2021SC@SDUSC
分析完了PaddleDetection的竞赛冠军模型。接下来分析移动端模型
PaddleDetection目前提供一系列针对移动应用进行优化的模型,主要支持以下结构:

其中大量网络应用了ssd算法 我们接下来进行对其中ssd算法的分析
链接介绍:
SSD github : https://github.com/weiliu89/caffe/tree/ssd
SSD paper : https://arxiv.org/abs/1512.02325
SSD 动态PPT: https://docs.google.com/presentation/d/1rtfeV_VmdGdZD5ObVVpPDPIODSDxKnFSU0bsN_rgZXc/pub?start=false&loop=false&delayms=3000&slide=id.g179f601b72_0_51
SSD PPT:http://www.cs.unc.edu/~wliu/papers/ssd_eccv2016_slide.pdf
目标检测|SSD原理与实现:https://zhuanlan.zhihu.com/p/33544892
论文阅读:SSD: Single Shot MultiBox Detector : https://blog.csdn.net/u010167269/article/details/52563573
一、SSD网络总体架构

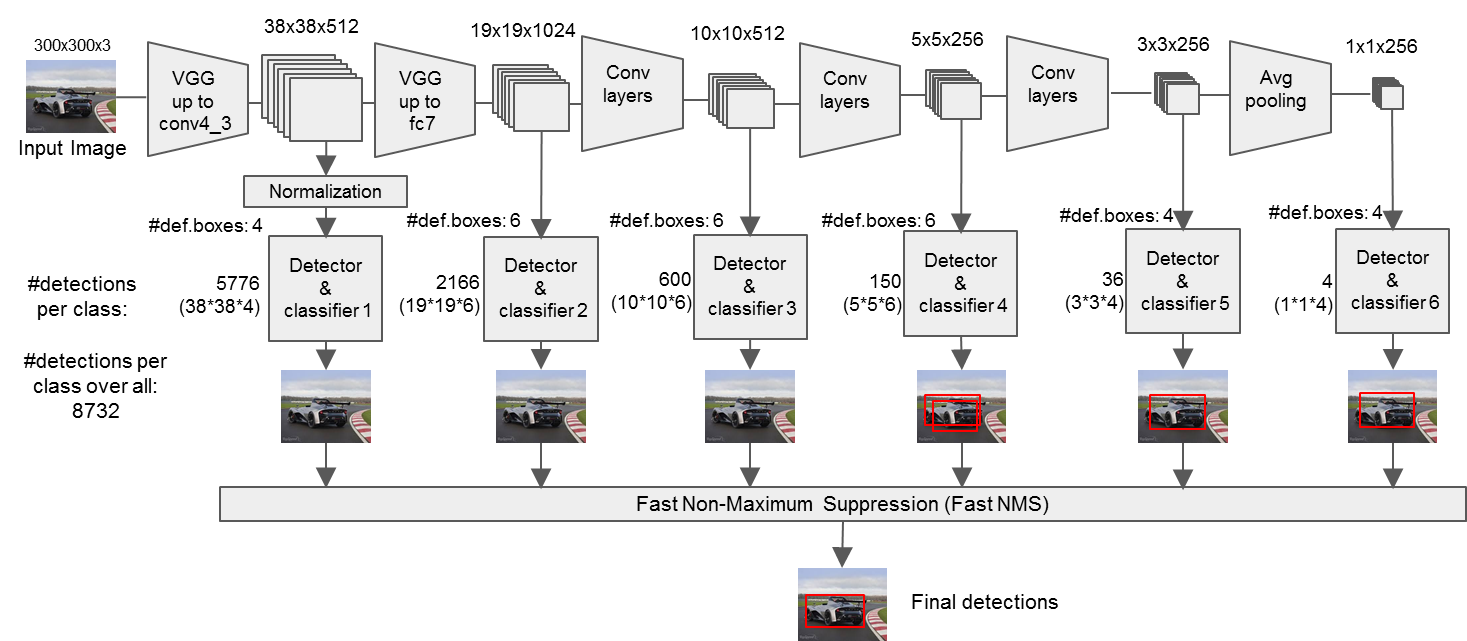
图1 SSD网络架构(精简版)
图2 SSD网络架构(细节版)
SSD采用VGG16作为基础模型,并且做了以下修改,如图1所示
分别将VGG16的全连接层FC6和FC7转换成 3x3 的卷积层 Conv6和 1x1 的卷积层Conv7
去掉所有的Dropout层和FC8层
同时将池化层pool5由原来的 stride=2 的 2x2 变成stride=1的 3x3 (猜想是不想reduce特征图大小)
添加了Atrous算法(hole算法),目的获得更加密集的得分映射
然后在VGG16的基础上新增了卷积层来获得更多的特征图以用于检测
二、算法细节
1、多尺度特征映射
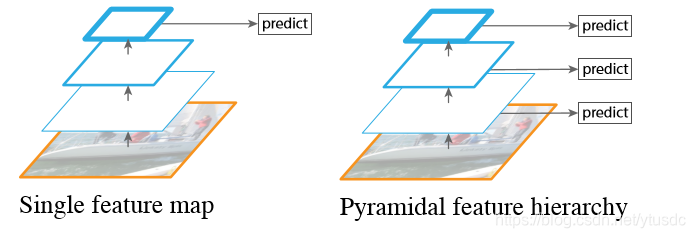
图3 单层feature map预测和多层特征金字塔预测对比
如图3所示,左边的方法针对输入的图片获取不同尺度的特征映射,但是在预测阶段仅仅使用了最后一层的特征映射;而SSD(右图)不仅获得不同尺度的特征映射,同时在不同的特征映射上面进行预测,它在增加运算量的同时可能会提高检测的精度,因为它具有更多的可能性。
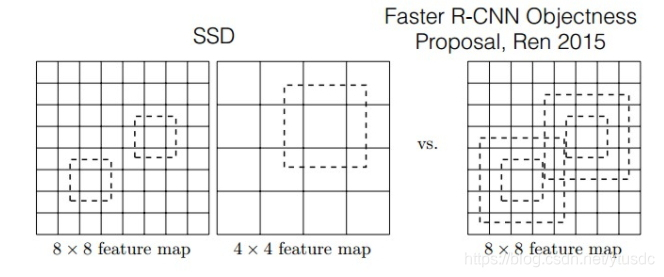
图4 SSD与Faster-rcnn比较
如图4所示,对于BB(bounding boxes)的生成,Faster-rcnn和SSD有不同的策略,但是都是为了同一个目的,产生不同尺度,不同形状的BB,用来检测物体。对于Faster-rcnn而言,其在特定层的Feature map上面的每一点生成9个预定义好的BB,然后进行回归和分类操作来进行初步检测,然后进行ROI Pooling和检测获得相应的BB;而SSD则在不同的特征层的feature map上的每个点同时获取6个(有的层是4个)不同的BB,然后将这些BB结合起来,最后经过NMS处理获得最后的BB。
原因剖析:
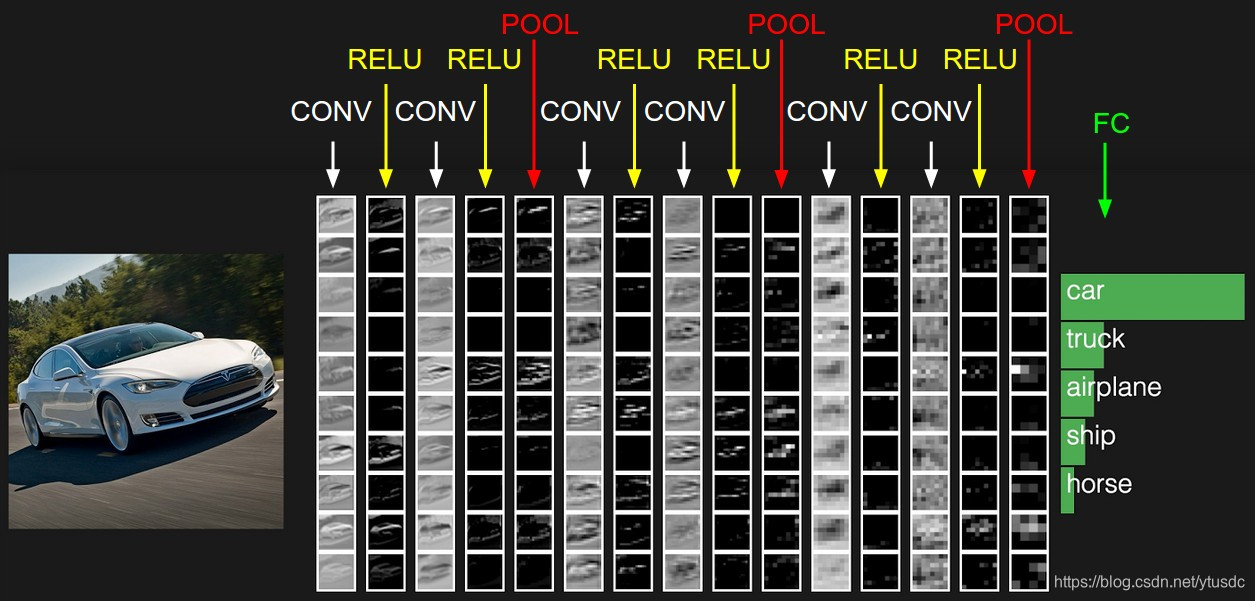
图5 不同卷积层的feature map
如上图所示,输入一幅汽车的图片,我们将其输入到一个卷积神经网络中,在这期间,经历了多个卷积层和池化层,我们可以看到在不同的卷积层会输出不同大小的feature map(这是由于pooling层的存在,它会将图片的尺寸变小),而且不同的feature map中含有不同的特征,而不同的特征可能对我们的检测有不同的作用。总的来说,浅层卷积层对边缘更加感兴趣,可以获得一些细节信息(位置信息),而深层网络对由浅层特征构成的复杂特征更感兴趣,可以获得一些语义信息,对于检测任务而言,一幅图像中的目标有复杂的有简单的,对于简单的patch我们利用浅层网络的特征就可以将其检测出来,对于复杂的patch我们利用深层网络的特征就可以将其检测出来,因此,如果我们同时在不同的feature map上面进行目标检测,理论上面应该会获得更好的检测效果。
2、Default box 和 Prior box(先验框)
图片被送进网络之后先生成一系列 feature map,传统框架会在 feature map(或者原图)上进行 region proposal 提取出可能有物体的部分然后进行分类,这一步可能非常费时,所以 SSD 就放弃了 region proposal,而选择直接生成一系列 defaul box(筛选出prior boxes投入训练),然后以prior box 为初始bbox,将bboxes回归到正确的GT位置上去,预测出的定位信息实际上是回归后的bboxes和回归前的(prior box)的相对坐标。整个过程通过网络的一次前向传播就可以完成。
Defalut box:

图6 SSD的default box
Default box是指在feature map的每个单元格(cell)上都有一系列固定大小的box。SSD 训练图像中的 groundtruth 需要赋予到那些固定输出的 boxes 上,看下节Prior box概念。如上图所示,每个单元格使用了4个不同的Defalut box(虚线框,仔细看格子的中间有比格子还小的一个box),图片a中猫和狗分别采用最适合它们形状的Defalut box来进行训练。假设每个feature map cell有k个default box,那么对于每个default box都需要预测C(包括背景)个类别score和4个offset,因此如果一个feature map的大小是m*n,那么这个feature map就一共有K*m*n个default box,每个default box需要预测4个坐标相关的值和C(包括背景)个类别概率,则在m*n的特征图上面将会产生(C+4)* K * m * n个输出。这些输出个数的含义是:采用3×3的卷积核对该层的feature map卷积时卷积核的个数,包含两部分,实际code是分别用不同数量的3*3卷积核对该层feature map进行卷积:比如数量为C*K的卷积核对应confidence输出,表示每个default box的confidence,也就是类别的概率;数量为4*K的卷积核对应localization输出,表示每个default box回归后的坐标)。作者的实验也表明default box的shape数量越多,效果越好。
Defalut box分析:
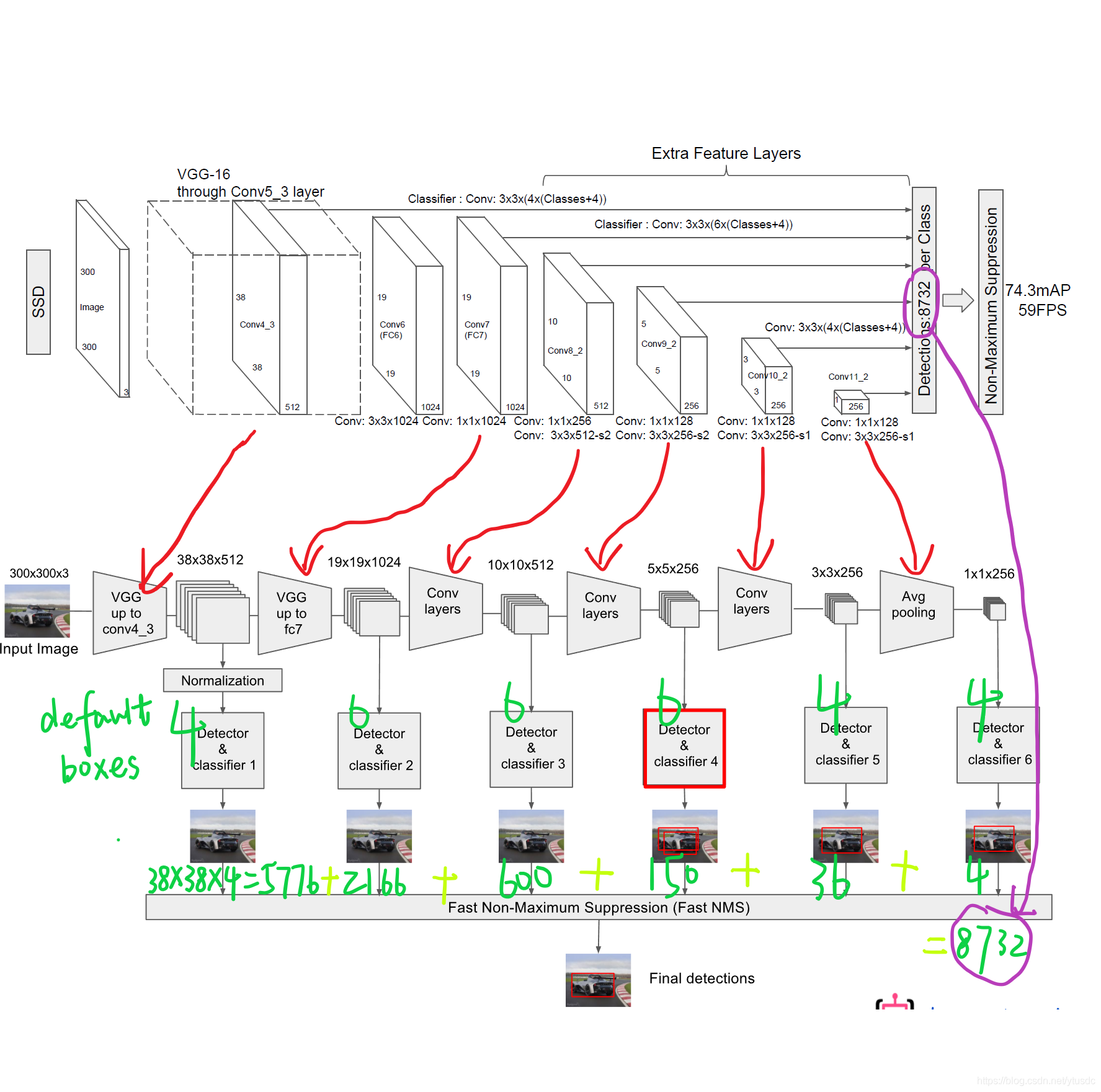
图7 Defalut box分析
SSD的一个核心是同时采用lower和upper的feature maps做检测。SSD中的Defalut box和Faster-rcnn中的anchor机制很相似。就是预设一些目标预选框,后续通过softmax分类+bounding box regression获得真实目标的位置。对于不同尺度的feature map 上使用不同的Default boxes。如上图所示,我们选取的feature map包括38x38x512、19x19x1024、10x10x512、5x5x256、3x3x256、1x1x256。具体怎么得到的看下面的表。我们总共可以获得8732个box,然后我们将这些box送入NMS模块中,获得最终的检测结果。
以上的操作都是在特征图上面的操作,即我们在不同尺度的特征图上面产生很多的bbox,如果映射到原始图像中,我们会获得一个密密麻麻的bbox集合,如下图所示:

图8 原始图像中生成的BB
Prior box概念:
训练中还有一个东西:Prior box,是指实际中选择的要投入训练过程的Default box(每一个feature map cell 不是k个Default box都取)。
也就是说Default box是一种概念,Prior box则是实际的选取。训练中一张完整的图片送进网络获得各个feature map,对于正样本训练来说,需要先将prior box与ground truth box做匹配,匹配成功说明这个prior box所包含的是个目标,但离完整目标的ground truth box还有段距离,训练的目的是保证default box的分类confidence的同时将prior box尽可能回归到ground truth box。
举个列子:假设一个训练样本中有2个ground truth box,所有的feature map中获取的prior box一共有8732个。那可能分别有10、20个prior box能分别与这2个ground truth box匹配上。
Defalut box生成规则:
以feature map上每个点的中点为中心(offset=0.5),生成一些列同心的Defalut box(然后中心点的坐标会乘以step,相当于从feature map位置映射回原图位置)
正方形prior box最小边长为:,最大边长为:
每在prototxt设置一个aspect ratio,会生成2个长方形,长宽为: 和
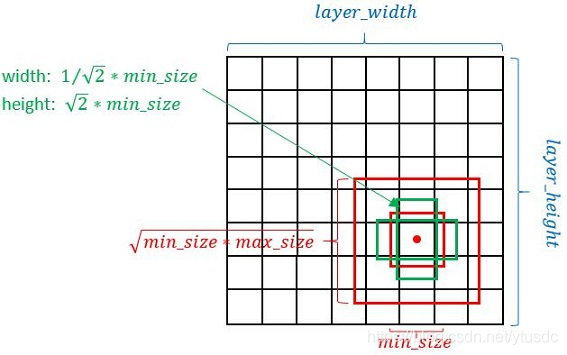
图9 default box的生成
而每个feature map对应Prior box的min_size和max_size由以下公式决定,公式中m是使用feature map的数量(SSD 300中m=6)
使用不同的ratio值,[1, 2, 3, 1/2, 1/3],通过下面的公式计算 default box 的宽度w和高度h:
而对于ratio=1的情况,指定的scale如下所示,即总共有 6 中不同的 default box
第一层feature map对应的min_size=S1,max_size=S2;第二层min_size=S2,max_size=S3;其他类推。在原文中,Smin=0.2,Smax=0.95。但是在SSD 300中prior box设置并不能和paper中上述公式对应:
不过依然可以看出,SSD使用低层feature map检测小目标,使用高层feature map检测大目标,这也应该是SSD的突出贡献了。每一层中每一个点对应的prior box的个数,是由PriorBox这一层的配置文件决定的。其中SSD 300在conv4_3生成prior box的conv4_3_norm_priorbox层prototxt定义如下:
layer {
name: "conv4_3_norm_mbox_priorbox"
type: "PriorBox"
bottom: "conv4_3_norm"
bottom: "data"
top: "conv4_3_norm_mbox_priorbox"
prior_box_param {
min_size: 30.0
max_size: 60.0
aspect_ratio: 2
flip: true
clip: false
variance: 0.1
variance: 0.1
variance: 0.2
variance: 0.2
step: 8
offset: 0.5
}
}
PS: min_size是必须要有的参数,否则不会进入对应的框的生成过程。论文跟实际代码是有一些出入的,Git上也有人在讨论这个,基本都选择无视论文。。。
这里还有一个比较关键的参数,就是step,在conv4-3中设置为8,这个又是怎么来的呢?
实际就是原图与特征图 大小的比值,比如conv4_3 width = 38 ,输入的大小为300,那么scale=7.8,所以这里设置的step=8。这一部分的计算过程可以在 prior_box_layer.cpp的Forward_cpu中看到。
Prior box如何使用:
知道了Prior box如何产生,接下来分析Prior box如何使用。这里以conv4_3为例进行分析。
图10
在conv4_3 feature map网络pipeline分为了3条线路,如上图:
1、经过一次batch norm+一次卷积后,生成了[1, num_class*num_priorbox, layer_height, layer_width]大小的feature用于softmax分类目标和非目标(其中num_class是目标类别,SSD 300的VOC数据集中num_class = 21)
2、经过一次batch norm+一次卷积后,生成了[1, 4*num_priorbox, layer_height, layer_width]大小的feature用于bounding box regression(即每个点一组偏移量[dxmin,dymin,dxmax,dymax])
3、生成了[1, 2, 4*num_priorbox]大小的prior box blob,其中2个channel分别存储prior box的4个点坐标和对应的4个variance。4个variance,这实际上是一种bounding regression中的权重。
后续通过softmax分类+bounding box regression即可从priox box中预测到目标。熟悉Faster RCNN的读者应该对上述过程应该并不陌生。其实pribox box的与Faster RCNN中的anchor非常类似,都是目标的预设框,没有本质的差异。区别是每个位置的prior box一般是4~6个,少于Faster RCNN默认的9个anchor;同时prior box是设置在不同尺度的feature maps上的,而且大小不同。
有一个细节是只有conv4_3层后加了一个Normalization 操作,其他的几层都没有,具体原因参考另一篇文章:Normalization on conv4_3 in SSD :https://blog.csdn.net/ytusdc/article/details/86612355
还有一个细节就是上面prototxt中的4个variance,这实际上是一种bounding regression中的权重。在图4线路(2)中,网络输出[dxmin,dymin,dxmax,dymax],即对应下面代码中bbox;然后利用如下方法进行针对prior box的位置回归:
decode_bbox->set_xmin(
prior_bbox.xmin() + prior_variance[0] * bbox.xmin() * prior_width);
decode_bbox->set_ymin(
prior_bbox.ymin() + prior_variance[1] * bbox.ymin() * prior_height);
decode_bbox->set_xmax(
prior_bbox.xmax() + prior_variance[2] * bbox.xmax() * prior_width);
decode_bbox->set_ymax(
prior_bbox.ymax() + prior_variance[3] * bbox.ymax() * prior_height);
上述代码可以在SSD box_utils.cpp的void DecodeBBox()函数见到。
Permute,Flatten And Concat Layers:
上一节以conv4_3 层分析了如何检测到目标的真实位置,但是SSD 300是使用包括conv4_3在内的共计6个feature maps一同检测出最终目标的。在网络运行的时候显然不能一个feature map单独计算一次softmax socre+box regression(虽然原理如此,但是不能如此实现)。那么多个feature maps如何协同工作?这时候就要用到Permute,Flatten和Concat这3种层了。其中conv4_3_norm_mbox_conf_perm的prototxt定义如下:
layer {
name: "conv4_3_norm_mbox_conf_perm"
type: "Permute"
bottom: "conv4_3_norm_mbox_conf"
top: "conv4_3_norm_mbox_conf_perm"
permute_param {
order: 0
order: 2
order: 3
order: 1
}
}
Permute是SSD中自带的层,Permute相当于交换blob中的数据维度。在正常情况下blob的顺序为:
bottom blob = [batch_num, channel, height, width]
经过conv4_3_norm_mbox_conf_perm后的blob为:
top blob = [batch_num, height, width, channel]
而Flattlen和Concat层都是caffe自带层。所有操作相当于各层输出中把channel放到了最后一个维度然后逆序相乘再总的相加。具体这两个层的细节参考另一篇文章:
深度学习中Concat层和Flatten层作用 :https://blog.csdn.net/ytusdc/article/details/86610897。
加入这几个层的原因分析:
SSD的 XX_conf 和 XX_loc层的输出,是用通道来保存特征向量的,所以这里需要将通道数调整到最后,也就是 permute所做的事情。通过该层后,数据的顺序被换成了 NHWC,再通过 flatten拉成一列。
Feature map合并方法:
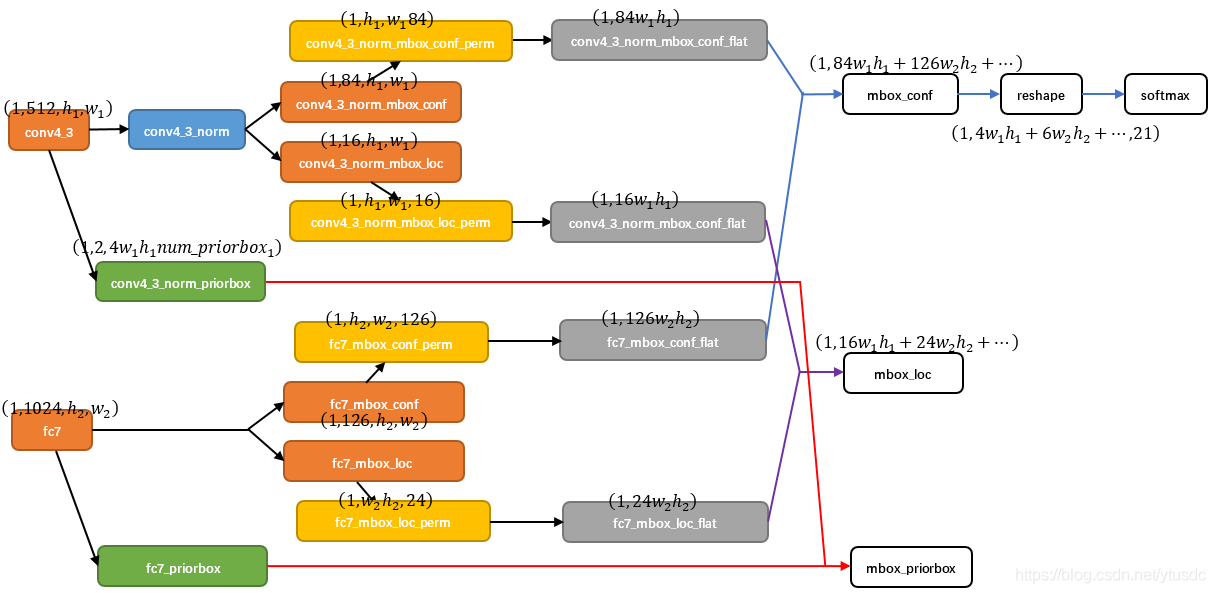
图11 SSD中部分层caffe blob shape变化
现在以conv4_3和fc7为例分析SSD是如何将不同size的feature map组合在一起进行prediction。上图展示了conv4_3和fc7合并在一起的过程中shape变化(其他层类似)。
1、对于conv4_3 feature map,conv4_3_norm_priorbox(priorbox层)设置了每个点共有4个prior box。由于SSD 300共有21个分类,所以conv4_3_norm_mbox_conf的channel值为num_priorbox * num_class = 4 * 21 = 84;而每个prior box都要回归出4个位置变换量[dx,dy,dx,dymax],所以conv4_3_norm_mbox_loc的channel值为4 * 4 = 16。
2、fc7每个点有6个prior box,其他feature map同理。
3、经过一系列图展示的shape变化后,最后拼接成mbox_conf和mbox_loc。而mbox_conf后接reshape,再进行softmax(为何在softmax前进行reshape,Faster RCNN有提及)。
4、最后这些值输出detection_out_layer,获得检测结果。
以上是本篇博客介绍的内容 接下来继续剩余部分的讲解