title: Intel CPU 上使用 pmu-tools 进行 TopDown 分析
date: 2021-01-24 18:40
author: gatieme
tags:
- debug
- linux
- todown
categories:
- debug
thumbnail:
blogexcerpt: 这篇文章旨在帮助希望更好地分析其应用程序中性能瓶颈的人们. 有许多现有的方法可以进行性能分析, 但其中没有很多方法既健壮又正式. 而 TOPDOWN 则为大家进行软硬协同分析提供了无限可能. 本文通过 pmu-tools 入手帮助大家进行 TOPDOWN 分析.
| CSDN | GitHub | OSKernelLAB |
|---|
| 紫夜阑珊-青伶巷草 | LDD-LinuxDeviceDrivers | Intel CPU 上使用 pmu-tools 进行 TopDown 分析 |

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可, 转载请注明出处, 谢谢合作.
因本人技术水平和知识面有限, 内容如有纰漏或者需要修正的地方, 欢迎大家指正, 鄙人在此谢谢啦
1 Topdown & PMU-TOOLS 简介
1.1 TopDown 简介
程序的执行效率是完全依赖与 CPU 执行的, 软件的性能优化, 除了通用的一些优化外, 更重要的是软硬协同优化, 充分发挥 CPU 的硬件特性. 因此我们软件上的一些性能问题, 可以在 CPU 执行流程中的某一环直观的显现出来. 但是由于 CPU 的复杂性, 普通用户和软件开发人员很难也很少有经历去弄懂 CPU 架构, 更不用谈从 CPU 架构上理解软件上那一块出现的问题.
如果有一套软硬协同的分析方法, 可以帮助用户快速了解/分析/定界/定位 当前应用在 CPU 上的性能瓶颈, 用户就可以针对当前 CPU 有针对性的修改自己的程序, 以充分利用当前的硬件资源.
因此 Intel 提出了一套软硬协同进行性能分析的更正式的方法. 它称为自上而下的微体系结构分析方法(TMAM) (<英特尔®64和IA-32架构优化参考手册> 附录B.1). 在这种方法论中, 我们尝试从高层组件(如前端, 后端, 退休, 分支预测器)开始检测导致执行停滞的原因, 并缩小性能低效的根源.
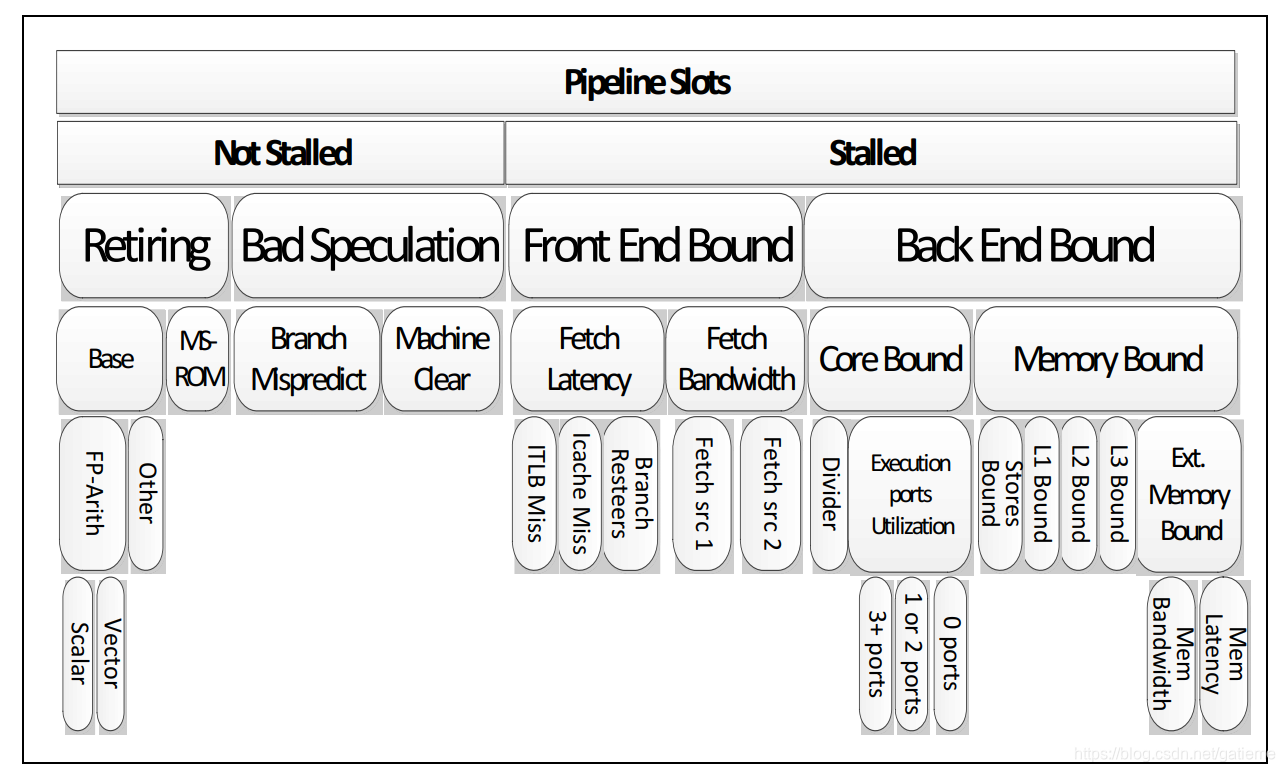
进行 TOPDOWN 分析的过程通过是一个不断迭代优化的过程, 他的通常流程如下
-
确定性能问题的类型;
1.1. 我们可以先从高层次的划分中, 先粗粒度的当前性能问题主要问题是在哪个阶段(类型).
1.2. 接着从低层次的划分中, 继续明确具体是哪块出的问题.
-
使用精确事件 PEBS(X86)/SPE(ARM64) 在代码中找到确切的位置;
2.1. 如果条件运行, 精确的抓取对应的 PMU 事件, 明确代码中出现问题的原因和位置.
-
解决性能问题后, 重新开始 1.
3.1. 修改代码, 解决性能问题, 然后重新进行 TOPDOWN 分析, 验证修改是否 OK, 看是否还有其他瓶颈或者是否引入其他问题.
1.2 TopDown 资料汇总
Top-down Microarchitecture Analysis Method(TMAM)资料
之前介绍过TMAM的具体内容, 在这里对网络上相关的信息和资料做一个汇总:
Tuning Applications Using a Top-down Microarchitecture Analysis Method
Top-down Microarchitecture Analysis through Linux perf and toplev tools
A Top-Down method for performance analysis and counters architecture
Performance_Analysis_in_a_Nutshell
Top Down Analysis Never lost with Xeon® perf. counters
How TMA* Addresses Challenges in Modern Servers and Enhancements Coming in IceLake
几句话说清楚15:Top-Down性能分析方法资料及Toplev使用
让 CPU 黑盒不再黑盒
1.3 PMU-TOOLS 简介
pmu-tools 是 Intel 的 Adni Kleen 开发的帮助用户和开发者在 Intel X86 CPU 下进行 TOPDOWN 分析的开源工具包, 可以定位和分析 CPU Bound 代码的瓶颈, 不能识别其他(Not bound by CPU)代码的瓶颈.
2 PMU-TOOLS 安装
2.1 下载 github 仓库
git clone https://github.com/andikleen/pmu-tools
2.2 下载 PMU 表
pmu-tools 完成的具体工作就是采集 PMU 数据, 并按照微架构既定的公式计算 topdown 数据, 但是不同的微架构和 CPU 所支持的 PMU 事件是不同的, 因此 pmu-tools提供了一套完成的映射表, 标记不同 CPU 所支持的 PMU 事件映射表, 以及 topdown 如何使用这些 PMU 数据去计算, 参见 Intel 01.day perfmon 下载.
pmu-tools 的工具在第一次运行的时会通过 event_download.py 把本机环境的 PMU 映射表自动下载下来, 但是前提是你的机器能正常连接 01.day 的网络. 很抱歉我司内部的服务器都是不行的, 因此 pmu-tools 也提供了手动下载的方式.
因此当我们的环境根本无法连接外部网络的时候, 我们只能通过其他机器下载实际目标环境的事件映射表下载到另一个系统上, 有点交叉编译的意思.
printf "GenuineIntel-6-%X\n" $(awk '/model\s+:/ { print $3 ; exit } ' /proc/cpuinfo )
cpu的型号信息是由 vendor_id/cpu_family/model/stepping 等几个标记的.
他其实标记了当前 CPU 是哪个系列那一代的产品, 对应的就是其微架构以及版本信息.
注意我们使用了 %X 按照 16 进制来打印
注意上面的命令显示制定了 vendor_id 等信息, 因为当前服务器端的 CPU 前面基本默认是 GenuineIntel-6 等.
不过如果我们是其他机器, 最好查看下 cpufino 信息确认.
比如我这边机器的 CPU 型号为 :
processor : 7
vendor_id : GenuineIntel`
cpu family : 6
model : 85
model name : Intel(R) Xeon(R) Gold 6161 CPU @ 2.20GHz
stepping : 4
microcode : 0x1
对应的结果就是 GenuineIntel-6-55-4.
我们也可以直接用 -v 打出来 CPU 信息.
$ python ./event_download.py -v
My CPU GenuineIntel-6-55-4
如果你可以链接网络, 那么这个命令就会把你 host 机器上的 PMU 映射表下载下来. 否则你拿到了 CPU 型号, 那么你可以直接显式指定 CPU 型号来获取.
$ python ./event_download.py GenuineIntel-6-55-4
Downloading https://download.01.org/perfmon/mapfile.csv to mapfile.csv
Downloading https://download.01.org/perfmon/SKX/skylakex_core_v1.24.json to GenuineIntel-6-55-4-core.json
Downloading https://download.01.org/perfmon/SKX/skylakex_matrix_v1.24.json to GenuineIntel-6-55-4-offcore.json
Downloading https://download.01.org/perfmon/SKX/skylakex_fp_arith_inst_v1.24.json to GenuineIntel-6-55-4-fp_arith_inst.json
Downloading https://download.01.org/perfmon/SKX/skylakex_uncore_v1.24.json to GenuineIntel-6-55-4-uncore.json
Downloading https://download.01.org/perfmon/SKX/skylakex_uncore_v1.24_experimental.json to GenuineIntel-6-55-4-uncoreexperimental.json
my event list /home/chengjian/.cache/pmu-events/GenuineIntel-6-55-4-core.json
最终 PMU 的映射表文件, 将被保存在 ~/.cache/pmu-events. 将此目录打包后, 放到目标机器上解压即可.
当前我们也可以使用 event_download.py -a 下载所有可用的 PMU 事件映射表. 然后通过如下环境变量, 将 PMU 映射手动指向正确的文件.
export EVENTMAP=~/.cache/pmu-events/GenuineIntel-6-55-4-core.json
export OFFCORE=~/.cache/pmu-events/GenuineIntel-6-55-4-offcore.json
export UNCORE=~/.cache/pmu-events/GenuineIntel-6-55-4-uncore.json
最后两个 offcore/uncore 的设置是可选的. 或者可以将名称设置为 CPU 标识符(GenuineIntel-FAM-MODEL), 这将覆盖当前 CPU.
另一种方法是显式设置目标机器的 PMU 映射文件存储路径( 注意是在相对于它的 pmu-events 目录中).
export XDG_CACHE_DIR=/opt/cache
则将从 /opt/cache/pmu-events 中查找对应的映射文件.
3 PMU-TOOLS 使用
3.1 准备工作
特别需要注意的是, pmu-tools 的大多数工作在使用期间都建议我们禁用 NMI watchdog, 并以 root 身份运行.
因为 X86_64 的 NMI_WATCHDOG 使用了一些 PMU 的寄存器, 同时我们在抓取的时候可能耗时过长, 存在出发 NMI_WATCHDOG 的影响.
Consider disabling nmi watchdog to minimize multiplexing
(echo 0 > /proc/sys/kernel/nmi_watchdog as root)
使用如下命令关闭
sysctl -p 'kernel.nmi_watchdog=0'
OR
echo 0 > /proc/sys/kernel/nmi_watchdog
3.1 toplev
toplev 是一个基于 perf 和 TMAM 方法的应用性能分析工具. 从之前的介绍文章中可以了解到 TMAM 本质上是对 CPU Performance Counter 的整理和加工. 取得 Performance Counter 的读数需要 perf 来协助, 对读数的计算进而明确是 Frondend bound 还是 Backend bound 等等.
在最终计算之前, 你大概需要做三件事:
- 明确 CPU 型号, 因为不同的 CPU, 对应的 PMU 也不一样
- 读取 TMAM 需要的 perf event 读数
- 按 TMAM 规定的算法计算, 具体算法在这个 Excel 表格里
这三步可以自动化地由程序来做. 本质上 toplev 就是在做这件事.
toplev的Github地址: https://github.com/andikleen/pmu-tools
另外补充一下, TMAM作为一种Top-down方法, 它一定是分级的. 通过上一级的结果下钻, 最终定位性能瓶颈. 那么toplev在执行的时候, 也一定是包含这个“等级”概念的.
下面是 toplev 使用方法的资料:
toplev manual
pmu-tools, part II: toplev
基本上都是由 toplev 的开发者自己写的, 可以作为一个 Quick Start Guide.
首先可以进行 L1 级别的检查
$ python toplev.py --core S0-C0 -l1 -v --no-desc taskset -c 0 ./a.out
...
S0-C0 FE Frontend_Bound: % Slots 19.2 <
S0-C0 BAD Bad_Speculation: % Slots 4.6 <
S0-C0 BE Backend_Bound: % Slots 4.1 <
S0-C0 RET Retiring: % Slots 72.1 <
S0-C0-T0 MUX: % 100.0
S0-C0-T1 MUX: % 100.0
接着进行 level2/level3 级别的检查, 最大支持到 level6.
$ python toplev.py --core S0-C0 -l2 -v --no-desc taskset -c 0 ./a.out
$ python toplev.py --core S0-C0 -l3 -v --no-desc taskset -c 0 ./a.out
toplev 工具是基于 perf 等工具进行采样的, 因此多数这些工作支持的行为, toplev 也是支持的.
-
默认情况下, toplev 同时测量内核和用户代码. 如果只对用户代码感兴趣, 则可以使用 --user 选项. 这往往会减少测量噪声, 因为中断被过滤掉了. 还有一个 --kernel 选项用来测量内核代码.
-
在具有多个阶段的复杂工作负载上, 测量间隔也是有用的. 这可以用 -I xxxi 选项指定, xxx 是间隔的毫秒数. perf 要求时间间隔至少需要 100ms. toplev 将输出每个间隔的测量值. 这往往会产生大量的数据, 所以绘制输出很有必要.
更多详细信息可以参照 topdev 的 help 帮助文档.
4 参考资料
Top-Down performance analysis methodology
-
本作品/博文 ( AderStep-紫夜阑珊-青伶巷草 Copyright ©2013-2017 ), 由 成坚(gatieme) 创作.
-
采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可. 欢迎转载、使用、重新发布, 但务必保留文章署名成坚gatieme ( 包含链接: http://blog.csdn.net/gatieme ), 不得用于商业目的.
-
基于本文修改后的作品务必以相同的许可发布. 如有任何疑问, 请与我联系.
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)