简介
有时候我们想看看自己跟另一个人的时长、频率、时间等或者是聊天过程中谁更在乎谁多一点,谁是话痨,聊天性格怎么样,这时就需要一个聊天记录分析的程序。
下面的Python代码能够统计聊天记录中的时间、消息次数、文本长度、词频等信息。
当然有一些小bug,这将在将来的更新中得到修复。
原文:omegaxyz.com
使用到的Python模块
①jieba:结巴分词,用来处理聊天记录中的文本,尤其是中文文本。
②matplotlib.pyplot:用来画折线图、条形图等。
③matplotlib.*.PdfPages:用来将数据及结果生成PDF文件。
④xlwt:将词频信息写到xls中。
注意点
①QQ中的聊天记录文件的昵称是每一阶段的昵称(时间不同昵称可能不同)。
②聊天文件中的字符一定要使用utf-8编码。
③利用matplotlib画图时中文字体一定要导入到当前文件夹下(Windows系统C盘下面有字体)
QQ聊天记录的导出
环境:截止到2018年7月最新的QQ
①选择消息管理器
②导出消息记录
③保存为txt文件
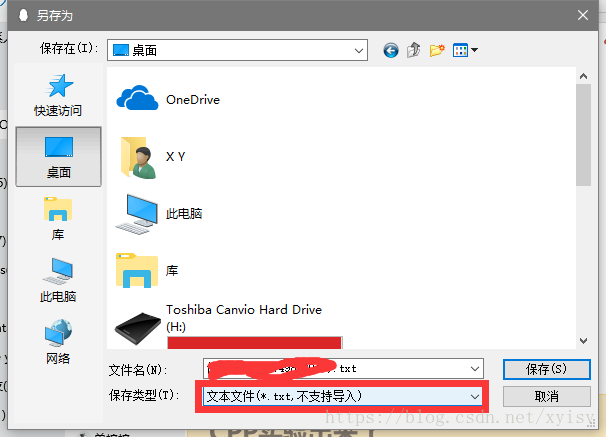
注意导出后放到代码目录下即可
代码主要步骤
①变量初始化
②读取QQ聊天记录txt文件
③利用结巴模块对聊天记录进行分析
④利用matplotlib画图并导出成PDF文件
核心代码
代码有bug:
①非utf-8编码问题导致数据无法加载(使用过颜表情的记录会出现,这里需要手动清除)
②词频统计中文与英文混乱(小bug,不影响使用)
因此只给出核心代码,修复后所有代码将在未来上传至github
获取最新信息请持续关注或在首页订阅omegaxyz.com
import jieba
import re
import jieba.analyse
import xlwt
from matplotlib import font_manager
import matplotlib as mpl
import matplotlib.pyplot as plt
from matplotlib.backends.backend_pdf import PdfPages
myfont = font_manager.FontProperties(fname='simhei.ttf')
mpl.rcParams['axes.unicode_minus'] = False
f = open("qk.txt", "r")
message = f.readlines()
name1 = 'PuzzleX'
name1_message = []
name2 = '输入另一个人的昵称'
name2_message = []
name1_word_count = 0
name2_word_count = 0
name1_time = []
name2_time = []
wbk = xlwt.Workbook(encoding='ascii')
sheet = wbk.add_sheet("message")
word_lst = []
key_list = []
pat = re.compile(r'(\d{4}-\d{1,2}-\d{1,2})')
pdf = PdfPages(name1 + '与' + 'DEMO' + '聊天记录分析' + '.pdf')
for line in message:
try:
item = line.strip('\n\r').split('\t')
tags = jieba.analyse.extract_tags(item[0])
if pat.match(str(item[0])) and name1 in str(item[0]):
name1_time.append(item)
elif pat.match(str(item[0])) and name2 in str(item[0]):
name2_time.append(item)
if (len(tags) == 7 or 6) and name1 in tags:
pass
elif (len(tags) == 7 or 6) and name2 in tags:
pass
else:
for t in tags:
word_lst.append(t)
except:
pass
word_dict = {}
with open("wordCount.txt", 'w') as wf2:
for item in word_lst:
if item not in word_dict:
word_dict[item] = 1
else:
word_dict[item] += 1
orderList = list(word_dict.values())
orderList.sort(reverse=True)
for i in range(len(orderList)):
for key in word_dict:
if word_dict[key] == orderList[i]:
wf2.write(key + ' ' + str(word_dict[key]) + '\n')
key_list.append(key)
word_dict[key] = 0
for i in range(len(key_list)):
sheet.write(i, 1, label=orderList[i])
sheet.write(i, 0, label=key_list[i])
wbk.save('message.xls')
for i in range(len(message)):
if name1 in message[i]:
name1_message.append(message[i+1])
name1_word_count += len(message[i+1])
if name2 in message[i]:
name2_message.append(message[i+1])
name2_word_count += len(message[i + 1])
name1_count = len(name1_message)
name2_count = len(name2_message)
name1_time_do = {'0':0, '1':0, '2': 0, '3': 0, '4': 0, '5': 0, '6': 0, '7': 0, '8': 0, '9': 0, '10': 0, '11': 0,
'12': 0, '13': 0, '14': 0, '15': 0,'16': 0, '17': 0, '18': 0, '19': 0, '20': 0, '21': 0, '22': 0, '23': 0, }
name2_time_do = {'0':0, '1':0, '2': 0, '3': 0, '4': 0, '5': 0, '6': 0, '7': 0, '8': 0, '9': 0, '10': 0, '11': 0,
'12': 0, '13': 0, '14': 0, '15': 0, '16': 0, '17': 0, '18': 0, '19': 0, '20': 0, '21': 0, '22': 0, '23': 0, }
for item in name1_time:
try:
name1_time_do[str(item[0])[11:13]] += 1
except KeyError:
name1_time_do[str(item[0])[11:12]] += 1
for item in name2_time:
try:
name2_time_do[str(item[0])[11:13]] += 1
except KeyError:
name2_time_do[str(item[0])[11:12]] += 1
time_range = name1_time[0][0][:11] + '到' + name1_time[-1][0][:11]
plt.figure()
plt.axis('off')
t = name1 + '与' + 'DEMO' + '的聊天记录分析' + '\nomegaxyz.com\n\n' + name1 + '的消息发送次数为: ' + str(name1_count) + '\n' + 'DEMO' + \
'的消息发送次数为: ' + str(name2_count) + '\n' + name1 + '的消息发送消息字数为: ' + str(name1_word_count) + '\n' + 'DEMO' + \
'的消息发送消息字数为: ' + str(name2_word_count) + '\n\n' + time_range + '\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n'
plt.text(0, 0, t, ha='left', wrap=True, fontproperties=myfont)
pdf.savefig()
plt.close()
word_T1 = ' 聊天词频分析\n'
for i in range(25):
word_T1 += key_list[i]
word_T1 += ':'
word_T1 += str(orderList[i]) + '\n'
plt.figure()
plt.axis('off')
plt.text(0, 0, word_T1, ha='left', wrap=True, fontproperties=myfont)
pdf.savefig()
plt.close()
word_T2 = ''
for i in range(25):
word_T2 += key_list[i+25]
word_T2 += ':'
word_T2 += str(orderList[i+25]) + '\n'
plt.figure()
plt.axis('off')
plt.text(0, 0, word_T2, ha='left', wrap=True, fontproperties=myfont)
pdf.savefig()
plt.close()
rects = plt.bar(range(len(orderList[0:11])), orderList[0:11], color='rgby')
index = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
plt.ylim(ymax=orderList[0]*1.1, ymin=0)
plt.xticks(index, key_list[0:11], fontproperties=myfont)
plt.ylabel("次数", fontproperties=myfont)
plt.title('聊天最多的词(包括表情和图片)', fontproperties=myfont)
for rect in rects:
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width() / 2, height, str(height), ha='center', va='bottom')
plt.savefig('Top10 words.jpg')
pdf.savefig()
plt.close()
plt.axis([0, 23, 0, 600])
plt.ion()
plt.plot(list(name1_time_do), list(name1_time_do.values()), color='red', label='User1')
plt.plot(list(name2_time_do), list(name2_time_do.values()), color='blue', label='User2')
plt.xlabel('时间(24小时制)', fontproperties=myfont)
plt.ylabel('频率', fontproperties=myfont)
plt.title('聊天时间分布', fontproperties=myfont)
plt.savefig('time frequency.jpg')
pdf.savefig()
plt.close()
pdf.close()
未来的工作
①修复bug ②GUI界面 ③利用机器学习算法推测聊天用户性格
测试
①主要信息

②词频
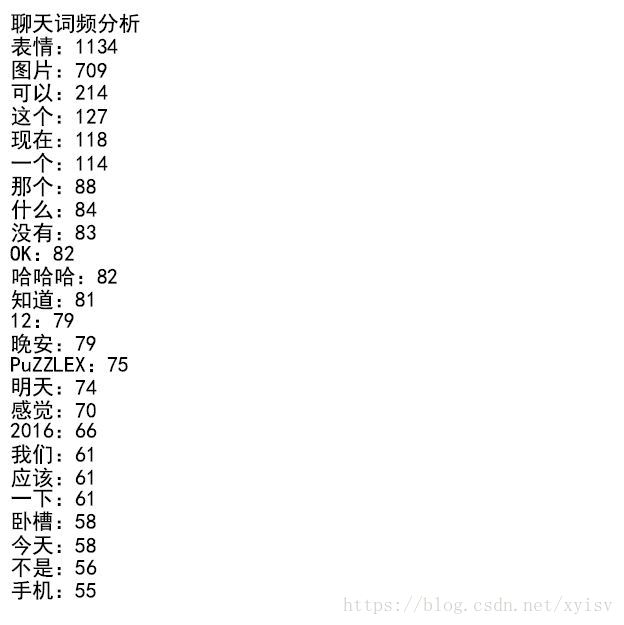
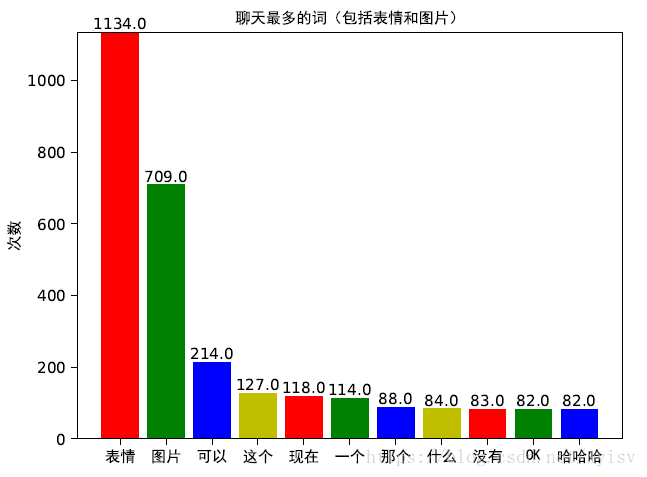
③聊天时间分布
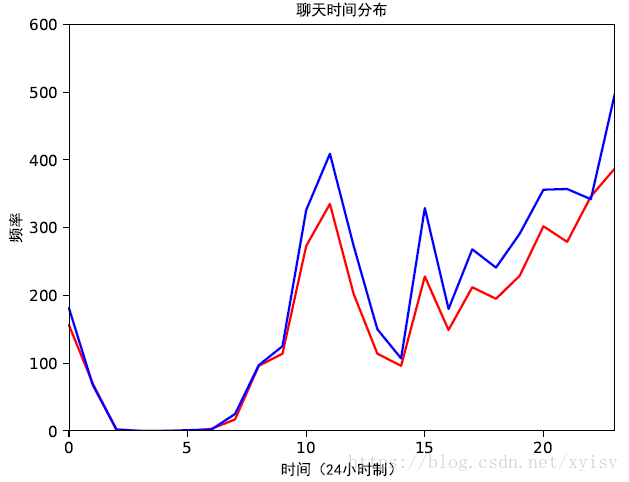
④导出的PDF文件

网站所有原创代码采用 Apache 2.0 授权
网站文章采用知识共享许可协议 BY-NC-SA4.0 授权
更多内容访问omegaxyz.com
网站所有代码采用Apache 2.0授权
网站文章采用知识共享许可协议BY-NC-SA4.0授权
© 2018 • OmegaXYZ-版权所有 转载请注明出处
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)