本文共1215个字,预计阅读时间需要4分钟。
最近有个上亿个关系/节点的数据需要导入到Neo4j,有以下几个工具可以导入:
- Cypher CREATE 语句,为每一条数据写一个CREATE
- Cypher LOAD CSV 语句,将数据转成CSV格式,通过LOAD CSV读取数据。
- 官方提供的Java API —— Batch Inserter
- Batch Import 工具
- neo4j-import 工具(Neo4j自带)
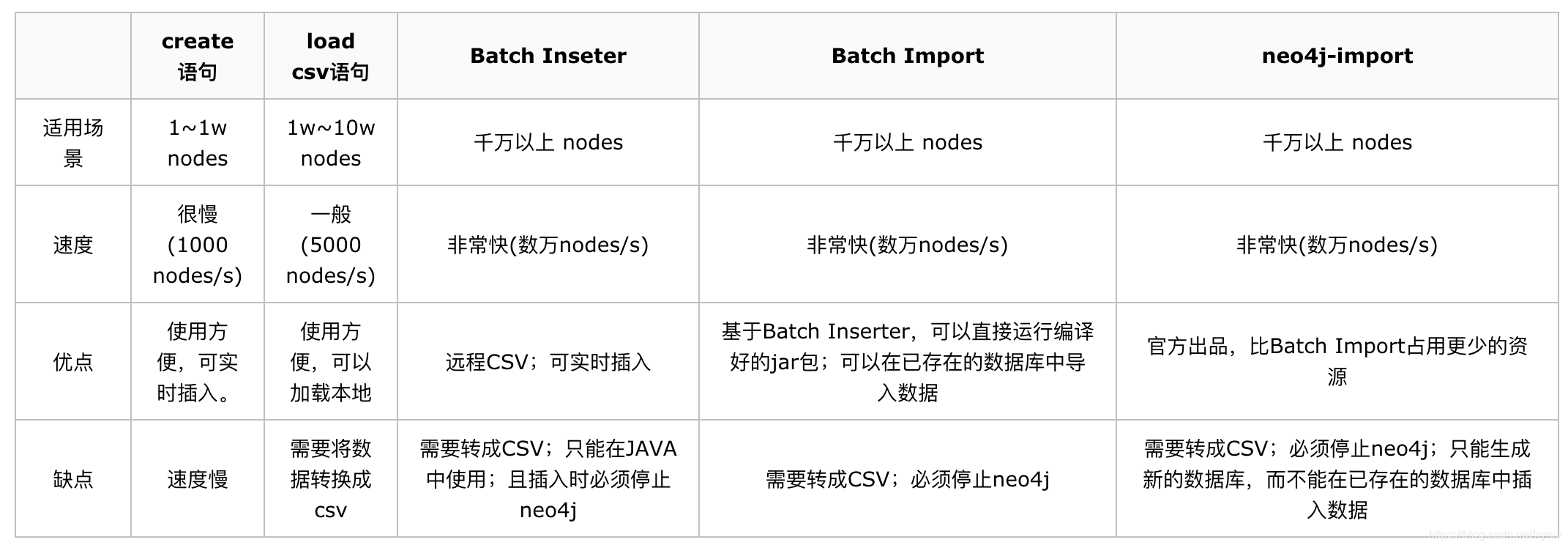
于是乎,毫不犹豫选择了最后一种。
Neo4j-import可用的参数命令:

遇到的坑
-
这个工具一般来说是放在Neo4j安装目录的bin文件夹下,也有可能在C盘用户的隐藏文件夹.Neo4jDesktop中的数据库文件下(比较隐蔽)
-
在CSV文件中需要提前编写好header,例如:
一般形式为名称:类型,用逗号分开,名称和类型必须要有一个,ID也是一个类型,它的名称可以忽略。包含的类型有:int、long、float、double、boolean、byte、short、char、string、point、date、localtime、time、localdatetime、datetime和duration中的一个来指定属性的数据类型。如果没有提供数据类型,则默认为string。若要定义数组类型,请将[]附加到该类型。

- 如果有多张实体表,他们可能有不同的ID,因此必须要在CSV文件中的头中增加名称空间,否则导入会报错。ID空间使用语法ID(<ID空间标识符>)在节点文件的ID字段中定义。要在关系文件中引用ID空间的ID,我们使用语法START_ID(<ID空间标识符>)和END_ID(<ID空间标识符>)。
例如我有两张表需要导入,需要在ID后面指定实体的名称空间。
- movieId:ID(Movie-ID),title,year:int,:LABEL
- personId:ID(Actor-ID),name,:LABEL
4.如果出现下面的问题:
Neo4j批量导入“neo4j-admin导入”OutOfMemoryError:Java堆空间和OutOfMemoryError:超出GC开销限制(Neo4j bulk import “neo4j-admin import” OutOfMemoryError: Java heap space and OutOfMemoryError: GC overhead limit exceeded)
说明分配的内存不够了,需要修改neo4j.conf的配置,这个文件可以从neo4j-import的上级文件夹中的某个子文件夹找到。
需要修改两个值
- dbms.memory.heap.initial_size=4096m
- dbms.memory.heap.max_size=16384m
最后我的电脑卡在了出现的第四个问题上,没办法电脑内存不够,于是我选择了使用CYPHER的LOAD语句导入CSV,可以采用USING periodic commit 10000这样的语法提高导入效率。
更多内容访问 omegaxyz.com
网站所有代码采用Apache 2.0授权
网站文章采用知识共享许可协议BY-NC-SA4.0授权
© 2020-2025 • OmegaXYZ-版权所有 转载请注明出处
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)