线程的同步与互斥
线程是一个存在进程中的一个执行控制流,因为线程没有进程的独立性,在进程内部线程的大部分资源数据都是共享的,所以在使用的过程中就需要考虑到线程的安全和数据的可靠。不能因为线程之间资源的竞争而导致数据发生错乱,也不能因为有些线程因为调度器长时间没有调度从而导致饥饿问题。所以在线程中也有了同步与互斥,这里用 “也” 是因为进程中也有同步与互斥,今天来了解线程中的同步与互斥。
互斥量
我们为什么要有互斥量
首先,一个进程中的多个线程因为同处于一个虚拟地址空间中,所以相互之间大部分数据是共享的,从而在线程竞争中出现数据错乱的情况,我们来举例子来看一下
首先我们采用多个线程去竞争着去修改count的数据,我们定义初始的count为100,让其减少为0就可以了,我们看看会有什么结果。
如果对线程不了解或者相关的创建API点击线程概念、线程创建、等待、退出
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <pthread.h>
#define num 3
int count = 100;
void* MyFun(void* arg)
{
int j = (int)arg;
while (ticket >= 0)
{
usleep(1000);
printf("thread %d count %d\n", j, count);
count--;
}
return NULL;
}
int main()
{
pthread_t th[num];
int i = 0;
for (;i < num; ++i)
{
int ret = pthread_create(&th[i], NULL, MyFun, (void*)i);
if (ret != 0)
{
perror("pthread_create error\n");
exit(1);
}
}
i = 0;
for (; i < num; ++i)
{
pthread_join(th[i], NULL);
}
return 0;
}
我们先看看结果
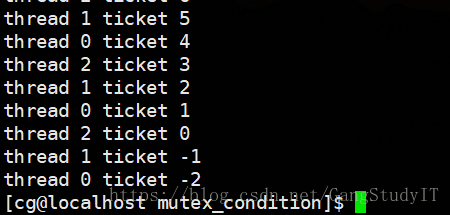
看到这个结果,如果仔细看代码就会发现,我们写的是代码count到0就退出,但是为什么会出现到-2呢?这里我们就解释一下
首先线程之间资源共享,所以随着cpu的调度,如果你是多核计算机,线程是可以同时访问一个共享资源,这个时候就会发生:
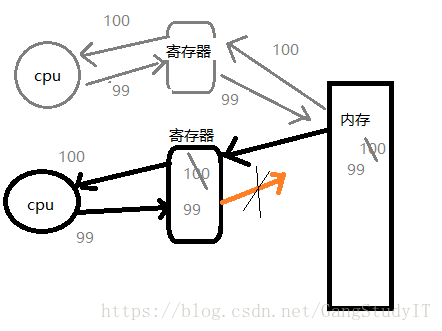
这只是其中的一种情况,还有可能在内存读到寄存器中的时候被切换掉等,就出现了数据错误的情况。
所以我们要加上互斥锁,让互斥的访问临界资源。
我们修改我们的代码:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <pthread.h>
#define num 3
pthread_mutex_t mutxe;
int ticket = 100;
void* MyFun(void* arg)
{
long j = (long)arg;
while (1)
{
usleep(1000);
pthread_mutex_lock(&mutxe);
if (ticket > 0)
{
printf("thread %lu ticket %d\n", j, ticket);
ticket--;
pthread_mutex_unlock(&mutxe);
}
else
{
pthread_mutex_unlock(&mutxe);
break;
}
}
return NULL;
}
int main()
{
pthread_mutex_init(&mutxe, NULL);
pthread_t th[num];
long i = 0;
for (;i < num; ++i)
{
int ret = pthread_create(&th[i], NULL, MyFun, (void*)i);
if (ret != 0)
{
perror("pthread_create error\n");
exit(1);
}
}
i = 0;
for (; i < num; ++i)
{
pthread_join(th[i], NULL);
}
pthread_mutex_destroy(&mutxe);
return 0;
}
我们看结果
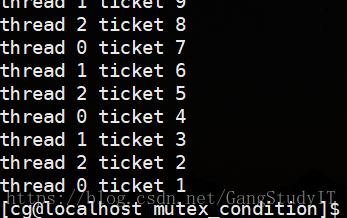
线程中互斥锁API
创建一个互斥锁,一般为全局量
// 当我们初始化为PTHREAD_MUTEX_INITIALIZER的时候互斥量不需要销毁
ptread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
int pthread_mutex_init(pthread_mutex_t* restrict mutex,\
const pthread_mutexattr_t* restrict attr);
int pthread_mutex_destroy(pthread_mutex_t* mutex);
int pthread_mutex_lock(pthread_mutex_t* mutex);
int pthread_mutex_unlock(pthread_mutex_t* mutex);
条件变量(同步)
首先我们还是了解一下为什么需要同步,条件变量。
为了防止竞争造成数据错乱,所以加上互斥锁,但是当两个线程同时访问时候,一个线程的访问速度快,一个访问慢,所以当一个线程不停的申请锁释放锁,但是里面的状态没有得到另一个线程改变,那么就会产生资源的浪费。
还有可能因为优先级问题,一个线程的优先级高,临界资源不能满足它的需求,它不停的申请锁释放锁,但是得不到满足,但是其它线程不等访问临界资源,从而造成饥饿问题。
问了解决这个问题,所以我们就有了一个同步的条件,来保证公平的访问,也可以说减少性能上的开销。
我们先看一下相关API
先需要有个同步变量和互斥锁
pthread_cond_t cond; // 同步变量,也一般在全局区
int pthread_cond_init(pthread_cond_t* restrict cond, const \
pthread_condattr_t* resttict attr);
int pthread_cond_destroy(pthread_cond_t* cond);
int pthread_cond_wait(pthread_cond_t* restrict cond, \
pthread_mutex_t* restrict mutex);
int pthread_cond_signal(pthread_cond_t* cond);
在这里我们要注意,在条件变量中的等待,为什么互斥变量,是因为 wait 方法所做的功能,pthread_cond_wait 函数在等待,要做三件事,先是解锁再等待等到信号后还要加锁,为什么一个函数要干这么多事情呢?
这里因为竞态条件产生的问题,必须要把这三个步骤合到一块为一个原子操作。
我们来画图分析
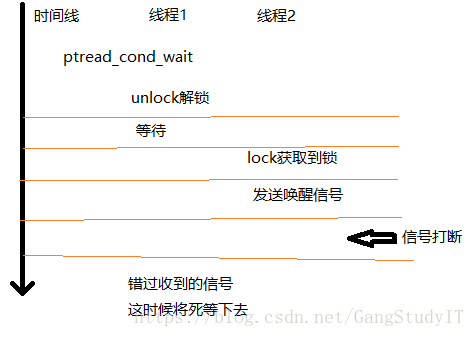
为了运用条件变量时候,不容易出错,最好运用
等待条件规范(自己觉得可靠)
pthread_mutex_lock(&mutex);
while (判断条件)
pthread_cond_wait(cond, mutex)
修改条件
pthread_mutex_unlock(&mutex);
给条件发送代码
pthread_mutex_lock(&mutex)
设置条件
pthread_cond_signal(cond);
pthread_mutex_unlock(&mutex);
生产者消费者模型
生产者消费者模型是线程中同步互斥的很典型的例子。
其中有三种关系:
1)生产者与生产者:互斥
2)消费者与消费者:互斥
3)生产者与消费者:同步互斥
生产者与消费者模型是基于一个场景,就是生产者在每次生产一个数据必须要放在一个仓库中,而消费者消费必须去仓库中拿数据,这样我们就会产生一些问题,比如,在生产者生产好数据去仓库放东西的时候,消费者是不能进去的,同行消费者取的时候,生产者也不能进去。当仓库为空的时候消费者就得等生产者放数据,仓库满了就必须等消费者取数据。所以为了满足上面的需求,我们就用同步与互斥来进行让他们有效的进行。
我们用代码模拟实现。我们用一个链表来模拟一个仓库。
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <pthread.h>
pthread_mutex_t mutex;
pthread_cond_t cond;
int count = 0;
typedef struct ListNode
{
struct ListNode* next;
int data;
}ListNode;
ListNode head;
ListNode* CreateNode(int value)
{
ListNode* new_node = (ListNode*)malloc(sizeof(ListNode));
new_node->next = NULL;
new_node->data = value;
return new_node;
}
void Init(ListNode* head)
{
head->data = 0;
head->next = NULL;
}
void Push(ListNode* head, int value)
{
if (head == NULL)
{
return;
}
ListNode* node = CreateNode(value);
ListNode* nex = head->next;
head->next = node;
node->next = nex;
}
void Pop(ListNode* head, int *top)
{
if (head == NULL)
{
return;
}
if (head->next == NULL)
{
return;
}
*top = head->next->data;
ListNode* node = head->next;
head->next = node->next;
free(node);
}
void* Producer(void* arg)
{
(void)arg;
while (1)
{
pthread_mutex_lock(&mutex);
Push(&head, count);
printf("Producer %d \n", head.next->data);
++count;
pthread_cond_signal(&cond);
pthread_mutex_unlock(&mutex);
sleep(1);
}
return NULL;
}
void* Consumer(void* arg)
{
(void)arg;
while (1)
{
int value = -1;
pthread_mutex_lock(&mutex);
while (head.next == NULL)
{
pthread_cond_wait(&cond, &mutex);
}
Pop(&head, &value);
printf("consumer %d\n",value);
pthread_mutex_unlock(&mutex);
usleep(100000);
}
return NULL;
}
int main()
{
Init(&head);
pthread_mutex_init(&mutex, NULL);
pthread_cond_init(&cond, NULL);
pthread_t producer, consumer;
pthread_create(&producer, NULL, Producer, NULL);
pthread_create(&consumer, NULL, Consumer, NULL);
pthread_join(producer, NULL);
pthread_join(consumer, NULL);
pthread_cond_destroy(&cond);
pthread_mutex_destroy(&mutex);
return 0;
}
读者写者问题
上面的生产者消费者模型是两个线程都在修改临界资源,那么我们的读者写者是一个线程修改多个线程读不修改的访问,这里我们要做到一下几点:
1)读者与读者之间是可以同时访问临界资源
2)写者与写者只能有一个,当然这里只有一个写者
3)读者和写者同时访问临界资源,写者优先
我们来看相关的函数的API
pthread_rwlock_t rwlock;
int pthread_rwlock_init(pthread_rwlock_t* restrict rwlock,\
phthread_rwlockattr_t* restrict attr);
int pthread_rwlock_destroy(pthread_rwlock_t *rwlock);
int pthread_rwlock_rdlock(pthread_rwlock_t* rwlock);
int pthread_rwlock_wrlock(pthread_rwlock_t* rwlock);
int pthread_rwlock_unlock(pthread_rwlock_t* rwlock);
对照上面的场景和和相关API我们来写代码
#include <stdio.h>
#include <unistd.h>
#include <pthread.h>
#include <stdlib.h>
#define num 5
pthread_rwlock_t lock;
int count = 0;
void *Reader(void* arg)
{
long i = (long)arg;
while (1)
{
pthread_rwlock_rdlock(&lock);
printf("Reader %lu count %d\n", i, count);
pthread_rwlock_unlock(&lock);
usleep(500000);
}
return NULL;
}
void *Writer(void* arg)
{
long i = (long)arg;
while (1)
{
pthread_rwlock_wrlock(&lock);
++count;
printf("Writer %lu count %d\n", i, count);
pthread_rwlock_unlock(&lock);
sleep(1);
}
return NULL;
}
int main()
{
pthread_rwlock_init(&lock, NULL);
pthread_t th[num];
long i = 0;
for (; i < num-1; ++i)
{
pthread_create(&th[i], NULL, Reader, (void*)i);
}
pthread_create(&th[num], NULL, Writer, (void*)1);
i = 0;
for (; i < num; ++i)
{
pthread_join(th[i], NULL);
}
pthread_rwlock_destroy(&lock);
return 0;
}
死锁问题
死锁的产生是因为我们为了保证线程或者进程访问临界资源时候保证真确的数据。但是又引来了新的问题,就是死锁。
死锁,在我们写代码的过程中,加锁就必须要解锁,不然就产生死锁,还有在一个线程中我们尝试对一个锁进行两次加锁操作也会产生死锁。
还有锁的数量和资源的数量相同,而每个线程需要两个资源,当同时对资源进行加锁,就会产生经典的哲学家进餐问题。这也是一种死锁。
我们总结一下:
死锁的形成
- 竞争不可抢占资源引起死锁
- 竞争可消耗资源引起死锁
- 进程推进顺序不当引起死锁
产生死锁的四个必要条件
那么我们怎么解决死锁问题呢?
预防死锁必须破坏四个必要条件之一
但是不能破坏互斥条件
如有错误,请多多指导!谢谢!
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)