快速排序
算法思想:快速排序从名字上就可以看出就是为了排序的效率,每次先选择一个关键字key,一般是选择序列的第一个元素或者序列的最后一个元素,将比key值小的元素全部放在左边,将比key值大的放在key值的右边,,然后一层层的递归下去,直至区间中只有一个元素时递归结束,然后在返回上一层,当所有的区间排序完成时,整个排序也就完成了。
快速排序常见单趟排序分类

左右指针法
算法步骤:
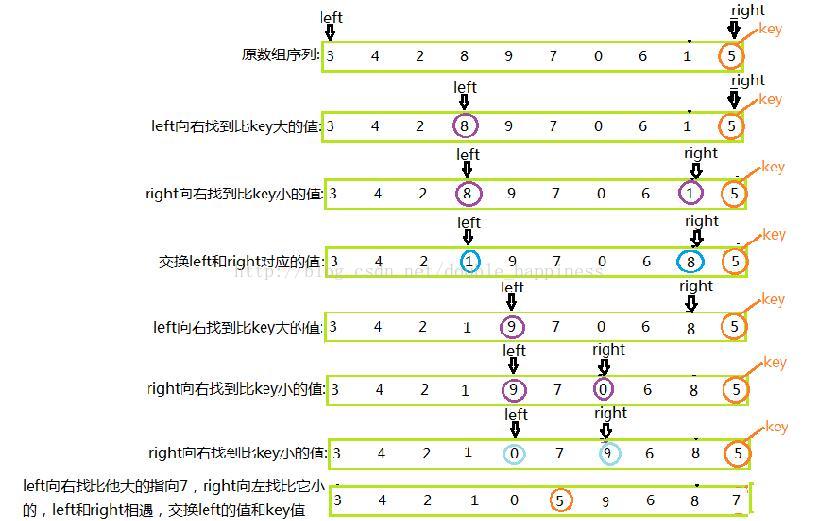
(1)传入一个区间序列,第一个元素下标用left,最后一个元素下标用right,约定下标为right的元素为key;
(2)左指针向右找比它大的元素停下,然后右指针向左找比它小的元素,找到后将left和right对应的元素交换;
(3)继续执行步骤(2),直到左右指针相遇交换key值和left对应的元素,单趟排序停止;
(4)此时比key值小的元素都在key值的左边,比key值大的都在key值的右边;
(5)左右区间继续递归执行(1)(2)(3)(4),直到区间中只有一个元素时排序完成
图示(单趟排序):
整体排序图示:

代码实现:
template<class T>
void Print(T* arr, size_t n)
{
for (int i = 0; i < n; i++)
{
cout << arr[i] << " ";
}
cout << endl;
}
template<class T>
int PartSort(T* arr, int left, int right)
{
int key = arr[right];
while (left < right)
{
while (left < right && arr[left] <= key)
{
++left;
}
swap(arr[left], arr[right]);
while (left < right && arr[right] > key)
{
--right;
}
if (arr[left] != arr[right])
{
swap(arr[left], arr[right]);
}
}
arr[left] = key;
return left;
}
void QuickSort(int* arr, int left, int right)
{
assert(arr);
if (left < right)
{
int div = PartSort(arr, left, right);
QuickSort(arr, left, div - 1);
QuickSort(arr, div + 1, right);
}
}
void TestQuickSort()
{
int arr[10] = { 2, 0, 4, 9, 3, 6, 8, 7, 1, 5 };
QuickSort(arr, 0, sizeof(arr) / sizeof(arr[0]) - 1);
Print<int>(arr, sizeof(arr) / sizeof(arr[0]));
}
运行结果:
挖坑法
算法执行步骤:
(1)首先确定一个关键字key,将其保存在一个临时变量中,同上定义左右指针;
(2)左指针向右找比它大的,找到了就放到key值所在的坑,原来左边的元素位置成为新的坑;
(3)接着右指针向左找比它小的,找到就将它放到上一个坑中,右指针所在的位置形成新的坑;
(4)继续执行步骤(2)(3)直到左右指针相遇,把保留在临时变量中的关键字放到当前的坑中;
(5)将关键字左右分为两个区间,递归继续执行上述步骤,直到区间中只有一个元素时,递归停止开始返回排序结束;
图示举例(单趟排序):

排序总趟数图示:

代码实现:
template<class T>
int PartSort(T* arr, int left, int right)
{
int key = arr[right];
while (left < right)
{
while (left < right && arr[left] <= key)
{
++left;
}
swap(arr[right], arr[left]);
//arr[right] = arr[left];
while (left < right && arr[right] >= key)
{
--right;
}
if (arr[left] != arr[right])
{
swap(arr[left], arr[right]);
}
}
arr[left] = key;
return left;
}
void QuickSort(int* arr, int left, int right)
{
assert(arr);
if (left < right)
{
int div = PartSort(arr, left, right);
QuickSort(arr, left, div - 1);
QuickSort(arr, div + 1, right);
}
}
前后指针法
算法执行步骤:
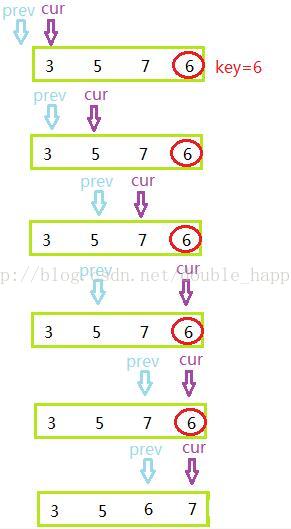
(1)定义一个cur指针指向left,prev指针指向left-1;
(2)cur向右走找比key小的值,找到之后prev++;
(3)如果prev和cur指向的不是同一个位置,就交换prev和cur位置的元素;
(4)重复上述操作,直到cur指向右边界,++prev并交换prev和cur指向的元素;
(5)将key值两边的区间进行递归操作执行上述操作,直到区间中只有一个元素时,排序完成;
图示(单趟排序):
代码示例:
template<class T>
int PartSort(T* arr, int left, int right)
{
int key = arr[right];
int cur = left;
int prev = cur - 1;
while (cur != right)
{
if (arr[cur] < key && ++prev != cur)
{
swap(arr[cur], arr[prev]);
}
++cur;
}
swap(arr[++prev], arr[cur]);
return prev;
}
void QuickSort(int* arr, int left, int right)
{
assert(arr);
if (left < right)
{
int div = PartSort(arr, left, right);
QuickSort(arr, left, div - 1);
QuickSort(arr, div + 1, right);
}
}
void TestQuickSort()
{
int arr[10] = { 2, 0, 4, 9, 3, 6, 8, 7, 1, 5 };
QuickSort(arr, 0, sizeof(arr) / sizeof(arr[0]) - 1);
Print<int>(arr, sizeof(arr) / sizeof(arr[0]));
}
时间复杂度&空间复杂度&稳定性分析
平均时间复杂度:O(N*log(N))----快排看的是平均时间复杂度
最坏时间复杂度:O(N*N)
空间复杂度:O(log(N))
稳定性:不稳定
快排算法优化
(1)三数取中优化
对于选取关键字进行分隔区间时,如果每次选取的都是最大值或者最小值时,就会造成快速排序的最坏场景,通过三数取中法,就可以避免这种情况出现;
代码实现:
int GetMidIndex(int * a, int left, int right) //优化的三数取中
{
int mid = left + ((right - left) >> 1);
//left mid right
if (a[left] < a[mid])
{
if (a[mid] < a[left])
return mid;
else if (a[left]>a[right]) //mid>right
return left;
else
return right;
}
else //left>mid
{
if (a[mid] > a[right])
{
return mid;
}
else if (a[left] < a[right])
{
return left;
}
else
{
return right;
}
}
}
(2)小区间优化算法
小区间优化算按法是对于递归调用的深度开销进行优化的,如果当递归的深度不断的向下展开时,递归调用的次数就会特别多,这时我们可以在这调用其他的排序算法,一般我们调用的是直接插入排序(见排序总结分析)
代码实现(以挖坑法实现):
int GetMidIndex(int * a, int left, int right) //优化的三数取中
{
int mid = left + ((right - left) >> 1);
//left mid right
if (a[left] < a[mid])
{
if (a[mid] < a[left])
return mid;
else if (a[left]>a[right]) //mid>right
return left;
else
return right;
}
else //left>mid
{
if (a[mid] > a[right])
{
return mid;
}
else if (a[left] < a[right])
{
return left;
}
else
{
return right;
}
}
}
template<class T>
void InsertSort(T* arr, size_t n) //插入排序
{
assert(arr);
for (size_t i = 1; i < n; ++i)
{
int end = i - 1; //end用来保存有序区间的最后一个数据的位置
T tmp = arr[i]; //temp用来保存无序区间的第一个数据,也是即将要插入有序区间的数据
while (end >= 0)
{
if (tmp < arr[end])
{
arr[end + 1] = arr[end]; //为temp[i]留出合适的位置
end--;
}
else
break;
}
arr[end+1] = tmp; //将temp插入到合适的位置
}
}
template<class T>
int PartSort(T* arr, int left, int right)
{
int ret = GetMidIndex(arr,left,right);
swap(arr[ret], arr[right]);
int key = arr[right];
while (left < right)
{
while (left < right && arr[left] <= key)
{
++left;
}
swap(arr[right], arr[left]);
//arr[right] = arr[left];
while (left < right && arr[right] >= key)
{
--right;
}
if (arr[left] != arr[right])
{
swap(arr[left], arr[right]);
}
}
arr[left] = key;
return left;
}
void QuickSort(int* arr, int left, int right)
{
assert(arr);
if (left < right)
{
if (right - left < 3) //便于测试选取的区间比较小
{
InsertSort(arr, right - left); //直接调用插入排序
}
int div = PartSort(arr, left, right);
QuickSort(arr, left, div - 1);
QuickSort(arr, div + 1, right);
}
}
void TestQuickSort()
{
int arr[10] = { 2, 0, 4, 9, 3, 6, 8, 7, 1, 5 };
QuickSort(arr, 0, sizeof(arr) / sizeof(arr[0]) - 1);
Print<int>(arr, sizeof(arr) / sizeof(arr[0]));
}
快速排序非递归
快速排序在处理的数据越多时,效率越明显,但是数据量越大所产生的递归调用的函数消耗也会越大,因此最好的解决方法是在上面的优化方法下,直接给出其对应的非递归排序算法;
代码实现:
#include<stack>
void QuickSortNonR(int* arr,int left,int right)
{
stack<int> s;
s.push(right);
s.push(left);
while (!s.empty())
{
int begin = s.top();
s.pop();
int end = s.top();
s.pop();
int div = PartSort(arr, left, right);
if (begin < div - 1)
{
s.push(div-1);
s.push(begin);
}
if (div + 1 < end)
{
s.push(end);
s.push(div + 1);
}
}
}
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)