前言
| 打怪升级:第60天 |
|---|
 |
|
|
一、引入
今天我们要来了解一下操作系统中对文件的操作过程,以及深入理解操作系统对文件的看待方式,那么在开始之前,我们回顾一下自己所学习过的计算机语言中的文件操作方式,这里以C语言为例。
C语言中的文件操作
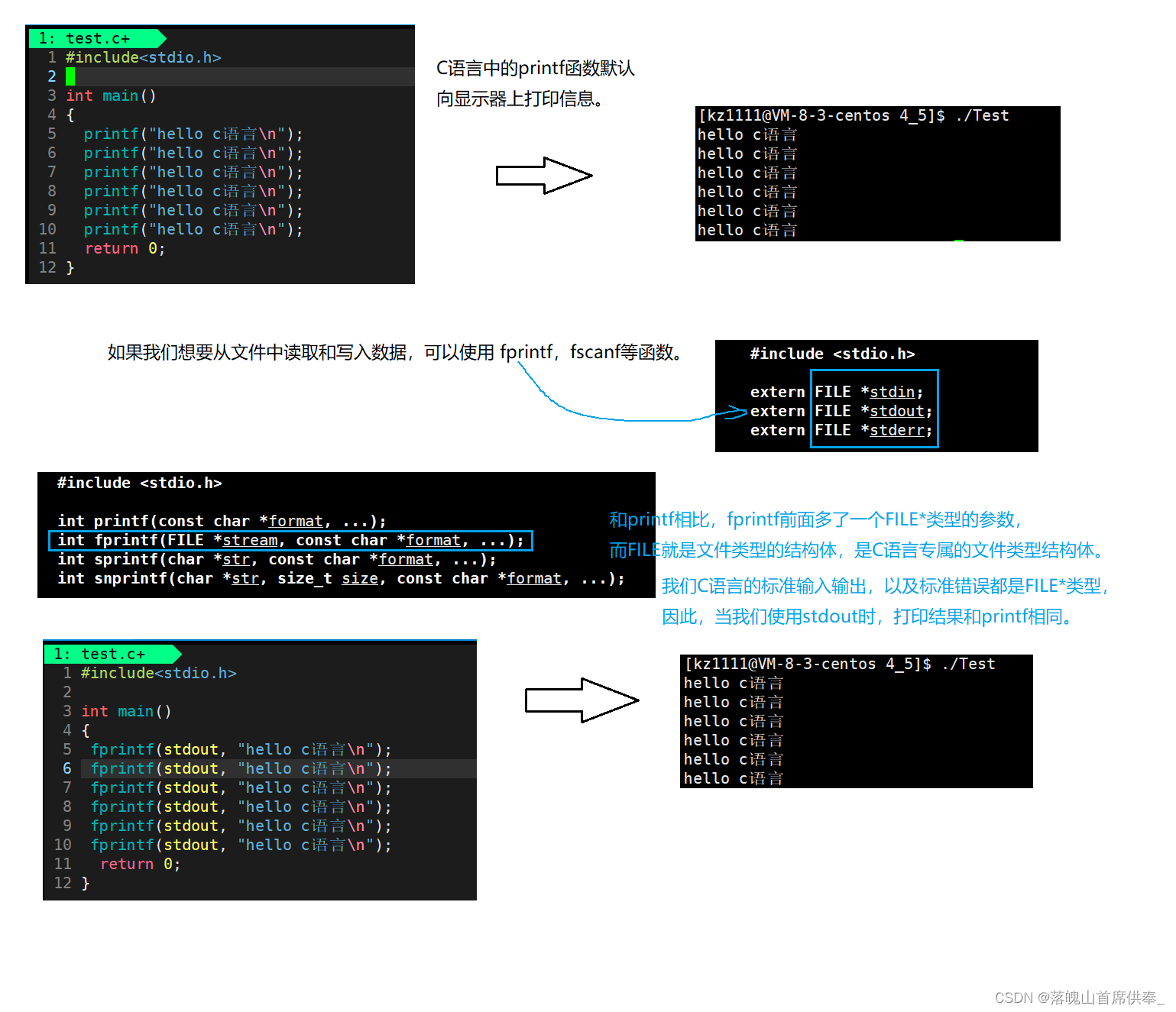
我们对文件的操作不能仅限于这三个标准文件流,那么当我们想要向其他文件中录入和读取数据时就需要了解文件打开和关闭。
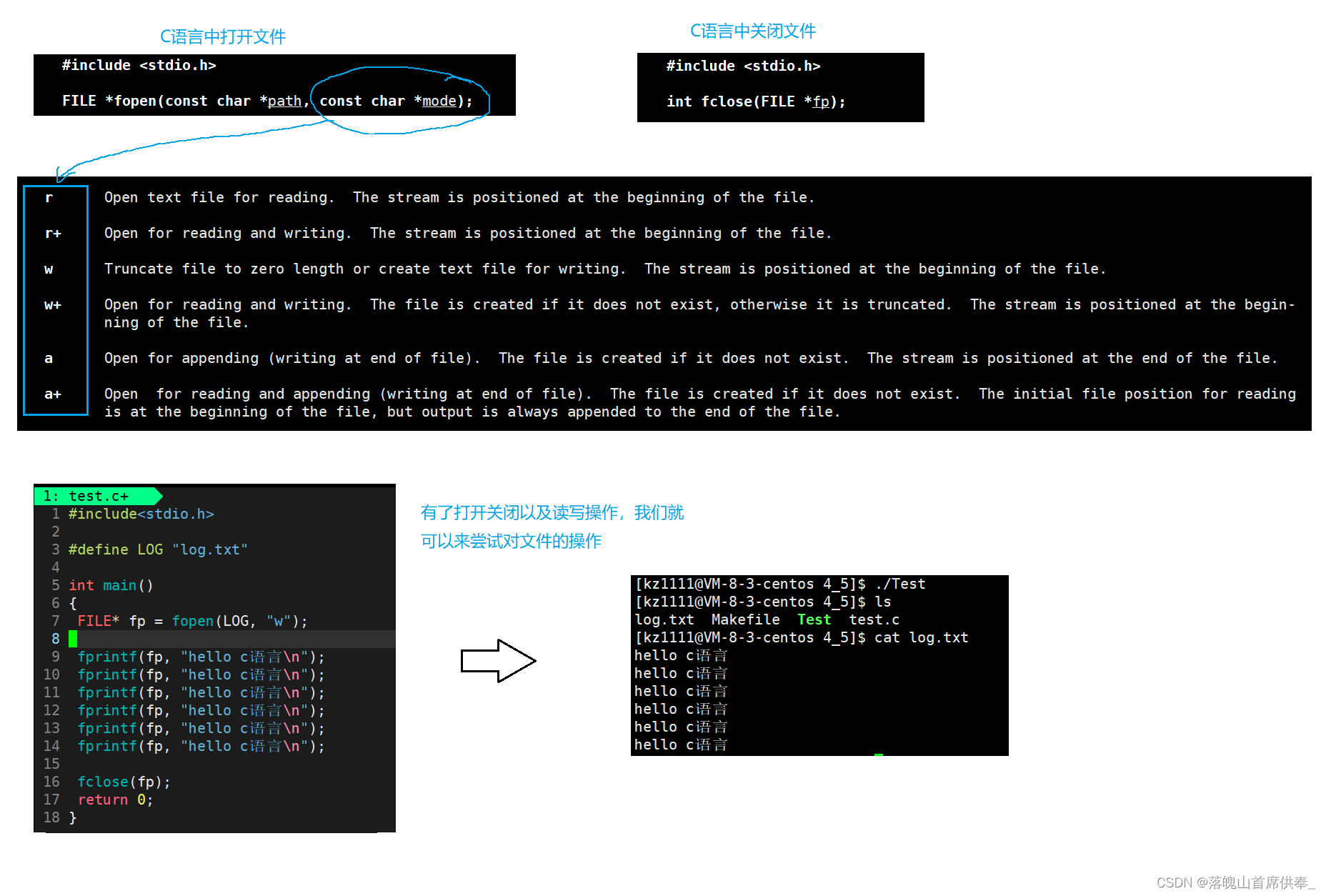
系统文件操作
先来见一见猪跑:
#include<stdio.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>
#define LOG "log.txt"
int main()
{
int fd = open(LOG, O_WRONLY | O_CREAT | O_TRUNC, 0666);
printf("success open file\n");
close(fd);
printf("success close file\n");
return 0;
}
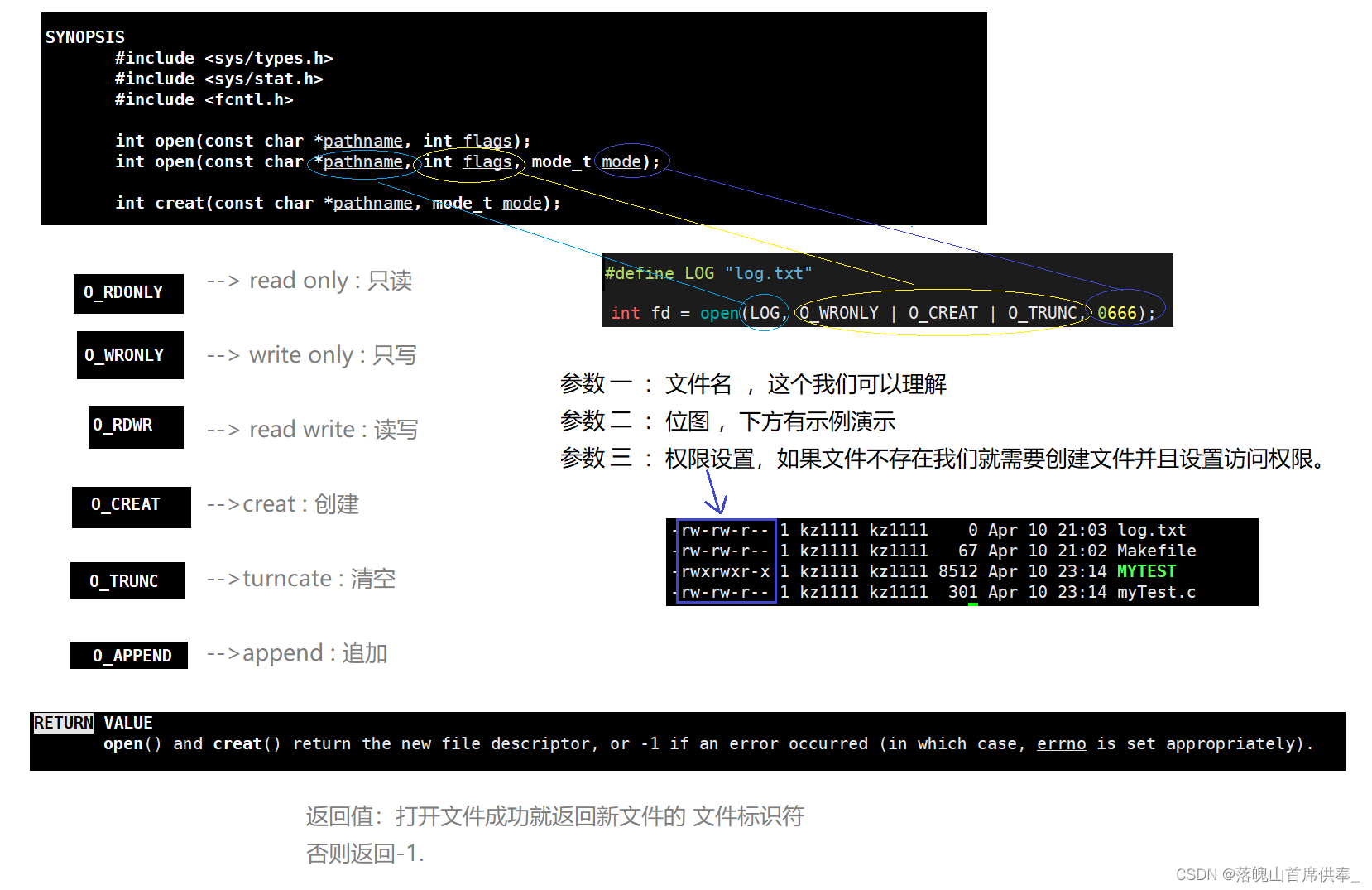
open
位图
以比特位为基本操作单位来存储数据的方式我们称之为位图。
一个整形有32个比特位,就可以表示32种不同的情况;
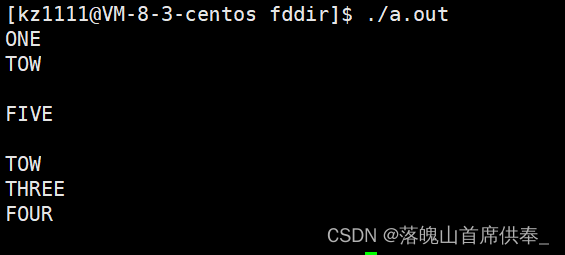
下方我们进行演示:
#include<stdio.h>
#define ONE 0x1
#define TOW 0x2
#define THREE 0x4
#define FOUR 0x8
#define FIVE 0x10
void BitMap(int flags)
{
if(flags & ONE) printf("ONE\n");
if(flags & TOW) printf("TOW\n");
if(flags & THREE) printf("THREE\n");
if(flags & FOUR) printf("FOUR\n");
if(flags & FIVE) printf("FIVE\n");
}
int main()
{
BitMap(ONE | TOW);
printf("\n");
BitMap(FIVE);
printf("\n");
BitMap(TOW | THREE | FOUR);
printf("\n");
return 0;
}

权限
补充一点:第二个open函数最后一个参数为:权限
我们设置的0666,表示它是一个八进制数 – 可读可写不可执行 – 当然这只是初始权限,真正的权限还需要和掩码进行运算,具体运算规则这里不再说明;
我们也可以手动设置该文件的掩码:
umask(0002);
close、write、read
现在我们可以打开文件,我们再来了解一下文件关闭以及读写操作。

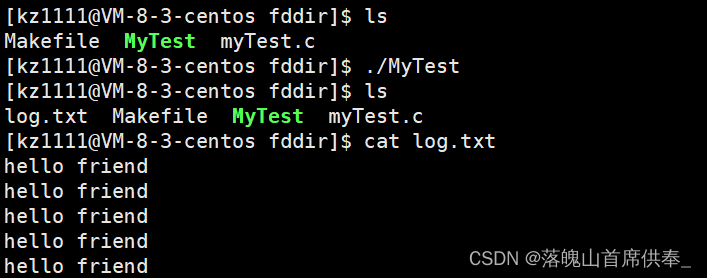
我们来浅浅练习一下:
#include<stdio.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h> // open
#include<unistd.h> // close、write
#include<string.h> // strlen
#define LOG "log.txt"
int main()
{
umask(002);
int fd = open(LOG, O_WRONLY | O_CREAT | O_TRUNC, 0666); // 只写 ,文件没有就创建,打开后清空
const char* ptr = "hello friend\n"; // 我们手动添加一个\n
for(int i=0; i<5; ++i) // 写入5次
write(fd, ptr, strlen(ptr));
close(fd);
return 0;
}
#include<stdio.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>
#include<string.h>
#define LOG "log.txt"
int main()
{
umask(002);
int fd = open(LOG, O_RDWR | O_CREAT | O_TRUNC, 0666); // 可读可写
const char* ptr = "hello friend\n"; // 我们手动添加一个\n
for(int i=0; i<5; ++i) // 写入5次
write(fd, ptr, strlen(ptr));
lseek(fd, SEEK_SET, 0); // 重定位文件读取位置
char str[1024]={0};
read(fd, str, 1023);
printf("%s", str);
close(fd);
return 0;
}
lseek
这里我们就来介绍一个新的函数接口 – 修改文件位置

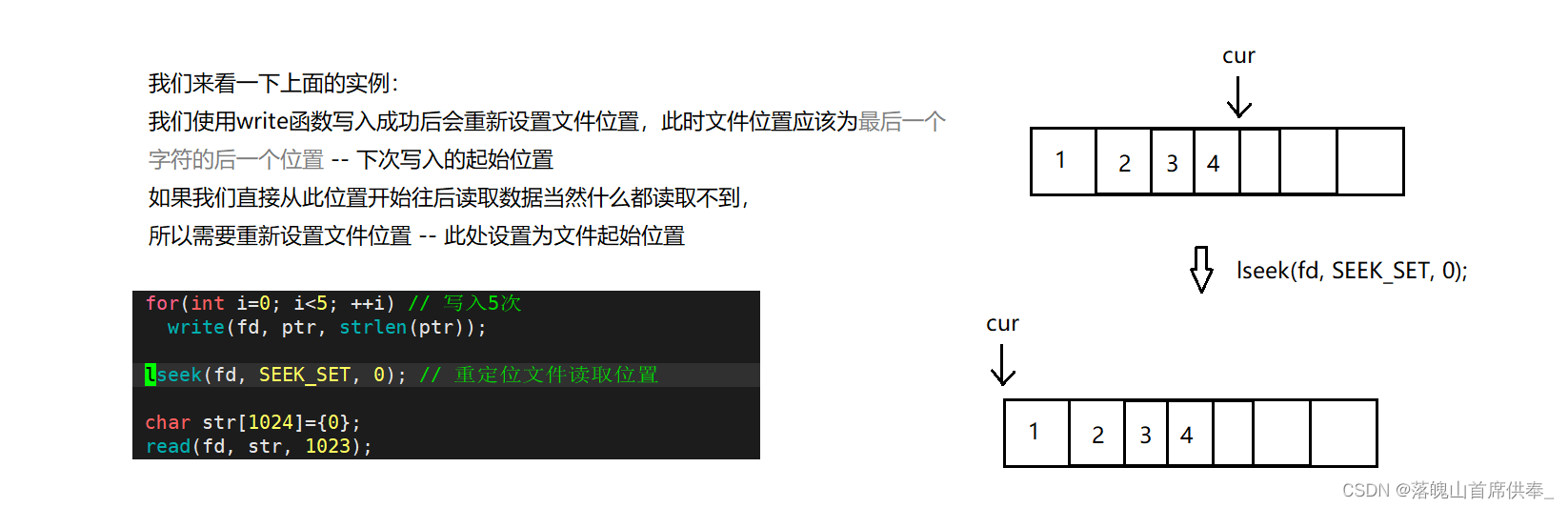
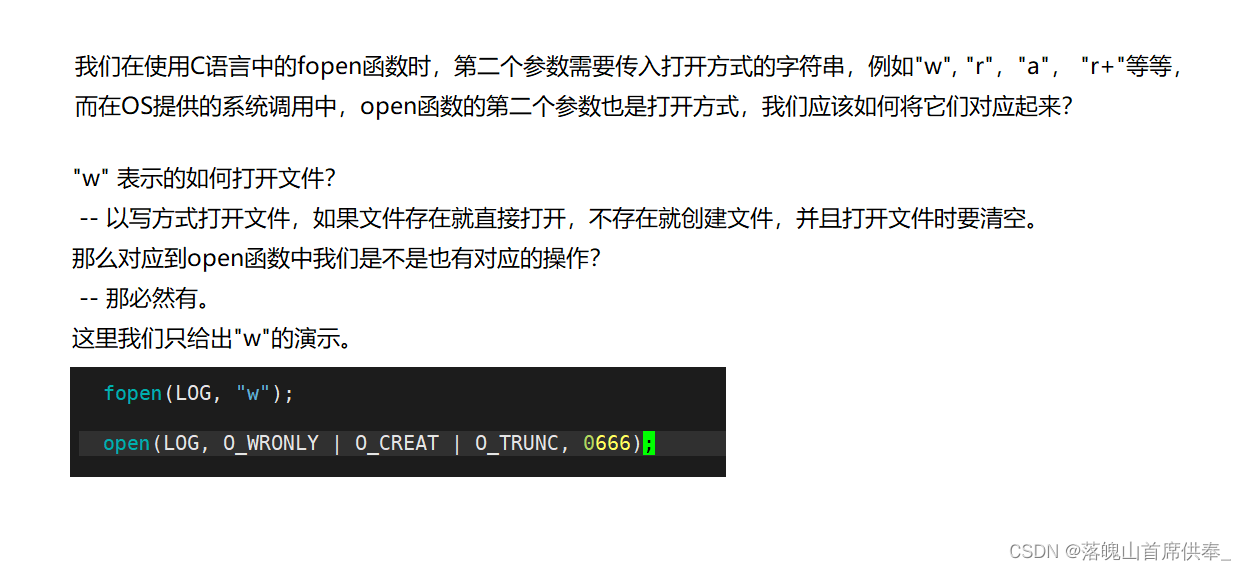
C语言中的文件操作函数与系统文件操作函数的联系
我们通过打开和关闭两个操作简单了解:

三、文件描述符
上面我们已经了解了OS中对文件的操作,我们是否已经清楚了OS中的文件操作呢?好像是?
好像已经了解了,那么我们要问一问自己,
- 文件描述符是什么?
- C语言为什么不直接使用fd,反而要对它进行进一步封装?
- C语言又是如何进行封装的?
- 其他语言呢?
文件描述符属于OS层面的文件标识符,当一个进程想要操作文件时,就需要用到文件描述符,这里我们需要注意:在语言层面我们一般用到的是文件指针(例如C语言的FILE*),其实这是各个语言对OS层面的文件描述符进行了对应的封装;
下图是OS对文件的相关管理:
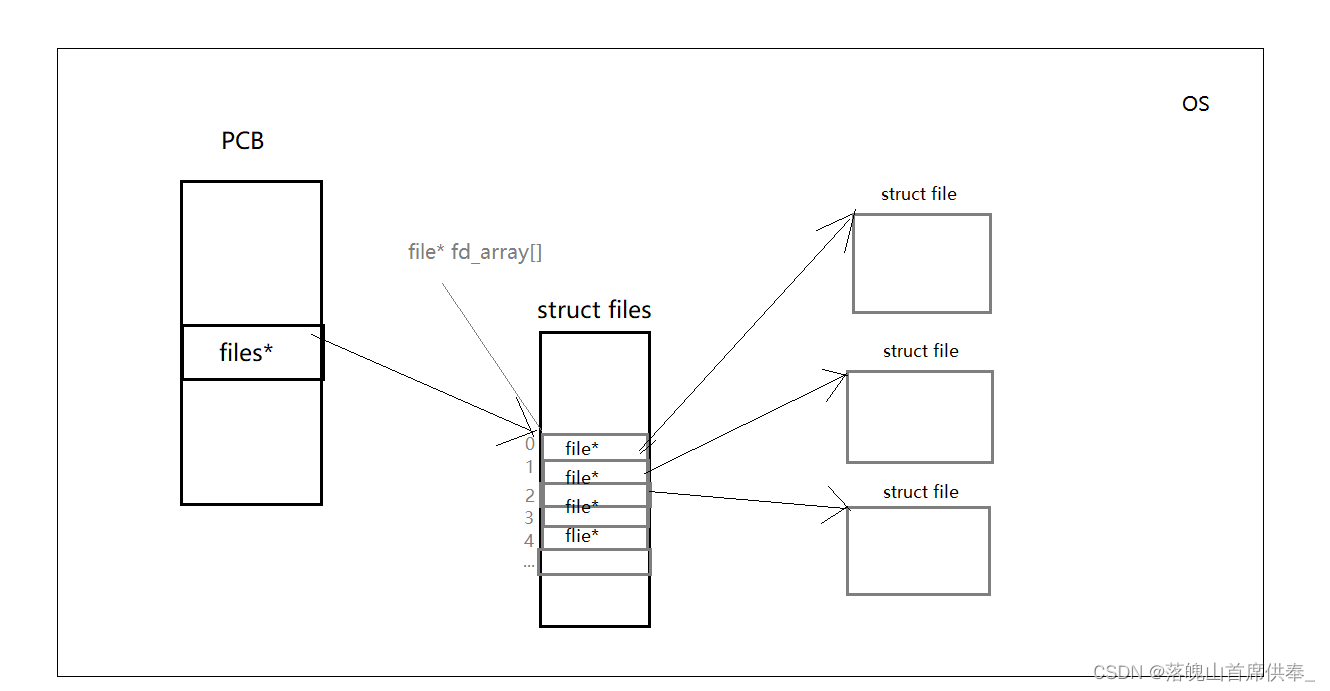
一个进程可以打开多个文件,那么操作系统就需要对这些文件进行管理 – 先描述再组织
OS会为每一个被打开的文件创建一个file结构体,用来存储该文件的属性信息(类比PCB),那么有了文件结构体file,进程还需要确定哪些文件是自己的,哪些是其他进程的,因此就需要对它们建立联系 – 添加指针
这里,操作系统将一个进程所打开的文件所有的地址全部存储在一个 files结构体中,当然files结构体并不仅仅存储了打开文件的地址,只是这部分最为重要,这些所打开文件的地址存储在fd_array数组中;
进程通过files*指针找到 files结构体,通过文件描述符(fd)在fd_array数组中找到对应文件的地址。
1.文件描述符是什么
#include<stdio.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>
#include<string.h>
#define LOG "log.txt"
int main()
{
int fd = open(LOG, O_RDONLY); // 只读方式
printf("%d\n", fd);
close(fd);
return 0;
}

我们上面说文件描述符其实本质上是数组下标,那么既然是数组下标不是应该从0开始吗,这里为什么是3,
难道它是随机存储的吗?
#include<stdio.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>
#include<string.h>
#define LOG "log.txt"
int main()
{
int fd1 = open(LOG, O_WRONLY | O_CREAT | O_TRUNC, 0666);
int fd2 = open(LOG, O_WRONLY | O_CREAT | O_TRUNC, 0666);
int fd3 = open(LOG, O_WRONLY | O_CREAT | O_TRUNC, 0666);
int fd4 = open(LOG, O_WRONLY | O_CREAT | O_TRUNC, 0666);
int fd5 = open(LOG, O_WRONLY | O_CREAT | O_TRUNC, 0666);
int fd6 = open(LOG, O_WRONLY | O_CREAT | O_TRUNC, 0666);
printf("%d\n", fd1);
printf("%d\n", fd2);
printf("%d\n", fd3);
printf("%d\n", fd4);
printf("%d\n", fd5);
printf("%d\n", fd6);
return 0;
}
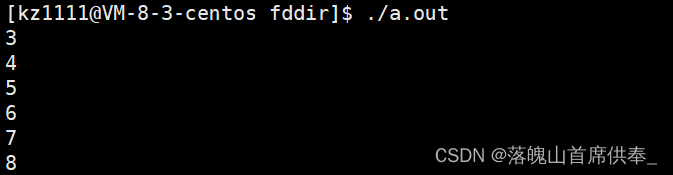
此时我们又发现,每打开一个文件,它的文件标识符就加1,也就是顺序存储,
那么为什么文件的文件标识符是从3开始而不是0呢?
文件标识符真的不是从0开始的吗?
在最前面的C语言文件操作中我们提到过:C语言会默认打开三个文件–> stdin, stdout, stderr,
所以,并不是标识符是从3开始,而是,我们在一开始就打开了三个文件占用了0,1,2三个文件标识符,因此,之后打开的文件依次往后排–也就是从3开始;
并且这三个文件的打开顺序是固定的 : 0–>stdin , 1–>stdout, 2–>stderr。
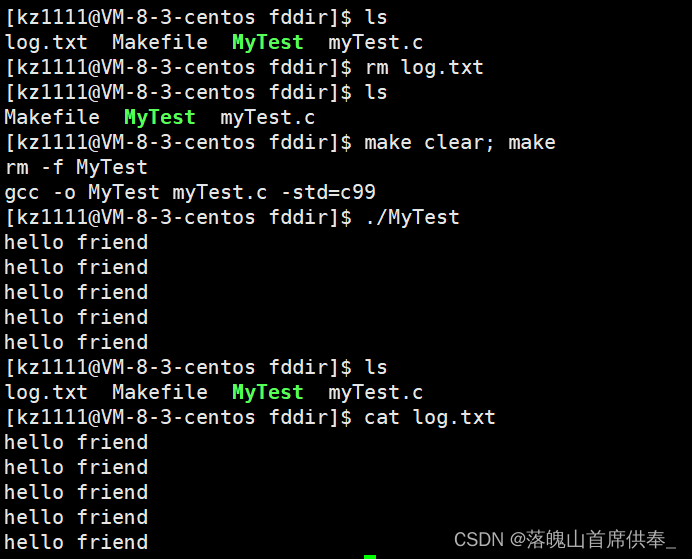
下面我们来验证一下:
验证方法:
以stdout为例,
既然stdout等也是文件,并且它们占用的文件标识符是固定的,那么我们是否可以关闭它们?
– 当然可以。
既然stdout被关闭了,那么它所占用的文件描述符是否还可以分配给其他文件?
我们知道,printf是默认向标准输出 – 显示器,中打印数据的,那么如果stdout被关闭了printf还可以使用吗?
#include<stdio.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>
#include<string.h>
#define LOG "log.txt"
int main()
{
close(1);
int fd = open(LOG, O_WRONLY | O_CREAT | O_TRUNC, 0666);
printf("%d\n", fd);
printf("close stdout\n");
printf("close stdout\n");
printf("close stdout\n");
return 0;
}
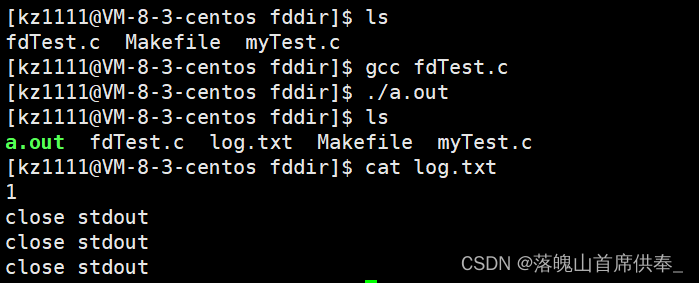
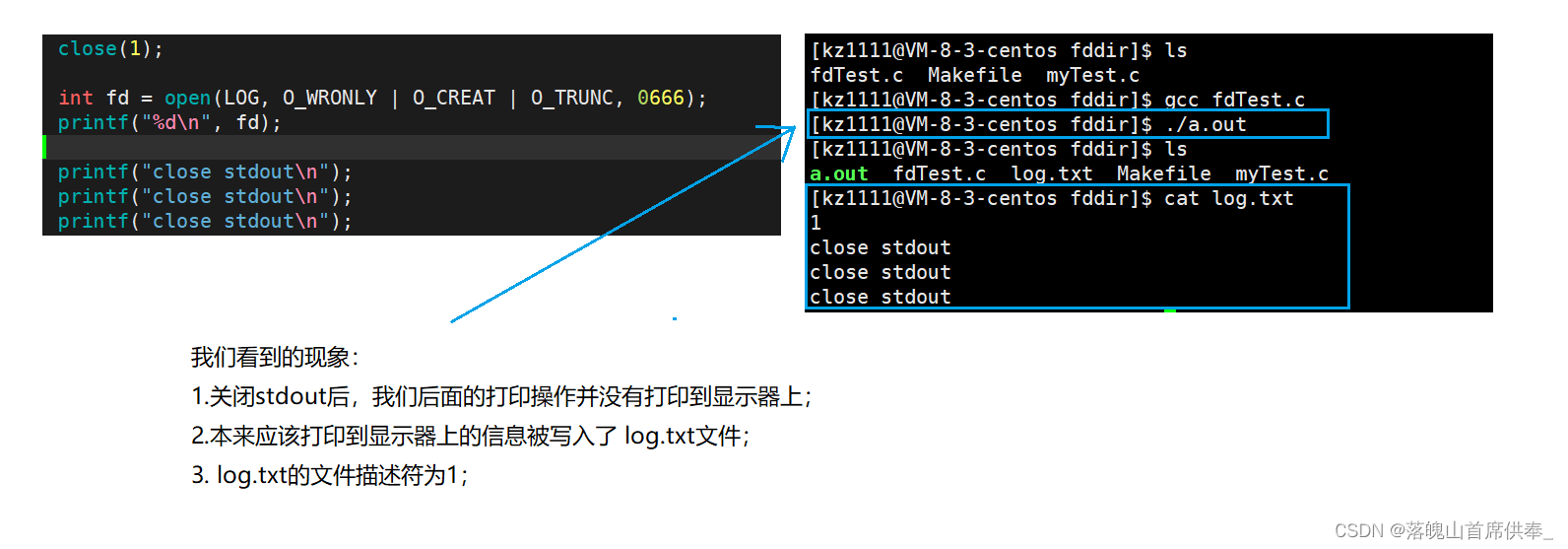
我们能得出的结论:
- 文件描述符的分配规则为–>遍历数组,找到第一个没有被使用的位置,将文件的地址存入其中,返回该位置的下标作为文件的文件描述符;(其实应该多打开几个文件使结果更加明显,但是上面已经写好了就懒得改了,看到了朋友要注意一下欧~)
- 之前我们认为的printf函数是将信息打印到显示器,而现在我们发现好像并非如此:printf是将信息默认打印到 文件描述符为1的文件中,之前之所以打印到显示器,只是因为显示器文件占用着1号文件描述符而已,换了其他文件也可以!!
2.文件缓冲区
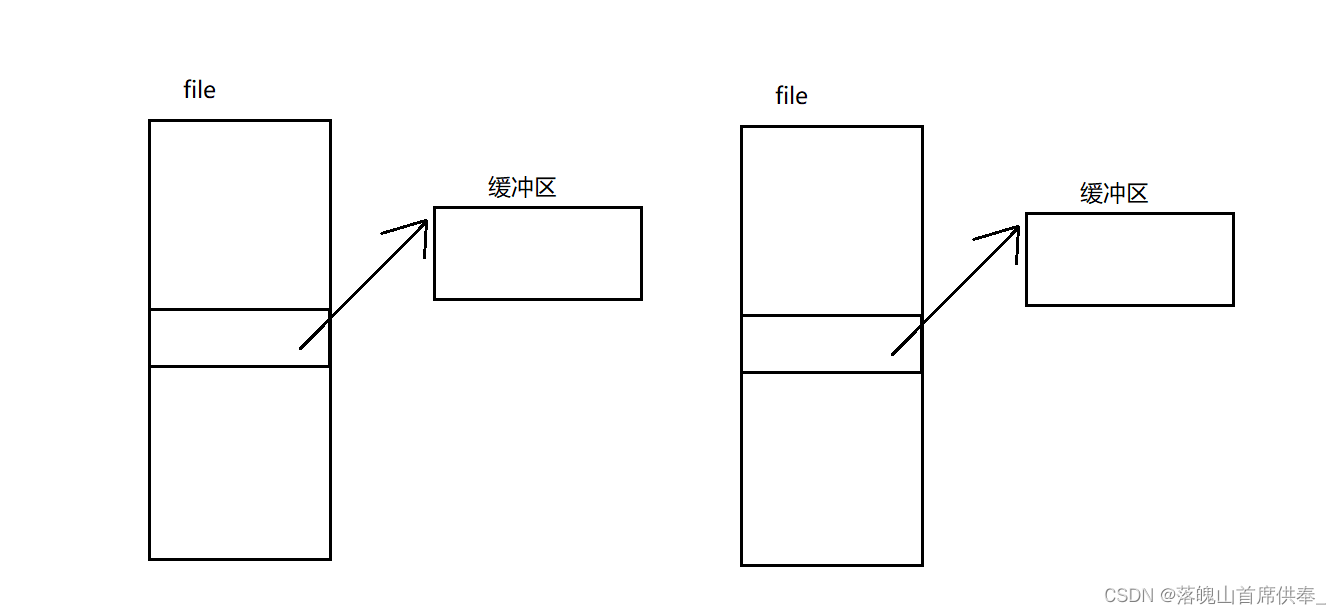
我们想要对文件中的内容进行操作就需要将文件信息加载到内存,既然需要加载到内存中,我们就需要找地方存储下来,这里就引入了文件缓冲区。
操作系统对文件进行管理时会为它创建file结构体,file结构体中会有一块区域(数组)存放从文件的读取到的(向文件中写入的)数据,
而这块区域就称为缓冲区;
这里我们可以解答一个平时使用文件时遇到的问题:为什么台式机写文档的时候很担心突然断电?
– 因为,我们向文件中写入内容的时候并没有直接写到磁盘中,而是写入了文件的缓冲区,只有当OS对缓冲区中的内容进行刷新后,我们写入的内容才会被保存到磁盘,而编译器何时刷新完全由编译器自己决定,因此,如果编译器没有进行刷新时突然断电,内存中的数据就丢失了(当然我们也可以手动刷新)。
#include<stdio.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>
#include<string.h>
#define LOG "log.txt"
int main()
{
fprintf(stdout, "write in stout\n");
fprintf(stdout, "write in stout\n");
fprintf(stdout, "write in stout\n");
fprintf(stdout, "write in stout\n");
fprintf(stdout, "write in stout\n");
fprintf(stderr, "write in stderr\n");
fprintf(stderr, "write in stderr\n");
fprintf(stderr, "write in stderr\n");
fprintf(stderr, "write in stderr\n");
fprintf(stderr, "write in stderr\n");
return 0;
}
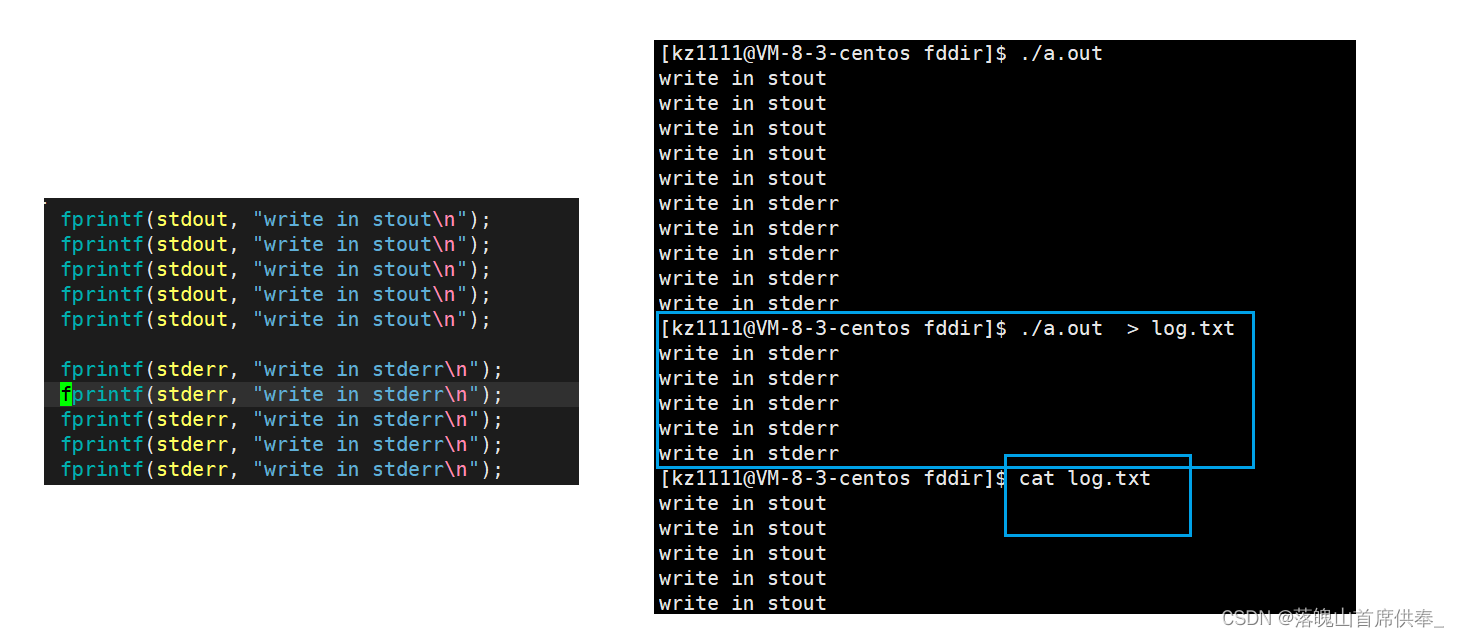
我们分别向标准输出和标准错误打印数据,可以同时打印到显示器上,说明在 文件标识符1合2中存储的都是显示器文件的地址;
第二步我们将文件中的内容重定向到 log.txt文件,此时我们发现,只有打印到标准输出的内容重定向到log.txt文件,标准错误的信息仍然打印到了显示器,这是因为重定向和printf类似,也是默认只重定向 文件标识符 1 所指向文件的内容,虽然1 和 2都是指向显示器,但是2的指向并没有改变。
再谈重定向
那么我们可以怎么将打印到2中的内容也重定向到log.txt文件呢?
- ./a.out &> log.txt (&>本身就是很好的分隔符,所以 &> 两边加不加空格都可以)
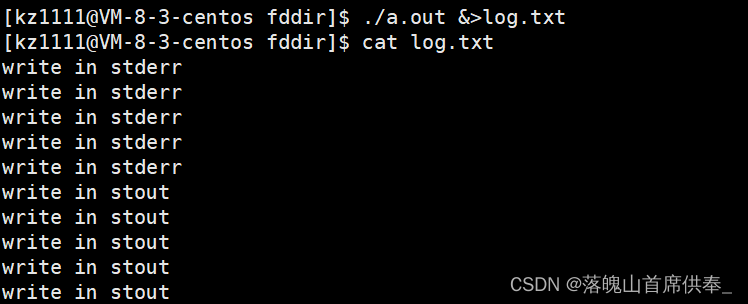
理解:将标准输出和标准错误输出到 log.txt文件。
- ./a.out >&log.txt(同上)
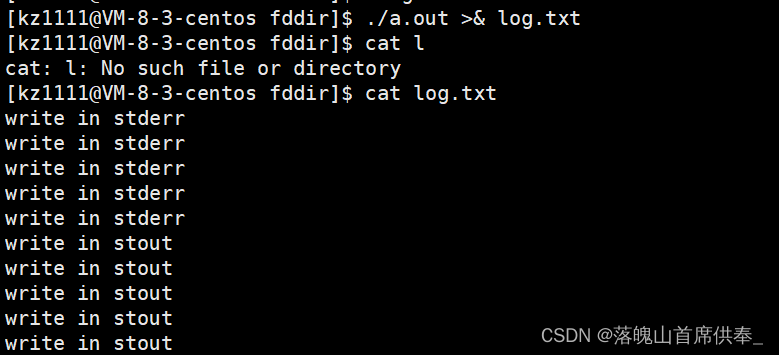
理解:同上, 将标准输出和标准错误输出到 log.txt文件。
- ./a.out > log.txt 2>&1
(文件标识符与操作符不可间断,中间不可有空格 – 为什么? – 因为文件中间加空格,OS可以识别区分,但是这些数字如果分开写,OS无法明确这些数字的含义)
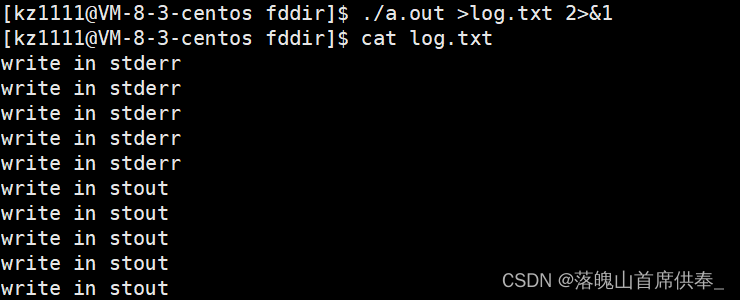
理解:将标准输出重定向到 log.txt文件,再将标准错误重定向到标准输出;
- ./a.out 2>log.txt 1>&2
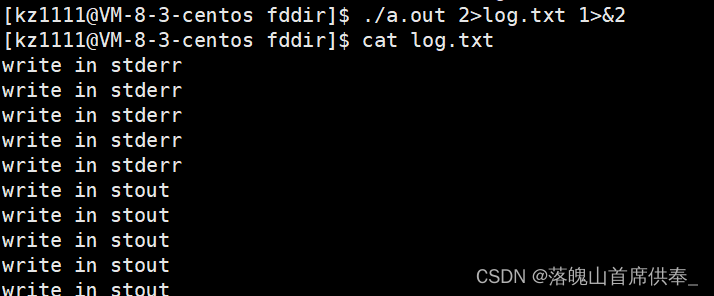
理解:同上,将标准错误重定向到 log.txt文件,再将标准输出重定向到标准错误;
四、文件缓冲区分类
语言级缓冲区
我们在一开始提出的第二个问题:C语言提供的FILE结构体在哪里,我们并没有手动设置为什么就可以使用?
C语言为什么要再提供一个FILE结构体而不是直接使用OS提供的fd进行文件操作,难道只是为了展现语言自己的特色吗?
在FILE结构体中到底有什么?
#include<stdio.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>
#include<string.h>
#define LOG "log.txt"
int main()
{
fprintf(stdout, "printf\n");
const char* ptr = "write\n";
write(1, ptr, strlen(ptr));
fork();
return 0;
}

这里,我们就需要引入第二个缓冲区的问题:语言自己提供的缓冲区
我们知道,语言封装的函数底层还是调用系统调用的,因此FILE结构体中一定有fd,
有fd,但是如果只是为了调用系统调用而封装了一个FILE结构体,那可就完全是“脱裤子放屁 ” - 多此一举了。
其实在FILE内部,也会为我们封装一个缓冲区,每个打开的文件都会有一个FILE结构体,也就都会有自己的缓冲区 – 语言级别,
下面我们通过图示进一步了解:
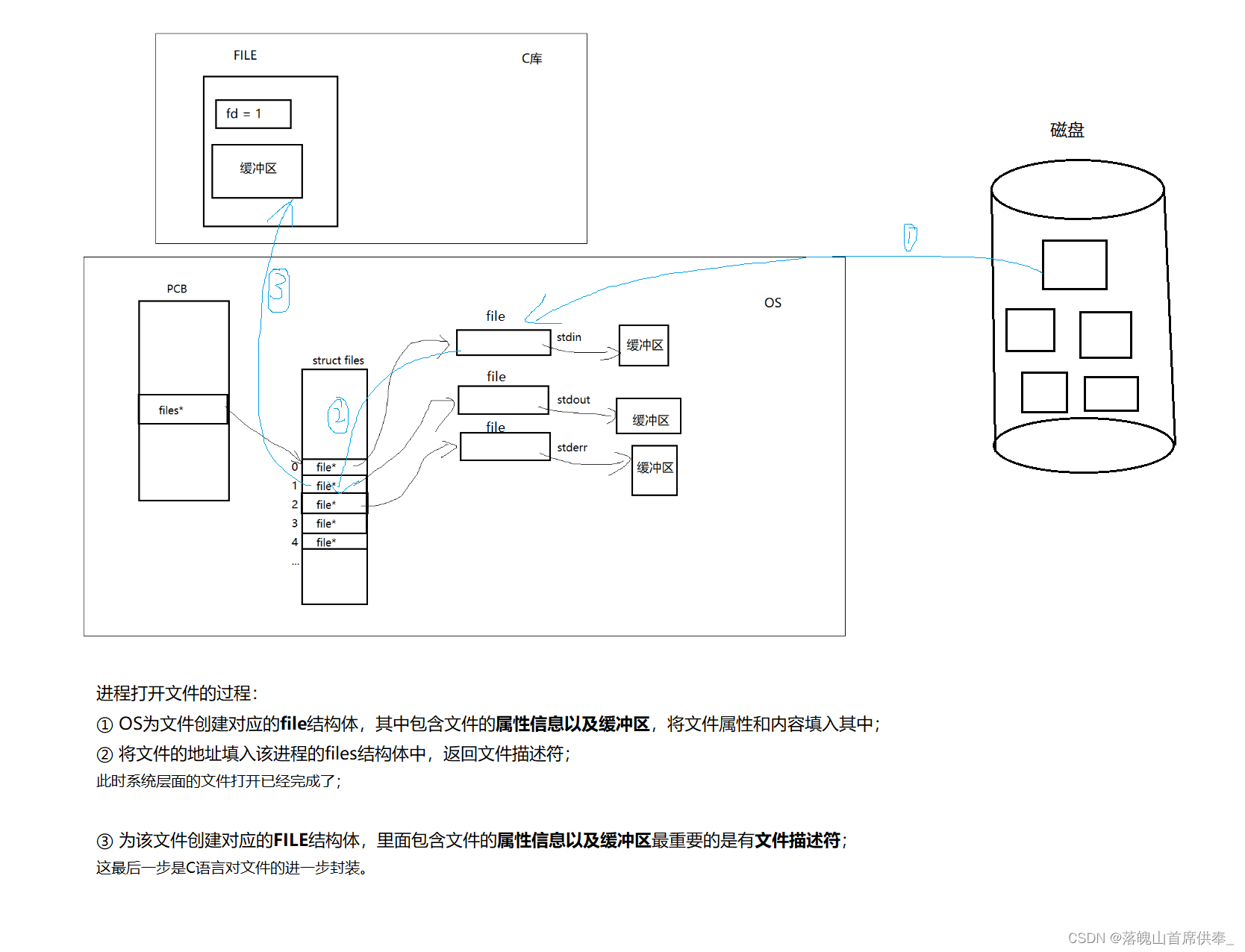
也就是说:对于一个已经打开的文件,它是有两个缓冲区的!而我们平时所说的文件缓冲区指的一般都是语言级别的缓冲区。
关于缓冲区,它的刷新方式一般有三种:
我们来解释一下:
无缓冲指的是 不管我们往缓冲区中写入多少数据,只要写入结束就立即从语言级换冲区刷新到系统缓冲区中;
行缓冲指的是 当我们写入结束,并且最后一个写入的是换行符就会刷新到系统缓冲区;
最后的全缓冲则是 无论我们写入的是什么内容,只有当我们把缓冲区写满的时候才会进行刷新。
各举出一个例子:
无缓冲:打印错误,sdterr;
行缓冲:往显示器上打印,stdout;
全缓冲:往一般文件中写入。
需要注意的一点是:我们上面所说的都是从语言级缓冲区刷新到系统级缓冲区的刷新策略,
至于系统级缓冲区何时将内容刷新到磁盘,这是完全由系统自己决定的。
下面我们来验证一下缓冲区的存在:
#include<stdio.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>
#include<string.h>
#define LOG "log.txt"
int main()
{
fprintf(stdout, "printf");
sleep(3);
const char* ptr = "write";
write(1, ptr, strlen(ptr));
sleep(3);
printf("\n");
return 0;
}

实验现象:等待三秒、打印 “write” , 等待三秒,打印 “printf”
但是如果按照我们平时的想法:打印 “printf” , 等待三秒,打印 “write” ,等待三秒
那么为什么会和我们的想法出入这么大 – 主要是 “printf” 的打印?
我们这里都是向显示器打印的,
首先是语言层,由于此时语言层面的刷新策略是行缓冲,由于没有遇到换行符,所以 “printf” 会一直在语言层面的缓冲区,而没有被刷新到系统缓冲区 ;
第二步,等待三秒;
第三步,我们直接调用系统接口往显示器上打印,那么此时就没有语言层的缓冲区什么事情,直接写入系统缓冲区,之后系统缓冲区根据自己的刷新策略将 “write” 刷新到了显示器;
第四步,等待三秒;
最后一步:我们 使用 printf向显示器文件写入了一个 换行符,语言层面的刷新策略将 语言级缓冲区中的信息刷新到系统缓冲区,再到显示器,所以到此时 “printf\n” 才被打印。
那下面我们就回到上面的问题中:为什么写入增加一个 fork()之后,将内容重定向输出会多打印一次呢?
其实这里涉及到写时拷贝的问题:
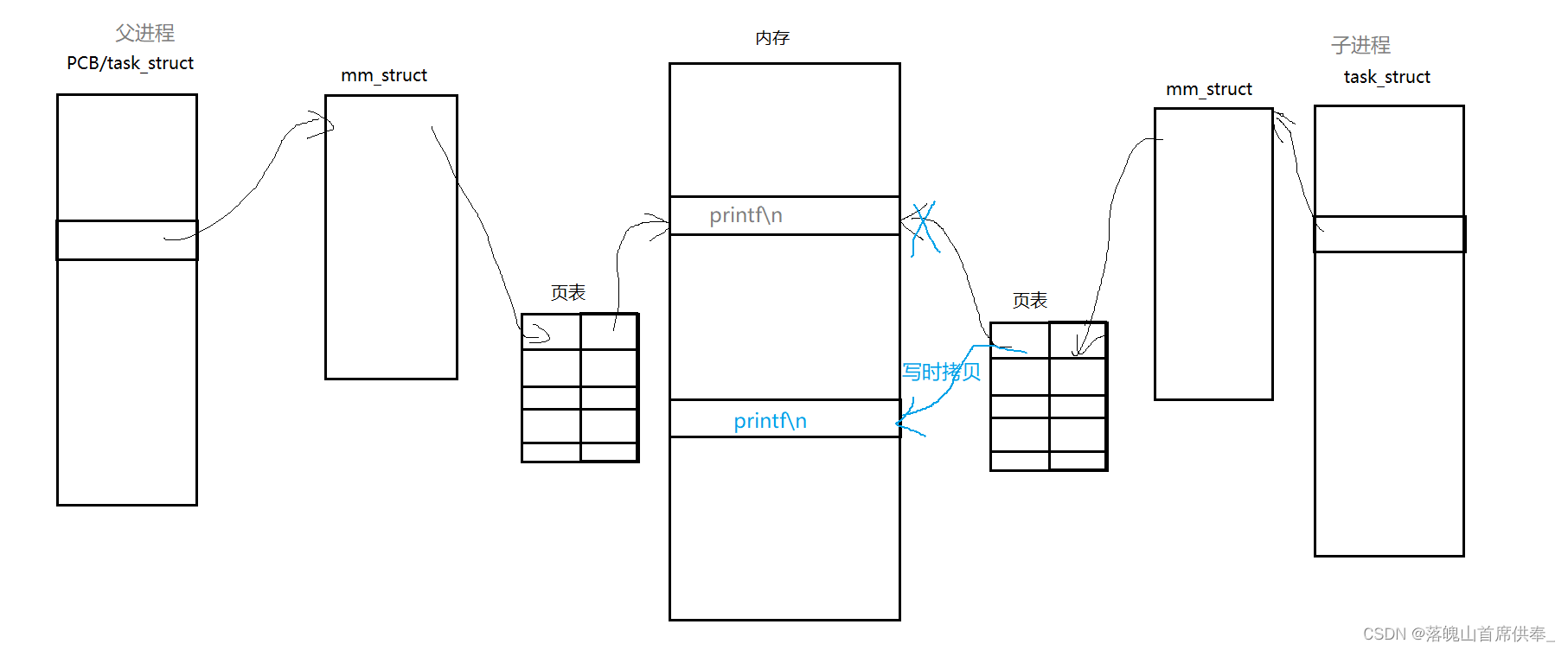
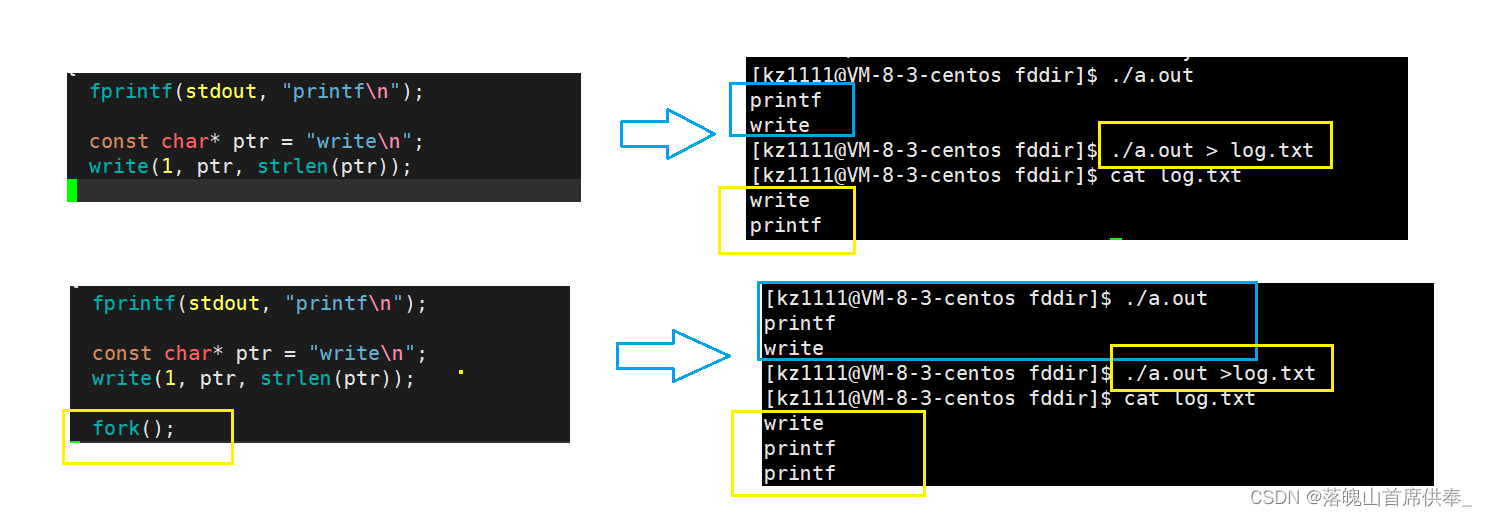
这里的write我们就不谈了,它是直接进行系统调用写入到系统级文件缓冲区的;
我们有两点需要注意:1是输出重定向, 2是创建子进程
由于我们将打印内容从显示器重定向到文件,所以语言级缓冲区的刷新策略也从 行缓冲 变为了 全缓存,
那么在fork之前我们就将 "printf\n"写入到了缓冲区中,之后创建子进程,子进程共享父进程的代码和数据,因此缓冲区中的内容父子都可以看到;
再之后程序运行结束,父子进程相继退出,而进程在退出之前都会清空缓冲区中的内容,
那么此时子进程去清空缓冲区时是不是就相当于一次写入,
所以,OS就会进行写时拷贝, 将 “printf\n” 拷贝到其他地方让子进程去刷新,子进程退出,
父进程也刷新缓冲区,父进程退出。
这,就是我们在 log.txt 中查看到两个 "printf\n"的原因。
为什么要有两个缓冲区
为什么C语言要专门封装一个 FILE结构体,再给我们提供一个缓冲区呢?
– 为了提高IO效率。
我们知道,write、read这些函数都是系统调用,每次使用系统调用都需要占用cpu资源,如果没有语言级的缓冲区,我们每次写入一个字节,就进行一次系统调用,每写入一个字节,就进行一次系统调用,这样做是不是会严重拖慢我们cpu的工作效率?
就比如送快递,到底是每有一个快递,快递公司就立即派一名快递员开始派送,还是等待一段时间,等到收到的快递足够装一车时才进行统一配送?
我想我们大多数朋友都经历过:在网上买一个东西,两天过去了快递仍然没有发出的情况吧(特别是双十一期间!)
采用统一配送的方式可以节省很多人力物力,因此,在我们的计算机中也使用着这种方式 – OS级别的缓存区也是这么个道理。
五、仿写c语言之 FILE结构体
我们采用分文件编写的方式,简单模拟文件操作的几个函数:fopen,fclose,fread,fwrite
my_stdio.h
#pragma once
#include<stdio.h>
#define BUFSIZE 1024
enum flush_way // 缓存方式
{
FLUSH_NONE, // 出错
FLUSH_ANAY, // 不缓存
FLUSH_LINE, // 行缓存
FLUSH_ALL // 全缓存
};
typedef struct __C_IO_FILE
{
int _fd; // 文件标识符 -- 任何语言的文件操作都必须有
char _buf[BUFSIZE]; // c库提供的缓冲区 -- 也可malloc到堆区
size_t _cur; //当前位置
enum flush_way fway; // 记录刷新方式
}MYFILE;
MYFILE* my_fopen(const char *path, const char *mode);
int my_fclose(MYFILE *fp);
size_t my_fread(void *ptr, size_t size, size_t nmemb, MYFILE *stream);
size_t my_fwrite(const void *ptr, size_t size, size_t nmemb, MYFILE *stream);
my_stdio.c
#include"my_stdio.h"
#include<string.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>
#include<assert.h>
#include<malloc.h>
MYFILE* my_fopen(const char *path, const char *mode)
{
// 1.分析权限
int flags = 0;
if(strcmp(mode, "w") == 0)
{
flags |= O_WRONLY | O_CREAT | O_TRUNC;
}
else if(strcmp(mode, "r") == 0)
{
flags |= O_RDONLY;
}
else if(strcmp(mode, "a") == 0)
{
flags |= O_WRONLY | O_CREAT | O_APPEND;
}
else // w+ 等等
{}
//2. 打开文件
int fd = -1;
if(flags | O_CREAT) fd = open(path, flags, 0666); // 如果创建文件需要设置权限
else fd = open(path, flags);
assert(fd >= 0);
//3. 配置文件信息 -- 注意此处需要malloc,之后也需要手动关闭
MYFILE* fp = (MYFILE*)malloc(sizeof(MYFILE));
assert(fp);
fp->_cur = 0;
fp->_fd = fd;
fp->fway = FLUSH_LINE;
memset(fp->_buf, '\0', BUFSIZE);
//4. 返回文件指针
return fp;
}
void my_fflush(MYFILE* stream) // 刷新库缓冲区
{
write(stream->_fd, stream->_buf, stream->_cur);
stream->_cur = 0;
}
int my_fclose(MYFILE *fp)
{
// 1. 不能传空指针
assert(fp);
// 清空缓冲区
my_fflush(fp);
// 2. 关闭os中的文件结构体
close(fp->_fd);
// 3.释放c库的文件结构体
free(fp);
fp = NULL;
return 0;
}
size_t my_fread(void *ptr, size_t size, size_t nmemb, MYFILE *stream)
{
assert(ptr);
assert(stream);
// 首先c库缓存中需要有数据 -- 没有就补满
if(stream->_cur == 0)
{
ssize_t rsize = read(stream->_fd, stream->_buf, BUFSIZE);
assert(rsize >=0);
if(rsize == 0) return 0; // 文件内容读取结束
}
size_t usrSize = size * nmemb;
for(size_t i=0; i<usrSize; )
{
// c库缓存中的数据足够用户使用
if(usrSize - i < BUFSIZE - stream->_cur)
{
strcpy((char*)ptr + i, stream->_buf + stream->_cur);
stream->_cur += usrSize - i;
i = usrSize;
}
// 不够用户使用的时候,读完之后重新补满
else
{
strncpy((char*)ptr + i, stream->_buf + stream->_cur, usrSize - i);
ssize_t rsize =read(stream->_fd, stream->_buf, BUFSIZE);
assert(rsize >=0);
if(rsize == 0) break; // 文件内容读取结束
stream->_cur = 0;
}
}
return usrSize;
}
size_t my_fwrite(const void *ptr, size_t size, size_t nmemb, MYFILE *stream)
{
assert(ptr);
assert(stream);
// 判断当前缓冲区有多少内容 -- 满了 需要刷新 并清空
if(stream->_cur == BUFSIZE)
{
my_fflush(stream);
stream->_cur = 0;
}
// 计算用户需要我们写入的数据量 , 开始写入
size_t usrSize = size * nmemb;
for(size_t i=0; i<usrSize; i+=BUFSIZE)
{
size_t tmp = BUFSIZE - stream->_cur;
if(usrSize - i > tmp) // 1. 现有的加上新添加的 如果大于剩余容量,不写入语言缓冲区,直接刷新到系统缓冲区,只写入我们能写的
{
if(usrSize - i > BUFSIZE + stream->_cur)
{
write(stream->_fd, stream->_buf, stream->_cur);
stream->_cur = 0;
write(stream->_fd, (char*)ptr+i, BUFSIZE);
}
else
{
strncpy(stream->_buf + stream->_cur, (char*)ptr + i, tmp);
my_fflush(stream);
strncpy(stream->_buf , (char*)ptr + i + tmp, usrSize - i - tmp);
}
}
else // 2. 不大于容量,写入用户需要写入的全部
{
strcat(stream->_buf, (char*)ptr);
stream->_cur += usrSize - i;
}
}
// 3. 判断刷新条件 - 全缓冲 行缓存 无缓冲
if((stream->fway == FLUSH_LINE && stream->_buf[stream->_cur-1]=='\n')
|| (stream->fway == FLUSH_ALL && stream->_cur == BUFSIZE)
|| (stream->fway == FLUSH_ANAY))
{
my_fflush(stream);
}
return usrSize;
}
my_main.c
为了方便大家阅读,减少文章长度:此处给出第一份测试代码,之后的测试代码省略,只放截图。
/* my_main.c */
#include"my_stdio.h"
#include<string.h>
#include<unistd.h>
int main()
{
MYFILE* fp = my_fopen("log.txt", "w");
//printf("open myfile success\n");
const char* msg = "i write in file of log.txt";
for(int i=1; 1; ++i)
{
my_fwrite(msg, strlen(msg), 1, fp);
sleep(1);
if(i % 5 == 0) // 采用行缓冲,每五行录入一个换行符
my_fwrite("\n", strlen("\n"), 1, fp);
}
my_fclose(fp);
//printf("close myfile success\n");
return 0;
}
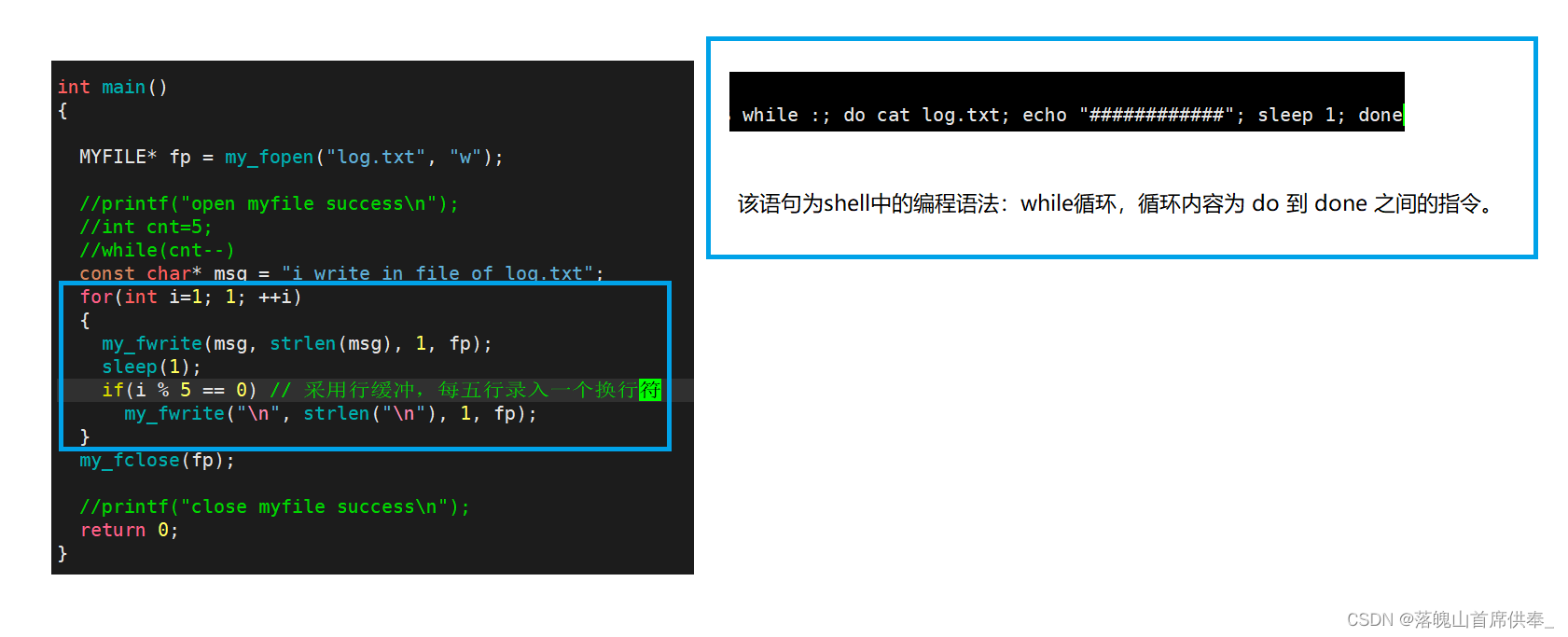
功能测验
w - 写入操作:

a - 追加操作
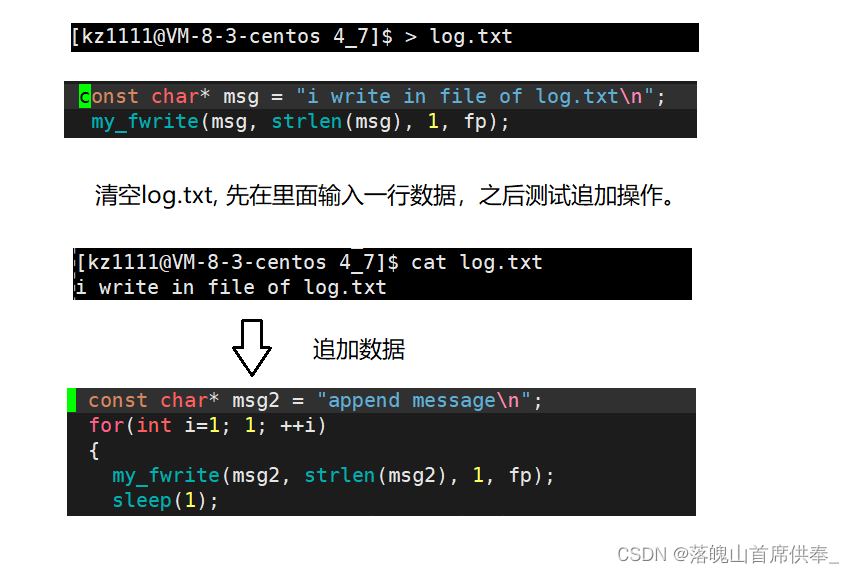

r - 读取测试

总结
今天我们了解了文件操作的系统调用接口:open、close、write、read、lseek;
搞清楚了文件描述符的含义 – 数组下标;
知道了文件的缓冲区 – OS级 和 语言级;
并且清楚了这两个缓冲区存在的位置,以及为什么存在 – 提高io效率;
最后我们也尝试 写了自己的 FILE结构体 ,
这里需要补充一句:并非只有c语言对有语言级的缓存区,其他语言也会有,并且,不管是哪一个语言,不管他如何进行封装,在这些封装的文件结构体内部,必定存在文件描述符。