MLOps 的最大优势之一是它使 AI 研究员和软件工程师能够更紧密地协作。AI 研究员可以专注于开发模型,而软件工程师可以专注于实施模型。这种协作有助于确保模型快速高效地部署,并满足业务需求。另一个 MLOps 的优点是它有助于自动化模型开发和部署的过程。这意味着 AI 研究员可以减少做重复性任务的时间,并有更多时间开发新模型。自动化还有助于确保模型一致地以高质量的方式部署。
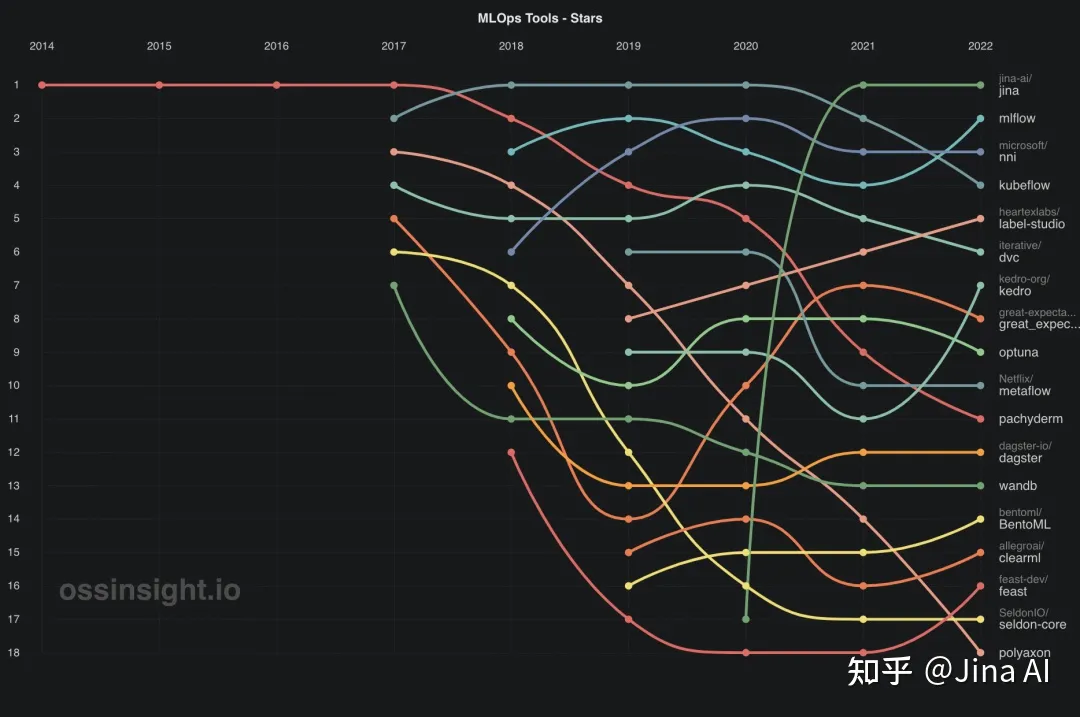
根据 OSSInsight,Jina AI 的同名核心产品 Jina 是目前最热门的 MLOps 开源工具。Jina 是一个 多模态 AI 的 MLOps 框架。它简化了云端的神经搜索和创意 AI 的构建和部署。Jina 极大简化了基础架构 AI 的复杂性,开发者可以轻松将 PoC 升级为生产就绪服务,直接使用 Jina 封装好的高级解决方案工程和 云原生技术。
MLflow 排在榜单第 2 名。与专门针对神经搜索和多模态 AI 应用的 Jina 不同,MLflow 是一个更通用的平台,旨在简化机器学习开发,包括跟踪实验、将代码打包成可重复运行的代码、共享和部署模型。它提供了一组轻量级 API,可与任何现有的机器学习应用或库(TensorFlow、PyTorch、XGBoost 等)一起使用,无论你当前在哪里运行 ML 代码(例如在笔记本、独立应用程序或云端)。MLflow 的当前组件有:
与更多关注推理的 Jina 不同,NNI 专注于模型训练和实验。它提供了强大且易于使用的 API,用于促进高级训练,如 AutoML。自动神经架构搜索在寻找更好模型方面发挥着越来越重要的作用。最近的研究已经证明了自动 NAS 的可行性,并导致了超过许多手动设计和调整的模型的模型。代表性作品包括 NASNet,ENAS,DARTS,网络形态学和演化。
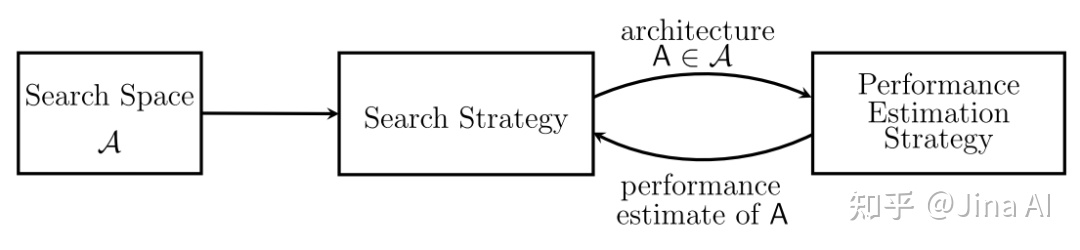
标题神经架构搜索的过程类似于超参数优化,只不过目标是最佳架构而不是超参数。
一般来说,神经架构搜索通常包括三项任务:搜索空间设计,搜索策略选择和性能评估。这些任务都很麻烦,但在 NNI 中却很容易解决:
# define model space
class Model(nn.Module):
self.conv2 = nn.LayerChoice([
nn.Conv2d(32, 64, 3, 1),
DepthwiseSeparableConv(32, 64)
])
model_space = Model()
# search strategy + evaluator
strategy = RegularizedEvolution()
evaluator = FunctionalEvaluator(
train_eval_fn)
# run experiment
RetiariiExperiment(model_space,
evaluator, strategy).run()
Label Studio 是 Heartex 开发的一款开源工具,专注于机器学习生命周期的早期阶段:数据标注。数据标注是将标签添加到数据集的过程,使其能够用于训练机器学习模型。数据标注是非常重要的。首先,它能创建质量更高的数据集。如果数据集未被标记,机器学习模型可能难以从中学习。其次,数据标注可以帮助加速训练过程。第三,数据标注可以提高机器学习模型的结果,使其更加准确。数据标注通常是人工完成的,这是一个耗时且昂贵的过程。
Label Studio 让您可以使用简单的 UI 来标记音频、文本、图像、视频和时间序列等数据类型,并将它们导出到各种模型格式。它可以用于准备原始数据或改进现有的训练数据,以获得更准确的 ML 模型。
您还可以将 Label Studio 与机器学习模型集成,以提供标签的预测(预标记),或进行持续的主动学习。Label Studio ML 后端是一个 SDK,可以让您包装机器学习代码并将其转换为 Web 服务器。然后,就可以将该服务器连接到 Label Studio 实例以执行 2 项任务:
在定义加载器后,您可以为模型定义两种方法:推理调用和训练调用。您可以使用推理调用即时从模型中获取预标记。必须更新示例 ML 后端脚本中的现有predict方法,使其适用于您的特定用例。
def predict(self, tasks, **kwargs):
predictions = []
# Get annotation tag first, and extract from_name/to_name keys from the labeling config to make predictions
from_name, schema = list(self.parsed_label_config.items())[0]
to_name = schema['to_name'][0]
for task in tasks:
# for each task, return classification results in the form of "choices" pre-annotations
predictions.append({
'result': [{
'from_name': from_name,
'to_name': to_name,
'type': 'choices',
'value': {'choices': ['My Label']}
}],
# optionally you can include prediction scores that you can use to sort the tasks and do active learning
'score': 0.987
})
return predictions
编写您自己的代码来覆盖 predict(tasks, **kwargs) 方法,该方法采用 JSON 格式的 Label Studio 任务并以 Label Studio 接受的格式返回预测。
写下你自己的训练调用,通过覆盖fit(annotations,kwargs)方法来更新你的模型的新注释,该方法接受格式化为 JSON 的 Label Studio 注释并返回可以存储有关创建的模型的任意 dict。
def fit(self, completions, workdir=None, **kwargs): # ... do some heavy computations, get your model and store checkpoints and resources return {'checkpoints': 'my/model/checkpoints'} # <-- you can retrieve this dict as self.train_output in the subsequent calls
如果你只想在不重新训练模型的情况下预注释任务,你不需要在代码中使用此调用。但如果你确实想根据 Label Studio 的注释重新训练模型,请使用fit(annotations,kwargs)方法。
在将模型代码与类封装、定义加载器以及定义方法之后,你就可以将模型作为 ML 后端与 Label Studio 一起使用了。
很难否认,任何机器学习模型的成功在很大程度上取决于其训练数据的质量。这就是为什么 Label Studio 在 2022 年排名较高,在 MLOps 中起着至关重要的作用。
就具体工具而言,我们认为版本控制工具将变得越来越重要,用于管理 ML 代码和模型。数据注释和标记工具也将获得更多普及,因为对高质量训练数据的需求变得更加明显。最后,模型管理工具将成为管理生产中部署的各种机器学习模型的必要工具。总的来说,我们预计 MLOps 领域将变得更加多元,将提供更多的工具来满足不同组织的需求。