1.3.1 机器学习的三个阶段
学习了机器学习的概念后,我们知道机器学习实际上就是计算机通过算法
处理数据并且学得模型的过程。“模型”这个词经常被我们挂在嘴边,但大部
分人仍然不清楚模型是怎么做出来的,模型在计算机里是怎么表示的,对模型
很难有一个具象的认识。实际上模型主要完成转化的工作,帮助我们将一个在
现实中遇到的问题转化为计算机可以理解的问题,这就是我们常说的建模 。
如图1-6所示,在机器学习中生成一个模型的过程包括准备数据、建立模
型以及模型应用三个阶段。准备数据有收集数据、探索数据及数据预处理三个
步骤。对数据进行处理后,在建立模型阶段开始训练模型、评估模型,然后通
过反复迭代优化模型,最终在应用阶段上线投产使用模型,在新数据上完成任
务。
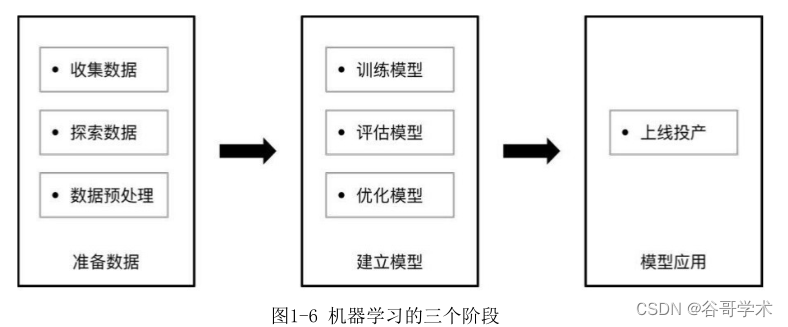
在数据准备阶段,我们首先通过各种渠道收集相关数据,然后对数据、需
求和机器学习的目标进行分析,尤其是对数据进行一些必要的梳理,从而了解
数据的结构、数据量、各特征的统计信息、数据质量情况及分布情况等,以便
后续根据数据的特点选择不同的机器学习算法。除此之外,为了更好地体现数
据分布情况,我们通常选择用可视化的方式把数据的概况展示出来。
通过数据探索,我们可能会发现不少问题,如存在数据缺失、数据不规
范,有异常数据、非数值数据、无关数据和数据分布不均衡等情况。这些问题
会直接影响数据的质量,因而得到的模型误差率会偏高。我们希望把样本数据
的各个变量处理得更规范整齐并且具有表征意?,这样才能最大限度地从原始
数据中提取特征信息以便算法和模型使用。为此,接?来要进行重点工作——
数据预处理,这是机器学习过程中必不可少的关键步骤。生产环境中的数据往
往是原始数据,也就是没有经过加工和处理的数据,这类数据常常存在千奇百
怪的问题,因此,数据预处理的工作通常占据整个机器学习过程的大部分时
间。
接?来就是整个机器学习中的重头戏——建模。训练模型的过程从本质上
来说就是通过大量训练数据找到一个与理想函数最接近的函数 。这是所有机
器学习研究的目标,也是机器学习的本质所在。
最理想的情况?,任何适合使用机器学习去解决的问题,在理论上都能被
一个最优的函数完美解决。但在现实应用中不一定能准确地找到这个函数,所
以我们会去找与这个理想函数较接近的函数。如果一个函数能够满足我们的使
用,那么我们就认为该函数是好的。
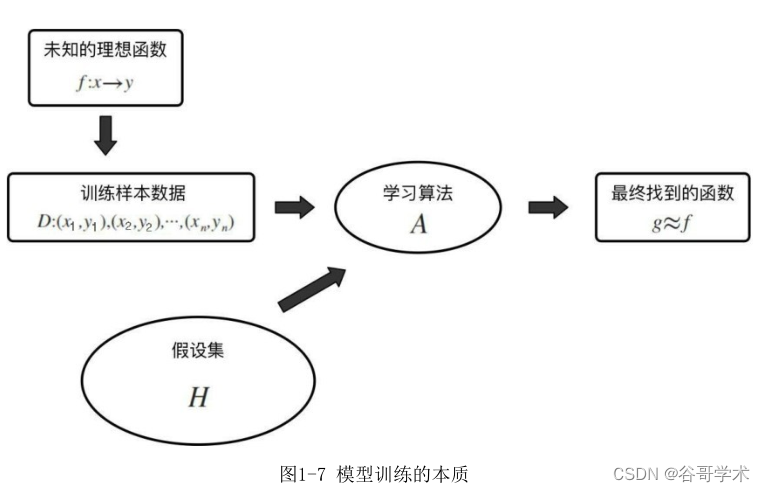
在训练数据的过程中,通常认为存在一个假设函数集合,这个集合包含了
各种各样的假设函数,我们需要做的就是从中挑选出最好的一个,这个假设
函数与理想函数是最接近的 。训练模型的过程,就好比在数学上,我们知道
有一个方程和一些点的坐标,用这些点来求这个方程的未知项,从而得到完整
的方程。但在机器学习中,我们往往很难得到这个完整的方程,所以我们只能
通过各种手段求最接近理想情况?的未知项的值,使得这个结果最接近原本的
方程。图1-7展示了模型训练的本质。
这个过程非常重要,在后续章节真正学习机器学习算法时,我们需要利用
这个过程去理解算法的实现过程、构造损失函数的原因,以及找到所谓“最优
解”的方法。在实际问题求解中,我们将理想函数与实际函数之间的差距称为
损失值,所有的损失值加起来构成一个损失函数。求解最好的实际函数,也就
是求解令损失函数最小化的过程。
1.3.2 模型的训练及选择
一般情况?,不存在在任何情况?表现效果都很好的算法。因此在实际选
择模型时,我们会选用几种不同的方法来训练模型,比较它们的性能,从中选
择最优的方案。在训练模型前,可以将数据集分为训练集和测试集,或将训练
集再细分为训练集和验证集,以便评估模型对新数据的表现。
构建模型后,我们通常使用测试数据测试模型的效果。如果我们对模型的
测试结果满意,就可以用这个模型对新数据进行预测;如果我们对测试结果不
满意,则可以继续优化模型。优化的方法很多,在后面的章节中再?细讨论。
到这里模型训练的工作就完成了。计算机在样本数据上使用一个算法,经
过学习后得到一个模型,然后为模型输入新的待预测的数据,得到最终的预测
结果。
总结上述训练模型的过程,可分为以?三步:(1)根据应用场景、实际
需要解决的问题以及手上的数据,选择一个合适的模型。
(2)构建损失函数。需要依据具体的问题来确定损失函数,例如回归问
题一般采用欧式距离作为损失函数,分类问题一般采用交?熵代价函数作为损
失函数,这部分内容在后续章节会展开讲述。
(3)求解损失函数。求解损失函数是机器学习中的一个难点,因为做到
求解过程又快又准不是一件容易的事情。常用的方法有梯度?降法、最小二乘
法等,这部分内容同样在后续章节会展开讲述。
实际上在每个阶段,产品经理都可以做很多事情以帮助开发工程师提升模
型的效果,因为产品经理最接近业务,最了解一线需求,也就是最了解问题背
景、方案应用场景、业务数据,等等。在整个项目开始之前我们需要确保开发
工程师能够完全理解业务场景,明确模型的目标。在准备数据阶段,我们可以
根据业务经验告诉开发工程师哪些数据是业务同事重点关注的,哪些数据可
能会更有价值,哪些数据之间可能存在关联 。比如在建立一个预测客户贷款
倾向度模型时,我们会根据银行的经验把一些符合贷款申请的条件和规则告诉
开发工程师,以便他们做数据过滤及异常数据的处理。在建模阶段,我们同样
可以根据对业务场景的理解提出模型与数据源优化的方向,让程序开发和场景
应用两个环境能够真正有机地结合起来。