多标记学习算法
算法分类
按相关性划分
“一阶(first-order)”策略:该类策略通过逐一考察单个标记而忽略标记之间的相关性,如将多标记学习问题分解为 个独立的二类分类问题,从而构造多标记学习系统。该类方法效率较高且实现简单,但由于其完全忽略标记之间可能存在的相关性,其系统的泛化性能往往较低。
一阶方法
Binary Relevance,该方法将多标记学习问题转化为“二类分类(binary classification)”问题求解;
ML-kNN,该方法将“惰性学习(lazy learning)”算法 k 近邻进行改造以适应多标记数据;
二阶方法
Calibrated Label Ranking[26],该方法将多标记学习问题转化为“标记排序(label ranking)”问题求解
Rank-SVM,该方法将“核学习(kernel learning)”算法 SVM 进行改造以适应多标记数据;
高阶方法
Random k-labelsets,该方法将多标记学习问题转化为“多类分类(multi-class classification)”问题求解。
LEAD,该方法将“贝叶斯学习(Bayes learning)算法”Bayes 网络进行改造以适应多标记数据。
算法适应法
ML-KNN(整理)
懒惰和关联的许多方法都是基于流行的k近邻(k Nearest Neighbors, kNN)懒惰学习算法。所有这些方法的第一步与kNN相同,即检索k个最接近的例子。区别它们的是这些例子的标签集的集合。
摘自硕士论文–多标记与偏标记学习算法研究_王登豹
本文CC参考文献

ML-kNN 算法[7]是用来解决多标记分类问题的懒惰算法,也是多标记分类领域最著名且最稳定(在多个数据集上表现比较稳定)的的算法之一。
主要思想是对传统kNN算法进行改造,通过使用最大后验规则来决定一个示例与每个标记是否应该相关联,代替了传统kNN算法投票多者胜出的原则。
kNN兼顾了基于特征相似度的近邻方法和贝叶斯推理方法的优点,使得其决策边界可以根据样本的差异动态的调整,而且后验概率表达式的使用在很大程度上避免了标记不平衡问题。
ML-KNN算法在决定样本标记归属时是对每个类别分开计算的,因此该方法属于一阶方法(ML-KNN算法忽略了标记相关性的利用)。
不足
虽然上文提到的多标记k近邻算法ML-kNN在多个数据集上表现比较稳定,但是我们发现其决策过程存在缺陷。当用ML-kNN算法对未知样本分类时,对于所有的待分类样本,只要它们的k近邻中具有某个类别的样本数目相等,它们就会以相同的概率被划分为这个类别标记,这种策略忽略了不同样本在特征空间中的位置差异。实际上,对于一个真实多标记数据集,特征空间中不同位置的样本,即使都拥有某个类别标记,其对应的k 近邻里面属于该类别标记的样本数目也不尽相同。因此,在运用k 近邻算法解决多标记问题时,我们应该将样本在特征空间的位置差异考虑在内,以获得更准确的分类结果。
Rank-SVM
摘自硕士论文–多标记与偏标记学习算法研究_王登豹
本文CC参考文献
Rank-SVM 算法[9]是基于支持向量机算法提出的多标记分类算法,该算法继承了传统支持向量机基于最大间隔来优化损失函数的特性,将一个样本对所有“相关标记&不相关标记”中最小的间隔作为该样本的间隔,而样本集的最小间隔则为所有样本中最小的间隔,然后通过最大化这个间隔来处理多标记学习问题。
Rank-SVM 算法通过引入核函数,能够有效的处理非线性的数据。由于Rank-SVM 算法中应用了基于排序的损失函数,因此该方法属于二阶多标记学习算法。
基本思想
采用“最大化间隔(maximum margin)”策略,定义一组线性分类器以最小化ranking loss评价指标,并通过引入“核技巧(kernel trick)”处理非线性分类问题。
An efficient multi-label support vector machine with a zero label
对Rank-SVM的改进,对Rank-SVM简化,并加入零标签作为区分相关和不相关标签的基准标签。
BP-MLL(Backpropagation for Multi-Label Learning)摘自硕士论文–多标记与偏标记学习算法研究_王登豹
本文CC参考文献
BP-MLL(Backpropagation for Multi-Label Learning)算法[8]将神经网络引入到多标记学习中来,该方法通过反向传播算法来更新神经网络的参数,利用一个基于排序的损失函数,使得模型能够很好地适应多标记学习的特点。
近年来,有深度神经网络在表示学习方面的突出表现,神经网络方法又重新得到大量的关注,因此在多标记学习领域,其他基于神经网络的多标记学习算法例如 ML-RBF 算法(基于 RBF 神经网络)[11]、MT-DNN(基于深度神经网络)[10]也被相继提出。
Random k-Labelsets for Multi-Label Classification
BP-MLL是一种适应流行的多标记学习的反向传播算法。该算法的主要改进是引入一个新的(考虑多个标签的)误差函数。这个误差函数类似于排序损失。
摘自:多标签数据挖 掘技术 : 研究综述
BP-MLL(Back-Propagati on for Multi-Label Learning)反向传播多标签学习法 。引人一个新的误差函数,该函数考虑了多标签学习的特征,例如: 对于一个样本的预测,相关标签应排在不相关标签前面等。
LEAD
该算法的基本思想是基于“贝叶斯网络(Bayesian network)”对标记之间的相关性进行建模,并采用近似策略实现对贝叶斯网络的高效学习。
LAML-kNN
LAML-kNN是一种局部自适应的k近邻多标记算法,该算法考虑到数据集样本空间中不同位置的样本之间的差异性,将样本的位置信息引入到用来分类的后验概率表达式里。
AdaBoost.MH和AdaBoost.MR
摘自:多标签数据挖 掘技术 : 研究综述


ML-DT(Multi-Label Decision Tree)> 摘自硕士论文–多标记与偏标记学习算法研究_王登豹
本文CC参考文献

ML-DT(Multi-Label Decision Tree)算法[42]采用决策树方法处理多标记学习问题,该方法定义了一种基于信息增益的多标记信息熵,并通过迭代构建用于处理多标记分类问题的决策树。
从树结构的根节点开始,ML-DT算法通过最大化信息增益将样本的特征空间分为两部分,通过迭代不断将特征空间进行分割从而产生新的子节点。ML-DT算法在计算多标记信息熵时假设标记之间是相互独立的,因此该方法属于没有利用标记相关信息的一阶方法。
在 ML-DT 被提出后,多种基于决策树的多标记学习方法又被相继提出,例如在构建树的过程中利用了剪枝策略的多标记决策树方法[42],以及在决策过程中利用集成策略的多标记决策树方法[43][44]。
问题转换法
CLR(Calibrated Label Ranking)算法 and RPC(Ranking by pairwise comparison)
摘自硕士论文–多标记与偏标记学习算法研究_王登豹
本文CC参考文献

Ranking by pairwise comparison (RPC)将多标签数据集对于每对标签$(y_i,y_j)$都转换一个二类标记数据集集,共$q(q-1)/2$个。每个数据集都包含训练集D的示例,这些示例由至少两个对应标签中的一个进行注释,但不能同时使用两个。从这些数据集训练,学习区分两个标签的二元分类器。给定一个新示例,将调用所有二类分类器,并通过计算每个标签收到的投票来获得排名。
将多标记分类问题转化成标记排序问题 ,其中标记排序采用“成对比较
(pairwise comparison) ”的方式实现。
例如 CLR(Calibrated Label Ranking校准的标签排序算法)[5]通过标记对内两个标记输出之间的比较实现多标记排序。对于有q个标记的多标记分类问题,总共会有q(q-1)/2个二元分类器用来进行标记对的比较,每个二元分类器对应一个标记对。由于CLR算法是通过标记对两两比较进行排序的,因此该算法属于二阶多标记算法。不同于BR和CC算法利用“一对多(one-vs-rest)”的方式构建二元基分类器,CLR方法利用“一对一(one-vs-one)”的方式构建基分类器,因此该方法能够处理标记不平衡问题。
但是该方法的缺点和Label Powerset类似,当标记数目过大时,CLR 需要构
建的基分类器数目会随标记数目q呈指数级增长,使得该方法不仅在训练阶段耗时较长,在对未知样本进行分类时同样需要较长的计算时间,难以处理一些有实时性需求的任务。
校准标签排名(CLR)通过引入一个额外的虚拟标签扩展了RPC,它作为一个自然的断裂点,将排名标签变成一个相关和不相关的标签集合。
摘自 多标记学习_张敏灵,周志华
对于具有q个类别的标记空间而言,针对每一个可能的标记配对$\left(y_{j}, y_{k}\right)(1 \leq j<k \leq q)$,采用成对比较的方式将产生共计$q(q-1)/2$个二类分类器。具体来说,对于标记配对$(y_{j}, y_{k})$而言,成对
比较法首先构造与该配对对应的二类训练集:
\begin{array}{c}
\mathcal{D}_{j k}=\left\{\left(\boldsymbol{x}_{i}, \psi\left(Y_{i}, y_{j}, y_{k}\right)\right) \mid \phi\left(Y_{i}, y_{j}\right) \neq \phi\left(Y_{i}, y_{k}\right), 1 \leq i \leq m\right\} \\
\text { where } \psi\left(Y_{i}, y_{j}, y_{k}\right)=\left\{\begin{array}{ll}
+1, & \text { if } \phi\left(Y_{i}, y_{j}\right)=+1 \text { and } \phi\left(Y_{i}, y_{k}\right)=-1 \\
-1, & \text { if } \phi\left(Y_{i}, y_{j}\right)=-1 \text { and } \phi\left(Y_{i}, y_{k}\right)=+1
\end{array}\right.
\end{array}
基于此,成对比较法采用某种二类学习算法$\mathcal{B}$训练二类分类器$g_{j k}: \mathcal{X} \rightarrow \mathbb{R}, \text { 即 } g_{j k} \leftarrow \mathcal{B}\left(\mathcal{D}_{j k}\right)_{\circ}$由此可见,对于任一多标记样本$(x_i,Y_i)$,示例$x_i$将参与$\left|Y_{i}\right| \mid \bar{Y}_{i}|$个
二类分类器的学习。其中,对于$\left(y_{j}, y_{k}\right) \in Y_{i} \times \bar{Y}_{i}(j<k)$的情况而言,$x_i$在构造二类分类器$g_{jk}(\cdot)$时
对应于正例;对于$\left(y_{j}, y_{k}\right) \in \bar{Y}_{i} \times Y_{i}(j<k)$的情况而言,$x_i$在构造二类分类器$g_{jk}(\cdot)$时
对应于反例。




摘自多标签数据挖 掘技术 : 研究综述
BR(Binary Relevance)
摘自硕士论文–多标记与偏标记学习算法研究_王登豹
本文BR参考文献
摘自:多标签数据挖 掘技术 : 研究综述

摘自 多标记学习_张敏灵,周志华
基本思想
将一个多标记问题分解为q个二元分类问题(BR利用“一对多(one-vs-rest)”的方式构建二元基分类器),每个类别标记对应一个子问题。在每个子问题中,如果一个样本具有该子问题所对应的类别标记,则这个样本为正样本,否则为负样本。
BR算法的分类器是q个子分类器的集合,可以表示为$ f=\{f_1,f_2,\dots,f_q\} $,其中每个二类分类问题对应于标记空间的一个类别标记,每个二元分类子问题可以运用已有的机器学习算法求解。
给定多标记训练集$\mathcal{D}=\left\{\left(\boldsymbol{x}_{i}, Y_{i}\right) \mid 1 \leq i \leq m\right\}$,其中$Y_i$为隶属于示例$x_i$的相关标记集合。具体来说,对于第j个类别$y_{j}(1 \leq j \leq q)$而言,Binary Relevance 算法首先构造与
该类别对应的二类训练集:
\begin{aligned}
\mathcal{D}_{j}=\left\{\left(\boldsymbol{x}_{i}, \phi\left(Y_{i}, y_{j}\right)\right) \mid 1\right.&\leq i \leq m\} \\
\text { where } \phi\left(Y_{i}, y_{j}\right)=\left\{\begin{array}{ll}
+1, & \text { if } y_{j} \in Y_{i} \\
-1, & \text { otherwise }
\end{array}\right.
\end{aligned}
基于此,Binary Relevance 算法采用某种二类学习算法$\mathcal{B}$训练二类分类器$g_{j}: \mathcal{X} \rightarrow \mathbb{R}$,即$g_{j} \leftarrow \mathcal{B}\left(\mathcal{D}_{j}\right)$。由此可见,对于任一多标记样本$(x_i,Y_i)$,示例x_i将参与q个二类分类器的学习中。其中,
对于相关标记$y_{j} \in Y_{i}$而言,$x_i$在构造二类分类器$g_j(\cdot)$时对应于反例。该训练策略亦称为“交叉训练(cross-training) ”法。
在测试阶段,对于未见示例x ,Binary Relevance 算法通常采用如下方式预测其类别标记集合Y:
Y=\left\{y_{j} \mid g_{j}(\boldsymbol{x})>0,1 \leq j \leq q\right\}
值得注意的是,当所有二类分类器的输出均为负值时,将会导致算法预测的标记集合Y为空。为了
避免这种情况的发生,可以采用如下的 T-Criterion准则来进行预测:
Y=\left\{y_{j} \mid g_{j}(\boldsymbol{x})>0,1 \leq j \leq q\right\} \cup\left\{y_{j^{*}} \mid j^{*}=\arg \max _{1 \leq j \leq q} g_{j}(\boldsymbol{x})\right\}
此时, 当所有二类分类器输出为负时, 预测的标记集合中将含有输出值 “最大 (least negative) ”
的类别标记。
除了上述的T-Criterion准则之外,Boutell 等人[8]还给出了其它一些基于各二类分类器
[8] Boutell M R, Luo J, Shen X, Brown C M. Learning multi-label scene classification. Pattern Recognition, 2004, 37(9):
1757-1771.
输出确定测试样本标记集合的准则,具体细节可参见相应文献。
1、P-Criterion:标记输入测试数据通过所有的对应正的SVM分数的类(在“P-Criterion”,P代表正)。如果没有得分为正,则将该数据示例标记为“未知”
2、 T-Criterion: 这与p准则类似,但在如何处理全负评分情况时有所区别。在这里,我们使用封闭世界假设(CWA),即所有的例子都至少属于N类中的一个。如果所有的N个支持向量机分数为负,输入对应于产生最高分(最小负值)的支持向量机的标签。(T表示最大。)
3、C-Criterion: 不管支持向量机的分数是正还是负,最终的结果取决于与最高支持向量机分数的接近程度。(C表示接近。) 在一个样例的所有SVM分数中,如果第M个足够接近,那么相应的类被认为是这个样例的标签。我们使用最大后验(MAP)原则来确定阈值来判断支持向量机分数是否足够接近。(注意这独立于以上给出的 SVM 分数的概率解释。)
BR方法将多标记分类问题转化为了多个独立的子问题,各子问题之间没有联系,不同类别之间的相关性也没有被有效利用,因此BR算法通常被称为一阶多标记学习方法。
优点
转化方式简单,可以被灵活地用来解决现实世界里的很多应用场景,对于每个子问题也可以应用现有的很多机器学习算法来解决,如SVM、神经网络、KNN等
缺点
不能有效利用多标记之间的关系,而且还无法处理标记类别数目过大时严重的标记不平衡问题。
BR 未能考虑标签之间的联系
而导致一定程度上的信息损失
RAkEL——Random k-Labelsets
多标记学习–张敏灵,周志华
基本思想
将多标记学习问题转化为多类分类问题的“集成(ensemble) ” ,集成中的每一个基分类器对应于标记空间的一个随机子集,并采用“Label Powerset”的方式进行构造。
主要思想:将一个大的标签集随机分解为多个小的标签集(我们只考虑相同大小的标签集,k),并对每个小的标签集使用LP方法训练一个多标签分类器。对于一个未标记实例的多标签分类,将所有LP分类器的决策进行汇总和组合。
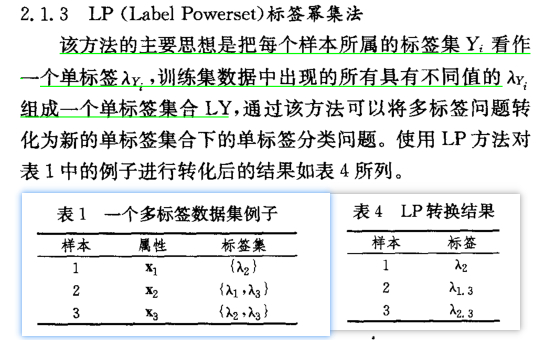
LP(Label Powerse标签幂集)(了解)
Label Powerset(简记为 LP)是一种直观地将多标记学习问题转化为多类分类问题的方法。它将多标签训练集中存在的每一组唯一的标签视为一个新的单标签分类任务的一个类别。给定一个新示例,LP的单标签分类器输出最可能的类,它实际上代表一组标签。


Random k-Labelsets


摘自:Random k-Labelsets
for Multi-Label Classification_2010
本文针对LP方法中的不足,提出将初始标签集随机分解为多个小型标签集,并利用LP训练相应的多标签分类器,由此产生的单标签分类任务在计算上更简单,并且它们的类值的分布更不倾斜,称为RAkEL的新的多标签分类方法。RAkEL可以被认为是一种通过使用随机操作标签空间来创建多标签分类器集合的新方法。
将最初的标签集分成若干随机小子集的方法有两种构造策略:
- 不相交( disjoint )RAkELd
- 重叠(overlapping)RAkELo
重叠策略比不相交策略具有更高的预测性能
这两种方法的结果都优于标准LP方法,特别是在有许多标签的情况。我们还发现重叠的子集比不相交的子集产生更好的结果,这是由于对每个标签进行分类器融合的过程。
不相交
子集不相交
对于给定标签集的大小k,
对标签集L拆分为[M/k](向上取模)个不相交的子标签集Rj(j:1-m)
若M/k能整除,则Rm也有k个标签
否则,Rm中只有M/k的余数个标签
之后使用LP学习m个多标签分类器
请注意,RAkELd可以预测未出现在训练集中的标签集,因为它的最终预测是从现有标签集的不同部分组装而成的。
重叠
在重叠标签集的情况下,RAkEL可以通过将该标签包含在其标签集中的不同LP模型收集对同一标签的多次预测。由于不同的LP模型是在不同的输出空间(不同的类标签)上训练的,因此它们对预测特定标签的值的任务提供了不同的观点。因此,通过投票过程结合他们的输出,提供了纠正潜在的不相关错误的机会,并提高整体性能。
给定标签集的大小k
可有C(k,M)个可能的k标签集
随机从这些可能的标签集中选取m个,初始为Ri
注:这些标签集可能会部分重叠
RAkELo通过使用LP方法学习m个多标记分类器
与Rd类似,Ro也可以预测训练集中没有的标签集,
摘自:多标签数据挖 掘技术 : 研究综述

LP(Label Powerset)
摘自:多标签数据挖 掘技术 : 研究综述
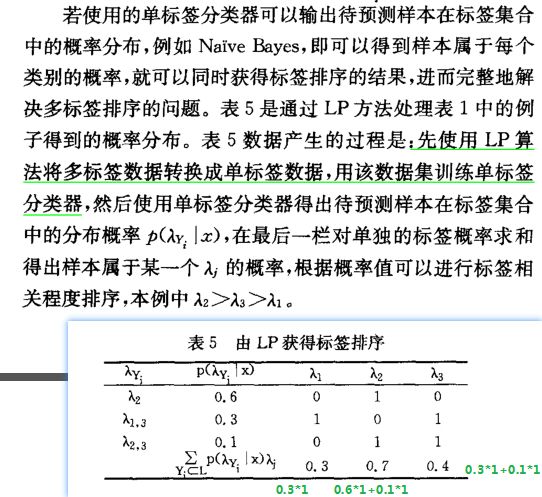
摘自硕士论文–多标记与偏标记学习算法研究_王登豹
本文CC参考文献


LP(Label Powerset 标签幂集算法)算法把数据集中出现的每一种标记组合作为一个更高层的类别,从而把多标记分类问题转化成多分类(Multi-Class Classification)问题。
LP将多标签训练集中存在的每一个唯一的标签集视为一个新的单标签分类任务的一个类别。对于给定的一个新示例,LP的分类器输出最可能的类,它实际上代表一组标签。
LP是一种相对简单的方法其优点是考虑到标签相关性。然而它受到具有大量标签M和训练示例N的域的挑战。
这种方法带来的一个明显的缺点是标记空间的类别数目的指数级增长,使得转化后的多分类问题难以求解。文献[4]针对这个问题提出了 RAKEL(Random k-Labelsets)算法[4][51],该算法多次随机抽取k个标记子集,对每次随机抽取的子集调用LP算法进行多分类学习,在对未知样本进行分类时,最终的多标记分类结果用集成方式得出,基于 Label Powerset 的方法同样属于高阶方法。
不足:
- LP仅能预测在训练集中出现过的类别标记集合,对于其真实标记集合在训练集中未出现的测试示例无法正确预测;
- 当标记空间较大时,往往会导致新类集合过大,从而导致部分新类在中的训练样本不足且多类分类器的训练复杂度过高。
LP的计算效率和预测性能受到具有大量标签和训练实例的应用领域的挑战。在这些情况下,类的数量可能会变得非常大,此外,许多标签集只与极少的例子相关,这也使得学习过程变得困难。
CC-分类器链(Classifier Chains, CC)
摘自硕士论文–多标记与偏标记学习算法研究_王登豹
本文CC参考文献

分类器链(Classifier Chains, CC)[3]算法将一个多标记分类问题转化成由q个二元子分类器(CC算法利用“一对多(one-vs-rest)”的方式构建二元基分类器)组成的链式结构,分类器链会将前一个子分类器的输出扩展到当前子分类器的输入里,从而充分利用类别标记之间的相关性,如下图:
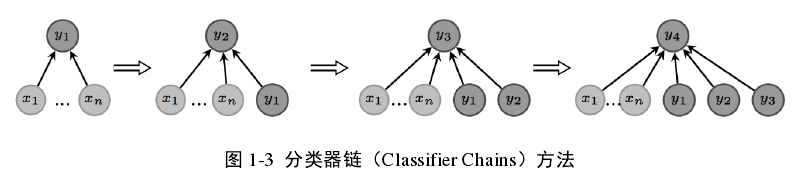
显然分类器链的上的标记顺序会影响最终的分类效果,针对这个问题文献[3]中提出了一个集成框架ECC(Ensembles of CC)来消除标记顺序带来的不利影响,ECC 算法生成多个随机标记顺序,多次调用CC算法训练多条分类器链,预测新样本时取所有分类器链的集成结果。分类器链方法属于高阶的多标记学习算法。
优点
是它能够利用标记之间的关系,通过这些额外的标记关系信息提升多标记学习的效果;
缺点
多个分类器链上的多个二元分类
子问题无法并行训练,使得该方法的时间复杂度更高;
ECC(Ensem bles of Cl assi fier Chai ns)组合分类器链
摘自:多标签数据挖 掘技术 : 研究综述
ECC组合分类器链是对于BR方法的一种改进,针对BR未能考虑标签之间的联系 而导致一定程度上的信息损失, 采用 了CC(Classifier Chain)分类器链,即通过将BR产生的 个二分类器连接成一条链,训练样本每经过一个二分类器,就将其预测结果添至样本属性向量中,继续代人下一个二分类器中训练。但是由于CC中二分类器不同顺序对结果有较大影响,因此 ECC 采取多条随机产生的不同标签序列的CC 组合,以减轻单个CA;由内部二分类器排列顺序问题而带来的不利影响。

RPC (Ranking by Pairwise Comparison)成对比较排序法
摘自:多标签数据挖 掘技术 : 研究综述
RPC (Ranking by Pairwise Comparison)成对比较排序法

多标记学习例子
在图像分类方面,一张真实图片可能会同时包含多个类别标记,如下图:

在新闻类型分类中,一篇新闻报道可能会同时涉及多个领域的内容,如下图:
