点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
作者:肖敏,朱军楠,林海涛,周玉,宗成庆
单位:中国科学院自动化研究所
邮箱:min.xiao@nlpr.ia.ac.cn
1.摘要
多模式摘要通常存在一个问题,即视觉模态的贡献不清晰。现有的多模式摘要方法主要关注不同模态的融合方法,而忽视了视觉模态在哪些条件下是有用的。因此,文章提出了一种新颖的多模态摘要的由粗到精的贡献网络(CFSum),以考虑图像对摘要的不同贡献。首先,为了消除无用图像的干扰,文章提出了一个预过滤模块来消除无用图像。其次,为了准确使用有用的图像,文章提出了两级视觉补充模块:词级别和短语级别。具体而言,计算图像的贡献并用于引导文本和视觉模态的注意力。实验结果表明,CFSum在标准数据集上明显优于多个强大的基线模型。此外,分析验证了有用的图像甚至可以帮助生成隐含在图像中的非视觉词汇。
2.方法
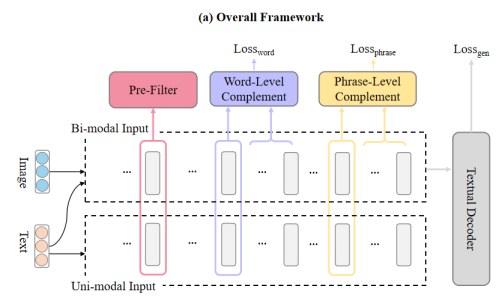
图1
2.1由粗到精的框架
模型基于多模式变换器UNITER和GRU编码器-解码器架构构建而成。文章将该模型称为UniG。如图1所示,为了评估不同模态的互补性,双模态和单模态输入与相同的编码器并行操作。这两个并行流可以捕捉图像的增益。此外,文章依靠双模态编码生成摘要。单模态编码用于测量不同贡献并引导双模态编码。具体来说,多模式编码器由L层组成,文章将这L层构建成一个分级结构,如图1所示。L_f, L_w, L_p分别标记为预过滤器、词级补充和短语级补充模块的起始层。现有研究假设所有图像都有助于摘要生成或输入文本编码,导致了不必要图像的干扰。预过滤模块用于预先消除误导性图像的干扰。接下来,词级别补充模块用于建模图像对摘要输入词的增益。然后,图像增益引导了单词和图像之间的后续注意力。同理,短语级补充模块集中在较高层的短语上。
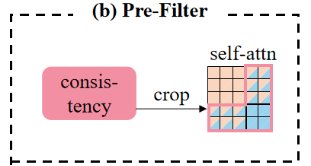
图2
2.2 预过滤模块
预过滤模块的目标是过滤掉对摘要不必要的图像。如图2所示,给定来自第L_f层的两个编码特征m^{L_f}和u^{L_f},过滤模块的目标是选择那些无用的图像并引导所有后续层的自注意力。文章认为,如果双模态特征与单模态特征的一致性较低,图像可能会引入干扰性信息。具体来说,文章首先计算单模态特征u^{L_f}和双模态特征m^{L_f}之间的一致性Δ^C,如下所示:
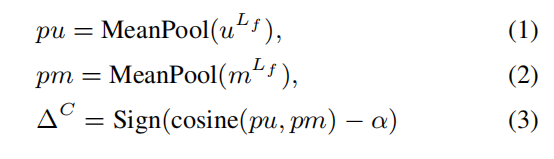
这个一致性值表示了文本关注图像、图像关注文本以及图像关注自身的情况。这里,为了方便修正自注意力,定义了一个索引函数:
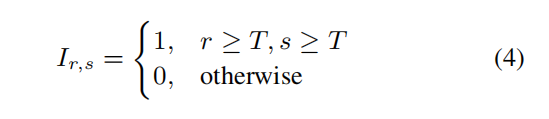
如图2所示,文章修正新的后续自注意力为na^i_{r,s},具体计算如下:
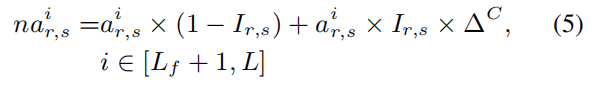
2.3词级别增益模块
图3
文章希望使用互信息来计算图像对摘要的增益。换句话说,文章想要衡量基于双模态特征m^L生成摘要是否比基于单模态特征u^L更加确定性。因此,文章期望计算参考摘要的第k个单词的图像增益:
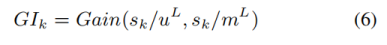
然而,文章打算在生成摘要S和编码m^L之前获得GI_k,从而GI可以有助于生成S和编码m^L。为此,文章定义了Copy 任务Y来近似摘要任务S:对于每个输入文本标记t_j,目标是二进制分类,即它是否出现在参考摘要中。如果标记出现在参考摘要中,则分类为\hat{y_j}=1;否则,\hat{y_j}=0。接下来,GI_j由以下公式给出:
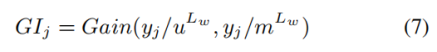
公式推导为:
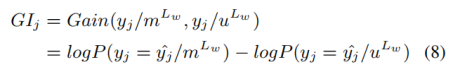
文章引入了KL散度损失来约束:具有更大增益的图像应该受到更多的文本关注度。在编码器第i∈[L_w+1,L_w+3]层中,每个文本标记t_j与图像之间的平均互关注是:
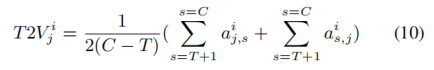
最后,添加了一个注意力散度损失来限制互关注得分T2V_j^i与GI_j之间的关系:
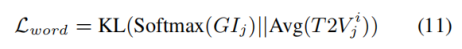
2.4 短语级别增益模块
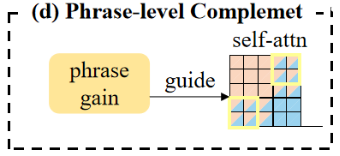
图4
同理于词级别增益模块,增益计算和增益指导attention矩阵的方式一样。区别在于1)计算增益时,为了获得短语级别增益,提出的近似任务为短语打分任务:输入短语中有多少词会出现在参考摘要中;2)增益指导时,利用增益指导attention矩阵中的短语和图片之间的关注度。
3.实验结果
在Multimodal Sentence Summarization数据集上做了实验,实验结果如表1:
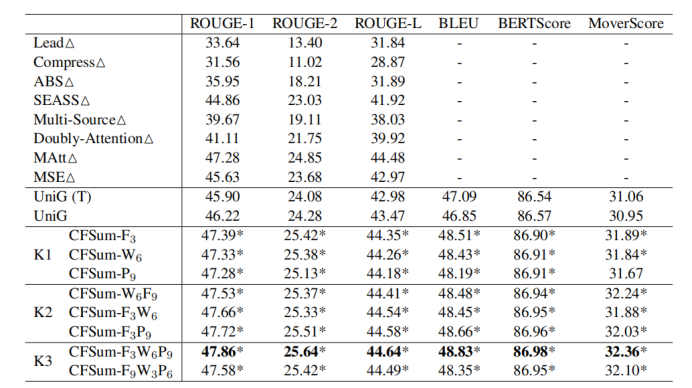
表1
其中,F表示pre-filter过滤模块,W表示词级别的增益模块,P表示短语级别的增益模块,它们各自的下标表示L_f, L_w, L_p 的设定值。K1表示只用一个贡献模块,K2表示用两个贡献模块,K3表示三个贡献模块全部用上。通过实验结果可以看出,用三个贡献模块的性能要优于两个贡献模块,优于一个贡献模块。证明了每一个贡献模块都是能够给模型带来性能提升的。
4.分析

图5
首先,这里文章希望可视化去看词级别增益和短语级别增益。如图5所示,输入一张图片和一段文本,红色框表示的是,将输入文本手动对齐到摘要中。不一定是一模一样的词,语义相似,或者单复数的词也被会对齐。蓝色实心点和橘色实心点表示是增益大于0的词。首先,可以发现,文章词级别和短语级别的增益,几乎可以覆盖所有的摘要内容。这证明了,文章提出的增益的确是可以帮助生成摘要的。另一方面,不同级别的模块会在不同的地方带来增益,不是完全重合的。这就证明了,文章多个增益模块比单个增益模块能带来更好的性能提升。

图6
另一方面,文章想关注图片会在哪些词上会带来增益。文章列举了三个受到增益的词(如图6所示),以及它们各自相关的图片,可以看到:比如earthquake这种可视化的词是能够带来增益的。更重要的是,像celebrate, sharply这些非可视化的词也可以被关注到。并且观察相关的图片,比如celebrate可以被用在比赛中,集会中,以及外交中。在其它多模态任务比如多模态翻译,字幕生成任务中,大多会关注把图片和earthquake这种可视化的词建立关联,但在多模态摘要中,图片也是能够为非可视化的词带来增益的。
5.结论
(1)文章提出了一个有粗到精的贡献多模态摘要网络,来建模图片对于摘要的不同贡献。并且这个模型在实验结果上被证明能够很大程度改善多模态摘要的性能。
(2)另一方面,进一步的分析证明了,在未来的工作中,非可视化的词和图片的联系也不容忽视,需要被建模。
Paper: https://aclanthology.org/2023.acl-long.476.pdf
Code: https://github.com/xiaomin418/CFSum
提
醒
点击“阅读原文”跳转至01:03:47,
即可查看回放
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1300多位海内外讲者,举办了逾600场活动,超600万人次观看。

我知道你
在看
哦
~

点击 阅读原文 查看回放!