1.Linux查看一个目录下文件占用多少空间
du -sh path
我们有个系统每天要下载数据,为了检查下载数据是否正常,需要查看下载数据目录大小,因为每天的数据都差不多,如果变化太大就说明不正常。查看目录大小的命令是du(当然也可以查看文件大小),例如:du ems_data,就是查看ems_data目录下各子目录的大小;du,就是查看当前目录下各子目录的大小;du *,就是查看当前目录下各子目录和文件的大小。
为了提高查看效果,我们需要对结果进行排序,因为du的命令结果很乱,例如:
从大到小排列:du ems_data | sort -nr
按目录名排列:du ems_data | sort +1 -2
选出排在前面的10个:du ems_data | sort -rn | head
选出排在后面的10个:du ems_data | sort -rn | tail
当前目录的大小:du -sh .
===================================================
附:linux中du命令参数的用法,并用示例进一步说明其使用方法。
Du命令功能说明:统计目录(或文件)所占磁盘空间的大小。
语 法:du [-abcDhHklmsSx] [-L <符号连接>][-X <文件>][--block-size][--exclude=<目录或文件>] [--max-depth=<目录层数>][--help][--version][目录或文件]
常用参数:
-a或--all 为每个指定文件显示磁盘使用情况,或者为目录中每个文件显示各自磁盘使用情况。
-b或--bytes 显示目录或文件大小时,以byte为单位。
-c或--total 除了显示目录或文件的大小外,同时也显示所有目录或文件的总和。
-D或--dereference-args 显示指定符号连接的源文件大小。
-h或--human-readable 以K,M,G为单位,提高信息的可读性。
-H或--si 与-h参数相同,但是K,M,G是以1000为换算单位,而不是以1024为换算单位。
-k或--kilobytes 以1024 bytes为单位。
-l或--count-links 重复计算硬件连接的文件。
-L<符号连接>或--dereference<符号连接> 显示选项中所指定符号连接的源文件大小。
-m或--megabytes 以1MB为单位。
-s或--summarize 仅显示总计,即当前目录的大小。
-S或--separate-dirs 显示每个目录的大小时,并不含其子目录的大小。
-x或--one-file-xystem 以一开始处理时的文件系统为准,若遇上其它不同的文件系统目录则略过。
-X<文件>或--exclude-from=<文件> 在<文件>指定目录或文件。
--exclude=<目录或文件> 略过指定的目录或文件。
--max-depth=<目录层数> 超过指定层数的目录后,予以忽略。
--help 显示帮助。
--version 显示版本信息。
linux中的du命令使用示例:
1> 要显示一个目录树及其每个子树的磁盘使用情况
du /home/linux
这在/home/linux目录及其每个子目录中显示了磁盘块数。
2> 要通过以1024字节为单位显示一个目录树及其每个子树的磁盘使用情况
du -k /home/linux
这在/home/linux目录及其每个子目录中显示了 1024 字节磁盘块数。
3> 以MB为单位显示一个目录树及其每个子树的磁盘使用情况
du -m /home/linux
这在/home/linux目录及其每个子目录中显示了 MB 磁盘块数。
4> 以GB为单位显示一个目录树及其每个子树的磁盘使用情况
du -g /home/linux
这在/home/linux目录及其每个子目录中显示了 GB 磁盘块数。
5>查看当前目录下所有目录以及子目录的大小:
du -h .
“.”代表当前目录下。也可以换成一个明确的路径
-h表示用K、M、G的人性化形式显示
6>查看当前目录下user目录的大小,并不想看其他目录以及其子目录:
du -sh user
-s表示总结的意思,即只列出一个总结的值
du -h --max-depth=0 user
--max-depth=n表示只深入到第n层目录,此处设置为0,即表示不深入到子目录。
7>列出user目录及其子目录下所有目录和文件的大小:
du -ah user
-a表示包括目录和文件
8>列出当前目录中的目录名不包括xyz字符串的目录的大小:
du -h --exclude=’*xyz*’
9>想在一个屏幕下列出更多的关于user目录及子目录大小的信息:
du -0h user
-0(杠零)表示每列出一个目录的信息,不换行,而是直接输出下一个目录的信息。
10>只显示一个目录树的全部磁盘使用情况
du -s /home/linux
注意:参数是多个字符时,前面的减号“–”是两个。
2.如何查看打开文件的所有进程
2010-04-17 00:18
16556人阅读
评论(0)
收藏
举报
lsof命令是什么?
可以列出被进程所打开的文件的信息。被打开的文件可以是
1.普通的文件,2.目录 3.网络文件系统的文件,4.字符设备文件 5.(函数)共享库 6.管道,命名管道 7.符号链接
8.底层的socket字流,网络socket,unix域名socket
9.在linux里面,大部分的东西都是被当做文件的…..还有其他很多
怎样使用lsof
这里主要用案例的形式来介绍lsof 命令的使用
1.列出所有打开的文件:
lsof
备注: 如果不加任何参数,就会打开所有被打开的文件,建议加上一下参数来具体定位
2. 查看谁正在使用某个文件
lsof /filepath/file
3.递归查看某个目录的文件信息
lsof +D /filepath/filepath2/
备注: 使用了+D,对应目录下的所有子目录和文件都会被列出
4. 比使用+D选项,遍历查看某个目录的所有文件信息 的方法
lsof | grep ‘/filepath/filepath2/’
5. 列出某个用户打开的文件信息
lsof -u username
备注: -u 选项,u其实是user的缩写
6. 列出某个程序所打开的文件信息
lsof -c mysql
备注: -c 选项将会列出所有以mysql开头的程序的文件,其实你也可以写成 lsof | grep mysql, 但是第一种方法明显比第二种方法要少打几个字符了
7. 列出多个程序多打开的文件信息
lsof -c mysql -c apache
8. 列出某个用户以及某个程序所打开的文件信息
lsof -u test -c mysql
9. 列出除了某个用户外的被打开的文件信息
lsof -u ^root
备注:^这个符号在用户名之前,将会把是root用户打开的进程不让显示
10. 通过某个进程号显示该进行打开的文件
lsof -p 1
11. 列出多个进程号对应的文件信息
lsof -p 123,456,789
12. 列出除了某个进程号,其他进程号所打开的文件信息
lsof -p ^1
13 . 列出所有的网络连接
lsof -i
14. 列出所有tcp 网络连接信息
lsof -i tcp
15. 列出所有udp网络连接信息
lsof -i udp
16. 列出谁在使用某个端口
lsof -i :3306
17. 列出谁在使用某个特定的udp端口
lsof -i udp:55
特定的tcp端口
lsof -i tcp:80
18. 列出某个用户的所有活跃的网络端口
lsof -a -u test -i
19. 列出所有网络文件系统
lsof -N
20.域名socket文件
lsof -u
21.某个用户组所打开的文件信息
lsof -g 5555
22. 根据文件描述列出对应的文件信息
lsof -d description(like 2)
23. 根据文件描述范围列出文件信息
lsof -d 2-3
3.测试写文件的平均速度
有时候我们在做维护的时候,总会遇到类似于IO特别高,但不能判定是IO瓶颈还是软件参数设置不当导致热盘的问题.这时候通常希望能知道磁盘的读写速度,来进行下一步的决策.
下面是两种测试方法:
(1)使用hdparm命令
这是一个是用来获取ATA/IDE硬盘的参数的命令,是由早期Linux IDE驱动的开发和维护人员 Mark Lord开发编写的( hdparm has been written by Mark Lord <mlord@pobox.com>, the primary developer and maintainer of the (E)IDE driver for Linux, with suggestions from many netfolk).该命令应该也是仅用于Linux系统,对于UNIX系统,ATA/IDE硬盘用的可能比较少,一般大型的系统都是使用磁盘阵列的.
使用方法很简单
# hdparm -Tt /dev/sda
/dev/sda:
Timing cached reads: 6676 MB in 2.00 seconds = 3340.18 MB/sec
Timing buffered disk reads: 218 MB in 3.11 seconds = 70.11 MB/sec
可以看到,2秒钟读取了6676MB的缓存,约合3340.18 MB/sec;
在3.11秒中读取了218MB磁盘(物理读),读取速度约合70.11 MB/sec
(2)使用dd命令
这不是一个专业的测试工具,不过如果对于测试结果的要求不是很苛刻的话,平时可以使用来对磁盘的读写速度作一个简单的评估.
另外由于这是一个免费软件,基本上×NIX系统上都有安装,对于Oracle裸设备的复制迁移,dd工具一般都是首选.
在使用前首先了解两个特殊设备
/dev/null 伪设备,回收站.写该文件不会产生IO
/dev/zero 伪设备,会产生空字符流,对它不会产生IO
测试方法:
a.测试磁盘的IO写速度
# time dd if=/dev/zero of=/test.dbf bs=8k count=300000
300000+0 records in
300000+0 records out
10.59s real 0.43s user 9.40s system
# du -sm /test.dbf
2347 /test.dbf
可以看到,在10.59秒的时间里,生成2347M的一个文件,IO写的速度约为221.6MB/sec;
当然这个速度可以多测试几遍取一个平均值,符合概率统计.
b.测试磁盘的IO读速度
# df -m
Filesystem 1M-blocks Used Available Use% Mounted on
/dev/mapper/VolGroup00-LogVol00
19214 9545 8693 53% /
/dev/sda1 99 13 82 14% /boot
none 506 0 506 0% /dev/shm
# time dd if=/dev/mapper/VolGroup00-LogVol00 of=/dev/null bs=8k
2498560+0 records in
2498560+0 records out
247.99s real 1.92s user 48.64s system
上面的试验在247.99秒的时间里读取了19214MB的文件,计算下来平均速度为77.48MB/sec
c.测试IO同时读和写的速度
# time dd if=/dev/sda1 of=test.dbf bs=8k
13048+1 records in
13048+1 records out
3.73s real 0.04s user 2.39s system
# du -sm test.dbf
103 test.dbf
上面测试的数据量比较小,仅作为参考.
相比两种方法:
前者是linux上专业的测试IDE/ATA磁盘的工具,但是使用范围有局限性;(此试验仅仅使用了测试磁盘IO的参数,对于其他参数及解释参考man手册)
后者可以通用,但不够专业,也没有考虑到缓存和物理读的区分,测试的数据也是仅作参考,不能算是权威.
4.测试IO读写速率
5.程序的局部性原理举例,分析
程序的局部性原理及例子(原)
2012-12-23
id="cproIframe_u1280993" src="http://pos.baidu.com/acom?adn=3&at=103&aurl=&cad=1&ccd=24&cec=UTF-8&cfv=11&ch=0&col=zh-CN&conOP=0&cpa=1&dai=2&dis=0<r=http%3A%2F%2Fwww.google.com.hk%2Furl%3Fsa%3Dt%26rct%3Dj%26q%3D%26esrc%3Ds%26source%3Dweb%26cd%3D2%26ved%3D0CCQQFjAB%26url%3Dhttp%253A%252F%252Fwww.j2men.com%252Findex.php%252Farchives%252F2035%26ei%3DDoQ6VIKjD5L08QW-34KgBw%26usg%3DAFQjCNErBNbvwpj9Ze7BTUPvYlU38Uj9CA%26sig2%3Dlud3bVimfygJ4EqVaJjdBQ<u=http%3A%2F%2Fwww.j2men.com%2Findex.php%2Farchives%2F2035&lunum=6&n=16080069_cpr&pcs=1334x875&pis=10000x10000&ps=269x582&psr=1920x1080&pss=1334x875&qn=326e32c716f6580b&rad=&rsi0=250&rsi1=250&rsi5=4&rss0=%23FFFFFF&rss1=%23FFFFFF&rss2=%230000FF&rss3=%23444444&rss4=%23008000&rss5=&rss6=%23e10900&rss7=&scale=&skin=&td_id=1280993&tn=text_default_250_250&tpr=1413121414389&ts=1&xuanting=0&dtm=BAIDU_DUP2_SETJSONADSLOT&dc=2&di=u1280993" marginwidth="0" marginheight="0" allowtransparency="true" frameborder="0" align="center,center" height="250" scrolling="no" width="250">
任何一个优秀的充满智慧的代码段,总离不开作者渊博的知识以及良好的程序习惯。最近在浏览一位大牛的博客时新学到了关于局部性原理的部分知识,在这里和大家分享一下。
首先什么是局部性原理?
程序的局部性原理是指程序在执行时呈现出局部性规律,即在一段时间内,整个程序的执行仅限于程序中的某一部分。相应地,执行所访问的存储空间也局限于某个内存区域。
另外,根据程序的局部性理论,Denning提出了工作集理论。所谓工作集是指进程运行时被频繁访问的页面集合。显然我们知道只要使程序的工作集全部集中在内存中,就可以大大减少进程的缺页次数;否则会使进程在运行过程中频繁出现缺页中断,从而出现频繁的页面调入/调出现象,造成系统性能的下降,甚至出现“抖动”。(百度百科)
局部性通常有两种形式:
时间局部性(temporal locality)
时间局部性指的是:被引用过一次的存储器位置在未来会被多次引用(通常在循环中)。
空间局部性(spatial locality)
如果一个存储器的位置被引用,那么将来他附近的位置也会被引用。
这部分解释如果对C语言了解的童鞋可能稍微更容易理解一些,举例来说:数组在实际存储时,多数情况下是按行存储的,即先存第一行接着第二行第三行,这样读取的时候,按行读取会好一点,因为根据空间局部性,存储器附近的位置更容易被访问到。
举例如下(java):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
public
static
void
main
(
String
[
]
arg
)
{
int
[
]
[
]
a
=
new
int
[
10000
]
[
10000
]
;
for
(
int
i
=
0
;
i
<
10000
;
i
++
)
for
(
int
j
=
0
;
j
<
10000
;
j
++
)
a
[
i
]
[
j
]
=
10000
;
long
m1
=
0
,
m2
=
0
;
//代码段1
long
ct
=
System
.
currentTimeMillis
(
)
;
for
(
int
i
=
0
;
i
<
10000
;
i
++
)
for
(
int
j
=
0
;
j
<
10000
;
j
++
)
m1
+=
a
[
i
]
[
j
]
;
long
ct2
=
System
.
currentTimeMillis
(
)
-
ct
;
System
.
out
.
println
(
"M1="
+
m1
+
" T="
+
ct2
)
;
//代码段2
long
ct1
=
System
.
currentTimeMillis
(
)
;
for
(
int
j
=
0
;
j
<
10000
;
j
++
)
for
(
int
i
=
0
;
i
<
10000
;
i
++
)
m2
+=
a
[
i
]
[
j
]
;
long
ct22
=
System
.
currentTimeMillis
(
)
-
ct1
;
System
.
out
.
println
(
"M2="
+
m2
+
" T="
+
ct22
)
;
}
|
产生一个一亿大小的整形数组,每个值赋值为10000,代码段1按行读取并求和,结果时间T=40毫秒左右,代码段2按列读取,时间T=2000+毫秒,也就是代码段2是代码段1的50倍。
当然,很小的数组是感觉不到差别的,但我们的目标,总是想要为世界上的每个人服务(你的基数,起码60亿了吧,如果你考虑他们口袋里的money~会更多的),此时,程序的局部性原理,会发挥他的作用的。
开篇
一个优秀的程序、优美的代码,一般都具有良好的局部性。简洁、高效是每个程序员的追求。了解程序的局部性,能编写出更高效的代码。
因为有良好局部性的程序能更好的利用缓存。不过这方面的只是将在以后的文章中介绍。
这篇文章就简单的介绍以下程序的局部性原理。
什么是局部性
局部性通常有两种形式:
时间局部性(temporal locality)
时间局部性指的是:被引用过一次的存储器位置在未来会被多次引用(通常在循环中)。
空间局部性(spatial locality)
如果一个存储器的位置被引用,那么将来他附近的位置也会被引用。
(这样说过于理论了些,在下面的论述中会有例子说明)
数据引用局部性

例子是最好说明问题的途径~
看图a)中的 for 循环,可以判断:循环中的 sum 有良好的时间局部性。因为在for循环结束之前,每次执行循环体都有对 sum 的访问。
而 sum 没有空间局部性。因为sum 是标量(也就是说通过 sum 这个地址(可认为是基址,只能得到一个值)
对于循环体中的 v 则有良好的空间局部性。可以看到 图 b) 中,向量 v 是按顺序存储的(在实际中多数情况也按顺序存储)。
每次访问 v[i]总是在 v[i-1] 的下一个位置。而 v 没有时间局部性。因为每个元素只被访问一次。
步长
向上面例子中按顺序、连续的对 v 的引用,我们称为步长为1的引用模式。同理,在一个连续的向量中,每隔k个元素对向量进行访问,称为步长为k的引用。一般来说,随着步长的增加,空间局部性会下降。
对于多维数组而言,步长对空间局部性的影响显得尤为重要。

考虑上面的例子,是对一个二维数组的求和。
可以看到,for循环体中,是以行序为主序对元素进行遍历。也就是说内层循环先访问第一行的元素,然后第二行。。。
图 b)中是二维数组存储情况。可以看出,在存储器中也是按照行序为主序来进行存储的。也就是说先存储第一行,然后第二行。。。
现在我们已经知道了,本例中存储顺序和访问顺序一致。所以可以该程序对a[][]的引用有良好的空间局部性。
对a[][]实行的是步长为1 的引用。
继续看下面的例子:

可以看出,相对于上面的例子,该例的for 循环中交换了 索引 i j 的位置。
也就是说在对a[][]进行遍历的时候,以列序为主序。即先访问第一列,在访问第二列。。。
而b)中,对a[][]的存储仍是行序为主序。这意味着没访问一个元素,就要跳过k个存储器才能访问下一个。于是得到一个简单的结论:该例中对a[][]的访问是以步长为k 的模式(k 为每行的元素个数)没有良好的时间局部性。
通过上面的例子我们知道:在对向量的访问中,如果访问数序和存储顺序一致,并且是连续访问,那么这种访问具有良好的空间局部性。
取指令的局部性
指令存在于存储器中,cpu 要读指令就必须取出指令。所以也能评价对于取指令的局部性。
在for 循环中,循环体内的指令多次被执行,所以有良好的时间局部性。
循环体中的指令是桉顺序执行的,有良好的空间局部性(指令在存储器中是顺序存放的)。
局部性小结
评价局部性的简单原则:
1、重复引用同一个变量有良好的时间局部性
2、对于步长为k 的引用的程序,步长越小,空间局部性越小。步长为1 的引用具有良好的空间局部性。k越大,空间局部性越差。
3、对于取指令来说、循环有较好的时间和空间局部性。
后记
这篇文章只是简单的介绍了什么是局部性,局部性原理的应有,即为什么有良好局部性的程序有更好的性能,局部性和告诉缓存的关系是如何的,将在后面的文章中介绍。这篇文章且当作后文的铺垫吧。
本人认知有限,如上述文章有不足之处欢迎指正交流。
6.根据结构体中变量地址,就能得到结构体起始地址
转自http://blog.csdn.net/hwz119/article/details/1626537,作者:hwz_119
我们在书写C程序的时候,有时候需要根据结构体成员变量的地址,得到结构体的地址,特别是我们想用C来实现C++的继承特性的时候。
我们对问题的分析如下:
- 输入:一个结构体定义type,这个结构体中某个成员变量的名字member以及它的地址ptr
- 输出:包含此成员变量的结构体的地址
为了便于分析,我们给出一个实例来说明
struct father_t {
int a;
char *b;
double c;
}f;
char *ptr = &(f.b);
//而不是 ptr = f.b; 这里ptr是b的地址,而不是它指向的地址。 |
根据C语言对struct类型的存储特性,我们可以画这么一个图示:
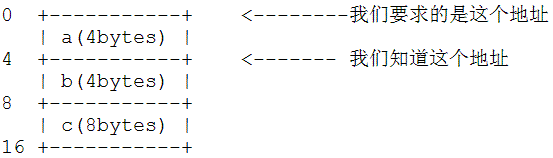
通过分析图示,我们可以看出,我们只需要把当前知道的成员变量的地址ptr,减去它在结构体当中相对偏移4就的到了结构体的地址(ptr-4)。
在linux当中对此有一个很好的宏可以使用,叫做 container_of, 放在 linux/kernel.h当中。它的定义如下所示:
/**
* container_of - cast a member of a structure out to the containing structure
*
* @ptr: the pointer to the member.
* @type: the type of the container struct this is embedded in.
* @member: the name of the member within the struct.
*
*/
#define container_of(ptr, type, member) ({
const typeof( ((type *)0)->member ) *__mptr = (ptr);
(type *)( (char *)__mptr - offsetof(type,member) );})
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER) |
对上面的定义,分析如下:
1. ((type *)0)->member为设计一个type类型的结构体,起始地址为0,编译器将结构体的起始的地址加上此结构体成员变量的偏移得到此结构体成员变 量的偏移地址,由于结构体起始地址为0,所以此结构体成员变量的偏移地址就等于其成员变量在结构体内的距离结构体开始部分的偏移量。即:&(((type *)0)->member)就是取出其成员变量的偏移地址。而其等于其在结构体内的偏移量:即为:(size_t)(& ((type *)0)->member)经过size_t的强制类型转换后,其数值为结构体内的偏移量。该偏移量这里由offsetof()求出。
2.typeof(((type *)0)->member)为取出member成员的变量类型。用其定义__mptr指针。ptr为指向该成员变量的指针。__mptr为member数据类型的常量指针,其指向ptr所指向的变量处。
3. (char*)__mptr转换为字节型指针。(char*)__mptr - offsetof(type,member))用来求出结构体起始地址(为char *型指针),然后(type*)(char*)__mptr - offsetof(type,member))在(type *)作用下进行将字节型的结构体起始指针转换为type *型的结构体起始指针。
这就是从结构体某成员变量指针来求出该结构体的首指针。指针类型从结构体某成员变量类型转换为该结构体类型。
7.利用malloc函数编写内存测试程序,测试当前系统可申请的最大内存大小
分类: C/C++
2013-11-20 20:45
156人阅读
评论(0)
收藏
举报
一般程序中使用malloc()函数进行地址空间的申请,那么malloc()到底最大可以申请多少内存呢?可以利用下面这个小程序来测试malloc最大内存申请数量(当然这个数量跟你系统拥有的内存有关)。
-
#include<stdio.h>
-
#include<stdlib.h>
-
- unsigned int maximum = 0;
-
int main()
- {
- unsigned int alloc_size[] = { 1024 * 1024, 1024, 1};
- int i,count;
- for( i = 0; i < 3; i++ )
- {
- for( count = 1; ; count++)
- {
- void * block = malloc( maximum + alloc_size[i] * count);
- if(block)
- {
- maximum += alloc_size[i] * count;
- free(block);
- }
- else
- {
- break;
- }
- }
- }
- printf("maximum alloc size = %u bytes \n", maximum);
- return 0;
- }