阅读论文:Combined Deep Learning With Directed Acyclic Graph SVM for Local Adjustment of Age Estimation | IEEE Journals & Magazine | IEEE Xplore
目录
1. 基本信息
2. 核心内容
3. 相关内容
3.1 SE-RESNET-50
1) RESNET
2) SQUEEZE-AND-EXCITATION模块
3.2 LAAE
A 局部调整
B 线性支持向量机
C 有向无环图SVM
D 邻域的设计
4. 实验
A 预处理、实验装置和评价指标
B 烧蚀实验
C 对比实验
5. 结论
1. 基本信息
C. Xiao, Z. Zhifeng, C. Jie and Z. Qian, "Combined Deep Learning With Directed Acyclic Graph SVM for Local Adjustment of Age Estimation," in IEEE Access, vol. 9, pp. 370-379, 2021, doi: 10.1109/ACCESS.2020.3046661.
关键词:年龄估计,深度学习,有向无环图支持向量机,局部调整。
2. 核心内容
A. 论文提出了一种基于深度学习和有向无环图SVM的局部调整年龄估计算法(LAAE)。流程图见图1。
B. 论文思想:在训练阶段,首先对VGGFace2数据集预先训练好的SE-ResNet-50网络进行微调。一旦网络收敛,由最后一个完全连接层的参数组成的向量作为表示,并训练多个一对一的(One-Versus-One)支持向量机。在测试阶段,我们首先将待估计的人脸图像送入SE-ResNet-50得到粗略的年龄估计值,然后设置特定的邻域,最后将训练好的支持向量机组合成有向无环图支持向量机,以全局估计的特定邻域为中心进行精确的年龄估计。
C. 实验设置:
数据集:VGGFace2数据集、AFAD图像集、MORPH图像集;
年龄估计的性能度量:平均绝对误差(MAE)和累积得分(CS);

3. 相关内容
3.1 SE-RESNET-50
1) RESNET
在VGGNet中,CNN达到了19层,在GoogleNet中,网络的层数达到了前所未有的22层。然而,在深度学习中,网络层数的增加通常伴随着计算资源的消耗、模型过拟合、梯度消失和梯度爆炸等问题。对于有足够研究资金的企业或大学来说,只有通过GPU集群才能解决计算资源短缺的问题。通过收集大量有效样本数据,配合Dropout等正则化方法,也可以解决过拟合问题。梯度问题也可以通过批量归一化来解决。似乎只要神经网络的层数不断增加,就能获得效益,但实验数据并不能有效地支持这一观点。网络深度越大,训练误差越大。当网络退化时,浅层网络可以达到比深层网络更好的训练效果。此时,如果将较低层的特性传输到较高层,效果应该不会比浅层网络差。从信息论的角度看,由于数据处理不平等的存在,在前向传输过程中,随着层数的加深,特征图中包含的原始图像信息会逐层减少,而身份映射的加入则保证了网络的后一层必然比前一层包含更多的图像信息。基于快速映射的思想,提出了残差神经网络。
残差网络是在原有神经网络的基础上添加一系列残差模块而形成的,如下图2所示。图2可以表示为: ,其中
,其中 是图左边的恒等映射,
是图左边的恒等映射, 为曲线右侧的残差,其中
为曲线右侧的残差,其中 为
为 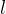 层的权重和偏差。当 当前层和后一层的特征图的数量维度不同时,需要进行1*1卷积运算来降低或提升维度。此时,
层的权重和偏差。当 当前层和后一层的特征图的数量维度不同时,需要进行1*1卷积运算来降低或提升维度。此时, ,其中
,其中 是 1∗1卷积运算。
是 1∗1卷积运算。
2) SQUEEZE-AND-EXCITATION模块
在卷积神经网络的卷积层,一系列卷积核的集合可以看作是输入通道上的邻域空间连接方式,它融合了局部接收域中的空间维度信息和通道信息。卷积神经网络通过叠加一系列卷积层、非线性激活函数和池化操作来获取层次模式并获得理论的全局接受域,从而生成鲁棒的表征。为了从空间信息层面提高网络性能,人们做了大量的研究工作。例如,初始结构中嵌入了多尺度信息,将多个感官场的特征依次聚合。由内而外考虑空间的邻域信息。Squeezing-and-Excitation模块(SE)通过考虑特征通道之间的关系来提高网络性能。该方法是自动学习每个特征通道的重要性。其重要性在于加强和抑制当前任务中不存在的特征。挤出激励模块(extruding-excitation module)各部分操作说明如下:
(1) :一般来说,它是卷积运算。
:一般来说,它是卷积运算。
(2)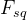 :挤压操作(Operation of Squeeze)。我们沿空间维度进行特征压缩,使输出维度与输入特征通道数匹配。此外,将每个二维特征通道转化为一个标量,该标量具有一定的全局接受域。它表示响应在特征通道上的全局分布,并使全局接受域在靠近输入的层可用。
:挤压操作(Operation of Squeeze)。我们沿空间维度进行特征压缩,使输出维度与输入特征通道数匹配。此外,将每个二维特征通道转化为一个标量,该标量具有一定的全局接受域。它表示响应在特征通道上的全局分布,并使全局接受域在靠近输入的层可用。
(3)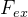 :激发操作(Excitation operation)。这是一种类似于循环神经网络中的门的机制,它通过学习显式地对特征通道之间的相关参数进行建模来为每个特征通道生成相应的权重。
:激发操作(Excitation operation)。这是一种类似于循环神经网络中的门的机制,它通过学习显式地对特征通道之间的相关参数进行建模来为每个特征通道生成相应的权重。
(4) :重新分配(即缩放)操作。在特征选择后,将激励输出(excitation output)的权重作为每个特征通道的重要程度,再乘以通道上的前一特征,完成原始特征在通道维度上的特征重校准。
:重新分配(即缩放)操作。在特征选择后,将激励输出(excitation output)的权重作为每个特征通道的重要程度,再乘以通道上的前一特征,完成原始特征在通道维度上的特征重校准。
SE模块可以集成到网络中,例如初始网络或残留网络。本文采用SE-Resnet-50作为主干网络,如图3所示。
先用一个残差模块后,再通过挤压使用全局平均池化操作,然后对两个全连接层之间的相关性进行显式建模:首先,将特征维数取为原来的1/r(r一般取16),经过一个完全连接的回溯到原来维度的瓶颈操作模块具有更强的非线性,大大降低了参数个数和计算复杂度,然后通过Sigmoid将特征权值取为0到1之间的值,最后通过Scale 运算对信道特征进行加权。
3.2 LAAE
A 局部调整
LAAE的想法是让CNN估计的年龄值尽可能接近局部邻域的真实年龄,如图4所示。

假设对于输入数据y,对应的CNN输出为f(y),即图4中的小黑圈。可能f(y)距离图中红色小圆的实际年龄值L还有一段距离,因此局部调整的年龄估计的思想是将估计值f(y)在区域范围的2d内左右滑动(即增加或减少),使其更接近实际年龄值L,它可以用公式表示为L∈[f(y)−d,f(y)+d]。
这样,局部调整的年龄估计可分为两个步骤:
1) 使用CNN网络对所有训练数据进行年龄分类。这一步可以被认为是粗略估计或全局估计。
2) 关注第一步的结果,并在小范围内进行局部调整。相应地,这一步可以被认为是微调或局部估计。
此时,关键问题是如何验证一定范围内的不同年龄值进行局部调整。我们的目标是通过全局回归使最初估计的年龄尽可能接近真实年龄。我们将每个年龄标签看作一个类别,并使用分类的方法对不同的年龄值进行局部调整或验证。由于每次局部调整只使用少量的年龄标签,因此回归方法无法正常工作。对于基于分类方法的局部调整,分类器方法有很多选择,但这里我们使用线性支持向量机进行局部调整。主要原因是SVM在训练样本较少的情况下具有鲁棒性。这已经在之前的小样本案例研究中得到了证明,如人脸识别、图像检索、音频分类和检索以及人脸表情识别。
B 线性支持向量机
已知训练向量(y1,z1),…,(yn,zn)属于两类,其中 。线性支持向量机可以学习一个最优分类超平面
。线性支持向量机可以学习一个最优分类超平面 来最大化两个类别之间的边界。SVM的学习本质是找到以下拉格朗日泛函的鞍点:
来最大化两个类别之间的边界。SVM的学习本质是找到以下拉格朗日泛函的鞍点:

其中S是拉格朗日乘数。其优化目标可以归结为以下对偶问题:

此时,最优超平面可以表示为对偶解:

将b的值代入原方程wy + b = 0即可求解。
测试时,对于任意数据点y,分类结果可以通过以下函数给出:

如果训练数据不可分,则可以引入松弛变量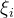 。这部分的详细介绍可以参考该部分的详细介绍。
。这部分的详细介绍可以参考该部分的详细介绍。
C 有向无环图SVM
经典支持向量机最初是为解决二分问题而设计的。当它扩展到多分类问题时,有以下几种方法:
1) 一对一:每两个类学习一个分类器;
2) 一对多:为每个类和其余的类训练一个以上的支持向量机;
3) 多对多:对于所有的类同时训练SVM显然不适合最后两种方法的算法,因为在局部调整部分只包括少量的样本,如果使用后面两种方法,SVM将在每次局部调整时动态地进行训练,这种训练无疑会增加第一种方法在任务中是可行的复杂度,原因是它不需要在线训练SVM,即所有的对都将离线训练SVM分类器。
在组合多个一对一的二值分类器的过程中,可以引入图论中有向无环图的思想,将多个二值分类器组合成多类分类器。对于n-分类问题,有向无环图SVM需要构造 个分类器,对应于n层结构中分布的 n(n-1) 个节点。以n=4为例,有向无环图中支持向量机的拓扑如图5所示。
个分类器,对应于n层结构中分布的 n(n-1) 个节点。以n=4为例,有向无环图中支持向量机的拓扑如图5所示。
从图5可以看出,有向无环图的顶层只包含一个节点,即根节点,第二层包含两个节点,依此类推,第i层包含i个节点,直到底层完成了n个类的分类。如果输入一个样本,则有向无环图从根节点开始,计算每个节点的符号函数 的决策值(见公式4)。如果为-1,则进入左子节点,如果为1,则变为右子节点。而最后一层叶节点的输出可以表示样本的类别。从这个角度来看,有向无环图等价于表操作:当初始表格包含所有类别时,则每个节点操作形成前后的两种比较,排除最不可能属于该类别的样本,并删除一个类别,在表格末尾的表格中只剩下一个类别作为样本所属的类别。
的决策值(见公式4)。如果为-1,则进入左子节点,如果为1,则变为右子节点。而最后一层叶节点的输出可以表示样本的类别。从这个角度来看,有向无环图等价于表操作:当初始表格包含所有类别时,则每个节点操作形成前后的两种比较,排除最不可能属于该类别的样本,并删除一个类别,在表格末尾的表格中只剩下一个类别作为样本所属的类别。
一般来说,对于n分类问题,在测试阶段只需要n-1个比较。这里,成对比较的数量被限制在m-1,因为只有m类参与局部调整(m<n)。

D 邻域的设计
在理论上,局部平差的邻域 很难设计,因为它是由许多因素决定的,例如样本规模的大小和粗略估计器的性能。然而,可以有广泛的方向:搜索范围越广,将真实年龄纳入该范围的可能性就越大。如果搜索区域太小,无法达到实际的年龄标签,那么在局部搜索时可能会找到任意的年龄标签。另一方面,如果局部搜索的范围过大,也增加了调整年龄偏离真实年龄的可能性,因为局部分类只是局部最优搜索。
很难设计,因为它是由许多因素决定的,例如样本规模的大小和粗略估计器的性能。然而,可以有广泛的方向:搜索范围越广,将真实年龄纳入该范围的可能性就越大。如果搜索区域太小,无法达到实际的年龄标签,那么在局部搜索时可能会找到任意的年龄标签。另一方面,如果局部搜索的范围过大,也增加了调整年龄偏离真实年龄的可能性,因为局部分类只是局部最优搜索。
为了局部调整年龄估计并满足有向无环图SVM的特殊拓扑结构,我们尝试了2的幂的不同局部搜索范围,即2(d = 1)、4(d = 2)、8(d = 4)和16(d = 8)。
从理论上讲,我们可以将搜索范围扩展到数据集的相同样本大小,但这不能满足“局部调整”的策略,所以我们将搜索范围设为最多16个。
在下一节的实验中,我们将指定不同的范围,并演示不同的局部搜索范围对结果的影响。主要目的是为了证明局部调整确实可以提高单个机器学习分类器或深度学习网络的年龄估计性能。
4. 实验
A 预处理、实验装置和评价指标
在年龄估计之前,对原始人脸图像进行以下预处理:首先利用级联的VJ检测器进行人脸检测,然后利用AAM定位人脸参考点,最后将人脸图像缩放到224∗224进行实验。本实验在caffe的GPU开源框架下进行,所使用的预训练SE-ResNet-50模型来源于文献[12](Q. Cao, L. Shen, W. Xie, O. M. Parkhi, and A. Zisserman, ‘‘VGGFace2:A dataset for recognising faces across pose and age,’’ in Proc. 13th IEEE Int. Conf. Autom. Face Gesture Recognit. (FG), May 2018, pp. 49–57.)。
年龄估计的性能通过两个度量来评估:平均绝对误差(MAE)和累积得分(CS)。
MAE定义为预测年龄值与实际年龄值之间的平均绝对误差:

其中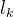 是测试样本k的实际年龄值,
是测试样本k的实际年龄值, 是估计的年龄值,N是测试集的样本大小。
是估计的年龄值,N是测试集的样本大小。
CS的公式定义为:

其中 是测试集中绝对值误差不小于j(即容差年龄误差)的图像总数。
是测试集中绝对值误差不小于j(即容差年龄误差)的图像总数。
B 烧蚀实验
为了证明LAAE的有效性,我们指定了不同的邻域,并展示了不同的局部搜索范围对结果的影响。作为对比,我们还增加了仅使用SE-ResNet和DAG SVM的消融实验(在这种情况下,使用图像三通道像素和线性降维即主成分分析(PCA)进行特征提取),结果如表1所示。

从表1可以得出以下结论:
- MORPH的性能总是比AFAD好。原因是MORPH中的图像是正式拍摄的,光照条件和相机性能都很好,而AFAD中的图像是从社交网络中抓取的,因此分辨率不同,这就造成了性能上的差异。
- 单一深度学习方法在两个数据集中的性能都优于单一经典机器学习方法(即本节中的DAG-SVM),进一步证明了深度学习的优越性。
- 局部调整的效果总是优于纯机器学习方法或纯深度学习方法,但不同邻域产生的性能差异很大,且两个数据集的最佳邻域设置也不相同。原因在于MORPH和AFAD的样本量大小不同,即MORPH中的类别数较多,所以搜索范围越大,性能越好,而AFAD则相反,因为其最好的性能是在d=4,之后邻域越大,效果就越差。
我们只取最大邻域d = 8。除了在前一节中提到的原因,邻域越大,越不符合局部调整的前置条件外,还有一个重要原因,那就是如果以d=16为较大的邻域,局部调整的范围将扩大到32个,而AFAD中的类别为40-16 + 1 = 35,相当于年龄的第二次估计。
C 对比实验
为了进一步验证该方法的有效性,将结果与其他基于深度学习的年龄估计方法进行了比较,结果如表2、图8和图9所示。论文的方法在MORPH和AFAD上的平均绝对误差分别达到3.04和3.17,与比较算法Cluster-CNN中最好的方法相比,我们的方法的性能明显超过了以前的方法,在平均情况下,我们的方法的性能提高了6%左右。

通过与其他累积得分指数方法的比较,我们分别选出了MORPH上最好的LAAE(d=8)和AFAD上最好的LAAE(d=4)。对比实验结果可以看到图8和图9,当容差年龄误差大于4时,我们的方法是领先于其他比较方法的。在图9中,我们的方法总是优于Cluster-CNN。


在图10和图11中,我们进一步比较了纯SE-ResNet-50和LAAE(d=8和d=4)在每个年龄的准确性。同样,我们的方法在几乎所有情况下都取得了一致的领先优势。需要注意的是,SE-ResNet-50的精确度极差,性能平平。我们的方法更统一,可能是因为它隐式地解决了类不平衡问题。这一结果也详细说明了使用局部调整方法来估计年龄的优越性。


5. 结论
本文提出了一种局部调整的年龄估计方法LAAE。具体地,首先利用深度学习对年龄进行全局粗略估计,然后通过设置邻域对DAG SVM进行局部精细估计。从实验结果可以看出,本文提出的由粗到精或/和从全局到局部的方法比纯深度学习和纯机器学习方法具有更好的性能,与其他方法的比较进一步说明了LAAE的有效性。

