目录
前言
aiohttp简介
aiohttp安装
aiohttp应用
先导包
拿到了批量URL
仿照上一节敲出模板
完善下载单个页面的代码
完整代码
运行效果
总结
前言
在上一节中,我们发现time.sleep()不是异步的,导致我们的异步函数无法按异步执行。实际上,requests模块的网络请求函数,get()、post()等也都不是异步的。所以我们想用它们做异步爬虫与网络请求时,就必须使用异步的HTTP请求,从而让异步函数正常工作。
那么在Python中如何实现异步HTTP请求呢?这就需要用到我们本节要介绍的新模块——aiohttp
aiohttp简介
asyncio可以实现单线程并发IO操作。如果仅用在客户端,发挥的威力不大。如果把asyncio用在服务器端,例如Web服务器,由于HTTP连接就是IO操作,因此可以用单线程+coroutine(协程)实现多用户的高并发支持。
asyncio实现了TCP、UDP、SSL等协议,aiohttp则是基于asyncio实现的HTTP框架。
aiohttp安装
pip install aiohttp
aiohttp应用
我们还是用一个例子来说明异步HTTP的使用方法吧。
加入我们有一组图片想要抓取,已经获得了这一堆图片的URL。
先导包
import asyncio
import aiohttp
要用到异步HTTP请求必然少不了异步I/O,因为网络请求本身就是一种I/O过程。
拿到了批量URL
urls = [
"http://kr.shanghai-jiuxin.com/file/2021/0809/e9c2d265db15c768bd1fca0cb32cfc05.jpg",
"http://kr.shanghai-jiuxin.com/file/2021/0809/f248df8386379735d855d1e56e9baae9.jpg",
"http://kr.shanghai-jiuxin.com/file/2021/0809/ea079076530e5f3e85f1f1090428b6f9.jpg"
]
async def aiodownload(url):
# TODO
# 完成单个页面下载任务
async def main():
# 准备异步协程对象列表
tasks = []
for url in urls:
d = asyncio.create_task(download(url))
tasks.append(d)
# 一次性把所有任务都执行
await asyncio.wait(tasks)
if __name__ == '__main__':
asyncio.run(main())
完善下载单个页面的代码
async def aiodownload(url):
# 发送请求
# 得到图片内容
# 保存到文件
name = url.rsplit("/", 1)[1] # 从右边切, 切一次. 得到[1]位置的内容
async with aiohttp.ClientSession() as session: # requests
async with session.get(url) as resp: # resp = requests.get()
# 请求回来了. 写入文件
# 可以自己去学习一个模块, aiofiles
with open(f"./aiohttp_img/{name}", mode="wb") as f: # 创建文件
f.write(await resp.content.read()) # 读取内容是异步的. 需要await挂起, resp.text()
print(name, "Complete!")
- 先将URL最后的那一段作为图片名称,通过切片得到。
- 再创建一个异步用户对话,它的用法相当于requests模块。
- 异步请求数据,并写入文件,注意也要异步读取,用await挂起,否则异步失效。(也可以学习aiofiles来异步写入文件的方式)
完整代码
# requests.get() 同步的代码 -> 异步操作aiohttp
# pip install aiohttp
import asyncio
import aiohttp
urls = [
"http://kr.shanghai-jiuxin.com/file/2021/0809/e9c2d265db15c768bd1fca0cb32cfc05.jpg",
"http://kr.shanghai-jiuxin.com/file/2021/0809/f248df8386379735d855d1e56e9baae9.jpg",
"http://kr.shanghai-jiuxin.com/file/2021/0809/ea079076530e5f3e85f1f1090428b6f9.jpg"
]
async def aiodownload(url):
# 发送请求
# 得到图片内容
# 保存到文件
name = url.rsplit("/", 1)[1] # 从右边切, 切一次. 得到[1]位置的内容
async with aiohttp.ClientSession() as session: # requests
async with session.get(url) as resp: # resp = requests.get()
# 请求回来了. 写入文件
# 可以自己去学习一个模块, aiofiles
with open(f"./aiohttp_img/{name}", mode="wb") as f: # 创建文件
f.write(await resp.content.read()) # 读取内容是异步的. 需要await挂起, resp.text()
print(name, "Complete!")
async def main():
tasks = []
for url in urls:
tasks.append(aiodownload(url))
await asyncio.wait(tasks)
if __name__ == '__main__':
asyncio.run(main())
运行效果

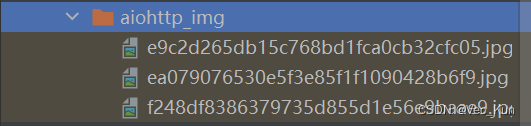
总结
本节我们介绍了异步HTTP请求的方法——借助aiohttp库实现。通过一个简单的实例实践了异步HTTP请求,效率也是极高的,不到一眨眼的功夫,三条URL的内容已经全部保存到本地了。