看《准确率98%的深度学习交通标志识别是如何做到的?》这篇文章的时候,发现了udacity的自动驾驶课程。可惜要收费,不过课程project在github上有,那直接做project就好了,不上课了。
那先从Build a Traffic Sign Recognition Program开始吧。
环境准备
官方提供了CPU的docker环境,略不爽,哥的1060吃灰好久,正想用起来。不过可以发现项目里其实也提供了Dockerfile.gpu文件,其实自己build一下就好,但因为万恶的防火墙,网络连接会有问题,而且速度很慢,让人揪心。后来才搞清楚怎么连。
直接export https_proxy其实没用,docker build的时候会进入docker环境里。这时候代理就失效了。
宿主机用ifconfig可以看到有docker0这个网卡,在docker环境里其实就用这个ip来访问宿主机。比如宿主是172.17.0.1,docker里面是172.17.0.2。然后ss设置在172.17.0.1监听,gui-config.json里配上 "shareOverLan": true, socks5模式连接有问题,得换成http。然后改一下Dockerfile,加上正确的export https_proxy应该就可以。
不过我是比较暴力地在宿主机器conda env create好环境,然后拷贝进去docker,最后用sed把conda-meta目录的路径修正一下。之前装好了一个TensorFlow的docker,我就基于这个环境,补全conda env,然后docker commit <CONTAINER ID> <IMAGE>把这个修改版的环境保存一下。
然后实验的时候就用这样来启动
nvidia-docker run -it -p 8888:8888 --volume /home/dinosoft/CarND-Traffic-Sign-Classifier-Project:/notebooks carnd bash
命令行不加bash就直接打开jupyter,这时候你想ctrl+z暂停,然后pip装个东西装不了。
环境有变更的话ctrl+p ctrl+q可以退出docker环境,然后docker ps查看 id,docker commit保存一下即可。
conda env
进入bash之后,记得切环境。不然pip安装新的包安装到其他地方去了。
source activate carnd-term1
source deactivate
jupyter
conda install nb_conda
因为这个notebook太长了,鼠标滚得我蛋疼,需要一个目录之类的东西,方便导航
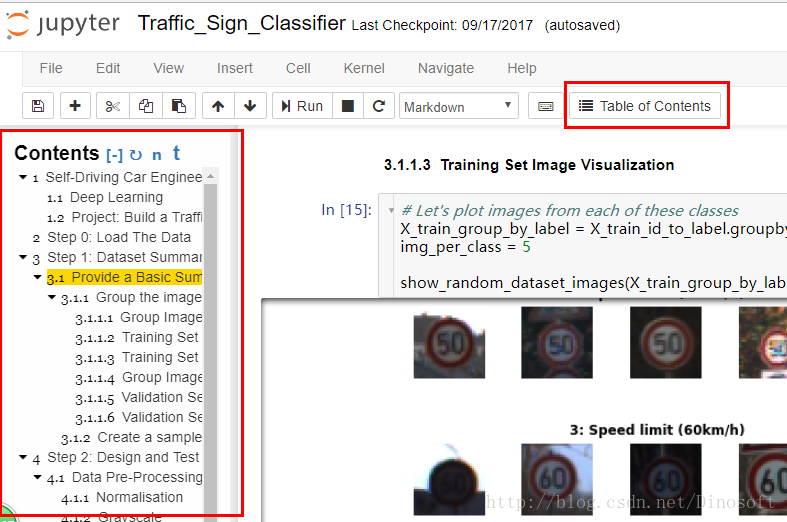
先把https://github.com/ipython-contrib/jupyter_contrib_nbextensions 装上,然后勾选table of content这个插件使其生效。
数据下载
课程材料应该会提供下载链接吧,可惜没交钱。不过还好,最后还是让我找到了。不然就得自己到官网下数据,然后费劲转换。
https://github.com/frankkanis/CarND-Traffic-Sign-Classifier-Project 这里提供了pickle格式的数据下载链接。好心人真多。
求数据的人多,我搬运到百度云吧。链接:https://pan.baidu.com/s/1XSvdVrFFkr0oKvM0JWt46A 密码:nb44
搞这个环境吐了一大口老血,蛋疼。
已有结果分析和实验
https://github.com/kenshiro-o/CarND-Traffic-Sign-Classifier-Project 这里已经有一份做好的代码,现在上班没有很多时间耗,就基于这个来吧。
| method | baseline score | normalised best score | dropout |
|---|
| color | 0.9145(5*5) | 0.9310(3*3) | 0.9754(0.5 3*3) |
| gray | 0.9165(3*3) | 0.9363(5*5) | 0.9755(0.5 3*3) |
| hist_eq(迭代500次) | | 0.9339(3*3) | 0.9775(5*5) |
| aug(迭代2000次) | | | 0.9786(0.5 3*3) |
直方图均衡化和数据增强这种hand-craft操作其实提升有限(对我这种懒人是个好消息),而且作者很trick,偷偷增加了迭代次数。normalization其实对模型效果没有提升,只是可以方便加速收敛(注意这里是在相同的迭代次数(200)的情况下对比的)。因为这点数据,DL很容易就过拟合,只有dropout提升是最明显的。
其他问题的思考(只针对当前场景,不要瞎推广):
Q:颜色对识别的影响
虽然人类对颜色还是比较敏感的,但是结果可以看到,在相同迭代次数下,灰度图效果反而要稍微好一丢丢。
仔细观察可以发现交通标志设计的时候在图案和颜色上都有很强的区分性(不存在形状类似,只是颜色不同的标识),所以在当前场景颜色信息是有点冗余的。不过对于区分标识和背景还是有用的。
Q:类别分布不均匀问题
valid和test集合分布都一样,算准确率的时候也没有对不同类别区分权重,其实就完全不会有问题啦。
Q:归一化
def normalise_images(imgs, dist):
"""
Nornalise the supplied images from data in dist
"""
std = np.std(dist)
mean = np.mean(dist)
return (imgs - mean) / std
原作者是用了这种,没有区分颜色通道。虽然常见都是分3通道做。
因为发现数据图片亮度不一,我试着对每一图片,每个通道单独矫正,发现费了老大劲,没有啥特别效果(乘以255是为了方便直接当作图片显示),人眼觉得看起来费劲,DL不一定看不清啊。
def normalise_images_new(imgs, _):
"""
Nornalise the supplied images from data in dist
"""
result = []
for i in range(imgs.shape[0]):
img = imgs[i]
range_max = np.max(img, axis=(0,1))
range_min = np.min(img, axis=(0,1))
mean = np.mean(img, axis=(0,1))
std = np.std(img, axis=(0,1))
if len(range_max.shape) == 1 and range_max.shape[0] > 1:
tmp = np.zeros(img.shape)
for j in range(range_max.shape[0]):
tmp[:, :, j] = (img[:, :, j] - range_min[j]) / (0.0 + range_max[j]-range_min[j]) * 255
result.append(tmp)
else:
result.append((img - range_min) / (range_max-range_min) * 255)
return np.array( np.clip(result, 0, 255) ).astype(np.uint8)
原作者最后用了Histogram Equalization,这玩意,本质上就是对图像做了线性变换,不过这个线性变换矩阵是对每个图片单独计算的。所以应该不会有大的奇迹发生。
大力出奇迹
这种问题实际中还是用基于现有网络做fine tuning的。用vgg16来试试看。
主要参考了
- https://flyyufelix.github.io/2016/10/08/fine-tuning-in-keras-part2.html
- https://www.kaggle.com/fujisan/use-keras-pre-trained-vgg16-acc-98
vgg要求输入224*224,还得把32*32的缩放一下,结果爆内存了,直接截取1w和1k做train和valid,最开始取了前面1w个样本,不均匀啊,有些label没取到。跑出来的结果让人怀疑人生啊。还好睡觉前找出原因,不然模型一夜就白跑了。
用完整的vgg16会爆显存,只能缩减后面追加的fc层,然后缩小batch size。
from keras.models import Sequential
from keras.optimizers import SGD
from keras.layers import Input, Dense, Convolution2D, MaxPooling2D, AveragePooling2D, ZeroPadding2D, Dropout, Flatten, merge, Reshape, Activation
import cv2
import pickle
from sklearn.metrics import log_loss
import numpy as np
img_rows, img_cols = 224, 224
channel = 3
num_classes = 43
datasets_path = "./datasets/german_traffic_signs/"
models_path = "./models/"
training_file = datasets_path + 'train.p'
validation_file= datasets_path + 'valid.p'
testing_file = datasets_path + 'test.p'
with open(training_file, mode='rb') as f:
train = pickle.load(f)
with open(validation_file, mode='rb') as f:
valid = pickle.load(f)
with open(testing_file, mode='rb') as f:
test = pickle.load(f)
X_train, y_train = train['features'], train['labels']
X_valid, y_valid = valid['features'], valid['labels']
X_test, y_test = test['features'], test['labels']
def normalise_image(X):
result = []
for img in X:
im = cv2.resize(img, (224, 224)).astype(np.float32)
im[:,:,0] -= 103.939
im[:,:,1] -= 116.779
im[:,:,2] -= 123.68
result.append(im/255.0)
return np.array(result)
r_index = np.random.choice(len(X_train), 10000)
X_train=normalise_image(X_train[r_index])
y_train=y_train[r_index]
r_index=np.random.choice(len(X_valid), 1000)
X_valid=normalise_image(X_valid[r_index])
y_valid=y_valid[r_index]
new_y = np.zeros((len(y_valid), num_classes))
new_y[np.arange(len(y_valid)), y_valid] =1
y_valid = new_y.astype(np.int8)
new_y = np.zeros((len(y_train), num_classes))
new_y[np.arange(len(y_train)), y_train] =1
y_train = new_y.astype(np.int8)
X_test=normalise_image(X_test)
new_y = np.zeros((len(y_test), num_classes))
new_y[np.arange(len(y_test)), y_test] =1
y_test = new_y.astype(np.int8)
np.sum(y_valid,axis=0)
np.sum(y_train,axis=0)
from keras import backend as K
K.set_image_dim_ordering('tf')
from keras import applications
base_model = applications.VGG16(weights='imagenet', include_top=False, input_shape=(img_rows, img_cols, channel))
from keras.models import Model
x = base_model.output
x = Flatten()(x)
x = Dense(32, activation='relu')(x)
x= Dropout(0.5)(x)
predictions = Dense(num_classes, activation='softmax')(x)
model = Model(input=base_model.input, output=predictions)
sgd = SGD(lr=1e-3, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(optimizer=sgd, loss='categorical_crossentropy', metrics=['accuracy'])
batch_size = 40
nb_epoch = 100
model.fit(X_train, y_train,
batch_size=batch_size,
nb_epoch=nb_epoch,
shuffle=True,
verbose=1,
validation_data=(X_valid, y_valid),
)
5分钟一个epoch,而且还是用的GPU,用CPU不敢想象。
Train on 10000 samples, validate on 1000 samples
Epoch 1/100
10000/10000 [==============================] - 301s - loss: 3.4573 - acc: 0.0940 - val_loss: 2.3256 - val_acc: 0.3370
Epoch 2/100
10000/10000 [==============================] - 292s - loss: 2.2340 - acc: 0.3346 - val_loss: 1.0591 - val_acc: 0.7060
Epoch 3/100
10000/10000 [==============================] - 288s - loss: 1.3982 - acc: 0.5568 - val_loss: 0.6324 - val_acc: 0.8330
Epoch 4/100
10000/10000 [==============================] - 286s - loss: 0.8322 - acc: 0.7297 - val_loss: 0.1478 - val_acc: 0.9670
Epoch 5/100
10000/10000 [==============================] - 286s - loss: 0.5617 - acc: 0.8179 - val_loss: 0.0939 - val_acc: 0.9710
Epoch 6/100
10000/10000 [==============================] - 285s - loss: 0.4264 - acc: 0.8639 - val_loss: 0.0838 - val_acc: 0.9840
Epoch 7/100
10000/10000 [==============================] - 284s - loss: 0.3375 - acc: 0.8887 - val_loss: 0.0623 - val_acc: 0.9890
Epoch 8/100
10000/10000 [==============================] - 284s - loss: 0.2885 - acc: 0.9068 - val_loss: 0.0460 - val_acc: 0.9910
Epoch 9/100
10000/10000 [==============================] - 283s - loss: 0.2532 - acc: 0.9188 - val_loss: 0.0634 - val_acc: 0.9850
Epoch 10/100
10000/10000 [==============================] - 283s - loss: 0.2624 - acc: 0.9129 - val_loss: 0.0675 - val_acc: 0.9860
Epoch 11/100
10000/10000 [==============================] - 283s - loss: 0.2250 - acc: 0.9275 - val_loss: 0.0374 - val_acc: 0.9900
Epoch 12/100
10000/10000 [==============================] - 284s - loss: 0.1994 - acc: 0.9307 - val_loss: 0.0526 - val_acc: 0.9850
Epoch 13/100
10000/10000 [==============================] - 283s - loss: 0.1900 - acc: 0.9361 - val_loss: 0.0542 - val_acc: 0.9910
Epoch 14/100
10000/10000 [==============================] - 283s - loss: 0.1891 - acc: 0.9360 - val_loss: 0.0565 - val_acc: 0.9860
Epoch 15/100
10000/10000 [==============================] - 284s - loss: 0.1747 - acc: 0.9374 - val_loss: 0.0284 - val_acc: 0.9920
Epoch 16/100
10000/10000 [==============================] - 283s - loss: 0.1716 - acc: 0.9394 - val_loss: 0.0675 - val_acc: 0.9900
Epoch 17/100
10000/10000 [==============================] - 283s - loss: 0.1567 - acc: 0.9456 - val_loss: 0.0299 - val_acc: 0.9930
Epoch 18/100
10000/10000 [==============================] - 283s - loss: 0.1734 - acc: 0.9415 - val_loss: 0.0593 - val_acc: 0.9880
Epoch 19/100
10000/10000 [==============================] - 283s - loss: 0.1601 - acc: 0.9425 - val_loss: 0.0451 - val_acc: 0.9930
Epoch 20/100
10000/10000 [==============================] - 283s - loss: 0.1567 - acc: 0.9463 - val_loss: 0.0492 - val_acc: 0.9920
Epoch 21/100
10000/10000 [==============================] - 283s - loss: 0.1537 - acc: 0.9456 - val_loss: 0.0306 - val_acc: 0.9910
Epoch 22/100
10000/10000 [==============================] - 284s - loss: 0.1501 - acc: 0.9488 - val_loss: 0.0297 - val_acc: 0.9910
Epoch 23/100
10000/10000 [==============================] - 283s - loss: 0.1469 - acc: 0.9509 - val_loss: 0.0341 - val_acc: 0.9920
Epoch 24/100
10000/10000 [==============================] - 283s - loss: 0.1447 - acc: 0.9509 - val_loss: 0.0404 - val_acc: 0.9930
Epoch 25/100
10000/10000 [==============================] - 283s - loss: 0.1538 - acc: 0.9480 - val_loss: 0.0646 - val_acc: 0.9810
Epoch 26/100
10000/10000 [==============================] - 283s - loss: 0.1777 - acc: 0.9432 - val_loss: 0.0411 - val_acc: 0.9890
Epoch 27/100
10000/10000 [==============================] - 283s - loss: 0.1586 - acc: 0.9450 - val_loss: 0.0313 - val_acc: 0.9910
Epoch 28/100
10000/10000 [==============================] - 283s - loss: 0.1373 - acc: 0.9540 - val_loss: 0.0373 - val_acc: 0.9900
Epoch 29/100
10000/10000 [==============================] - 283s - loss: 0.1357 - acc: 0.9526 - val_loss: 0.0480 - val_acc: 0.9910
Epoch 30/100
10000/10000 [==============================] - 283s - loss: 0.1344 - acc: 0.9541 - val_loss: 0.0618 - val_acc: 0.9920
Epoch 31/100
10000/10000 [==============================] - 283s - loss: 0.1303 - acc: 0.9550 - val_loss: 0.0374 - val_acc: 0.9920
Epoch 32/100
10000/10000 [==============================] - 283s - loss: 0.1329 - acc: 0.9537 - val_loss: 0.0370 - val_acc: 0.9910
Epoch 33/100
10000/10000 [==============================] - 283s - loss: 0.1462 - acc: 0.9503 - val_loss: 0.0441 - val_acc: 0.9920
Epoch 34/100
10000/10000 [==============================] - 283s - loss: 0.1386 - acc: 0.9515 - val_loss: 0.0468 - val_acc: 0.9910
Epoch 35/100
10000/10000 [==============================] - 283s - loss: 0.1233 - acc: 0.9572 - val_loss: 0.0655 - val_acc: 0.9910
Epoch 36/100
10000/10000 [==============================] - 283s - loss: 0.1250 - acc: 0.9557 - val_loss: 0.0426 - val_acc: 0.9910
Epoch 37/100
10000/10000 [==============================] - 284s - loss: 0.1303 - acc: 0.9573 - val_loss: 0.0406 - val_acc: 0.9940
Epoch 38/100
10000/10000 [==============================] - 284s - loss: 0.1309 - acc: 0.9542 - val_loss: 0.0481 - val_acc: 0.9930
Epoch 39/100
10000/10000 [==============================] - 284s - loss: 0.1361 - acc: 0.9551 - val_loss: 0.0322 - val_acc: 0.9930
Epoch 40/100
10000/10000 [==============================] - 284s - loss: 0.1254 - acc: 0.9542 - val_loss: 0.0388 - val_acc: 0.9910
Epoch 41/100
10000/10000 [==============================] - 283s - loss: 0.1285 - acc: 0.9550 - val_loss: 0.0677 - val_acc: 0.9890
Epoch 42/100
10000/10000 [==============================] - 283s - loss: 0.1305 - acc: 0.9538 - val_loss: 0.0562 - val_acc: 0.9900
Epoch 43/100
10000/10000 [==============================] - 283s - loss: 0.1254 - acc: 0.9554 - val_loss: 0.0361 - val_acc: 0.9910
Epoch 44/100
10000/10000 [==============================] - 283s - loss: 0.1247 - acc: 0.9559 - val_loss: 0.0583 - val_acc: 0.9920
Epoch 45/100
10000/10000 [==============================] - 283s - loss: 0.1238 - acc: 0.9568 - val_loss: 0.0419 - val_acc: 0.9920
Epoch 46/100
10000/10000 [==============================] - 283s - loss: 0.1222 - acc: 0.9586 - val_loss: 0.0371 - val_acc: 0.9920
Epoch 47/100
10000/10000 [==============================] - 283s - loss: 0.1269 - acc: 0.9570 - val_loss: 0.0371 - val_acc: 0.9920
Epoch 48/100
10000/10000 [==============================] - 283s - loss: 0.1180 - acc: 0.9583 - val_loss: 0.0230 - val_acc: 0.9940
Epoch 49/100
10000/10000 [==============================] - 283s - loss: 0.1276 - acc: 0.9547 - val_loss: 0.0235 - val_acc: 0.9950
Epoch 50/100
10000/10000 [==============================] - 284s - loss: 0.1336 - acc: 0.9507 - val_loss: 0.0384 - val_acc: 0.9910
Epoch 51/100
10000/10000 [==============================] - 283s - loss: 0.1154 - acc: 0.9563 - val_loss: 0.0396 - val_acc: 0.9920
Epoch 52/100
10000/10000 [==============================] - 283s - loss: 0.1136 - acc: 0.9583 - val_loss: 0.0285 - val_acc: 0.9930
Epoch 53/100
10000/10000 [==============================] - 283s - loss: 0.1235 - acc: 0.9550 - val_loss: 0.0367 - val_acc: 0.9920
Epoch 54/100
10000/10000 [==============================] - 284s - loss: 0.1639 - acc: 0.9445 - val_loss: 0.0604 - val_acc: 0.9920
Epoch 55/100
10000/10000 [==============================] - 284s - loss: 0.1226 - acc: 0.9540 - val_loss: 0.0652 - val_acc: 0.9900
Epoch 56/100
10000/10000 [==============================] - 283s - loss: 0.1199 - acc: 0.9551 - val_loss: 0.0615 - val_acc: 0.9890
Epoch 57/100
10000/10000 [==============================] - 283s - loss: 0.1217 - acc: 0.9561 - val_loss: 0.0532 - val_acc: 0.9930
Epoch 58/100
10000/10000 [==============================] - 283s - loss: 0.1266 - acc: 0.9524 - val_loss: 0.0412 - val_acc: 0.9920
Epoch 59/100
10000/10000 [==============================] - 283s - loss: 0.1225 - acc: 0.9542 - val_loss: 0.0455 - val_acc: 0.9910
Epoch 60/100
10000/10000 [==============================] - 283s - loss: 0.1247 - acc: 0.9544 - val_loss: 0.0527 - val_acc: 0.9910
Epoch 61/100
10000/10000 [==============================] - 283s - loss: 0.1144 - acc: 0.9571 - val_loss: 0.0499 - val_acc: 0.9910
Epoch 62/100
10000/10000 [==============================] - 283s - loss: 0.1191 - acc: 0.9549 - val_loss: 0.0404 - val_acc: 0.9920
Epoch 63/100
10000/10000 [==============================] - 283s - loss: 0.1153 - acc: 0.9579 - val_loss: 0.0271 - val_acc: 0.9940
Epoch 64/100
10000/10000 [==============================] - 283s - loss: 0.1130 - acc: 0.9596 - val_loss: 0.0356 - val_acc: 0.9910
Epoch 65/100
10000/10000 [==============================] - 283s - loss: 0.1173 - acc: 0.9570 - val_loss: 0.0322 - val_acc: 0.9930
Epoch 66/100
10000/10000 [==============================] - 283s - loss: 0.1114 - acc: 0.9582 - val_loss: 0.0447 - val_acc: 0.9920
Epoch 67/100
10000/10000 [==============================] - 283s - loss: 0.1067 - acc: 0.9585 - val_loss: 0.0441 - val_acc: 0.9930
Epoch 68/100
10000/10000 [==============================] - 283s - loss: 0.1175 - acc: 0.9573 - val_loss: 0.0483 - val_acc: 0.9910
Epoch 69/100
10000/10000 [==============================] - 283s - loss: 0.1278 - acc: 0.9542 - val_loss: 0.0528 - val_acc: 0.9890
Epoch 70/100
10000/10000 [==============================] - 284s - loss: 0.1171 - acc: 0.9575 - val_loss: 0.0401 - val_acc: 0.9910
Epoch 71/100
10000/10000 [==============================] - 283s - loss: 0.1147 - acc: 0.9578 - val_loss: 0.0601 - val_acc: 0.9910
Epoch 72/100
10000/10000 [==============================] - 283s - loss: 0.1237 - acc: 0.9542 - val_loss: 0.0594 - val_acc: 0.9910
Epoch 73/100
10000/10000 [==============================] - 283s - loss: 0.1182 - acc: 0.9564 - val_loss: 0.0396 - val_acc: 0.9920
Epoch 74/100
10000/10000 [==============================] - 283s - loss: 0.1121 - acc: 0.9590 - val_loss: 0.0332 - val_acc: 0.9910
Epoch 75/100
10000/10000 [==============================] - 283s - loss: 0.1171 - acc: 0.9571 - val_loss: 0.0293 - val_acc: 0.9910
Epoch 76/100
10000/10000 [==============================] - 283s - loss: 0.1153 - acc: 0.9574 - val_loss: 0.0464 - val_acc: 0.9900
Epoch 77/100
10000/10000 [==============================] - 283s - loss: 0.1058 - acc: 0.9601 - val_loss: 0.0311 - val_acc: 0.9910
Epoch 78/100
10000/10000 [==============================] - 283s - loss: 0.1139 - acc: 0.9572 - val_loss: 0.0489 - val_acc: 0.9900
Epoch 79/100
10000/10000 [==============================] - 283s - loss: 0.1071 - acc: 0.9601 - val_loss: 0.0509 - val_acc: 0.9900
Epoch 80/100
10000/10000 [==============================] - 283s - loss: 0.1049 - acc: 0.9618 - val_loss: 0.0557 - val_acc: 0.9920
Epoch 81/100
10000/10000 [==============================] - 284s - loss: 0.1109 - acc: 0.9592 - val_loss: 0.0501 - val_acc: 0.9920
Epoch 82/100
10000/10000 [==============================] - 284s - loss: 0.1159 - acc: 0.9593 - val_loss: 0.0435 - val_acc: 0.9900
Epoch 83/100
10000/10000 [==============================] - 283s - loss: 0.1137 - acc: 0.9591 - val_loss: 0.0284 - val_acc: 0.9930
Epoch 84/100
10000/10000 [==============================] - 284s - loss: 0.1114 - acc: 0.9566 - val_loss: 0.0393 - val_acc: 0.9900
Epoch 85/100
10000/10000 [==============================] - 284s - loss: 0.1057 - acc: 0.9602 - val_loss: 0.0396 - val_acc: 0.9920
Epoch 86/100
10000/10000 [==============================] - 284s - loss: 0.1147 - acc: 0.9606 - val_loss: 0.0426 - val_acc: 0.9890
Epoch 87/100
10000/10000 [==============================] - 284s - loss: 0.1142 - acc: 0.9570 - val_loss: 0.0327 - val_acc: 0.9920
Epoch 88/100
10000/10000 [==============================] - 284s - loss: 0.1092 - acc: 0.9592 - val_loss: 0.0295 - val_acc: 0.9920
Epoch 89/100
10000/10000 [==============================] - 284s - loss: 0.1121 - acc: 0.9588 - val_loss: 0.0295 - val_acc: 0.9940
Epoch 90/100
10000/10000 [==============================] - 284s - loss: 0.1082 - acc: 0.9610 - val_loss: 0.0423 - val_acc: 0.9930
Epoch 91/100
10000/10000 [==============================] - 284s - loss: 0.1028 - acc: 0.9617 - val_loss: 0.0374 - val_acc: 0.9930
Epoch 92/100
10000/10000 [==============================] - 284s - loss: 0.1095 - acc: 0.9612 - val_loss: 0.0410 - val_acc: 0.9920
Epoch 93/100
10000/10000 [==============================] - 284s - loss: 0.1073 - acc: 0.9619 - val_loss: 0.0321 - val_acc: 0.9940
Epoch 94/100
10000/10000 [==============================] - 284s - loss: 0.1187 - acc: 0.9570 - val_loss: 0.0492 - val_acc: 0.9930
Epoch 95/100
10000/10000 [==============================] - 284s - loss: 0.1125 - acc: 0.9577 - val_loss: 0.0597 - val_acc: 0.9930
Epoch 96/100
10000/10000 [==============================] - 284s - loss: 0.1057 - acc: 0.9602 - val_loss: 0.0451 - val_acc: 0.9920
Epoch 97/100
10000/10000 [==============================] - 283s - loss: 0.1047 - acc: 0.9600 - val_loss: 0.0460 - val_acc: 0.9930
Epoch 98/100
10000/10000 [==============================] - 284s - loss: 0.1155 - acc: 0.9559 - val_loss: 0.0626 - val_acc: 0.9900
Epoch 99/100
10000/10000 [==============================] - 284s - loss: 0.1166 - acc: 0.9563 - val_loss: 0.0354 - val_acc: 0.9930
Epoch 100/100
10000/10000 [==============================] - 284s - loss: 0.1087 - acc: 0.9596 - val_loss: 0.0300 - val_acc: 0.9930
model.save('traffic_signs.h5')
from keras.models import load_model
model = load_model('traffic_signs.h5')
predictions_test = model.evaluate(X_test, y_test, batch_size=32, verbose=1)
[0.058963652333059884, 0.99144893111638954]
loss 0.0589, accuracy 99.144% 这样才对嘛。
predicted_y = np.argmax(model.predict(X_test, batch_size=32, verbose=1), axis=1)
groundtruth_y = np.argmax(y_test, axis=1)
diff_idx= np.equal( np.array(predicted_y), ( np.array(groundtruth_y)))
predicted_y[diff_idx == False]
groundtruth_y[diff_idx == False]
所以project里用32*32和比较小的网络来训练是对的,网络一大确实很麻烦,特别是没有牛X的机器可以用。
继续优化的话,可以把其他train数据也用上,不过训练一次要一晚上,不玩了。当然了,图片augment也能搞搞,看了一些分错的例子,应该有点帮助的。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)