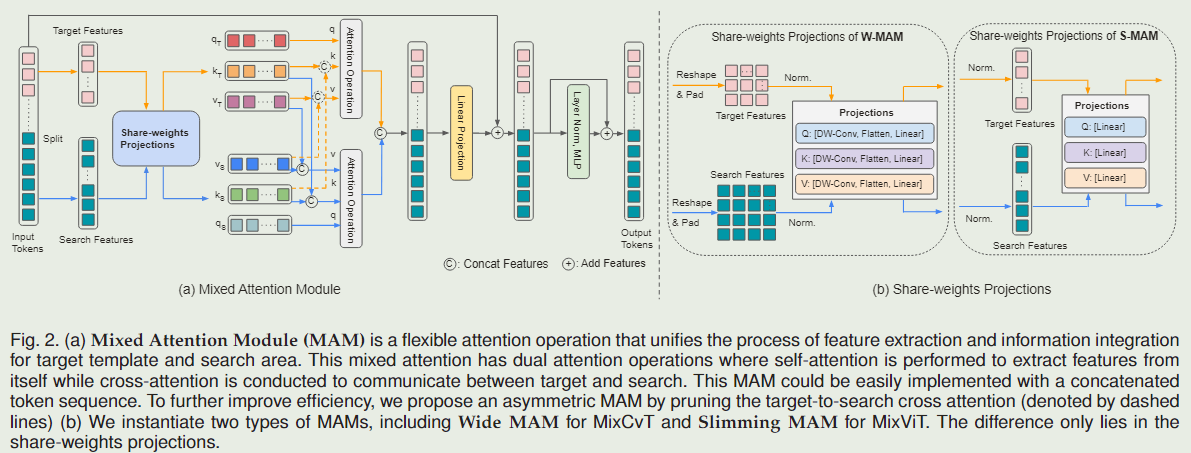
视觉对象跟踪通常采用特征提取、目标信息集成和边界框估计的多阶段管道。为了简化这一流程,并统一特征提取和目标信息集成的过程,本文提出了一种基于转换器的紧凑跟踪框架MixFormer。我们的核心设计是利用注意力操作的灵活性,并提出一种混合注意力模块(MAM)来同时进行特征提取和目标信息整合。这种同步建模方案允许提取特定于目标的区分特征,并在目标和搜索区域之间进行广泛的通信。基于 MAM,我们只需通过堆叠多个 MAM 并将定位头放在顶部来构建我们的 MixFormer跟踪器。
从形式上看,给定一个多个目标和搜索的串联标记,我们首先将其分成两部分,并将其重塑为2D特征图。为了实现局部空间上下文的额外建模,在每个特征图(即查询、键和值)上执行可分离的深度卷积投影层。它还允许在键和值矩阵中进行下采样,从而提高了效率。然后目标和搜索的每个特征图都被线性投影展平和处理以产生注意力操作的查询、键和值。我们用
q
t
q_t
qt、
k
t
k_t
kt和
v
t
v_t
vt表示目标,用
q
s
q_s
qs、
k
s
k_s
ks和
v
s
v_s
vs表示搜索区域。混合注意定义为:
k
m
=
Concat
(
k
t
,
k
s
)
,
v
m
=
Concat
(
v
t
,
v
s
)
,
Attention
t
=
Softmax
(
q
t
k
m
T
d
)
v
m
,
Attention
s
=
Softmax
(
q
s
k
m
T
d
)
v
m
,
\begin{array}{l}k_m=\operatorname{Concat}\left(k_t, k_s\right), \quad v_m=\operatorname{Concat}\left(v_t, v_s\right), \\ \operatorname{Attention}_{\mathrm{t}}=\operatorname{Softmax}\left(\frac{q_t k_m^T}{\sqrt{d}}\right) v_m, \\ \operatorname{ Attention }_s=\operatorname{Softmax}\left(\frac{q_s k_m^T}{\sqrt{d}}\right) v_m,\end{array}
km=Concat(kt,ks),vm=Concat(vt,vs),Attentiont=Softmax(dqtkmT)vm,Attentions=Softmax(dqskmT)vm, 其中
d
d
d表示键的维度,
Attention
t
\operatorname{ Attention }_t
Attentiont和分
Attention
s
\operatorname{ Attention }_s
Attentions别是目标和搜索的注意图。它包含自我注意和交叉注意,统一了特征提取和信息集成。然后将目标标记和搜索标记连接起来,通过线性投影进行处理。最后,通过层归一化和MLP函数处理连接的标记序列,如图2所示。
Slimming Mixed Attention Module (S-MAM)
虽然W-MAM通过在Vanilla变换(即深度卷积投影)中引入平移等变先验(即深度卷积投影)来产生强视觉表示,但它也存在一些问题。首先,由于每个关注元素(即查询、关键字和值)的重塑运算和深度卷积运算,导致跟踪速度较慢。此外,它缺乏适应最近 ViT 开发的灵活性,例如简单的掩码预训练。为了解决这些问题,我们通过去除 W-MAM 中的深度卷积投影来进一步呈现 Slimming Mixed Attention Module (S-MAM)。S-MAM的详细结构如图2所示。
直观地说,从目标查询到搜索区域的交叉注意并不那么重要,并且可能会因为潜在的干扰而带来负面影响。为了减少MAM的计算开销,从而有效地使用多个模板来处理对象变形,我们进一步提出了一种定制的非对称混合注意方案,通过剪枝不必要的目标到搜索区域的交叉注意。这种不对称混合注意的定义如下:
Attention
t
=
Softmax
(
q
t
k
t
T
d
)
v
t
Attention
s
=
Softmax
(
q
s
k
m
T
d
)
v
m
\begin{array}{l} \operatorname { Attention }_{\mathrm{t}}=\operatorname{Softmax}\left(\frac{q_t k_t^T}{\sqrt{d}}\right) v_t \\ \operatorname { Attention }_s=\operatorname{Softmax}\left(\frac{q_s k_m^T}{\sqrt{d}}\right) v_m \end{array}
Attentiont=Softmax(dqtktT)vtAttentions=Softmax(dqskmT)vm 每个MAM中的模板令牌在跟踪过程中可以保持不变,因此只需要处理一次。
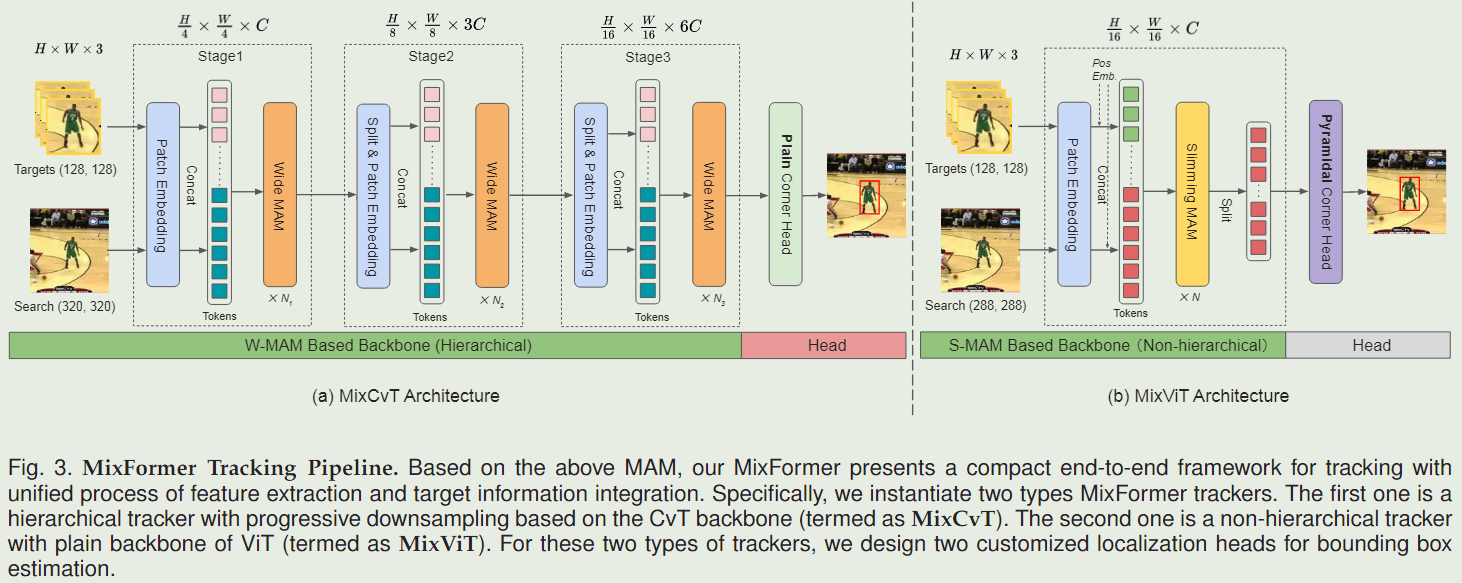
我们的目标是在统一的基于Transformer的架构中将通用特征提取和目标信息集成结合起来。基于 W-MAM 的主干采用渐进式多阶段架构设计。每个阶段由 N个MAM 层组成,这些层在具有相同通道数的相同比例特征图上操作。所有阶段都有类似的结构,由一个重叠的补丁嵌入层和
N
i
N_i
Ni宽的混合注意力模块组成。
具体来说,给定大小为
T
×
H
t
×
W
t
×
3
T×H_t×W_t×3
T×Ht×Wt×3 的
T
T
T个模板(即第一个模板和T−1个在线模板)和大小为
H
s
×
W
s
×
3
H_s×W_s×3
Hs×Ws×3的搜索区域(根据先前目标状态裁剪的区域),我们首先使用卷积标记嵌入层将它们映射为重叠的补丁嵌入,其步长为4,核大小为7。卷积令牌嵌入层在每个阶段都被引入,以便在降低空间分辨率的同时提高通道分辨率。然后我们展平补丁嵌入并将它们连接起来,得到一个大小为
(
T
×
H
t
4
×
W
t
4
+
H
s
4
×
W
s
4
)
×
C
\left(T \times \frac{H_t}{4} \times \frac{W_t}{4}+\frac{H_s}{4} \times \frac{W_s}{4}\right) \times C
(T×4Ht×4Wt+4Hs×4Ws)×C 的融合令牌序列,其中
C
C
C等于 64 或 192,
H
t
H_t
Ht和 $W_t
是
128
,
是 128,
是128,H_s$和
W
s
W_s
Ws是 320 。然后,串联后的令牌通过
N
i
N_i
Ni目标搜索MAM进行特征提取和目标信息融合。最后得到大小为
(
T
×
H
t
16
×
W
t
16
+
H
s
16
×
W
s
16
)
×
6
C
\left(T \times \frac{H_t}{16} \times \frac{W_t}{16}+\frac{H_s}{16} \times \frac{W_s}{16}\right) \times 6 C
(T×16Ht×16Wt+16Hs×16Ws)×6C 的令牌序列。在传递到预测头部之前,搜索标记被拆分并重塑为
H
s
16
×
W
s
16
×
6
C
\frac{H_s}{16} \times \frac{W_s}{16} \times 6 C
16Hs×16Ws×6C 的大小。特别是,我们不应用多尺度特征聚合策略。
首先,给定大小为$T×H_t×W_t×3
的
T
个模板和大小为
的 T 个模板和大小为
的T个模板和大小为H_s×W_s×3$ 的搜索区域,我们使用内核大小为16、跨度为16的卷积标记嵌入层将它们映射为非重叠的补丁嵌入。然后我们分别向搜索区域和模板补丁嵌入添加两个不同的位置嵌入。接下来,我们将模板(大小为
T
×
H
t
16
×
W
t
16
×
C
T×\frac{H_t}{16}×\frac{W_t}{16}×C
T×16Ht×16Wt×C)和搜索区域标记(大小为
H
s
16
×
W
s
16
×
C
\frac{H_s}{16}×\frac{W_s}{16}×C
16Hs×16Ws×C)连接起来,并将其输入到多个 Slimming 混合注意模块中。最后,分割的搜索区域令牌准备输入定位头。
Positional Embedding
在这项工作中,我们研究了三种类型的位置嵌入,对目标和搜索区域的位置建模进行了彻底的检查。我们对目标和搜索区域使用两个不同长度的位置嵌入。三种位置嵌入的区别在于初始化方法和是否可学习。对于第一类,我们采用二维双线性插值法从MAE预训练的VIT模型中内插预训练的位置嵌入。并且在训练过程中将嵌入设置为冻结。对于第二种类型,使用与第一种类型相同的初始化方法。然而,将嵌入设置为可学习,以实现动态调整。对于最后一个,我们使用 vanilla ViT 中采用的冻结 sin-cos 位置嵌入。
受掩模自编码器(mask autoencoder, MAE)预训练的巨大成功及其在目标检测中的应用的启发,我们也在MixViT中研究了MAE预训练。为了更好地研究监督预训练和自监督预训练在学习表征上的差异,我们通过改变ViT深度对预训练的效果进行了详细的研究。我们观察到监督预训练和 MAE 预训练的不同行为,其中有监督的预训练模型倾向于学习后期的高级语义表示,而 MAE 预训练模型似乎专注于沿所有层逐步学习低级信号结构。因此,在有监督的预训练模型中减少几层会导致很小的性能损失,因为后期的高层语义特征对目标跟踪的贡献很小。此外,我们通过借用MAE解码器的Transformer块,进一步增加了MAE预训练ViT的深度,并获得了进一步的性能提升。
受 MAE 预训练及其在训练样本上的数据效率的启发,我们想知道我们是否可以仅使用普通跟踪数据集预训练我们的 MixViT,而不使用大规模 ImageNet 数据集。首先,我们通过在跟踪数据集上直接预训练掩码自动编码器来设计一个简单的 MAE 基线,并使用这个预训练的 MAE 来初始化我们的 MixViT。具体来说,我们首先在跟踪数据集(包括 LaSOT、TrackingNet、GOT-10k 和 coco)上训练掩码自动编码器,然后在相同的跟踪数据集上微调 MixViT。除了数据集和数据增强之外,训练掩码自动编码器的主要过程与 MAE 保持一致。令人惊讶的是,我们观察到仅在跟踪数据集上具有自我监督预训练的 MixVT 大大优于从头开始训练。
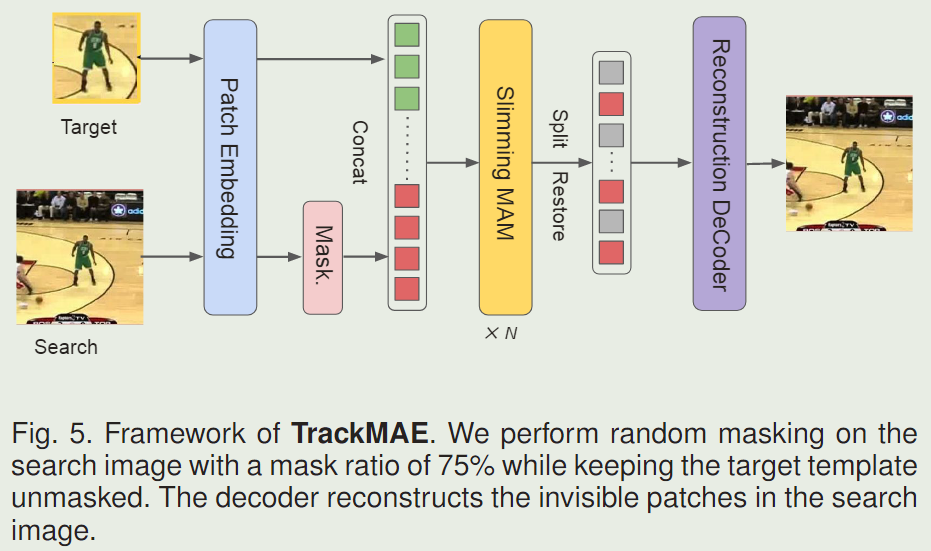
TrackMAE Pre-training on Tracking Datasets.
为了更好地将 MAE 预训练适应我们的 MixViT 跟踪器,我们提出了一种新的自监督预训练方法,用于视觉对象跟踪,称为 TrackMAE,如图 5 所示。
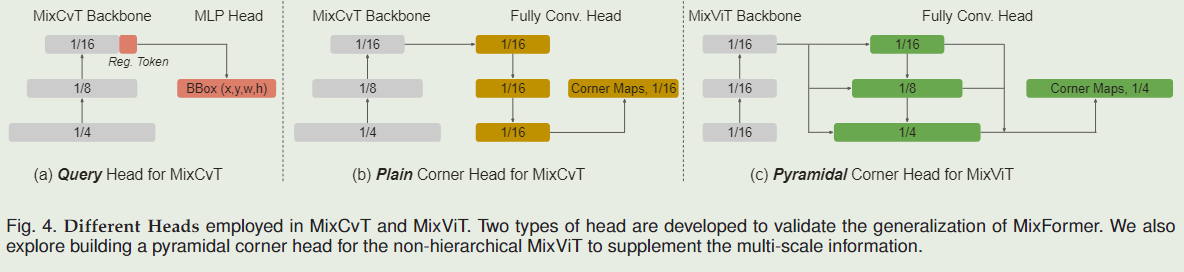
对于MixCvT训练,采用L1损失和GIoU损失的组合如下:
L
l
o
c
=
λ
L
1
L
1
(
B
i
,
B
i
^
)
+
λ
g
i
o
u
L
g
i
o
u
(
B
i
,
B
i
^
)
,
L_{loc} = λ_{L1}L_1(B_i, \hat{B_i}) + λ_{giou}L_{giou}(B_i, \hat{B_i}),
Lloc=λL1L1(Bi,Bi^)+λgiouLgiou(Bi,Bi^), 其中
λ
L
1
=
5
和
λ
g
i
o
u
=
2
λ_{L1} = 5 和 λ_{giou} = 2
λL1=5和λgiou=2 是两个损失的权重,
B
i
B_i
Bi是真实边界框,
B
i
^
\hat{B_i}
Bi^ 是目标的预测边界框。对于MixViT训练,我们将GIoU损失替换为CIoU损失[89]。
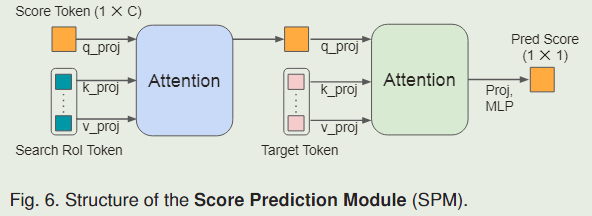
SPM由两个注意块和一个三层感知器组成。首先,可学习的分数标记作为查询来关注搜索 ROI 标记。它使分数标记能够对挖掘的目标信息进行编码。接下来,分数标记关注初始目标标记的所有位置,以将挖掘的目标与第一个目标隐式进行比较。最后,分数由 MLP 层和一个 sigmoid 激活产生。当其预测分数低于 0.5 时,在线模板被视为负数。对于 SPM 训练,它是在主干训练后执行的,我们使用标准的交叉熵损失:
L
s
c
o
r
e
=
y
i
l
o
g
(
p
i
)
+
(
1
−
y
i
)
l
o
g
(
1
−
p
i
)
,
L_{score} = y_ilog(p_i) + (1 − y_i)log(1 − p_i),
Lscore=yilog(pi)+(1−yi)log(1−pi), 其中
y
i
y_i
yi是真实标签,
p
i
p_i
pi是预测的置信度分数。