前言
之前因为想研究怎么让esp8266上校园网,折腾半天,请教大佬后,说要先学爬虫,就能知道怎么模拟登录上网了。大佬学的是c#,我学的是python,于是就开始学习了python爬虫,这是学习中觉得好玩的事,也遇到了不少困难。
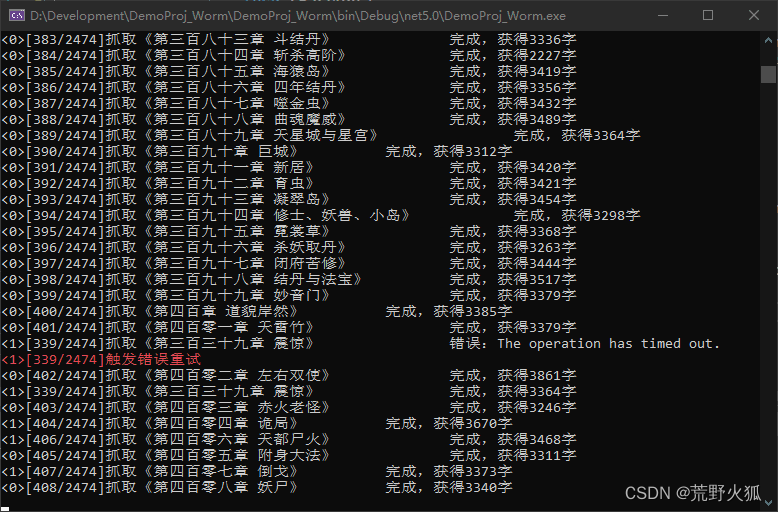
一、先上效果图
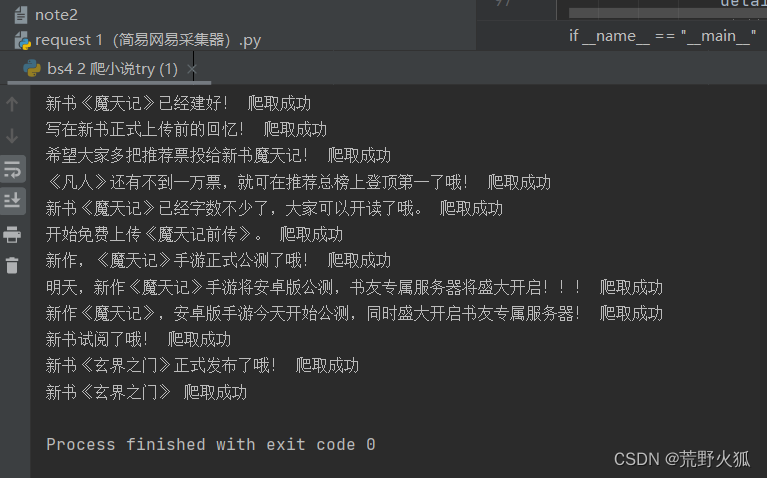
这本书一共两千四百多章,一开始基本上爬到第1章(前面还有广告恰饭章)就报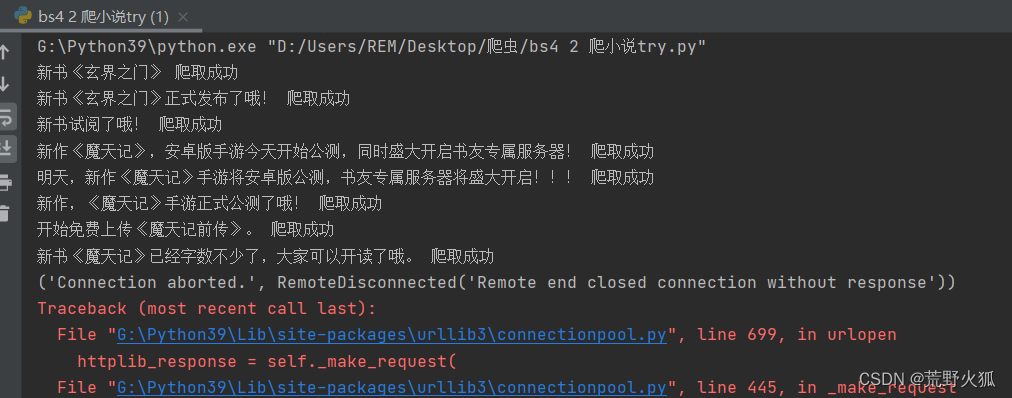
Remoto end closed connection without response 的错,估计被发现是爬虫了,弄了半天,总算爬取成功。
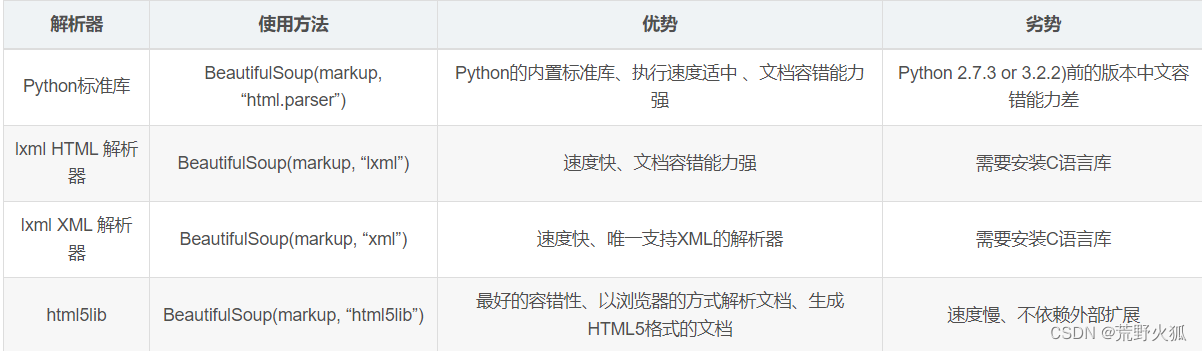
二、bs4学习
1.原理
bs4进行数据解析
bs4数据解析原理
1.实例化一个BeautifulSoup对象,并且将页面源码数据加载到该对象中
2.通过调用BeautifulSoup对象中相关的属性或者方法进行标签定位和数据解析
环境安装
# pip install bs4
# pip install lxml
#如何实例化BeautifulSoup对象
from bs4 import BeautifulSoup
2.运用
两种操作方式,我们一般用第二种爬取网页
from bs4 import BeautifulSoup
#1.将本地的html文档中的数据加载到对象中
fp = open("./baidu.html",'r',encoding='utf-8')
soup = BeautifulSoup(fp,'lxml')#创建一个lxml解析器
# print(soup)
#2.将互联网上获取的页面源码加载到该对象中
#page_text = response.text
#soup = BeatifulSoup(page_text,'lxml')
3.数据解析
#提供用于数据解析
#print(soup.a)#soup.tagName 返回的是html中第一次出现的tagName标签
#print(soup.div)
#print(soup.find('div')) #等同于soup,div
4.属性定位
#属性定位
#print(soup.find('div',class_= "head_wrapper"))
#print(soup.find_all('a'))# 返回符合要求的所有标签
#select select('某种选择器(id,class,标签,,,选择器)')
#print(soup.select('.head_wrapper'))
#print(soup.select(".head_wrapper > "))
#soup.select('.tang > ul > li > a')[0] #层级选择
#soup.select('.tang > ul a')[0] #跨层选择 空格表示多个层级
5. 获取标签之间的文本数据
#获取标签之间的文本数据
print(soup.select('a')[0].string) # 只可以获取该标签下面直系的文本内容
print(soup.select('a')[0].get_text())#text/get_text()可以获取某一个标签中所有的文本内容
print(soup.select('a')[0].text)
6.获取标签中的属性值
#获取标签中的属性值
#print(soup.select('.tang > ul > li > a')[0]['href'])
三、开始爬小说
一般步骤
聚焦爬虫 爬取页面中指定的页面内容
编码流程
指定URL
发起请求
获取响应数据
数据解析
持久化存储
在此之前,先要
pip instal requrests
import requrests
1、获取url
首先我选用笔趣阁的《凡人修仙传》作为爬取对象
url = 'https://www.qbiqu.com/7_7365/'
2 、UA伪装
然后,正常的ua伪装(User-Agent)用户代理,里面包含操作系统版本号和使用的浏览器,来伪装成一个正常的请求。按键盘上的F12 进入网站的开发者模式得到。(找不到可以尝试刷新页面)
#UA : User_Agent(请求载体的身份标识)
#UA检测 门户网站的服务器会检测对应请求的载体身份标识,如果监测到的载体身份标识为某一款浏览器
#说明该请求是一个正常的请求。但是如果检测到的载体身份标识不是基于某一款浏览器则表示该请求
#为不正常的请求(爬虫),则服务器就很可能拒绝该次请求
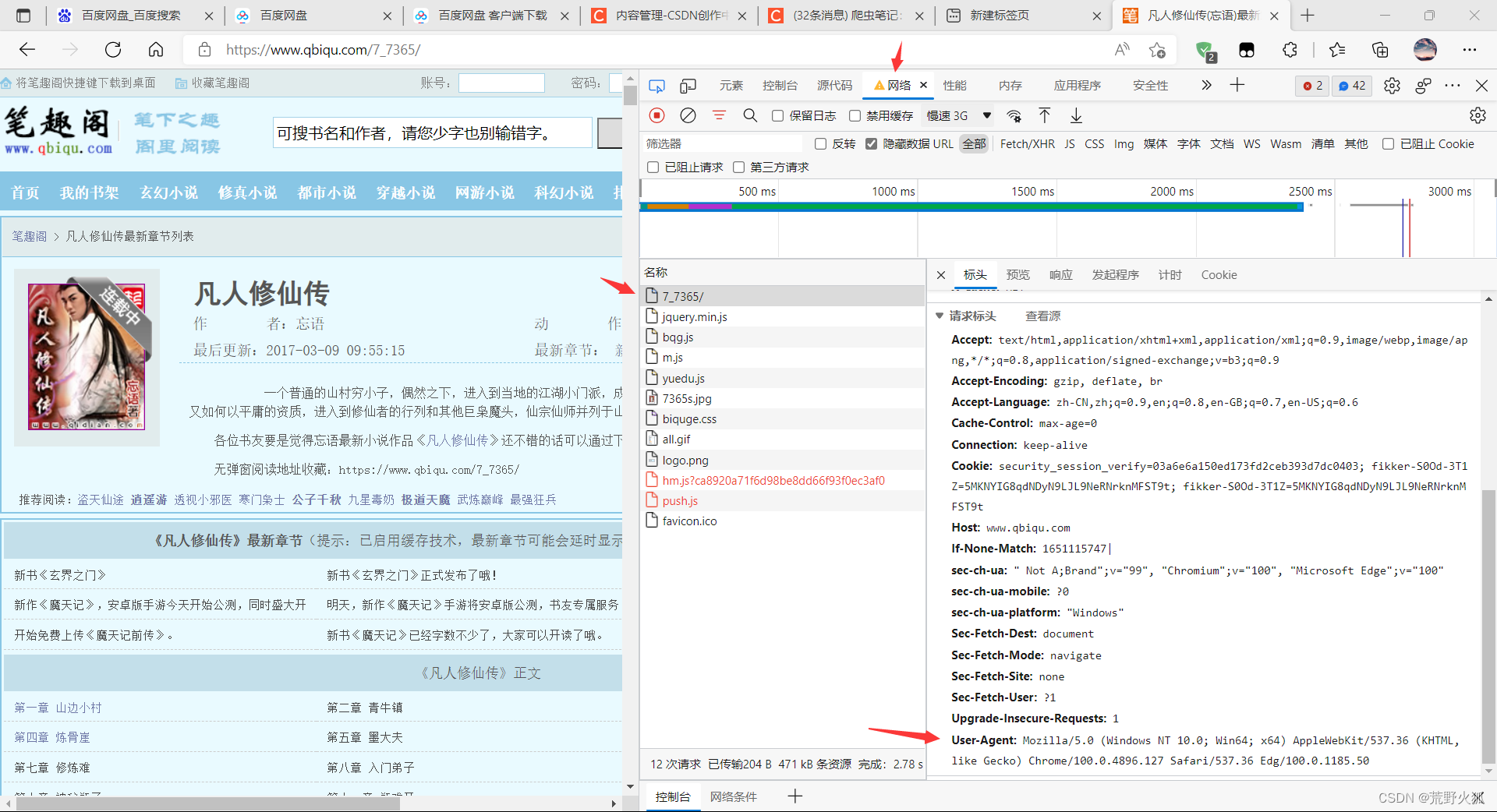
#UA伪装: 将对应的User-Agent封装到一个字典中
headers = {
"User-Agent":'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36 Edg/100.0.1185.44'
}
3、获取cookie
获取cookie
requests.session进行状态保持
requests模块中的Session类能够自动处理发送请求获取响应过程中产生的cookie,进而达到状态保持的目的。
# 创建一个session,作用会自动保存cookie
session = requests.session()
因为一直远程连接断开(Remoto end closed connection without response ),发现加上这句后,会好很多,用法和requests一样,requests.get();requrests.post();
4、请求网站
session.get(url,headers)
URL:Internet上的每一个网页都具有一个唯一的名称标识,通常称之为URL(Uniform Resource Locator, 统一资源定位器)。它是www的统一资源定位标志,简单地说URL就是web地址,俗称“网址”。
防止因为网络不好问题请求不到网站,我们使用while语句
while(1):
try:
page_text = session.get(url= url,headers= headers)
break
except Exception as e:
print(e)
time.sleep(2)
5、完美解决爬取中文数据乱码问题
后来遇到中文报错问题
page_text = page_text.text.encode('iso-8859-1').decode(’gbk‘)
暂时这样解决了,可后来爬到三百二十六章是报了一个gbk编码格式不能编码的错,debug了一下
把要编码的格式传给decode,就不写死了。
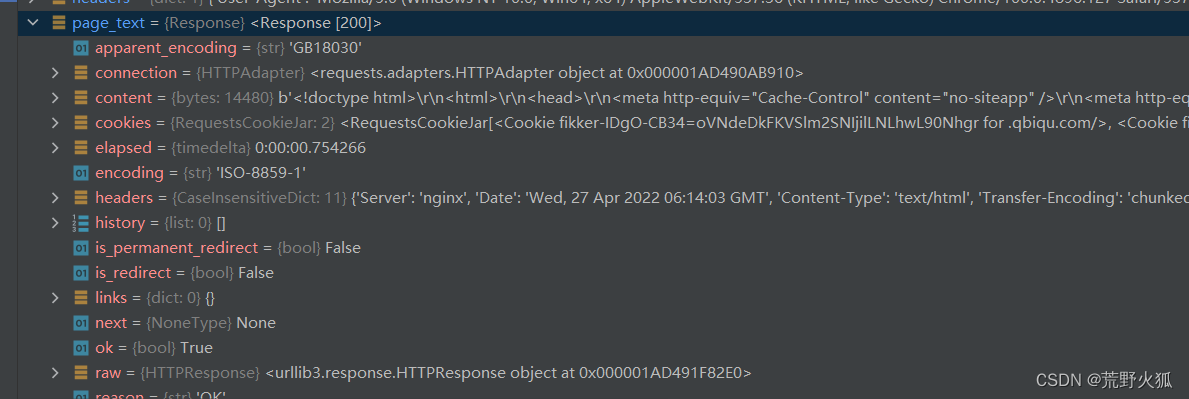
于是用类的方法调用
# #print(response.encoding) #查看网页返回的字符集类型
page_text = page_text.text.encode('iso-8859-1').decode(page_text.apparent_encoding) #完美解决爬虫中文数据乱码问题
6、在目录中获取详情页
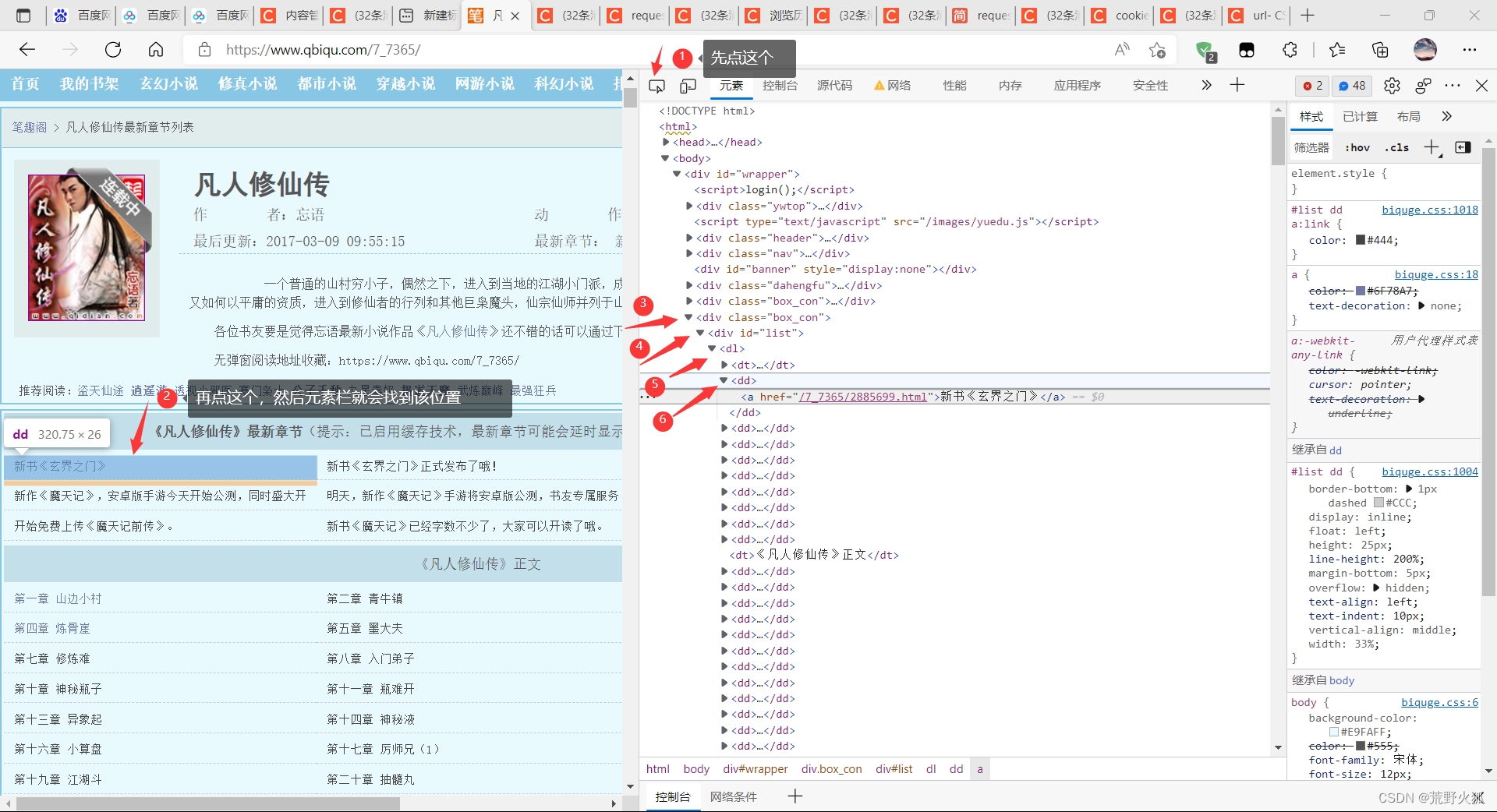
class 用.box_con
id 用#list 获取
#在首页中解析出章节的标题和详情页的url
#1.实例化BeautifulSoup对象,需要将页面源码数据加载到该对象中
soup = BeautifulSoup(page_text,'lxml')
#解析章节标题和详情页的url
dd_list = soup.select('.box_con > #list > dl > dd')
#print(dd_list)
#id和class都可以在网页中任何标签内使用。一般比较重要的部分、比较特别的盒子使用id,而小局部不重要的或小结构使用class。id调用css中以“#”井号命名的样式选择器,class调用css中以“.”英文半角小写句号命名的样式选择器。
dd_list 为标签dd的列表
for dd in dd_list:
#time.sleep(0.1)#解决requests.exceptions.ConnectionError问题
title = dd.a.string
title 为《凡人修仙传的目录》
detail_url = 'https://www.qbiqu.com/'+dd.a["href"]#要补全
detail_url为目录的详情页
7、在详情页中获取小说内容
同样的方法,定位到div标签页下的id content
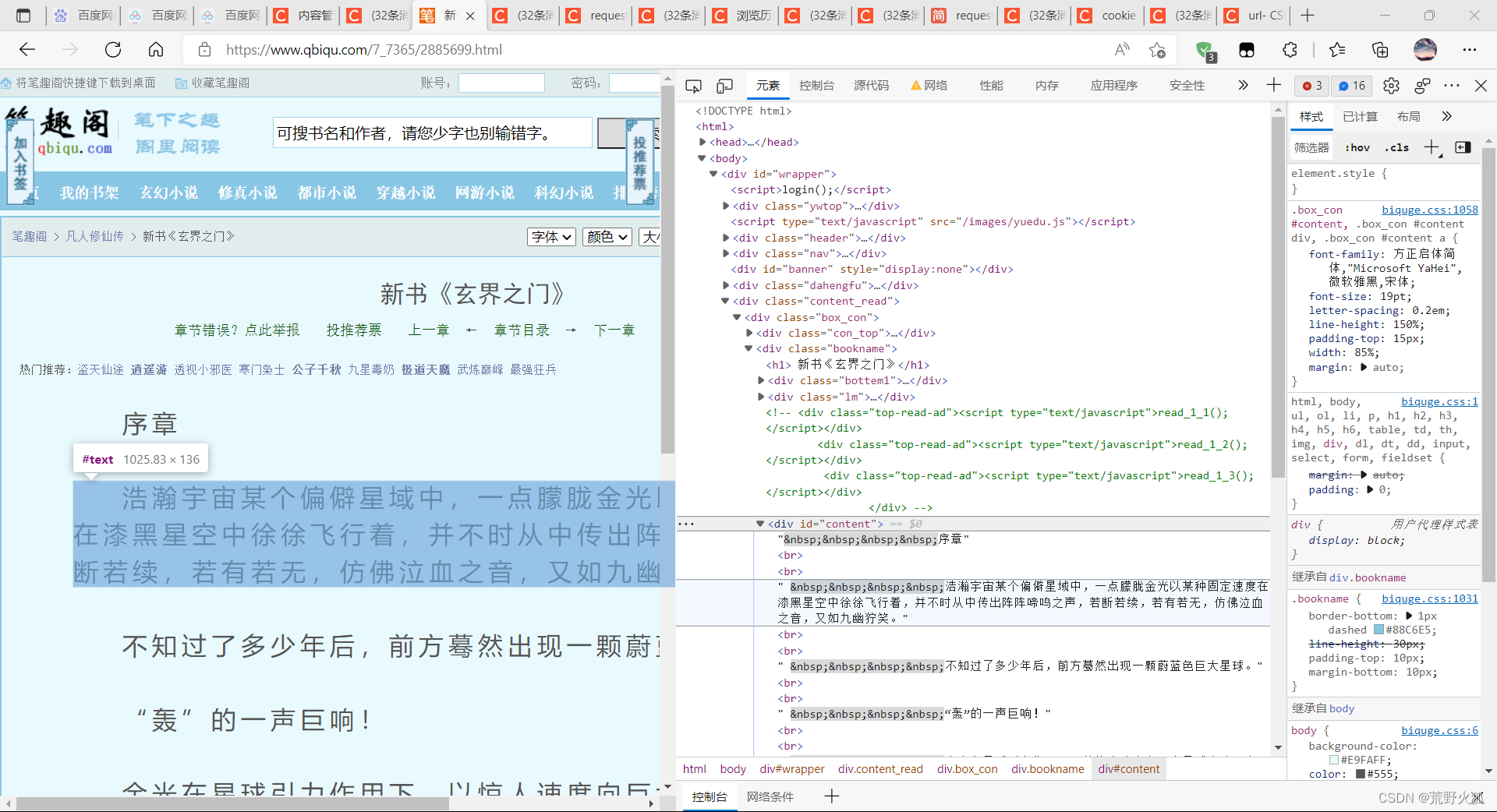
为了避免错误退出和网络不好的问题,和之前一样用了whie 和try,保证爬取成功才退出程序,因为session会保存之前的数据,所以不用再次session = requests.session()
还加上了time.sleep()延时,据大佬说不用加也没事。
#对详情页发起请求,解析出章节内容
while(1):
try :
detail_page_text = session.get(url = detail_url,headers = headers)#.text
detail_page_text = detail_page_text.text.encode('iso-8859-1').decode(detail_page_text.apparent_encoding)
#解析出详情页中相关的章节内容
detail_soup = BeautifulSoup(detail_page_text,'lxml')
div_tag = detail_soup.find('div',id = 'content')
#解析到了章节的内容
content = div_tag.text
#print(content)
fp.write(title +":" + content + "\n" )
print(title,"爬取成功")
time.sleep(3)
break
#time.sleep(3)
except Exception as e :
print(e)
8、持久化存储
fp = open('./fanrenxiuxian.txt','w',encoding='utf-8')
注意事项
如果你当前的网因为爬取多次,而被公网的ip被封了,就会这样

而其他网还能上,因为这个造成的
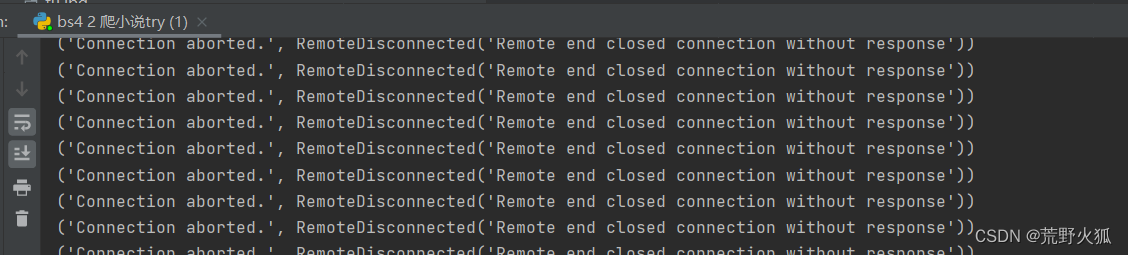
建议换个热点,换个网试试。
而其他博客说的
随机UA
代理ip
headers 加 ‘Connection’: ‘close’
博主一一试过,没什么用,最有效的方法就是获取cookie 和直接换热点
(为了这个我借了三个别人的热点)
四、小白常见问题
UA会被封吗?
大佬:ua不太可能封,因为ua是浏览器标识,同样浏览器在windows下会给出同样的ua,一封一大片,所有使用同一个操作系统,同一个浏览器的人都会是一样的ua,所以如果封了我的ua,就是拒绝所有在windows上用edge的人访问网站。
所以UA就获取自己浏览器下的就好。
封的是什么?
大佬:封你的公网ip,如果你用的njit,那就是学校的出口ip,整个学校都开不了。
爬虫君子协议
robots.txt协议
君子协议。规定了网站中哪些数据可以被爬虫爬取哪些数据不可以被爬取。在网址后加/robots.txt
淘宝君子协议
五、python代码
自写python代码
# -*- codeing = utf-8 -*-
# @Time : 2022/4/26 19:40
# @Auther : 顾家成
# @Fire .py
# @Software PyCharm
# -*- codeing = utf-8 -*-
# @Time : 2022/4/25 20:43
# @Auther : 顾家成
# @Fire .py
# @Software PyCharm
# 需求 爬取小说 笔趣阁《凡人修仙传》
import requests
#from urllib import request
from bs4 import BeautifulSoup
import time
import random
from random import randint
user_agent_list = [
#"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36",
#"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
# "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36",
# "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36",
# "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36",
# "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)",
# "Mozilla/5.0 (Macintosh; U; PPC Mac OS X 10.5; en-US; rv:1.9.2.15) Gecko/20110303 Firefox/3.6.15",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36 Edg/100.0.1185.50"
#"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36 Edg/100.0.1185.50"
#"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.146 Safari/537.36"
]
if __name__ == "__main__":
headers = {
#"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36 Edg/100.0.1185.44'
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36 Edg/100.0.1185.50",
}
# 创建一个session,作用会自动保存cookie
session = requests.session()
#headers['User-Agent'] = random.choice(user_agent_list)
url = 'https://www.qbiqu.com/7_7365/'
while(1):
try:
page_text = session.get(url= url,headers= headers)#.text
break
except Exception as e:
print(e)
time.sleep(2)
#page_text = session.get(url=url, headers=headers) # .text
# #print(response.encoding) #查看网页返回的字符集类型
page_text = page_text.text.encode('iso-8859-1').decode(page_text.apparent_encoding) #完美解决爬虫中文数据乱码问题
#print(page_text)
#在首页中解析出章节的标题和详情页的url
#1.实例化BeautifulSoup对象,需要将页面源码数据加载到该对象中
soup = BeautifulSoup(page_text,'lxml')
#解析章节标题和详情页的url
dd_list = soup.select('.box_con > #list > dl > dd')
#print(dd_list)
#id和class都可以在网页中任何标签内使用。一般比较重要的部分、比较特别的盒子使用id,而小局部不重要的或小结构使用class。id调用css中以“#”井号命名的样式选择器,class调用css中以“.”英文半角小写句号命名的样式选择器。
fp = open('./fanrenxiuxian.txt','w',encoding='utf-8')
flag = 1
for dd in dd_list:
#time.sleep(0.1)#解决requests.exceptions.ConnectionError问题
title = dd.a.string
#print(title)
detail_url = 'https://www.qbiqu.com/'+dd.a["href"]
#对详情页发起请求,解析出章节内容
while(1):
try :
#session = requests.session()#
#headers['User-Agent'] = random.choice(user_agent_list)
detail_page_text = session.get(url = detail_url,headers = headers)#.text
detail_page_text = detail_page_text.text.encode('iso-8859-1').decode(detail_page_text.apparent_encoding)
#解析出详情页中相关的章节内容
detail_soup = BeautifulSoup(detail_page_text,'lxml')
div_tag = detail_soup.find('div',id = 'content')
#解析到了章节的内容
content = div_tag.text#.split(" ")
#print(content)
fp.write(title +":" + content + "\n" )
print(title,"爬取成功")
time.sleep(3)
break
#time.sleep(3)
except Exception as e :
print(e)
# for dd in dd_list:
# #time.sleep(0.1)#解决requests.exceptions.ConnectionError问题
# title = dd.a.string
# #print(title)
# detail_url = 'https://www.qbiqu.com/'+dd.a["href"]
# #对详情页发起请求,解析出章节内容
# detail_page_text = session.get(url = detail_url,headers = headers)#.text
# detail_page_text = detail_page_text.text.encode('iso-8859-1').decode('gbk')
# #解析出详情页中相关的章节内容
# detail_soup = BeautifulSoup(detail_page_text,'lxml')
# div_tag = detail_soup.find('div',id = 'content')
# #解析到了章节的内容
# content = div_tag.text#.split(" ")
# #print(content)
# fp.write(title +":" + content + "\n" )
# print(title,"爬取成功")
#'''
大佬用c#写了一个还更好,他的运行结果,还加上了双线程爬取。