目录
Insight
DenseNet
ResNets
Dense connectivity
Composite function
Pooling layers
Growth rate
Bottleneck layers
Compression
实验
架构
Classification Results on CIFAR and SVHN
Accuracy
Capacity
Parameter Efficiency
Overfitting
Classification Results on ImageNet
Discussion
Model compactness
Implicit Deep Supervision
Stochastic vs. deterministic connection
Feature Reuse
论文题目:Densely Connected Convolutional Networks
发表机构:康奈尔大学,清华大学,Facebook AI
发表时间:2018年1月
论文代码:https://github.com/WangXiaoCao/attention-is-all-you-need-pytorch
pytorch代码:https://github.com/WangXiaoCao/attention-is-all-you-need-pytorch
本文提出了一种稠密卷积网络(DenseNet),对于每一层,前面所有层的特征图被用作输入,而它自己的特征图被用作所有后续层的输入。传统的有L层的卷积网络有L个连接——每层与其后续层之间都有一个连接——而本文的网络有L(L+1)/2个连接。
densenet有几个优点:
-
缓解了消失梯度问题
-
加强了特征传播
-
鼓励特征重用,并大大减少了参数的数量
Insight
之前的一些解决梯度弥散问题的研究工作都具有一个特性,就是使用了之前层到之后层的短路连接。本文提出了一种架构,将这种见解提炼为一种简单的连通性模式:为了确保网络中各层之间最大的信息流,将所有层(以匹配的feature map大小)直接连接在一起。为了保持前馈特性,每一层都从前面所有的层获得额外的输入,并将自己的特征图传递给后面的所有层。

注意:与ResNets不同的是,文章不是在它们被传递到一个层之前通过求和将它们组合起来;相反,而是通过连接特性来组合它们。因此,第l层有由前面所有卷积块的特征图组成的l个输入。它自己的特征图被传递到所有的L - l个之后的层。这将在一个L层网络中引入L(L+1) /2个连。由于其稠密的关联模式,文章将这种方法称为稠密卷积网络(DenseNet)。
-
比较反直觉的一件事是,这种网络比传统的卷积网络的参数更少,这是因为网络没有必要重新学习多余的特征图(残差网络中有大量的冗余)。DenseNet架构明确区分了添加到网络中的信息和保存的信息。DenseNet层非常狭窄(例如,每层12个过滤器),只向网络的“集体知识”中添加一小组特征图,并保持其余的特征图不变,最后的分类器根据网络中的所有特征图做出决定。
- 除了更好的参数效率之外,densenet的一大优势是其改进的信息流和网络中的梯度,这使得它们易于训练。每一层都可以直接得到损失函数和原始输入信号的梯度,导致了一种隐含的深层次的监督。这有助于训练更深层次的网络架构。
- 密集的连接有一种正则化效果,可以减少训练集较小的任务的过度拟合
DenseNet
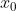 为输入,网络由L层组成,每一层实现非线性转换
为输入,网络由L层组成,每一层实现非线性转换 ,其中 l 索引层。可以是诸如批处理标准化(BN)、整流线性单元relu、池化或卷积等操作的复合函数。第l层的输出表示为
,其中 l 索引层。可以是诸如批处理标准化(BN)、整流线性单元relu、池化或卷积等操作的复合函数。第l层的输出表示为 .
.
ResNets
传统的卷积前馈网络将第l层的输出作为输入连接到第(l+ 1)个层,有:
ResNets的一个优点是梯度可以直接通过恒等函数从较后的层流到较前的层。但是恒等函数和的输出以和的形式组合在一起,可能会阻碍信息在网络中的流动。
Dense connectivity
为了进一步改善层之间的信息流,提出了一种不同的连接模式,如Figure 1所示,第 l 层接收所有之前层的特征图, ,作为输入:
,作为输入:![x_l=H_l([x_0,x_1\cdot \cdot \cdot x_{l-1}])](https://private.codecogs.com/gif.latex?x_l%3DH_l%28%5Bx_0%2Cx_1%5Ccdot%20%5Ccdot%20%5Ccdot%20x_%7Bl-1%7D%5D%29)
其中[]指在0层、…l-1层中产生的特征图的串联,串联成一个张量。
Composite function
定义为三个连续操作的复合函数:
- 批处理标准化(BN)
- 整流线性单元relu
- 3*3卷积
Pooling layers
当特征图的大小发生变化时连接操作是不可行的。因为卷积网络下采样层改变特征图的大小,为了便于在网络中使用下采样,将网络划分为多个紧密相连的密集块;参见下图。
把块之间的层称为过渡层,主要是卷积和池化。实验中使用的过渡层包括一个BN层和一个1×1的卷积层,然后是一个2×2的平均池化层

Growth rate
如果每个函数H产生k个feature map,则第l层有 个 feature map,其中k0为输入层的通道数。
个 feature map,其中k0为输入层的通道数。
DenseNet和现有网络架构的一个重要区别是DenseNet可以有非常窄的层,例如k = 12。将超参数k作为网络的增长率。
文章指出,一个相对较小的增长率就足以在数据集上获得先进的性能。对此的一种解释是,每一层都可以访问其块中的所有前面的特征图即可以访问网络的“集体知识”。可以把特征图看作是网络的全局状态。每一层都将自己的k个特征图添加到这个状态中。增长率调节了每一层向全局状态贡献的新信息的数量。一旦写入全局状态,就可以从网络中的任何地方访问它,而且不像在传统网络架构中那样,逐层复制它。
Bottleneck layers
虽然每一层只产生k个输出特征图,但它通常有更多的输入。可以在每个3*3卷积之前引入一个1*1 卷积作为瓶颈层,以减少输入特征图的数量,从而提高计算效率。
这种设计对DenseNet特别有效,采用这样一个瓶颈层的网络DenseNet-B,为BN-ReLU-Conv(1*1)-BN-ReLU-Conv(3*3)。在实验中,让每个1*1个卷积产生4k的feature maps。
Compression
为了进一步提高模型的紧凑性,可以减少过渡层的特征映射数量。
如果一个稠密块包含m个特征图,让过渡层生成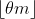 个输出feature- maps,其中0<θ≤1,为压缩因子。
个输出feature- maps,其中0<θ≤1,为压缩因子。
- 当θ取值为1时,穿过过渡层的特征图数量保持不变。将θ<1的DenseNet称为DenseNet- c,在实验中,设置θ= 0.5。
- 当使用瓶颈层,并且过渡层小于1时,将模型称为DenseNet-BC
实验
架构

Classification Results on CIFAR and SVHN
用不同的深度L和增长率k来训练densenet,结果如下表:黑体字标记所有优于现有技术的结果,蓝色表示总体最好的结果

Accuracy
- 在所有CIFAR数据集上,L = 190和k = 40的DenseNet-BC始终优于现有的最先进技术。
- 在C10和C100上的最佳结果(没有数据增加)都比使用drop-path正则化的FractalNet 低近30%。
- 在SVHN上,有dropout, L = 100和k = 24的DenseNet也超过了目前宽ResNet取得的最佳结果。
- 250层的DenseNet-BC并没有进一步提高性能。这可能是因为SVHN是一项相对简单的任务,深度极深的模型可能会过度拟合。
Capacity
在没有压缩或瓶颈层的情况下,随着L和k的增加,DenseNets的表现总体趋势更好。
这主要归因于模型容量的相应增长。C10+和C100+的列很好的展示了这一点。在C10+上,随着参数从1.0M增加到7.0M以上,误差从5.24%下降到4.10%,最后下降到3.74%。在C100+上,我们观察到了类似的趋势。这表明DenseNets可以利用更大、更深入的模型增加的代表性能力。也表明它们不存在过拟合问题,也不存在残差网络的优化困难。
Parameter Efficiency
在过渡层具有瓶颈结构和降维的DenseNet- BC参数效率很高。
L= 100和k = 12的DenseNet-BC取得了与1001层预激活ResNet相当的性能,参数少了90%。
下图显示了这两个网络在C10+上的训练损失和测试错误。1001层的深层ResNet收敛于一个较低的训练损失值,但测试错误类似。

Overfitting
观察到,在没有数据增强的数据集上,DenseNet架构的改进超过先前的工作是特别明显的。在C10上,改进表示误差相对减少了29%,从7.33%降到5.19%。在C100上,从28.20%下降到19.64%,降幅约为30%。
在实验中,观察到在单一设置下的过拟合:在C10上,将k=12增加到k=24所产生的参数增加4倍,导致误差从5.77%适度增加到5.83%。DenseNet-BC瓶颈和压缩层似乎是应对这一趋势的有效方法。
Classification Results on ImageNet


Discussion
Model compactness
输入连接的一个直接结果是,任何DenseNet层学习到的特征图都可以被随后的所有层访问。这鼓励在整个网络中重用特性,并导致更紧凑的模型。
下图比较在C10+ 上的DenseNets所有变体的参数效率:

从图中可以看出:
- DenseNet- bc始终是DenseNet最具参数效率的变体。
- 为了达到同样的精度水平,DenseNet-BC只需要ResNets(中间图)大约1/3的参数。
- 只有0.8M可训练参数的DenseNet-BC与具有10.2m参数的1001层(预激活)ResNet具有相当的准确率
Implicit Deep Supervision
对于稠密卷积网络精度提高的一种解释可能是,各个层通过更短的连接从损失函数获得额外的监督。也叫“深度监督”。
Stochastic vs. deterministic connection
在密集卷积网络和随机深度正则化残差网络之间有一个有趣的联系。在随机深度下,残差网络的层是随机丢弃的,它在周围的层之间创建了直接的连接。由于池化层从未被丢弃,因此网络产生了与DenseNet类似的连接模式:如果所有中间层都被随机丢弃,那么在同一池化层之间的任何两个层都有很小的概率直接地依赖连接。
Feature Reuse
根据设计,DenseNets允许各层从之前的所有层(尽管有时通过过渡层)得到feature map。
文章首先在C10+上训练一个L = 40 k = 12的DenseNet。对于在一个块内的每个卷积层l,计算分配给层s连接的平均(绝对)权重。图5显示了所有三个密集块的热图。平均(绝对)权重表明了这一层对于之前某一层feature的利用率。一个红点(l, s)表示,对层l平均来说,强烈使用s层之前产生的特征。可以得出几个观察结果:

-
一些较早层提取出的特征仍可能被较深层直接使用
-
即使是Transition layer也会使用到之前Denseblock中所有层的特征
-
在第二和第三密集块内的层一致地分配最小的权值给过渡层的输出(三角形的顶部行),即第2-3个Denseblock中的层对之前Transition layer利用率很低,说明transition layer输出大量冗余特征.这也为DenseNet-BC提供了证据支持,既Compression的必要性.
-
最后的分类层虽然使用了之前Denseblock中的多层信息,但更偏向于使用最后几个feature map的特征,说明在网络的最后几层,某些high-level的特征可能被产生.