安装
使用PyCharm安装,进入到PyCharm -> Preferences -> Project Interpreter,点击加号
查询框输入‘Scrapy’,点击‘Install Package’
使用shell调试工具
- 使用Scrapy提供的shell调试工具来抓取网页信息, 以爬取我的博客为例,如下
MAC-53796:PycharmProjects gcui$ scrapy shell https://blog.csdn.net/galen2016
...
...
...
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler <scrapy.crawler.Crawler object at 0x10672f050>
[s] item {}
[s] request <GET https://blog.csdn.net/galen2016>
[s] response <200 https://blog.csdn.net/galen2016>
[s] settings <scrapy.settings.Settings object at 0x106817090>
[s] spider <DefaultSpider 'default' at 0x106bab490>
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
>>>
可以看到返回200,说明抓取网页信息成功了。
注意,如果返回403,可能是网页开启了“防爬虫’,可以让Scrapy伪装成浏览器来解决,即在发送请求时添加User-Agent头,将User-Agent的值设置为浏览器发送请求的User-Agent。可以在浏览器的开发者模式中查到User-Agent。
例如,可以使用如下命令让Scrapy伪装成Chrome浏览器来开启shell调试
scrapy shell -s USER_AGENT='Mozilla/5.0' https://blog.csdn.net/galen2016
- 在Scrapy的shell控制台调用response的xpath()方法来获取Xpath匹配的节点,如获取博客的标题:
>>> response.xpath('//article//h4/text()').extract()
['PyCharm上传本地项目到GitLab - MacOS版', '【Docker】Docker运行Web UI自动化Demo', '[Mac] selenium打开Chrome浏览器', 'Python-常用的正则表达式', 'Docker - Dockerfile指令', '【Docker】docker容器管理总结', 'Postman/Newman+Docker+Jenkins/Pipeline 做接口自动化测试', 'Docker运行Postman/Newman', 'Docker -删除镜像(image)', '【Pytest】fixture使用request传参,结合parametrize', '【Pytest】使用Allure测试报告', '域名系统DNS 总结', 'Python - 日期、时间和日历操作', 'Python -日志模块使用', '动态主机配置协议DHCP', '2019年总结 - 收获很多', 'MacBook 复制文件和文件夹路径', '【Appium】Android Toast捕获', '【Appium】使用uiautomator定位元素', 'xpath不等于、不包含的写法']
>>>
创建Scrapy项目
- 选择一个目录,在命令行输入:scrapy startproject xxxx,最后一个参数是项目名,如下
MAC-53796:PycharmProjects gcui$ scrapy startproject BlogSpider
New Scrapy project 'BlogSpider', using template directory '/usr/local/lib/python3.7/site-packages/scrapy/templates/project', created in:
/Users/gcui/PycharmProjects/BlogSpider
You can start your first spider with:
cd BlogSpider
scrapy genspider example example.com
MAC-53796:PycharmProjects gcui$
- 用PyCharm打开该项目,可以看到项目的目录如下:
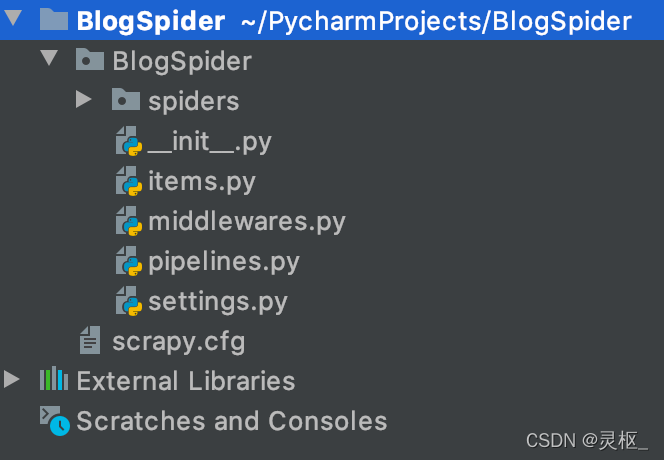
scrapy.cfg: 项目的总配置文件,通常无需修改
BlogSpider/items.py: 用于定义项目用到的Item类,也就是一个数据传输对象,需要由开发者来定义
BlogSpider/pipelines.py: 项目的管道文件,负责处理爬取到的信息,需要由开发者来编写
BlogSpider/setting.py: 项目的配置文件
BlogSpider/spiders: 在该目录下存放项目所需的蜘蛛–负责抓取项目感兴趣的信息。
Scrapy开发步骤
- 定义Item类,定义被爬取对象的属性,如果博客标题、发布时间、阅读量等,在item.py中定义,如下:
import scrapy
class BlogspiderItem(scrapy.Item):
title = scrapy.Field()
publish_date = scrapy.Field()
read_count = scrapy.Field()
- 编写Spider类,将该Spider类文件放在spiders目录下,然后用XPath或CSS来提取HTML页面中感兴趣的信息。
Scrap提供了scrapy genspider命令,可以直接生成Spider类。先进入到BlogSpider目录下,然后运行:
MAC-53796:BlogSpider gcui$ scrapy genspider galen__blogs 'blog.csdn.net/'
Created spider 'galen__blogs' using template 'basic' in module:
BlogSpider.spiders.galen__blogs
MAC-53796:BlogSpider gcui$
以上命令在BlogSpider/spiders目录下生成了galen_blogs.py, 如下图:
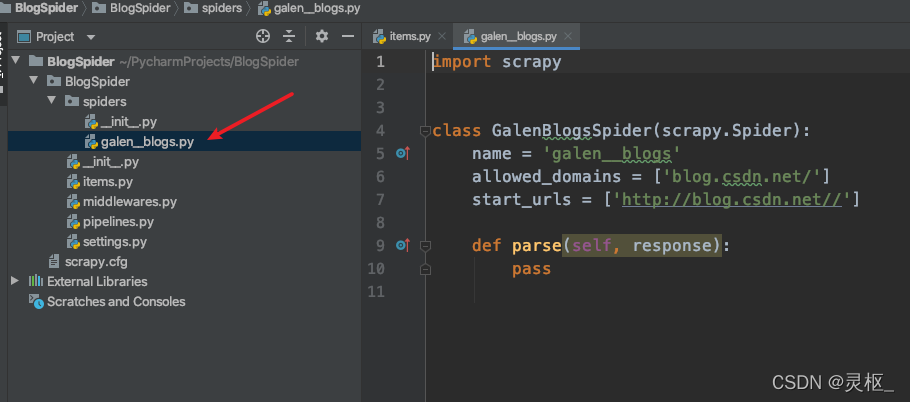
重写Spider类,主要是将要爬取的各页面URL定在start_url列表中,然后在parse方法中通过XPath或CSS提取感兴趣的信息,如下:
import scrapy
from BlogSpider.items import BlogspiderItem
class GalenBlogsSpider(scrapy.Spider):
name = 'galen__blogs'
allowed_domains = ['blog.csdn.net/']
start_urls = ['https://blog.csdn.net/galen2016']
def parse(self, response):
for article in response.xpath('//article[@class="blog-list-box"]'):
item = BlogspiderItem()
item['title'] = article.xpath('.//h4/text()').extract_first()
item['publish_date'] = article.xpath('.//div[@class="view-time-box"]/text()').extract_first()
item['read_count'] = article.xpath('.//span[@class="view-num"]/text()').extract_first()
yield item
最后一行代码使用yield语句将item对象返回给Scrapy引擎,然后Scrapy引擎将这些item收集起来传给项目的Pipeline。
3. 编写pipelines.py文件,目前只是简单的在控制台打印item数据,没有使用数据库。如下:
class BlogspiderPipeline:
def process_item(self, item, spider):
print('博客标题:', item['title'])
print('发布时间:', item['publish_date'])
print('阅读量:', item['read_count'])
Scrapy引擎会自动将Spider捕获的所有item逐个传给process_item(self, item, spider)方法,因此该方法只需处理单个的item即可。
4. 修改settings.py文件,将如下行取消注释
ITEM_PIPELINES = {
'BlogSpider.pipelines.BlogspiderPipeline': 300,
}
- 启动Spider,命令行进入到项目根目录下,输入如下命令:
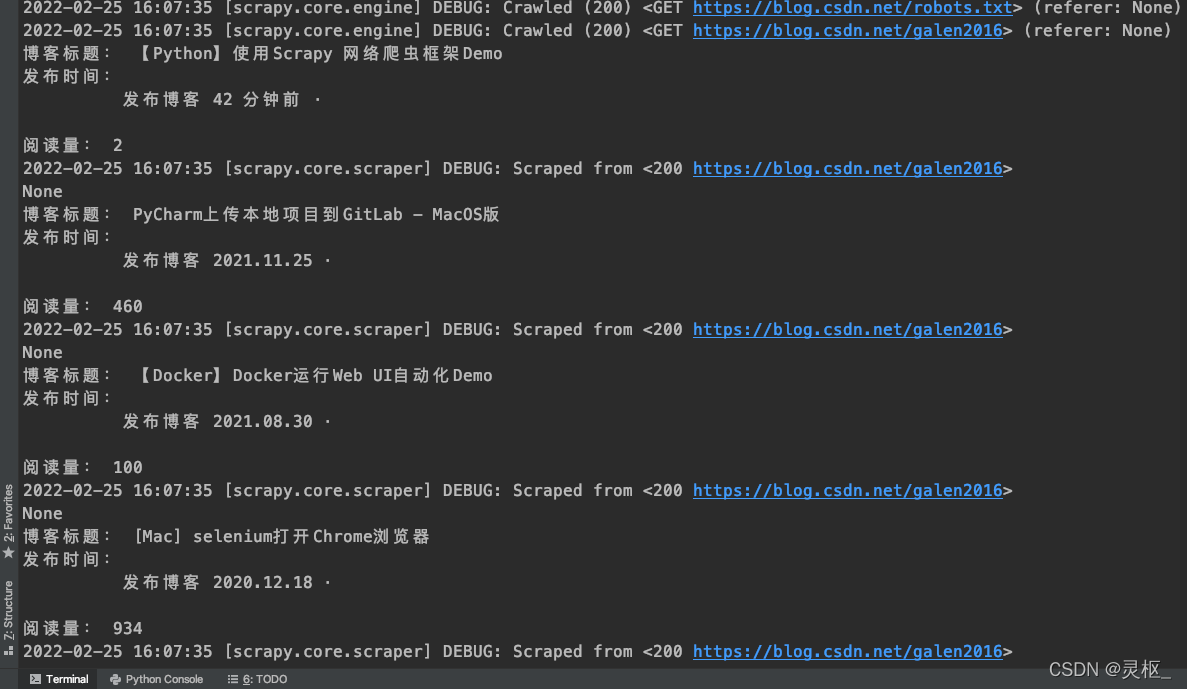
MAC-53796:BlogSpider gcui$ scrapy crawl galen__blogs
最后一个参数 galen_blogs就是前面定义的Spider名称。运行上面命令之后,可以获取如下结果:
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)