摘要
传统机器学习的目的是通过最小化训练数据的正则化经验风险,对测试数据的最小期望风险最小的模型,但假设训练数据和测试数据具有相似的联合概率分布。TAL的目标是通过从语义相关但分布不同的源域学习知识,来建立能够执行目标域任务的模型。
在经典的机器学习问题中,往往假设训练集和测试集分布一致,在训练集上训练模型,在测试集上测试。然而在实际问题中,测试场景往往非可控,测试集和训练集分布有很大差异,这时候就会出现所谓过拟合问题:模型在测试集上效果不理想。
主要内容
文章对迁移学习和域适应(文章统称为Transfer Adaptation Learning, TAL),介绍了五个关键的挑战、技术以及基准数据集。
五大关键技术分别为:
实例权重调整自适应(Instance Re-Weighting Adaptation)
样本迁移,在源域中找到与目标域相似的数据,把这个数据的权值进行调整,使得新的数据与目标域的数据进行匹配,然后加重该样本的权值,使得在预测目标域时的比重加大
当训练集和测试集来自不同分布时, 这通常被称为采样选择偏差(sample selection bias)或者协方差偏移(covariant shift)。
实例权重调整方法旨在通过非参数方式对跨域特征分布匹配直接推断出重采样的权重。
基于直觉的权重调整
直接对原始数据进行权重调整:TrAdaBoost2。
J. Huang, A. Smola, A. Gretton, K. Borgwardt, and B. Scholkopf, Correcting sample selection bias by unlabeled data, in NIPS, 2007, pp. 1–8.
基于核映射的权重调整:将原始数据映射到高维空间(如,再生核希尔伯特空间RKHS)中进行权重调整.
分布匹配
主要思想是通过重新采样源数据的权重来匹配再生核希尔伯特空间中源数据和目标数据之间的均值。
主要有两种非参数统计量来衡量分布差异:
- 核均值匹配(kernel mean matching, KMM)
J. Huang, A. Smola, A. Gretton, K. Borgwardt, and B. Scholkopf, Correcting sample selection bias by unlabeled data, in NIPS, 2007, pp. 1–8.
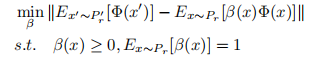
通过调整源样本的β重系数, 使得带权源样本和目标样本的KMM最小。
- 最大均值差异(maximum mean discrepancy, MMD)
H. Yan, Y. Ding, P. Li, Q. Wang, Y. Xu, and W. Zuo, Mind the class weight bias: Weighted maximum mean discrepancy for unsupervised domain adaptation, in CVPR, 2017, pp. 2272–2281

这种方法相比于KMM考虑到了类别权重的差别。
样本选择
主要方法有
- 基于k-means聚类的:KMapWeighted
Intuitive Re-Weighting是在raw dataspace上操作的,而Kernel Mapping Based-ReWeighting是通过kernel mapping,使source和target在再生的希尔伯特核空间(RKHS)上距离最小化(距离衡量用MMD或KMM)做Distribution Mapping.核映射后两个域的边缘分布相似,但条件分布仍不同,可以利用Sample Selelction做进一步变换,可以利用cluster assumption做聚类,选取同一个cluster中标签相同的source samples
H. Yan, Y. Ding, P. Li, Q. Wang, Y. Xu, and W. Zuo, Mind the class weight bias: Weighted maximum mean discrepancy for unsupervised domain adaptation, in CVPR, 2017, pp. 2272–2281
H. Yan, Y. Ding, P. Li, Q. Wang, Y. Xu, and W. Zuo, Mind the class weight bias: Weighted maximum mean discrepancy for unsupervised domain adaptation, in CVPR, 2017, pp. 2272–2281
协同训练
主要思想是假设数据集被表征为两个不同的视角, 使两个分类器独立地从每个视角中进行学习。首先分别在每个视图上利用有标记样本训练一个分类器;然后,每个分类器从未标记样本中挑选若干标记置信度(即对样本赋予正确标记的置信度)高的样本进行标记,并把这些“伪标记”样本(即其标记是由学习器给出的)加入另一个分类器的训练集中,以便对方利用这些新增的有标记样本进行更新。
H. Yan, Y. Ding, P. Li, Q. Wang, Y. Xu, and W. Zuo, Mind the class weight bias: Weighted maximum mean discrepancy for unsupervised domain adaptation, in CVPR, 2017, pp. 2272–2281
H. Yan, Y. Ding, P. Li, Q. Wang, Y. Xu, and W. Zuo, Mind the class weight bias: Weighted maximum mean discrepancy for unsupervised domain adaptation, in CVPR, 2017, pp. 2272–2281
特征自适应(Feature Adaptation)
特征适应,意在为不同域的数据找到共同的特征表示方法。
基于特征子空间
该方法假设数据可以被低维线性子空间进行表示, 即低维的格拉斯曼流形(Grassmann manifold)被嵌入到高维数据中。
通常用PCA方法来构造该流形, 使得源域和目标域可以看成流形上的两个点, 并得到两者的测地线距离(geodesic flow)。
- 基于流形的方法有SGF和GFK
集成无穷多个子空间来模拟域的移动
R. Gopalan, R. Li, and R. Chellappa, Domain adaptation for object recognition: An unsupervised approach, in ICCV, 2011, pp. 999–1006
B. Gong, Y. Shi, F. Sha, and K. Grauman, Geodesic flow kernel for unsupervised domain adaptation, in CVPR, 2012, pp. 2066–2073
- 基于流形的方法有SA、SDA、GTH
利用变换矩阵等方法直接对其source和target的subspace对齐
B. Gong, Y. Shi, F. Sha, and K. Grauman, Geodesic flow kernel for unsupervised domain adaptation, in CVPR, 2012, pp. 2066–2073
B. Sun and K. Saenko, Subspace distribution alignment for unsupervised domain adaptation, in BMVC, 2015, pp. 24.1–24.10.
J. Liu and L. Zhang, Optimal projection guided transfer hashing for image retrieval, in AAAI, 2018.
基于特征变换
特征变换方法旨在学习变换或投影矩阵,使得源域和目标域中的数据在某种分布度量准则下更接近。
基于投影
该方法通过减少不同域之间的边缘分布和条件分布差异, 求解出最优的投影矩阵.
- MMD下,基于边缘分布的TCA、基于条件分布的JDA
S. J. Pan, I. W. Tsang, J. T. Kwok, and Q. Yang, Domain adaptation via transfer component analysis, IEEE Trans. Neural Networks, vol. 22, no. 2, p. 199, 2011
S. J. Pan, I. W. Tsang, J. T. Kwok, and Q. Yang, Domain adaptation via transfer component analysis, IEEE Trans. Neural Networks, vol. 22, no. 2, p. 199, 2011
S. Si, D. Tao, and B. Geng, Bregman divergence-based regularization for transfer subspace learning, IEEE Trans. Knowledge and Data Engineering, vol. 22, no. 7, pp. 929–942, 2010.
- 基于Hilbert-Schmidt Independence Criterion
A. Gretton, O. Bousquet, A. Smola, and B. Scholkopf, Measuring statistical dependence with hilbert-schmidt norms, in ALT, 2005.
基于度量
该方法通过在带标签的源域中学习一个好的距离度量, 使得其能够应用于相关但不同的目标域中。
Z. Ding and Y. Fu, Robust transfer metric learning for image classification, IEEE Trans. Image Processing, vol. 26, no. 2, p. 660670, 2017.
B. Sun, J. Feng, and K. Saenko, Return of frustratingly easy domain adaptation, in AAAI, 2016, pp. 153–171.
基于增强
特征增强方法,假设数据的特征可分为common,source specific,target specific(公共特征、源域特征、目标域特征)三种,基于此进行数据增强。
- 基于零填充(Zero Padding)的EasyAdapt(EA)
H. Daume III, Frustratingly easy domain adaptation, in arXiv,2009.
- 基于生成式模型(Generative Model)
训练两个GAN分别做数据增强和特征提取
R. Volpi, P. Morerio, S. Savarese, and V. Murino, Adversarial feature augmentation for unsupervised domain adaptation, in CVPR, 2018, pp. 5495–5504.
基于特征重构
利用source domain重建target domain以学习共同特征,排除outliers和噪音,对reconstruction矩阵加以rank或sparsity的限制以更好地学习两个领域的相关性。
- 低秩重构(Low-rank Reconstruction)
I. H. Jhuo, D. Liu, D. T. Lee, and S. F. Chang, Robust visual domain adaptation with low-rank reconstruction, in CVPR, 2012, pp. 2168–2175.
- 稀疏重构(Sparse Reconstruction)
L. Zhang, W. Zuo, and D. Zhang, Lsdt: Latent sparse domain transfer learning for visual adaptation, IEEE Trans. Image Processing, vol. 25, no. 3, pp. 1177–1191, 2016.
基于特征编码
Feature Reconstruction是在两个领域的raw feature上学习reconstruction coefficients,而feature coding的方法注重于 seeking a group of basis (i.e., dictionary)and representation coefficients in each domain, 所以又称为域适应字典学习(domain adaptive dictionary learning)。
- 共享域字典(Domain-shared dictionary)
S. Shekhar, V. Patel, H. Nguyen, and R. Chellappa, Generalized domain-adaptive dictionaries, in CVPR, 2013, pp. 361–368.
- 指定域字典(Domain-specific dictionary)
F. Zhu and L. Shao, Weakly-supervised cross-domain dictionary learning for visual recognition, International Journal of Computer Vision, vol. 109, no. 1-2, pp. 42–59, 2014.
分类器自适应Classifier Adaptation
分类器适应,利用source domain的大量带标注数据和target domain的少量带标注数据学习一个generic classifier。
基于核分类器
- 自适应支持向量机(adaptive support vector machine, ASVM)
在SVM中加一个bias item:

J. Yang, R. Yan, and A. G. Hauptmann, Cross-domain video concept detection using adaptive svms, in ACM MM, 2007, pp. 188–197.
- 基于多核学习(multiple kernel learning, MKL)的域迁移分类器
L. Duan, I. Tsang, D. Xu, and S. Maybank, Domain transfer svm for video concept detection, in CVPR, 2009
基于流形正则项
这种方法基于半监督学习的manifold assumption,即假设特征空间中距离近的样本属于同一类别的可能性较大.核心是挖掘边缘分布的几何形状,将其作为一个增加的正则化项,用了有监督和无监督样本共同来挖掘这一个数据分布的几何结构,这样训练出来的分类器就有更好的泛化性。
M. Long, J. Wang, G. Ding, S. Pan, and P. Yu, Adaptation regularization: a general framework for transfer learning, IEEE Trans. Knowledge and Data Engineering, vol. 26, no. 5, p. 10761089, 2014.
Y. Cao, M. Long, and J. Wang, Unsupervised domain adaptation with distribution matching machines, in AAAI, 2018
J. Wang, W. Feng, Y. Chen, H. Yu, M. Huang, and P. S. Yu, Visual domain adaptation with manifold embedded distribution alignment, 2018.
基于贝叶斯分类器
M. Gonen and A. Margolin, Kernelized bayesian transfer learning, in AAAI, 2014, pp. 1831–1839.
深度网络自适应(Deep Network Adaptation)
DNN适应,研究如何将DNN学习到的特征在不同领域间迁移
这也是我关注的重点,这是目前迁移学习和深度网络最密切的应用形式,instance,feature,classifer的方法都可以整合到这里来。
基于边缘分布对齐
边缘分布对齐,将source domain和target domain各层特征的MMD距离加入损失项
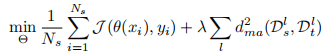
E. Tzeng, J. Hoffman, N. Zhang, K. Saenko, and T. Darrell, Deep domain confusion: Maximizing for domain invariance, arXiv, 2014
- 深度自适应网络DAN
DAN的基本思想是通过将更高层次的特征嵌入到再现核希尔伯特空间(RKHSs)中,以实现域之间的非参数核匹配(例如,基于MMD的),从而增强在特定任务的dnn层中的特征可转移性。
M. Long, Y. Cao, J. Wang, and M. I. Jordan, Learning transferable features with deep adaptation networks, in ICML, 2015, pp. 97–105.
M. Long, H. Zhu, J. Wang, and M. Jordan, Deep transfer learning with joint adaptation networks, in ICML, 2017.
基于条件分布对齐
- 深度迁移网络DTN
多考虑语义信息,定义了与MMD类似的d将条件概率项加入到损失中
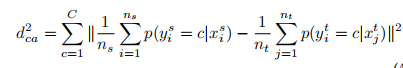
X. Zhang, F. Yu, S. Wang, and S. Chang, Deep transfer network: Unsupervised domain adaptation, in arXiv, 2015.
基于自动编码器
用source data训练encoder,用decoder表征target data来做Adaptation.Stacked deep autoencoder用于TAL的General idea可以用这个式子表示:
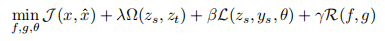
M. Chen, Z. Xu, K. Weinberger, and F. Sha, Marginalized denoising autoencoders for domain adaptation, in ICML, 2012
对抗式自适应(Adversial Adaptation)
对抗式适应,基于GAN的思想,使特征生成和域分类器进行对抗训练啊,直到两个领域的分布难以区分.作者介绍了三类方法,前两种是基于特征进行domain discrimination,第三种是用GAN生成target domain的图像。
基于梯度转换
- 通过添加一个简单的梯度转换层(gradient reversal layer, GRL)来实现领域自适应。
Y. Ganin and V. Lempitsky, Unsupervised domain adaptation by backpropagation, in arXiv, 2015.
基于Minimax优化
其与基于梯度转换的方法相似,在网络中加入gradient reversal layer(GRL).模型由三部分构成:domain-invariant的特征表示模型,图像分类器,域分类器,最小化图像分类器的损失,最大化域分类器的损失。
H. Ajakan, P. Germain, H. Larochelle, F. Laviolette, and M. Marchand, Domain-adversarial neural network, in arXiv, 2015
E. Tzeng, J. Hoffman, K. Saenko, and T. Darrell, Adversarial discriminative domain adaptation, in CVPR, 2017, pp. 7167–7176
M. Long, Z. Cao, J. Wang, and M. I. Jordan, Conditional adversarial domain adaptation, in NIPS, 2018.
K. Saito, K. Watanabe, Y. Ushiku, and T. Harada, Maximum classifier discrepancy for unsupervised domain adaptation, in CVPR, 2018, pp. 3723–3732.
基于生成对抗网络
用GAN生成target domain的图像,主要有基于CycleGAN
J. Hoffman, E. Tzeng, T. Park, and J. Zhu, Cycada: Cycleconsistent adversarial domain adaptation, in ICML, 2018.
L. Hu, M. Kan, S. Shan, and X. Chen, Duplex generative adversarial network for unsupervised domain adaptation, in CVPR, 2018, pp. 1498–1507.