介绍
如果你是神经网络领域的初学者,那么你可能已经使用过CPU训练模型。好吧,即使你的模型有 100000 个参数也没关系,训练模型可能需要几个小时。但是,如果你的模型有 100 亿或 200 亿个参数怎么办?像 VGG16 这样常见的 CNN 模型有 1.38 亿个参数,因此使用 CPU 训练这样的模型将是一个问题,因为它会占用你很多宝贵的时间。
在本文中,我们将讨论 GPU 如何为我们解决这个问题,并拥有使用 GPU 训练简单模型的实践经验。
为什么 GPU 在某些任务中优于 CPU?
而不是我介绍它的好处,相信我这个视频会给你一个更好的想法。
来源:https://www.youtube.com/watch?v=ZrJeYFxpUyQ&t=7s
现在你可能有主意了吧?是的,GPU 的这种大规模并行计算能力极大地帮助我们提高了复杂神经网络模型的性能并减少了训练时间。GPU 包含大量内置的较小内核,有助于完成此任务。
神经网络中最基本的运算是矩阵乘法,GPU 非常擅长这个任务,它像专门研究矩阵乘法的专业数学家一样解决这些计算。GPU 相对于 CPU 的其他一些优势是:
为了高效利用 GPU 的多核,我们使用了 CUDA 编程模型。在 Pytorch 中,运行 CUDA 操作要容易得多。
但请切记,GPU不会在所有目的上替代CPU,因为在主程序仍在运行时,GPU会通过帮助运行给定应用程序的并行重复计算,而仅作为CPU的额外贡献者。在 CPU 上。GPU优于CPU的其他一些应用程序是:
与其坚持理论方面,不如让我们通过在 Google Colab notebook 上使用 GPU 训练模型来动手实践。
在 google Colab 中在 GPU 上训练神经网络模型
使用google Colab环境,我们可以免费使用“NVIDIA Tesla K80”GPU。但请记住,你只能连续使用它 12 小时,之后你可能无法在特定时间内访问它,除非你购买 Colab pro。
我们将把MNIST 手写数字分类数据集作为我们的问题。我们的任务是训练一个模型,该模型可以将给定的手写数字图像正确分类为相应的标签。因此,在 GPU 上训练模型时,你必须强调的一些主要步骤是:
设置运行时类型。
定义一个在 GPU 和 CPU 之间切换的函数。
将数据集和模型加载到 GPU 中。
那么让我们开始吧!
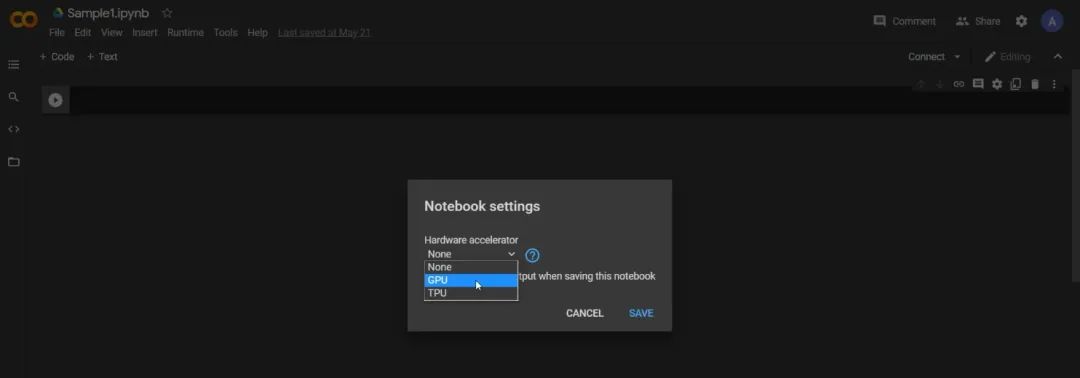
步骤 1:设置 Google Colab 笔记本
创建新笔记本后,第一步是将运行时类型设置为 GPU。

步骤 2:加载必要的库
import torch
import torchvision
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import torch.nn as nn
import torch.nn.functional as F
from torchvision.datasets import MNIST
from torchvision.transforms import ToTensor
from torchvision.utils import make_grid
from torch.utils.data.dataloader import DataLoader
from torch.utils.data import random_split
%matplotlib inline
# Use a white background for matplotlib figures
matplotlib.rcParams['figure.facecolor'] = '#ffffff'
步骤 3:创建训练和验证数据集
dataset = MNIST(root='data/',download =True,transform = ToTensor())
#Splitting dataset to train and validaion
val_size = 10000
train_size = len(dataset) - val_size
train_set,val_set = random_split(dataset,[train_size,val_size]
步骤 4:批量加载训练和验证数据集
batch_size = 128
train_loader = DataLoader(train_set,batch_size=128,shuffle=True,num_workers=2,pin_memory =True)
val_loader = DataLoader(val_set,batch_size=256,shuffle=True,num_workers=2,pin_memory=True)
当你想将 CPU 上加载的数据集推送到 GPU 时,设置pin_memory = True 会导致两者之间的数据传输速度更快。
步骤 5:创建类 Mnistmodel
class Mnistmodel(nn.Module):
def __init__(self,input_size,hidden_size,out_size):
super().__init__()
##hidden layer
self.linear1 = nn.Linear(input_size,hidden_size)
## Output layer
self.linear2 = nn.Linear(hidden_size,out_size)
def forward(self,xb):
xb = xb.view(xb.size(0),-1)
# Output of hidden layer
out = self.linear1(xb)
#Applying Relu activation on output of hidden layer
rel = F.relu(out)
# Final output
out = self.linear2(rel)
return out
def training_step(self,batch):
""" Returns loss for a training data"""
images,labels = batch
out = self(images)
loss = F.cross_entropy(out,labels)
return loss
def validation_step(self,batch):
"""Finding loss and accuracy for a batch of validation data"""
images,labels = batch
out = self(images)
loss = F.cross_entropy(out,labels)
acc = accuracy(out,labels)
return {'val_loss':loss,'val_acc':acc}
def validation_epoch_end(self,outputs):
batch_losses = [x['val_loss'] for x in outputs]
epoch_loss = torch.stack(batch_losses).mean()
batch_accuracy = [x['val_acc'] for x in outputs]
epoch_accuracy = torch.stack(batch_accuracy).mean()
return {'val_loss':epoch_loss,'val_acc':epoch_accuracy}
def epoch_end(self,epoch,result):
print("Epoch [{}], val_loss: {:.4f}, val_acc: {:.4f}".format(epoch, result['val_loss'], result['val_acc']))
使用该类,我们可以创建需要训练的模型。
在将模型和数据加载到 GPU 之前,让我们检查一下 GPU 是否可用?
torch.cuda.is_available()
如果一切顺利,你可能会得到输出为True。 但是 由于你没有使用 Colab pro,如果你连续使用一段时间,有时 GPU 将无法使用。
所以在下一步中,我们正在创建一个在 GPU 和 CPU 之间切换的函数,以便在 GPU 不可用时自动切换到 CPU。
步骤 6:创建一个辅助函数,以在 CPU 和 GPU 之间切换
def get_default_device():
"""Picking GPU if available or else CPU"""
if torch.cuda.is_available():
return torch.device('cuda')
else:
return torch.device('cpu')
device = get_default_device()
现在即使GPU不可用也不会有问题,因为你将自动切换到CPU进行训练,但是训练所花费的时间会很长。
步骤 7:定义将数据/模型移动到 GPU 的函数
def to_device(data, device):
"""Move tensor(s) to chosen device"""
if isinstance(data, (list,tuple)):
return [to_device(x, device) for x in data]
return data.to(device, non_blocking=True)
步骤 8:创建类 Devicedataloader
class DevicedataLoader():
def __init__(self,dl,device):
self.dl = dl
self.device = device
def __iter__(self):
for b in self.dl:
yield to_device(b, self.device)
def __len__(self):
return len(self.dl)
train_loader = DeviceDataLoader(train_loader,device)
val_loader = DeviceDataLoader(val_loader,device)
使用类 Devicedataloader,我们将创建帮助我们将 train_loader 和 val_loader(在步骤 4 中定义)中存在的数据移动到 GPU 的对象。
步骤 9:定义用于训练和验证模型的函数
def fit(epochs,lr,model,train_loader,val_loader,opt_func = torch.optim.SGD):
history = []
optimizer = opt_func(model.parameters(),lr)
for epoch in range(epochs):
#training phase
for batch in train_loader:
loss = model.training_step(batch)
loss.backward()
optimizer.step()
optimizer.zero_grad()
#Validation phase
result = evaluate(model,val_loader)
model.epoch_end(epoch,result)# Result after each epoch
history.append(result)
return history
def evaluate(model,val_loader):
outputs = [model.validation_step(batch) for batch in val_loader]
return model.validation_epoch_end(outputs)
步骤 10:创建类 MNISTmodel 的实例并将其移动到 GPU
num_classes =10
model = Mnistmodel(input_size =784 ,hidden_size=32,out_size= num_classes)
to_device(model,device)
请注意,在创建模型后,你必须将其移至GPU,否则我们已经移动的数据将在GPU中,而模型将在CPU中。
步骤 11 :训练和验证模型

就是这样了!!你已经使用 GPU 训练了你的模型。
结论
现在我希望你可能对使用 GPU 训练模型有了更好的想法,以及在使用 GPU 的训练阶段要记住的三个重要步骤。
为了使你了解更多,最近,由莱斯大学的一组计算机科学家创建了一种称为SLIDE(亚线性深度学习引擎)的新算法。该算法背后的主要思想是减少在反向传播中进行的无用计算。这种高效的算法仅使用 CPU 来训练深度学习模型,而不依赖于硬件加速器。
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 mthler」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓