引言
测试驱动开发,英文全称 Test-Driven Development,简称 TDD,是一种不同于传统软件开发流程的开发方法。
在《程序员的职业素养》第五章,我第一次看到有关 TDD 内容,当时Bob大叔向我展示了一种不可思议的编程开发方法,这种方法颠覆了我的认知。Bob 大叔列举了 TDD 很多好处,例如确定性、降低代码缺陷、方便代码重构、测试单元文档化,更优秀的代码设计等等。并强力安利读者们尝试 TDD,因为 TDD 是专业人士的选择。
在 Bob 大叔的洗脑下,我决定去尝试学习如何使用 TDD。从写第一行 TDD 代码到现在,已经大概一年了,这期间我一直坚持用 TDD 的方式来写代码。还没毕业之前,需要写的代码比较少,鲜有机会锻炼 TDD 能力。进入公司工作后,就有大把的机会用 TDD 进行开发,对 TDD 的理解逐渐有一个比较全面的认知。此次要分享的目的就是向你展示实际使用 TDD 的系统方法,你将会学到:
- TDD的基本工作方式
- TDD的潜在好处
- TDD怎杨帮助解决设计缺陷
- TDD的难点和成本
- TDD怎么减少甚至免除调试工作
- 怎样长时间维持TDD
- 如何编写高质量的测试
另外,还会分享我这段时间使用 TDD 的一些感受,以及 TDD 对我开发思维的影响
Google Mock
在开始 TDD 之前,需要说明一些关于测试框架的内容,这一点不是必须的,你完全可以用assert来完成测试的工作,但是测试框架提供了更好编码体验,能够提高开发效率,你只需要花一点点的时间学习它,就能获得巨大的收获,何乐而不为呢。
本文所有的例子都是 C++ 代码,所用的测试框架为 Google Mock,它是一种模拟(Mock)和匹配器的框架,其中包含了单元测试工具 Google Test。
详细的安装以及使用,请参考 快速上手Google C++测试框架。这里我们简单重述一遍如何使用 Google Mock,以便你可以不被打断的继续看下去。
测试用例结构
一个测试用例,在 Google Mock 下,大致是这样的结构:
TEST(TestSuiteName, TestName)
{
... test body ...
}
TestSuiteName是测试套件名称,TestName测试用例名称。'测试套件’这个翻译很怪,让人不知所云,其实它是许多测试用例的集合,可以认为是一种逻辑上分组。
从左到右阅读测试套件和测试用例的名称,可以连成一句话,描述了我们想要验证的行为,例如下面的代码中:Set insert ignores duplicate values
TEST(SetInsert, IgnoresDuplicateValues)
{
std::set<int> a_set;
int val = 0;
a_set.insert(val);
a_set.insert(val);
ASSERT_THAT(a_set.size(), Eq(1));
}
断言
使用自动断言是自动化测试的关键,Google Mock 中提供了两种断言:
- ASSERT_* 失败是会终止当前函数,ASSERT_* 后面的代码将不会运行
- EXPECT_* 失败时不会终止,EXPECT_* 后面的代码将会继续运行
Google Mock 提供了两种形式的断言:经典式 和 Hamcrest 断言
经典式断言
下表列出了 经典式断言 的两个主要断言。其他框架也会使用类似的名称
| 形式 |
描述 |
实例 |
| ASSERT_TRUE(表达式) |
表达式返回假(或者0),测试失败 |
ASSERT_TRUE(4<7) |
| ASSERT_EQ(期待值,实际值) |
期待值和实际值不等时,测试失败 |
ASSERT_EQ(4, 20/5) |
更多关于经典断言的内容请参考:
Hamcrest 断言
Hamcrest 断言是为了提高测试的表达能力,创建复杂断言的灵活性,以及测试错误所提供的信息
Hamcrest 断言使用匹配器比较实际结果。匹配器可以组成复杂但易懂的比较表达式。你也可以自己定义匹配器。
几个简单的示例胜过千言万语
TEST(StringTest, StringEq)
{
string actual = string("al") + "pha";
ASSERT_THAT(actual, Eq("alpha"));
}
断言可以从左到右读作:断定实际值等于"alpha"。对比与 ASSERT_EQ(actual, "alpha"),Hamcrest 断言用区区几个额外的字符就提高了阅读性。
匹配器的价值在于它能极大地提升测试的表达能力,许多匹配器能够减少所需的代码量,同时也能提升测试的抽象层次。
ASSERT_THAT(actual, StartsWith("alx"));
Hamcrest断言在提升失败信息的可读性方面意义更大。
Value of: actual
Expected: starts with "alx"
Actual: "alpha"
Hamcrest 断言真的很 Coooool,如果你想进一步了解它,可以参考 快速上手Google C++测试框架 中关于匹配器的部分。
关于 Google Mock 的部分,我们就此打住,了解了以上的内容,你已经可以无障碍继续阅读了。
太棒了!如果你坚持看到了这里,那么你已经穿好鞋,准备好向 TDD 出发了。相信我,这趟旅途一定会让你受益匪浅。
测试驱动开发:第一个示例
开场白
写个测试,保证它通过,接着重构设计。这就是TDD的全部内容。但是这个三个简单的步骤背后却另有乾坤。就像踢足球一样,规则简单,但是想要踢得好,就需要进行训练以及学习相应的技巧。为了让你更快的理解TDD,这里我举个例子,让我们一起用TDD的形式开发一个小工具。这个实例提供了很多教学点,展示了TDD如何增量地设计一个程序。
场景:字节转换器
我们需要一个类,它能将一组字节转换成一组音频采样点(float),这样可以方便音频算法处理
再提供两个强假设:
- 字节都是以小端格式排列的
- 音频数据是 16 bit的,也就是说两个字节构成一个采样点(float)
开始吧
OK,让我们开始,上面的场景告诉我们,有一组字节(byte),我们需要将其转换成采样点…。等等!我们应该从最简单的开始,如果这个字节数组只有两个字节呢?为此我们写个测试:
#include <gmock/gmock.h>
TEST(AByteConverter, ConvertsTwoBytesToOneFloat)
{
ByteConverter converter;
}
- 第一行代码包含了gmock的头文件
- 一个简单的测试声明需要使用 TEST 宏。TEST宏包括两个参数:测试套件名称和测试用例名称。从左右往右阅读测试套件和测试用例名称,可以连成一句话,描述了我们想要验证的行为:A Byte Converter converts two bytes to one float。
- 我们创建了一个
ByteConverter 对象,然后…,停止!在写更多测试代码之前,我们已经加入了一些不能通过编译的代码:我们还没有定义 ByteConverter 类,先停下来解决这个问题。这个方法和TDD的三条规则保持一致:
- 只在为了使失败的测试用例通过时才编写产品代码
- 当测试刚好失败时,停止继续编写。编译失败也是失败。
- 只编写刚好让一个失败测试用例通过的代码
我们现在编译失败了(原则二),因此我们停止编写测试,开始编写产品代码(原则一)。这种增量地获得反馈是很好的办法,因为有时候只需要几行代码,就能产生一大堆的编译错误。若能够及时的看到代码产生的错误,那么就可以更容易的解决它们。
编译器提示我们需要 ByteConverter 类。我们可以添加一对.h/.cpp文件,但是先别自找麻烦。相反,不要急于使用独立文件,先简单地在测试文件中包含所有东西。在最后提交代码的时候,或者苦于所有东西都放在同一个文件的时候,再以适当的方式把产品代码独立出去。这种方法可以减少一直在文件间来回切换的开销,是一种短期内不引入复杂开销而节省时间的方式。
#include <gmock/gmock.h>
class ByteConverter
{
};
TEST(AByteConverter, ConvertTwoBytesToOneFloat)
{
ByteConverter converter;
}
如果你无法忍受将测试代码和产品代码暂时放在一起的做法,那就马上把东西分散到不同的文件吧,依然可以继续我们的示例。但是我建议你先试试这种方法,因为它可能是一种更有效的工作方式。
我们遵循了原则三:只编写刚好让测试通过的代码。很显然,我们并没有完成测试,ConvertTwoBytesToFloat没有测试任何行为,所以它验证不了什么,但是我们却对负反馈(编译失败)采取了应对措施,加入了足够的代码消除它。
构建并运行上面的测试就能得到正反馈了,如下:
[==========] Running 1 test from 1 test suite.
[----------] Global test environment set-up.
[----------] 1 test from AByteConverter
[ RUN ] AByteConverter.ConvertTwoBytesToOneFloat
[ OK ] AByteConverter.ConvertTwoBytesToOneFloat (0 ms)
[----------] 1 test from AByteConverter (0 ms total)
[----------] Global test environment tear-down
[==========] 1 test from 1 test suite ran. (0 ms total)
[ PASSED ] 1 test.
测试通过,欢乐时刻!虽然这个测试除了创建一个空类之外,没有干任何事情。但是,我们已经有了一些基本要素。并且,我们已经验证目前代码是正确的。如果你include的头文件写错了,或者class定义的分号忘记加了,那么你将第一时间发现这些错误。所以要尽早并频繁地测试,通常测试失败的原因只有一个。
继续吧!往测试中加入几行代码,来表示我们预期的客户端与ByteConverter对象交互方式
#include <gmock/gmock.h>
#include <vector>
class ByteConverter
{
};
TEST(AByteConverter, ConvertTwoBytesToOneFloat)
{
ByteConverter converter;
std::vector<uint8_t> two_bytes{0x01, 0x00}; // 1.0
float result = converter.convertTwoBytesToFloat(two_bytes[0], two_bytes[1]);
}
如上述代码所示,我们暴露了一个convertTwoBytesToFloat公共函数。尝试编译会失败,因为convertTwoBytesToFloat不存在。这个负反馈迫使我们去编写足够的代码,让测试通过编译。
class ByteConverter
{
public:
float convertTwoBytesToFloat(uint8_t byte_1st, uint8_t byte_2nd)
{
return 0.0f;
}
};
现在代码可以编译了,所有测试也通过了。是时候验证一些东西了:给定两个字节,convertTwoBytesToFloat 能够正确一个float返回吗?我们加入一个验证结果的断言:
TEST(AByteConverter, ConvertTwoBytesToOneFloat)
{
ByteConverter converter;
std::vector<uint8_t> two_bytes{0x01, 0x00}; // 1.0
float result = converter.convertTwoBytesToFloat(two_bytes[0], two_bytes[1]);
ASSERT_THAT(resutl, ::testing::FloatEq(1.0));
}
断言可以用来验证结果是否符合预期。上面代码中断言中声明了convertTwoBytesToFloat返回的值等于1.0。现在编译通过了,但是断言却失败了。
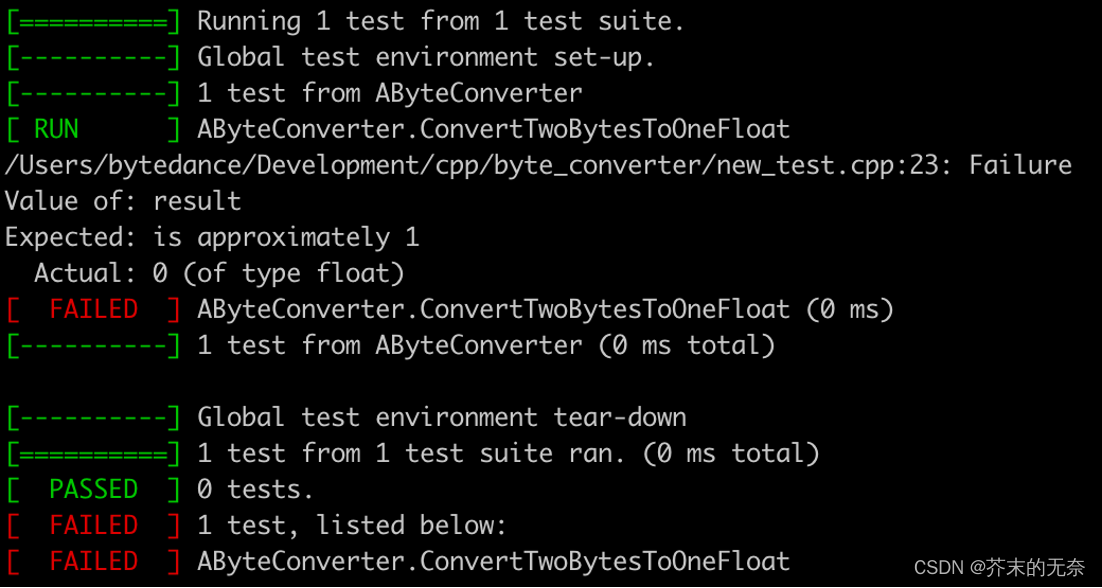
乍一看,Google Mock给出的信息可能不太容易读懂。从最后一行开始看,它提示我们有一个测试没有通过,并且在 [RUN] 和 [FAILED] 之间信息帮助我们了解测试为什么失败。在上面的例子中,可以看到下面信息:
Value of: result
Expected: is approximately 1
Actual: 0 (of type float)
断言信息非常明确:Google Mock期待 result 的值应该约等于1,但实际上却是0.
断言是意料之中的,因为为了通过编译,我们特意硬编码了一个0。得到这个负反馈是好事,也是TDD周期中可以发生的事情。首先,我们保证新加的测试不能通过,这表示这个功能没有被显示(有时候是通过的,但这通常不是个好事)。起初测试是失败,在加入适当的代码后测试通过了,这也说明测试时可靠的。
失败的断言提醒我们编写仅通过断言的代码即可。如下:
class ByteConverter
{
public:
float convertTwoBytesToFloat(uint8_t byte_1st, uint8_t byte_2nd)
{
int16_t result = byte_2nd | byte_1st;
return (float)(result);
}
};
现在编译并运行。最后两行显示测试通过了:

去掉不干净的代码
啥?我们才写了两行产品代码和四行测试代码就有问题?当然,区区几行代码也容易引入缺陷。让我们先审阅一下刚写的代码,找一找缺陷吧。有一点是确定的,测试中的断言不是非常便于阅读。
ASSERT_THAT(result, ::testing::FloatEq(1.0));
我们希望断言阅读起来想个句子,但是::testing::却妨碍了阅读。我们引入using来帮忙:
#include <gmock/gmock.h>
#include <vector>
using namespace testing;
TEST(AByteConverter, ConvertTwoBytesToOneFloat)
{
ByteConverter converter;
std::vector<uint8_t> two_bytes{0x01, 0x00}; // 1.0
float result = converter.convertTwoBytesToFloat(two_bytes[0], two_bytes[1]);
ASSERT_THAT(result, FloatEq(1.0));
}
现在断言看起来好多了,我们称这个小小的改动为重构,在不改变现有行为的前提下改进了设计。
另外,byte_2nd | byte_1st 看起来不知所云,还有(float)(result)强制转换不是良好的编程风格,我们进一步重构:
class ByteConverter
{
public:
float convertTwoBytesToFloat(uint8_t byte_1st, uint8_t byte_2nd)
{
return static_cast<float>(convertTwoBytesToInt16(byte_1st, byte_2nd));
}
private:
int16_t convertTwoBytesToInt16(uint8_t byte_1st, uint8_t byte_2nd)
{
return byte_2nd | byte_1st;
}
};
我们使用static_cast替换了强制转换,并封装convertTwoBytesToInt16用来提高了代码的可阅读性。
现在看起来好多了,重新编译并且运行,保证测试时通过。
增量性
我们已经完成了将两个比特转换成浮点数值的函数,如果了解过音频的同学可能注意到了,我们编写的代码不符合音频处理的使用习惯,因为音频处理中,采样点的范围应该是[-1, 1]。就目前来说,我们的代码中没有做归一化,所以它并不符合规范。所以数值的归一化是我们接下去要做的事情。
为了测试新的行为,我们需要写一个新的单元测试:
TEST(AByteConverter, ConvertTwoBytesToNormalizedFloat)
{
ByteConverter converter;
std::vector<uint8_t> two_bytes{0x01, 0x00}; // 1.0
float normalized_result = converter.convertTwoBytesToNormalizedFloat(two_bytes[0], two_bytes[1]);
}
同样的,convertTwoBytesToNormalizedFloat 没有定义,所以编译不过。因此编写刚好让编译通过的代码:
float convertTwoBytesToNormalizedFloat(uint8_t byte_1st, uint8_t byte_2nd)
{
return 0.0f;
}
然后编写断言:
TEST(AByteConverter, ConvertTwoBytesToNormalizedFloat)
{
ByteConverter converter;
std::vector<uint8_t> two_bytes{0x01, 0x00}; // 1.0
float normalized_result = converter.convertTwoBytesToNormalizedFloat(two_bytes[0], two_bytes[1]);
ASSERT_THAT(normalized_result, FloatEq(1.0/32768));
}
断言失败,这是预期之中的。接下去,写刚好让测试通过的代码:
float convertTwoBytesToNormalizedFloat(uint8_t byte_1st, uint8_t byte_2nd)
{
return convertTwoBytesToFloat(byte_1st, byte_2nd)/32768.0f;
}
新的测试通过了!但是代码中去出现了一些坏味:32768这个数字不知所云,并且重复了两次,一次在测试之中,一次在产品代码中。该进行重构了:
class ByteConverter
{
public:
constexpr static float MAX_16BIT_VAL = 32768.0f;
float convertTwoBytesToNormalizedFloat(uint8_t byte_1st, uint8_t byte_2nd)
{
return convertTwoBytesToFloat(byte_1st, byte_2nd)/MAX_16BIT_VAL;
}
...
};
TEST(AByteConverter, ConvertTwoBytesToNormalizedFloat)
{
ByteConverter converter;
std::vector<uint8_t> two_bytes{0x01, 0x00}; // 1.0
float normalized_result = converter.convertTwoBytesToNormalizedFloat(two_bytes[0], two_bytes[1]);
ASSERT_THAT(normalized_result, FloatEq(1.0/ByteConverter::MAX_16BIT_VAL));
}
我们将32768提取为静态常量,消除了硬编码的重复,并且提供了代码的可阅读性。
fixture 设置
在重构的时候,不仅要审阅产品代码,还要审阅测试代码。如上所述,我们的测试都要创建 ByteConverter 实例,并且使用相同的代码。我们不乐意看到这种貌似无关紧要的重复代码。这些重复会积累的很快,并且通常会演化为更为复杂的重复代码。这也会让测试变得主次不分,对于阅读代码的来说,这会分散注意力,从而忽视了真正需要关注的内容。
相关的测试拥有一些共同的代码是常见的,Google Mock 允许我们定义一个 fixture 类,我们可以在这个类里为相关的测试声明函数和数据。
class AByteConverter : public Test
{
public:
ByteConverter converter;
std::vector<uint8_t> two_bytes{0x01, 0x00}; // 1.0
};
TEST_F(AByteConverter, ConvertTwoBytesToFloat)
{
float result = converter.convertTwoBytesToFloat(two_bytes[0], two_bytes[1]);
ASSERT_THAT(result, FloatEq(1.0));
}
TEST_F(AByteConverter, ConvertTwoBytesToNormalizedFloat)
{
float normalized_result = converter.convertTwoBytesToNormalizedFloat(two_bytes[0], two_bytes[1]);
ASSERT_THAT(normalized_result, FloatEq(1.0/ByteConverter::MAX_16BIT_VAL));
}
上述代码中,我们创建了一个名为 AByteConverter 的 fixture(必须继承::testing::Test)。在 fixture 内部我们声明了公共变量 converter 和 two_bytes,以便测试可以访问。
Google Mock 运行每个单元测试时,会创建fixture实例。也就是说,在运行 ConvertTwoBytesToFloat 之前,它会创建一个 AByteConverter 实例。在运行ConvertTwoBytesToNormalizedFloat之前,创建另一个 AByteConverter 实例。
为了使用fixture,我们将宏TEST改成了TEST_F,F表示fixture。如果忘记加F,所有测试都会失败。
去除掉重复的测试代码至少了两个好处:
- 提高了测试的抽象度。现在每个测试只有两行代码,这有助我们集中精力关注与测试相关的东西
- 可以减低未来的维护测试的开销。试想一下,如果
ByteConverter的构造函数发生变化,那么只需要改动一个地方即可。
思索与测试驱动开发
简单的说,TDD的周期就是写一个测试,先确保测试失败,然后编码让其通过,接着审阅代码和打磨设计(包括测试的设计),最后保证所有测试仍然通过。在一天中,你不断的重复这个周期,保持周期尽量小,以便得到更多的反馈。
让我们继续下一个测试,我们传入一组字节,得到一组浮点值。沿着这个思路想下去,我们首先会考虑,返回的个数是多少?Ok,为了验证这个行为,让我们来写一个测试:
TEST_F(AByteConverter, ConvertsBytesToFloatsWithSizeOfHalfSizeOfBytes)
{
int num_bytes = 5;
std::vector<uint8_t> five_bytes(num_bytes);
auto floats = converter.convertBytesToFloat(five_bytes);
}
我们编写了一个新的函数convertBytesToFloat,它返回一组浮点数。同样的,这里提示编译失败,写一个刚好让编译通过的代码:
std::vector<float> convertBytesToFloat(const std::vector<uint8_t>& bytes)
{
return std::vector<float>();
}
编译通过,接着写测试代码:
TEST_F(AByteConverter, ConvertsBytesToFloatsWithSizeOfHalfSizeOfBytes)
{
int num_bytes = 5;
std::vector<uint8_t> five_bytes(num_bytes);
auto floats = converter.convertBytesToFloat(five_bytes);
ASSERT_THAT(floats.size(), Eq(num_bytes/2));
}
测试失败。然后接着写产品代码:
std::vector<float> convertBytesToFloat(const std::vector<uint8_t>& bytes)
{
auto num_floats = (bytes.size() / 2);
std::vector<float> floats(num_floats);
return floats;
}
在编译运行,测试通过。值得庆幸的是,上面的代码没有需要重构的地方,至少现在没有。所以我们赶紧进入下一个测试。
很自然的,下一个测试中我们应该验证其转换的浮点值是否正确:
TEST_F(AByteConverter, ConvertsBytesToFloats)
{
std::vector<uint8_t> five_bytes{
0x01, 0x00, // 1
0x02, 0x00, // 2
0x00
};
auto floats = converter.convertBytesToFloats(five_bytes);
ASSERT_THAT(floats[0], Eq(1));
ASSERT_THAT(floats[0], Eq(2));
}
很明显,测试失败了:
非常好,这是符合预期的失败,我们接着写让测试刚好通过产品代码:
std::vector<float> convertBytesToFloats(const std::vector<uint8_t> &bytes)
{
auto num_floats = (bytes.size() / 2);
std::vector<float> floats(num_floats);
for(int i = 0; i < num_floats; ++i)
{
floats[i] = convertTwoBytesToFloat(bytes[i*2], bytes[i*2 + 1]);
}
return floats;
}
接着编译运行,所有测试都通过了。
重构时间到!现在的代码中有好几处可以进行改进:
-
convertBytesToFloats函数中,2多次出现,并且含义不明确
- 新的测试代码中,用了两个
ASSERT_THAT来验证结果。但是如果返回的数组包含多个值呢?岂不是要写一大串的ASSERT_THAT才能验证结果?其实我们只需要一个ASSSERT_THAT就可以对比容器的内容了
-
five_bytes 变量在两个单元测试中都出现了,可以通过fixture来消除重复
先从最简单的重构开始,消除重复的five_bytes
class AByteConverter : public ::testing::Test
{
public:
ByteConverter converter;
std::vector<uint8_t> two_bytes{0x01, 0x00}; // 1.0
std::vector<uint8_t> five_bytes
{
0x01, 0x00, // 1
0x02, 0x00, // 2
0x00
};
};
TEST_F(AByteConverter, ConvertsBytesToFloatsWithSizeOfHalfSizeOfBytes)
{
auto floats = converter.convertBytesToFloats(five_bytes);
ASSERT_THAT(floats.size(), Eq(five_bytes.size()/2));
}
TEST_F(AByteConverter, ConvertsBytesToFloats)
{
auto floats = converter.convertBytesToFloats(five_bytes);
ASSERT_THAT(floats[0], Eq(1));
ASSERT_THAT(floats[1], Eq(2));
}
记得每次重构完成后都要重新运行单元测试,确保重构没有改变代码行为。
然后消除多余的ASSERT_THAT,只需要添加一个匹配器
class AByteConverter : public ::testing::Test
{
public:
ByteConverter converter;
std::vector<uint8_t> two_bytes{0x01, 0x00}; // 1.0
std::vector<uint8_t> five_bytes
{
0x01, 0x00, // 1
0x02, 0x00, // 2
0x00
};
std::vector<float> floats_of_five_bytes
{
1.0f,
2.0f
};
};
TEST_F(AByteConverter, ConvertsBytesToFloats)
{
auto floats = converter.convertBytesToFloats(five_bytes);
ASSERT_THAT(floats, ContainerEq(floats_of_five_bytes));
}
我们引入了ContainerEq匹配器,它可以比较容器的内容。更多关于匹配器的内容,参考Matchers
另外,为了精简测试代码,我们将要验证的结果floats_of_five_bytes加入到fixture中。
最后,给予2一个有意义的名字:
class ByteConverter
{
public:
constexpr static float MAX_16BIT_VAL = 32768.0f;
constexpr static size_t NUM_BYTES_OF_16BIT = 2;
...
std::vector<float> convertBytesToFloats(const std::vector<uint8_t> &bytes)
{
auto num_floats = (bytes.size() / NUM_BYTES_OF_16BIT);
std::vector<float> floats(num_floats);
for(int i = 0; i < num_floats; ++i)
{
floats[i] = convertTwoBytesToFloat(bytes[i*NUM_BYTES_OF_16BIT], bytes[i*NUM_BYTES_OF_16BIT + 1]);
}
return floats;
}
测试驱动与测试
或许有人觉得我们的测试用的数据都太弱了,应该增强测试数据,并增加新的测试来保证结果是正确的,例如编写多组长度不同的bytes,然后进行测试。
TDD诞生初期有个口头禅:“可能出现问题的地方才需要测试”。我们写的字节转换器出现问题的风险比较小,即使不挨个测试一遍,应该也不会出什么问题。
另一个相反的观点是,什么都可能出现问题,无论它多简单。这种观点下,我们可能需要提供一份上百个断言的测试用例,测试可能出错的每一种情况。但是它确实提升了我们发布代码的信心。
那么正确答案是什么?考量的重点在于我们在做测试驱动开发,而非测试。你或许会问:这两者有什么区别吗?答案是肯定。用测试的技巧,你会全面的分析,并创建大量的测试来罗列不同的行为。TDD则着力于代码设计,测试主要用于描述你要构建的行为,这些测试大都是TDD流程的附属产物,有了这些测试,在接下来改动代码的时候,你将更有信心。
TDD与测试区别很微妙。TDD的一个重要方面就是秉承够用心态。你写的测试只是为了开发代码做准备的。当要开发下一个行为时,再写测试。如果代码逻辑一样,就可以不写测试了。
既然选择了TDD,那么来完成接下来一个测试吧,让结果归一化,但是在这之前,先判断下返回数组的大小:
TEST_F(AByteConverter, ConvertsBytesToNormalizedFloatsWithSizeOfHalfSizeOfBytes)
{
auto normalized_floats = converter.convertBytesToNormalizedFloats(five_bytes);
}
convertBytesToNormalizedFloats未定义,编译不过。因此编写刚好让编译通过的代码:
class ByteConverter
{
public:
...
std::vector<float> convertBytesToNormalizedFloats(const std::vector<uint8_t>& bytes)
{
return std::vector<float>();
}
...
};
接着写断言,用于验证行为:
TEST_F(AByteConverter, ConvertsBytesToNormalizedFloatsWithSizeOfHalfSizeOfBytes)
{
auto normalized_floats = converter.convertBytesToNormalizedFloats(five_bytes);
ASSERT_THAT(normalized_floats.size(), Eq(five_bytes.size()/2));
}
毫不意外测试失败了。因此接下来写一个刚好让测试通过的产品代码
std::vector<float> convertBytesToNormalizedFloats(const std::vector<uint8_t>& bytes)
{
return convertBytesToFloats(bytes);
}
这里我们之间调用convertBytesToFloats就可以了。虽然它并没有归一化浮点数,但是返回结果的大小是我们想要的。
编译运行,测试通过!散花~
最后一个测试,让验证归一化的结果:
class AByteConverter : public ::testing::Test
{
public:
...
std::vector<float> norm_floats_of_five_bytes
{
1.0f/ByteConverter::MAX_16BIT_VAL,
2.0f/ByteConverter::MAX_16BIT_VAL
};
};
TEST_F(AByteConverter, ConvertsBytesToNormalizedFloats)
{
auto normalized_floats = converter.convertBytesToNormalizedFloats(five_bytes);
ASSERT_THAT(normalized_floats, ContainerEq(norm_floats_of_five_bytes));
}
编译并运行,断言失败
Value of: normalized_floats
Expected: equals { 3.05176e-05, 6.10352e-05 }
Actual: { 1, 2 }, which has these unexpected elements: 1, 2,
and doesn't have these expected elements: 3.05176e-05, 6.10352e-05
因此接着写让测试通过的代码:
std::vector<float> convertBytesToNormalizedFloats(const std::vector<uint8_t>& bytes)
{
auto normalized_floats = convertBytesToFloats(bytes);
std::transform(normalized_floats.begin(), normalized_floats.end(),
normalized_floats.begin(),
[](float x){return x/MAX_16BIT_VAL;}
);
return normalized_floats;
}
编译运行测试,太棒了,所有测试都通过了。
就这样我们增量性的完成了一个简易版字节转换器,它已经可以满足一些需求了,例如帮助解码16 bit的wav文件。如果你只有16bit的wav要解码,它完全就够了。当然,它可以继续扩展,例如可以支持8bit、32bit,可以支持多通道解码等等。这些新的需求都可以用TDD很好的完成。
这个方案绝对不是唯一或者最好的,但是我们已经有足够的信心去发布了,这才是最重要的。最后要做的事情就是将ByteConverter代码从测试代码中剥离,放到单独的 .h/.cpp 中,然后提交代码。
下面是完整的代码:
// byte_converter.h
#pragma once
#include <vector>
class ByteConverter
{
public:
constexpr static float MAX_16BIT_VAL = 32768.0f;
constexpr static size_t NUM_BYTES_OF_16BIT = 2;
float convertTwoBytesToFloat(uint8_t byte_1st, uint8_t byte_2nd)
{
return static_cast<float>(convertTwoBytesToInt16(byte_1st, byte_2nd));
}
float convertTwoBytesToNormalizedFloat(uint8_t byte_1st, uint8_t byte_2nd)
{
return convertTwoBytesToFloat(byte_1st, byte_2nd)/MAX_16BIT_VAL;
}
std::vector<float> convertBytesToFloats(const std::vector<uint8_t> &bytes)
{
auto num_floats = (bytes.size() / NUM_BYTES_OF_16BIT);
std::vector<float> floats(num_floats);
for(int i = 0; i < num_floats; ++i)
{
floats[i] = convertTwoBytesToFloat(bytes[i*NUM_BYTES_OF_16BIT], bytes[i*NUM_BYTES_OF_16BIT + 1]);
}
return floats;
}
std::vector<float> convertBytesToNormalizedFloats(const std::vector<uint8_t>& bytes)
{
auto normalized_floats = convertBytesToFloats(bytes);
std::transform(normalized_floats.begin(), normalized_floats.end(),
normalized_floats.begin(),
[](float x){return x/MAX_16BIT_VAL;}
);
return normalized_floats;
}
private:
int16_t convertTwoBytesToInt16(uint8_t byte_1st, uint8_t byte_2nd)
{
return byte_2nd | byte_1st;
}
};
// byte_converter_test.cpp
#include "byte_converter.h"
#include <gmock/gmock.h>
#include <vector>
using namespace testing;
class AByteConverter : public ::testing::Test
{
public:
ByteConverter converter;
std::vector<uint8_t> two_bytes{0x01, 0x00}; // 1.0
std::vector<uint8_t> five_bytes
{
0x01, 0x00, // 1
0x02, 0x00, // 2
0x00
};
std::vector<float> floats_of_five_bytes
{
1.0f,
2.0f
};
std::vector<float> norm_floats_of_five_bytes
{
1.0f/ByteConverter::MAX_16BIT_VAL,
2.0f/ByteConverter::MAX_16BIT_VAL
};
};
TEST_F(AByteConverter, ConvertTwoBytesToFloat)
{
float result = converter.convertTwoBytesToFloat(two_bytes[0], two_bytes[1]);
ASSERT_THAT(result, FloatEq(1.0));
}
TEST_F(AByteConverter, ConvertTwoBytesToNormalizedFloat)
{
float normalized_result = converter.convertTwoBytesToNormalizedFloat(two_bytes[0], two_bytes[1]);
ASSERT_THAT(normalized_result, FloatEq(1.0/ByteConverter::MAX_16BIT_VAL));
}
TEST_F(AByteConverter, ConvertsBytesToFloatsWithSizeOfHalfSizeOfBytes)
{
auto floats = converter.convertBytesToFloats(five_bytes);
ASSERT_THAT(floats.size(), Eq(five_bytes.size()/2));
}
TEST_F(AByteConverter, ConvertsBytesToFloats)
{
auto floats = converter.convertBytesToFloats(five_bytes);
ASSERT_THAT(floats, ContainerEq(floats_of_five_bytes));
}
TEST_F(AByteConverter, ConvertsBytesToNormalizedFloatsWithSizeOfHalfSizeOfBytes)
{
auto normalized_floats = converter.convertBytesToNormalizedFloats(five_bytes);
ASSERT_THAT(normalized_floats.size(), Eq(five_bytes.size()/2));
}
TEST_F(AByteConverter, ConvertsBytesToNormalizedFloats)
{
auto normalized_floats = converter.convertBytesToNormalizedFloats(five_bytes);
ASSERT_THAT(normalized_floats, ContainerEq(norm_floats_of_five_bytes));
}
测试驱动开发基础与单元测试
单元测试的组织结构
TDD会产出单元测试。了解如何组织测试有助于你写出更容易被人理解的单元测试。
测试都有相同的流程。首先先设置好合适的条件,然后执行代表要验证的行为的代码,最后验证结果是否和预期一样(有些测试可能要做一些清理工作,例如关闭之前打开的数据库连接)
通常测试的基本构成包括:测试初始化(Arrage)、测试的行为(Act)以及怎样验证结果(Assert)。Arrange、Act 和 Assert(AAA,三A),它能提醒你直观地去组织测试以便快速阅读。
有一个3A类似的助记词:Given-When-Then。即给定(Given)一个上下文、当(When)测试调用一些行为,然后(Then)验证结果。举个例子:
TEST(ASet, IsNoLongerEmpterAfterElementInserted)
{
// Given
std::set<int> a_set;
int val = 0;
// When
a_set.insert(val);
// Then
ASSERT_FALSE(a_set.empty());
}
如果测试用例中所有的测试都需要一条或者更多的相同初始化代码,那么可以将它们写在 fixture 的初始化函数中。在 Google Mock 中,这个函数必须叫 SetUp(覆写了基类的虚函数)。例如:
class ASet : public Test
{
public:
void SetUp() override
{
a_set.insert(val);
}
std::set<int> a_set;
int val = 0;
};
TEST_F(ASet, IsNoLongerEmpterAfterElementInserted)
{
ASSERT_FALSE(a_set.empty());
}
TEST_F(ASet, HasSizeOfOneAfterElementInserted)
{
ASSERT_THAT(a_set.size(), Eq(1));
}
与之类似的,如果有相同的清理工作(关闭数据库连接、释放内存等等),可以覆写 TearDown。
测试驱动开发周期:红-绿-重构
在做测试开发的时候,要重复一下简短的周期:
- 写一个测试(红)
- 让测试通过(绿)
- 优化设计(重构)

将TDD周期记在脑海里,可以让你习惯两件事情。第一,你需要写一个测试说明代码行为。第二,每个周期都要清理代码。养成这个习惯会使你思想得到解放,进而去思考增量开发中更具有挑战的问题。
另外,一定要恪守TDD开发周期,这能让你集中精力:在红阶段,着力于系统行为的描述;在绿阶段,要重点关注如何快速实现功能;在重构阶段,关心如何提高代码的质量。不能遵守TDD的开发周期会让你开发变得更慢。
测试驱动开发的思维
持有正确的实践心态是成功运用TDD的基础,下面是一些运用TDD时有效的思维方式
增量性
TDD以渐进的方式从无到有的开发一个功能完善的系统。TDD支持类似增量思维的小步方法。你可以逐个地处理单元测试,使用测试来定义和验证它们的行为,在任何时间点你都可以停止开发,并且知道你已经构建了测试所描述的系统的行为。我们可以认为,任何没有测试描述的行为都没有实现,而经测试描述的行为则正确且完整地实现了。
此外,用单元测试作为项目进度的衡量单位,帮助你更快的进入到编码的状态中去。当你正在开发一个功能时,却因为紧急的事情被突然打断,等你处理完紧急事情回到键盘前准备继续时,这时候你通常要花不少时间来回忆我刚才开发到哪了?如果你遵循TDD的开发思维,以增量的形式逐个处理单元测试,那么你可以通过单元测试的状态立马进入编码状态。
测试行为而非方法
TDD初学者常会放一个错就是集中精力去测试成员函数。“我们实现了一个Add方法,那么再写一个TEST(AClassCollection, Add)的测试”。Add虽然只是一个方法,但它却可能有多中不同的行为,比如 Add 增加了size、Add之后容器不再为空,再或者Add会忽略重复的数据。如果你将这些行为的验证都塞进一个单元测试中,此时,测试就没有文档价值了,同时,理解一个测试要花费的时间也会增加。
相反的,你应该把注意力放在代码行为上。如果加入一个重复的数据会怎样?如果客户传入一个空的数据呢?如果数据是无效的呢?我们就这几个考量做下面几个独立的测试:
TEST(AClassCollection,IgnoresDuplicateElementAdded);
TEST(AClassCollection,UsesDefalutElementWhenEmptyElementAdded);
TEST(AClassCollection,ThrowsExceptionWhenElementNotValidAdded);
使用测试来描述行为
你可以把测试想象成一个示例,用它来描述或者文档化系统中的行为。你可以通过两个方面来理解一个编写良好的测试。第一,测试名称,它概括了特定上下文中系统表现出的行为。第二,测试语句本身,它精炼的展示了一个测试行为。
越是重视TDD的文档功能,越懂得高质量测试的重要性。测试的文档性功能时TDD的附属产物,为了保证在单元测试中的投入能得到良好的回报,必须保证其他人能够很容易的理解单元测试,否则你的单元测试就是在浪费别人的时间。
良好的测试可以通过全面记录系统的行为来节约时间。只要所有测试都通过,那么它就能准确传达系统的行为,也不会过时。
保持简单
当你写一个新的测试,来验证系统行为时,首先应该用你能想到最简单最粗暴的方式来实现这个功能。直到这个简单的方案无法满足新的需求时,再采用另一个稍微更复杂一点的方案来满足需求。
在实际的开发工程中,每次迭代都会交付新特性,其中一些你可能从未考虑过。如果系统不能保持简单,那么这种突如其来的特性可能会让你苦不堪言。为此,最好的防范方法就是保持简单的设计:代码易读、没有冗余、没有所谓的复杂性。具有这些特性可以大大减少维护成本。
高质量测试
FIRST,测试先行
想知道如何写出高质量的测试吗?可以对照 FIRST 原则:
- F,快速(Fast)
- I,独立(Isolated)
- R,可重复(Repeatable)
- S,自我验证(Self-verifing)
- T,及时(Timely)
快速
保持TDD的周期尽量短非常重要。如果测试需要三四秒来编译、链接和运行测试的话,你可以在短时间内获得很多反馈。但试想一下,如果测试集需要两分钟来构建和运行,你会多久运行一次呢?或许十分钟。那如果运行测试集需要20分钟呢?恐怕你一天只会运行几遍
如果没有快速的反馈,你编写的测试会变少,代码重构会更少,从引入问题到发现问题的间隔也会变得更长。因此高质量的测试必须是快速的。有哪些因素会影响测试的速度呢?
第一、构建的开销。C++系统的构建时间是个很大的开销。一些大系统编译、链接的时间需要好几分钟,有时候要更长。大部分构建时间与代码的依赖直接相关。依赖于改动的代码必须重新编译。
如果一个类暴露了大量的接口,那么接口发生变化时必须重新编译使用此类的客户端。或许可以考虑使用 “pointer to implementation”,PIMPL 惯用法。这样就可以随心所欲地修改和创建新的函数了,而不用重新编译公开的接口。
第二、对协作者的依赖。如果测试代码和另一类交互,且这个类调用了外部API(如一个数据库调用),那么必须等待API调用完成。花费几毫秒建立数据库连接,然后执行一次操作,似乎不太会浪费时间。但是如果有成千上万个测试都有这样的开销,那么就要花费数分钟才能运行完所有测试。
因此,应该在单元测试中避免调用外部API,这包括:数据库服务、Web服务、文件的IO等等。这些都会导致你的测试运行速度变慢,关于外部API的测试,应该被归为集成测试,而非单元测试。
有时候你可以只运行测试的集子来加速测试的运行时间。大部分单元测试的工具运行运行整个测试中的一个子集。此外,很多 IDE 提供了更为方便的操作,例如 Clion 中,可以单独运行一个 fixture 或者一个单元测试:

虽然运行测试的子集可以节省时间,但是请记住,运行的测试越少,今后发现问题就会越多,进而也需要更多的时间来修复。
独立
测试应该是独立,只会因为一个原因失败。测试间是彼此独立的,使用静态数据或者全局数据的测试可能会因为旧的数据而失败。
应尽量避免在测试中引入静态数据或全局数据,如果不得已需要这么做,那么应该在测试收尾阶段(TearDown)恢复数据。
可重复
高质量的测试是可重复的,一遍一遍的运行得到的结果总是相同的。
下列原因可能导致测试间隙性失败:
- 静态数据。好的测试不会受到其他测试的影响,如果静态数据可能会使测试失败,那么你在加入或者移除一些测试时,才会看到真正的失败
- 不稳定的外部服务。有些测试依赖于你无法控制因素,例如系统时间、文件系统,数据库等。可以引入测试替身(Mock)来打破这种依赖。
- 程序并发。多线程技术会导致一些不确定的行为,这对单元测试而言是极大的挑战。
自我验证
所谓自我验证就是采用自动化测试,而非手动测试。每个单元测试至少有一个断言,利用断言来完成自动化测试。不要在测试中加入 cout 或者日志来代替断言。
及时
及时编写测试意味着你要先写测试。同样,不要一开始写写一堆测试。相反,每次只写一个测试,甚至在每个测试中只加入一个断言。
也许你会有这样的疑问:在代码完成后写测试和代码完成前写,到底有什么区别?
说实话,如果你是一个没有感情的写代码机器,这两者并没有区别。但由于人为的原因,就产生了区别。首先,一旦写好代码,大多数程序员就认为完成了“真正”的工作。他们自信满满地认为能写出正确的代码,经常满足于一两个简单的手动测试。因此,他们对为写一些测试来证明他们已经知道的东西并不感兴趣。并且,他们也会认为代码编码写得足够好了,于是就很少利用测试整理代码。第二,日程安排压力通常会其主导作用,代码编写完后的事情只会得到短暂的关注。
一个测试一个断言
遵循一个简单的小方法就可以让你测试质量得到提升:尽量保持一个测试一个断言。
测试名称是代码行为的描述,一个测试如果涵盖多个行为,测试名称就不能准确的描述系统行为,并且为了验证多个行为,你通常会写多个断言。
多个断言会将多个行为揉进一个测试,这导致阅读测试的人需要花费更多的时间来理解测试。另一种让人头疼情况是,一个行为出现在多个测试中,当这个行为发生变化时,你需要改动多处,这必然增加了我们重构的成本。
要尽量保持一个测试一个断言。有时候多个断言也是合理的,例如在验证一大堆数据时引入多个断言(对结构体各个成员的判定)
测试私有方法
我们是否要测试私有方法?大多数情况不需要。如果你发现一定要测试私有接口才能及时获得反馈,那么首先请思考下是否能将这些私有接口进行拆分,举个例子,有个相当复杂的类,只有一个公共接口:
class AComplexClass
{
public:
void fun();
private:
void A_fun0();
void A_fun1();
void A_fun2();
void B_fun0();
void B_fun1();
void B_fun2();
};
我们可以将它进行拆分,然后分别对拆分后的类进行测试即可
class AComplexClass
{
public:
void fun();
private:
A a_;
B b_;
};
class A
{
public:
void fun0();
void fun1();
void fun2();
};
class B
{
public:
void fun0();
void fun1();
void fun2();
};
如果拆分也不管有,并且这个私有接口真的困扰了你,那么不要纠结了,把这个接口公有化然后进行测试吧。虽然这破坏了一点点的信息隐蔽的原则,但是我们只是暴露了一个接口,并不是将所有接口公开,这并不会引起太多的麻烦。
不适合TDD的开发场景
TDD的开发方式很棒,它适合大多数的开发场景,但是有些情况,TDD就显得无能无力了。下面为大家总结一些不适用TDD的情况
1. 复杂算法
曾经有人尝试用TDD开发数独算法,但是失败了。数独的玩法非常简单,可以说需求非常明确:在每个空格子上添上一个合适的数字,让它在每行、每列、每个粗线宫都不重复就可以了。但这个看似简单的需求,实现起来却非常困难。
TDD 开发的前提是:我知道这种方法如何工作。如果不知道这个方法如何工作,就无法用TDD去实现它。
因此在开发复杂算法时,首先应该搞清楚算法的原理,当你对算法流程、算法实现都胸有成竹的时候,再考虑用TDD去开发它。
阻碍TDD在开发算法上大展身手的另一个原因是,一些复杂算法的结果难以验证。
举个例子,你现在要开发一个傅里叶变化的模块,输入一些数据,得到傅里叶变换的结果。你花了一些时间,看懂了傅里叶变化的公式,对其实现也有把握,但是在写断言的时候就发现结果的验证太困难了,你可能需要借助matlab或者python来预先得到结果,然后复制结果到断言中。
ok,至少还有matlab和python可以帮助你。但如果连matalb或者python都没有相应的算法模块呢?那么你应该如何验证算法结果?手算吗?我的天哪。
算法模块之间的依赖性会导致另一个棘手的问题:测试依赖性。想象一个算法由好几个模块组成,模块有底层算法,也有上层应用,层层依赖:A <- B <- C。在这里 A 为底层模块,B 依赖于 A,C 又依赖于 B。
如果某一天 A 模块算法输出的结果发生了变化,那么不仅 A 模块的测试要做修改,另外所有直接或者间接依赖于 A 的模块测试都要做修改。
此外,数据驱动的算法也无法用TDD来开发,例如机器学习、深度学习。因为其结果与数据相关,当数据发生变化时,算法行为也会发生变化,这就没法写测试用例了。
2. 物理边界
在开发一些与物理现实世界交互的代码时,TDD似乎不起作用。
例如,假设你被安排写一个控制铃声的程序,当某些事件发生时,程序必须响铃。那么如何测试”响铃“?在自动测试领域,这是个相当困难的问题。但是如果在手动测试领域,你只需要自己触发事件,然后听是否正常响铃就完事了。目前,软件控制着与物理世界的部分让自动化测试显得那么的不切实际,以至于手动测试才是最佳选择。
与GUI相关的内容也不适合TDD,例如前端。可以用MVC等模式将表现层和逻辑层分开,可以对 M 和 C 做TDD,而放任 V,因为view部分的代码测试环境非常难搭,另外,大多数情况都不需要通过测试来获得反馈,刷新就可以了。
3. 难以构建测试的环境
有时候想要写一个测试真的非常困难,试想你正在开发一个模拟小球碰撞的模块,你想写一个测试来验证碰撞后的结果符合你的预期,例如看看碰撞前后的速度变化,位置变化等等。但是这样的测试写起来非常困难:
- 两个小球的初始位置、初速度、碰撞后的速度,都要设置成非常特殊的情况才能写一个测试
- 小球碰撞这个行为虽然很简单明了,但是背后的实现却相当复杂。一开始就引入测试,会导致实现的跨度非常大,不符合TDD中增量的思想
- 即使这个测试通过了,仍然不能信任碰撞的情况。
当你发现难以构建测试环境或者无法增量开发时,你需要冷静一下,过早引入测试会让你束手束脚,并且测试会长时间处于不通过的状态。这一点都不TDD。
总结来说,一切无法快速测试的环境都不适合TDD,快速测试是TDD周期的前提。
关于TDD的研究
有关TDD的有效性和成本已经有很多研究了。下表是个总结
| 作者/年份 |
重要发现 |
| Siniaalto,2017 |
TDD不总是能提高开发效率,特别是在对TDD不熟悉的情况下。但是TDD所生产的代码具有更高的测试覆盖率。 |
| Neil,2017 |
github上使用TDD开发的Java项目非常少,将TDD开发的项目与其他项目进行对比,并没有发现TDD开发的项目有明显的优势。 |
| Wilson,2016 |
TDD能够生产更好质量的代码,但是开发效率不如TLD(开发完再测试) |
| Davide,2016 |
TDD声称的好处可能不是由于其独特的测试先行产生的。但类似于TDD所鼓励的细粒度稳步的增量式开发,可以改善开发质量 |
| Nagappan, 2008 |
TDD消除缺陷是40% ~ 90%,其成本在开发初期多出15% ~ 35% |
| Sanchez,J.C,2007 |
TDD产生的缺陷密度低于行业标准。TDD或许能减少代码复杂度随着软件年限而增长的程度 |
| Bhat,2006 |
TDD的使用可以让代码质量提升,初始成本增加至少15% |
| Siniaalto,2006 |
有些情况,TDD会大幅度提升效率,大概在2/13的情况下回减低生产效率(但会提升代码质量) |
| George,2003 |
TDD开发的代码质量更好(可以多通过18%或者更多的功能测试),且多用16%的开发时间。事后测试的代码测试不够充分 |
一个研究或许不具有说服力,但是大半的研究都显示了相同的结果,为以下两点提供了强有力的证据:
- TDD会开发出质量更高的代码
- TDD会增加原始开发时间
以下几点假设还没有相关研究:
- TDD可以减低长期成本
- TDD产生的测试可以减少回答关于系统行为问题的时间
TDD对我的影响
TDD是一种开发方式,或者说是一种开发习惯。有的人能够接受它,有的人觉得不合适。关键是要去试一试,只有去尝试过了,才有资格去评判它好还是不好。
对于我而言,TDD影响我最深的有两点。第一点,学习过TDD后,测试的概念已经深入我心了。以前,我对测试并没有概念,认为这是QA应该做的事情。但学习过TDD之后,我充分地了解了测试的重要性,并且知道如何编写高质量的测试。第二点,增量开发。以小步增量性地开发复杂的系统,每一步都以最简单粗暴的方法完成需求,并且通过重构来优化设计。增量性的开发思维,减少了预先设计,将所有设计都做了拆分,每次在重构的时候就是一小次设计的过程。预先设计可能会让你陷入思维旋涡,为了追求设计的完美,你可能会思考每一种可能发生的情况,并期望设计出一种可以应对所有情况的软件,但通常预先设计是过度设计,甚至是错误的设计。用增量性地开发方式替代预先设计,这是TDD与传统开发方法最大的区别。
TDD的思想还改变了我的工作模式。以我自己为例子,和大家分享我是如何在开发 Audio SDK 时使用TDD思想,并提高开发的效率。
第一点:无论如何,重构之前先写测试
我进入公司后的第一件事情,就是给我们所有音频算法写demo。当时的出发点非常简单:我想要对现在的音频算法做一些重构,例如提取公共模块,统一接口等等。既然是重构,那么我应该先写好测试,防止在重构的时候引入其他的bug。但是有个问题,就如前面提到的那样,TDD并不适合算法的开发,或者说单元测试不适合算法的验证。另外,音频算法的结果通常需要人去听才能判断是否符合预期,这种有物理边界的情况,自动化测试显得无能无力。
种种迹象表明,这类测试只能放在集成测试或者回归测试当中。因此,我们组内就建立了一个 sample-by-sample 对比机制,用来对比音频算法的结果。
这个对比系统已经运行了好几个月了,结果表明它确实是相当有用的,主要体现在这几个方面:
- 增强我们交付的信心。我们整个团队的代码更新速度是非常快的,两周一个版本,这种快速的版本更新必然会带来代码管理的巨大工作,比如各个分支的合并,解决代码冲突等等。你是否担心过不小心合错分支,或者搞错了代码冲突?大部分人可能都有过类似的顾虑。有了这套对比机制后,对于代码管理的顾虑可以减少不小。每次代码的提交都会生成对比报告,通过报告可以知道音频SDK的核心,音频算法模块,是否是正常的。如果一切都符合预期,那么当前代码就是可交付的。
- 提早暴露隐蔽的bug。通过这个对比机制,我们还抓到过几次非常微妙的算法bug。例如一些变量没有初始化,多次对比的结果出现随机化的差异。当预期不应该出现差异的修改,结果出现了差异,那么我们就应该警觉起来了,很有可能是在代码修改的过程中不小心引入了bug。
- 算法重构更加便利。算法重构提交后,CI会自动运行算法得到结果,还可以和重构前的结果做对比,非常的直观。
第二点:用单元测试来减少沟通成本
单元测试的文档性,可以减少沟通的成本。从我自身的体验来说,TDD 产生的测试确实可以减少回答关于系统行为问题的时间。
想必大家都有跨地合作开发的经历,跨地沟通成本是比较大的,而且合作写代码这件事情也比较麻烦,毕竟代码这东西很难一两句话就说得清楚。但如果我们用单元测试作为辅助手段,你就会发现沟通起来顺畅不少。比如深圳的同事说:嘿,这个模块我写好,你帮忙看看。我:好的,没问题。接着我就去看他写的单元测试。单元测试比起单纯的代码 review 有几个优势:
- 单元测试的标题描述了代码的行为。这一点让我们比较宏观的了解模块的功能和行为,避免代码 review 时陷入细节的旋涡之中。此外,你也可以根据单元测试来估计模块的完成度是多少,是否有某些行为没有被测试。
- 单元测试是独立可运行的最小单元。可运行这一特点比起单纯代码 review 就进步太多了。通过单元测试的组织结构(3A/Given-When-Then)可以了解代码是如何交互的,它们产生的结果是什么。这样的单元测试就是一小个一小个 demo,让你逐步了解如何使用这些代码。因此,你完全可以按照自己的理解对一些变量进行修改,然后给出预期的断言。如果断言都通过了,说明你理解了这部分的代码,就不用揪着同事问为什么这里是这样的呀?这一点还可以帮助你快速的上手开源代码。如果一个开源的代码提供了完备的单元测试,我们就可以通过单元测试知道代码的行为和交互,再配合阅读官方的文档,能够起到事半功倍的效果。
当我们习惯将单元测试作为沟通的辅助手段后,沟通起来就会变得相当有趣,比如
A: 嘿,这种情况你要考虑过吗?
B: 有的,在xxx单元测试里
或者
A: 我期望的代码行为应该是这样的,我把它写到xxx这个测试里
B: 好的,看完那个测试我明白你的意思了,你是想…
再或者
A: 在这种情况下,代码有个bug
B: 好的,我先用单元测试复现这个bug,然后再解决它
没有什么是一个单元测试解决不了的,如果有,那就两个。