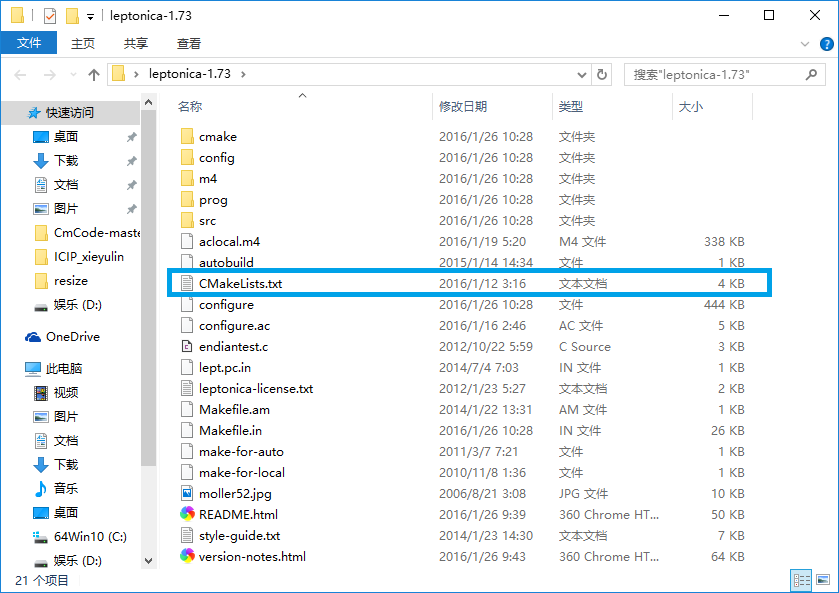
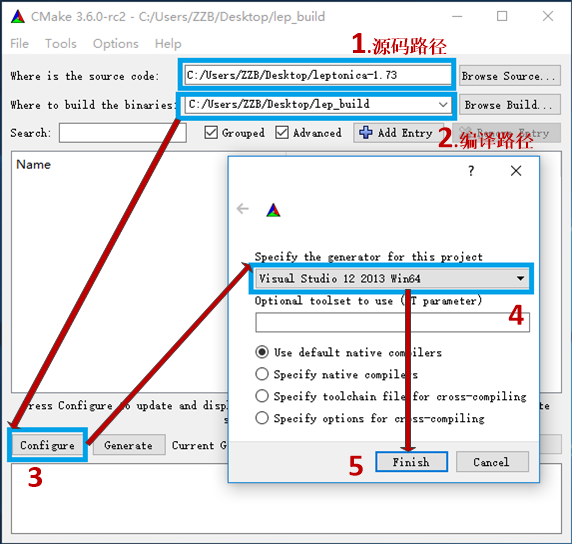
上次写了Tesseract-OCR 3.02命令行程序的简单使用,同时官网上给出了3.02版本基于VS2008平台的编译工程。但对于最新源码只是说了在VS2015(3.05)和VS2013(3.04)的编译,还是英文的,且网上关于最新源码的编译不是很多,所以这里我就说一下其最新源码的编译。因为Tesseract依赖于leptonica,所以这里先讲一下最新的leptonica编译。 图1.源码目录 按装完成Cmake以后,我们先建立一个空文件保存leptonica编译完的工程文件,Cmake编译步骤如下所示: 图2.编译步骤 a.在Cmake界面,首先设定好源码路径,以及编译文件输出路径即上图的1,2。 b.在路径设定完成以后,点击3处的Configure按钮进行编译,此时会弹出提示框让我们选择使用的编译器,这个按自己要求去选4,选定以后点击5处的Finish就可以了。编译后出现下面情况:
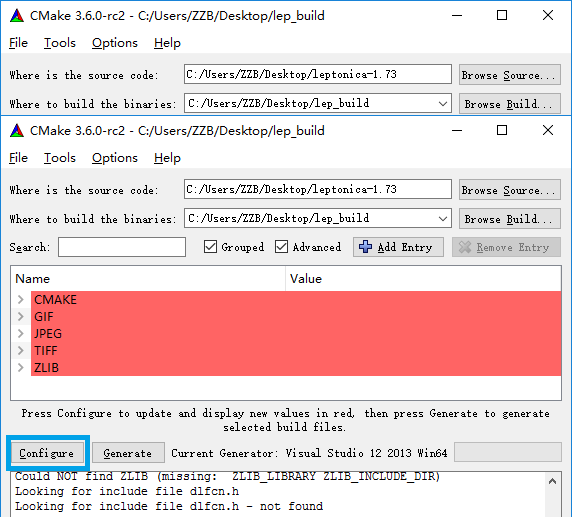
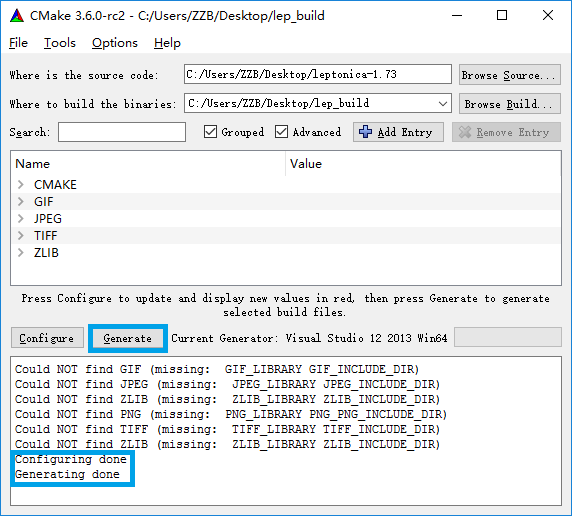
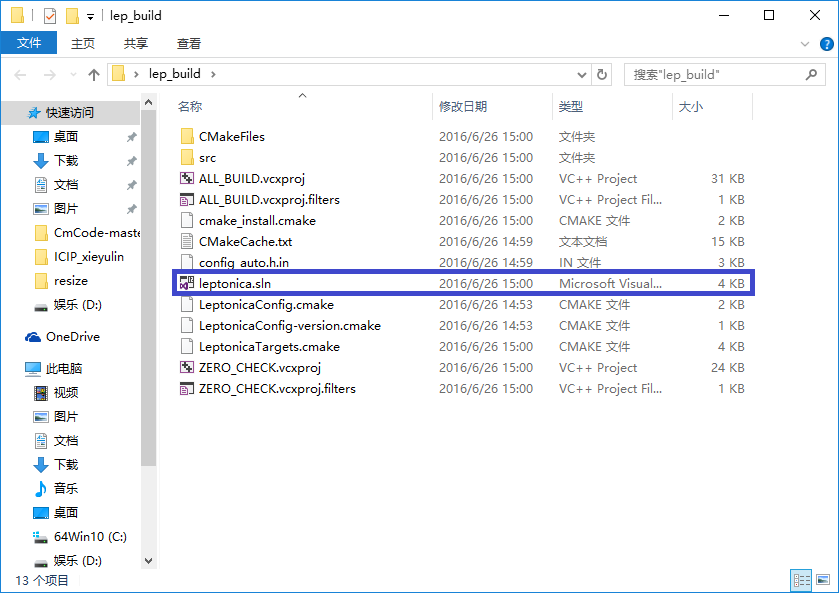
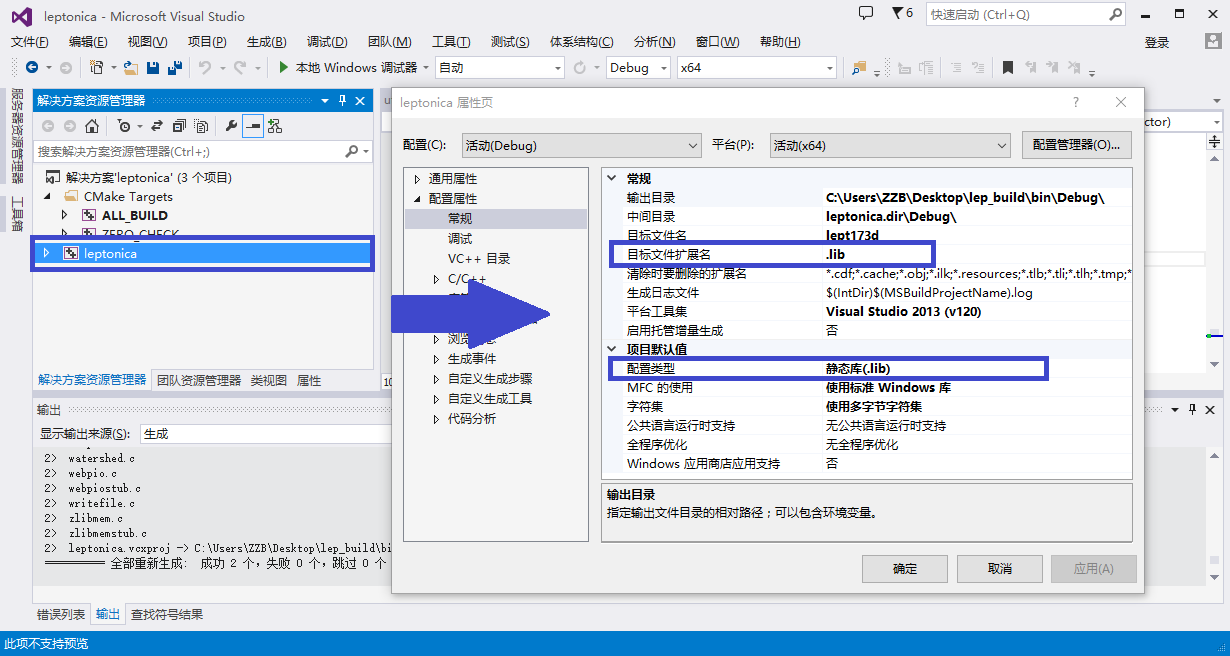
c.这时会出现红色的提示,因为并没有弹出错误提示所以不用管他,图中红色部分GIF,JPEG,TIFF,ZLIB都是leptonica所需要的图片识别库,大家可以下载尝试编译。这里我们不管他,再次点击Configure按钮进行编译就好了。 图4.编译完成 d.编译完成以后,点击Generate进行项目生成即可,然后打开我们新建的编译保存文件夹,(我的是lep_build)如图5: 5.编译后的文件目录 e.然后双击图中蓝框中的解决方案,用VS打开,我这里是VS2013,然后就可以编译出我们想要的库文件了,Cmake的默认生成文件是.dll所以我们这里需要配置一下项目。如图6:
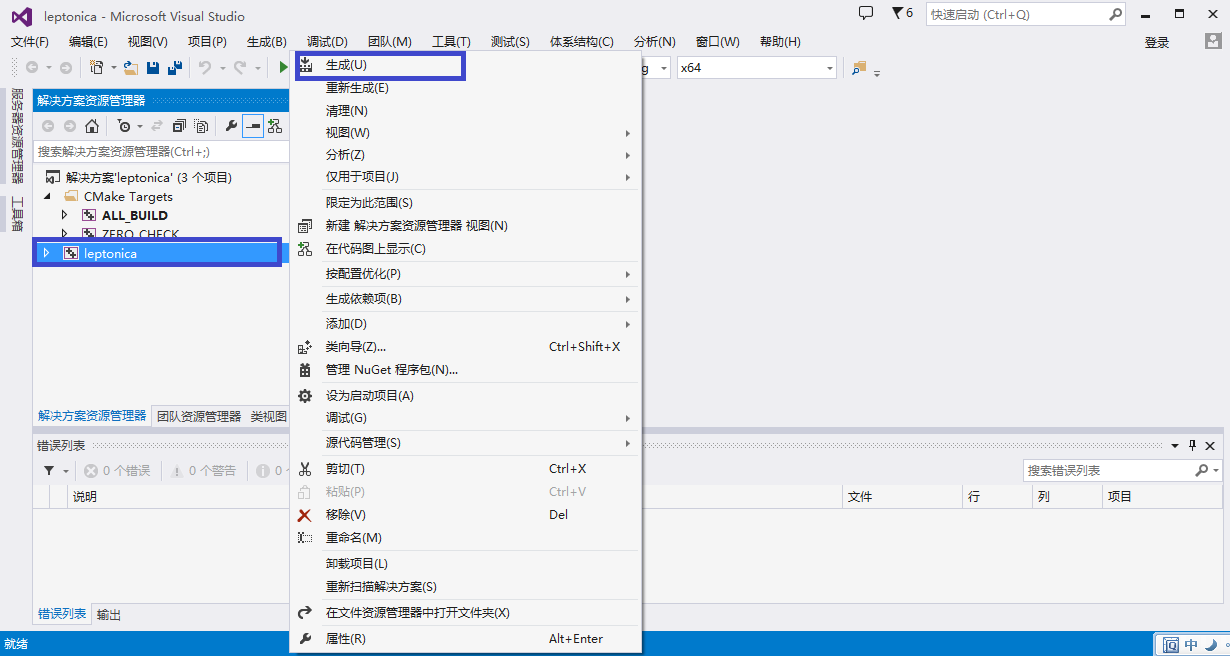
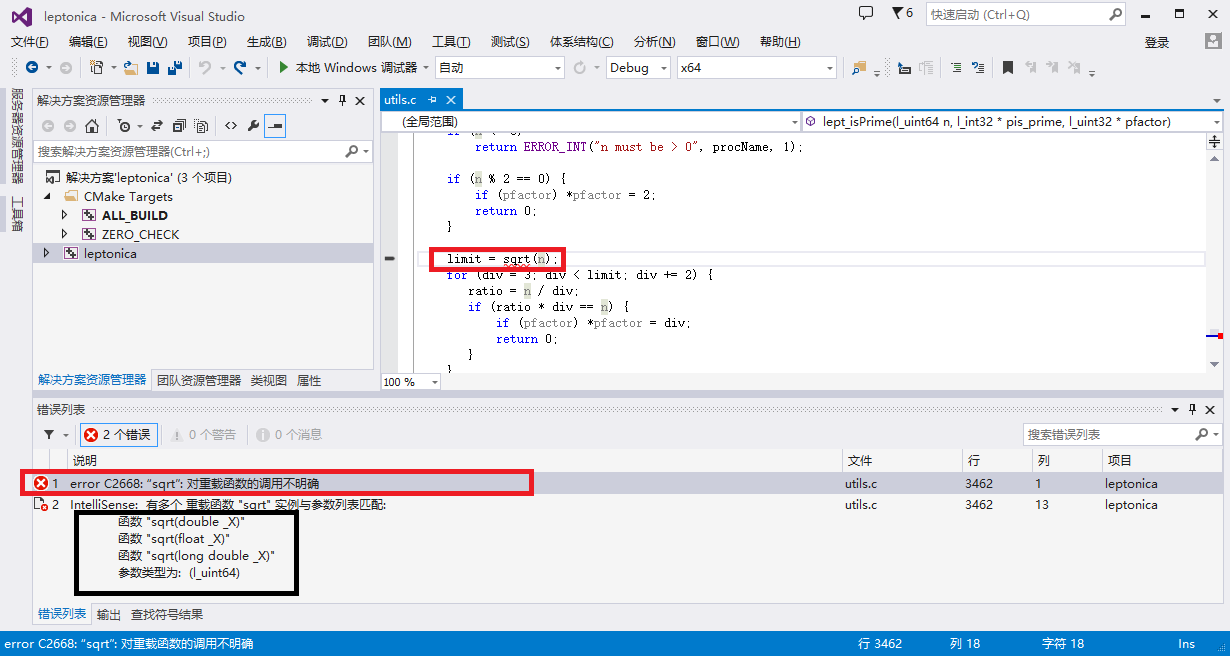
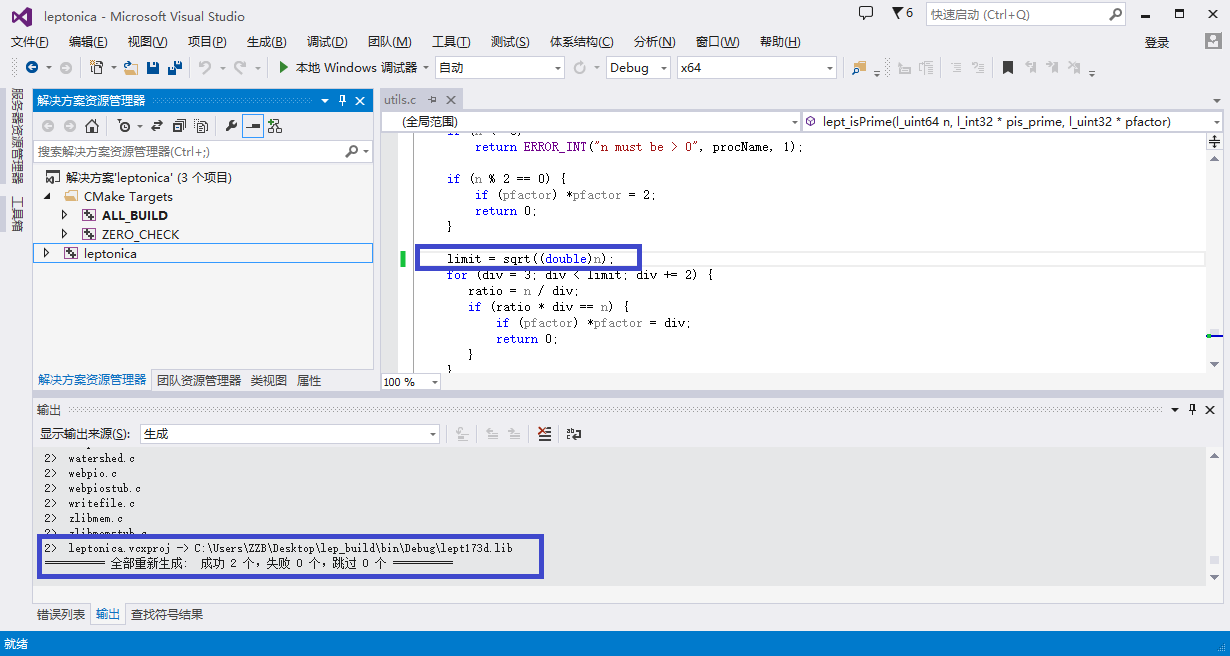
f.完成后,就可以编译了,这里我们生成静态库文件,右键leptonica工程生成: 图7.右键生成 注意:在编译过程中如果出现错误,可以根据自己错误情况修改一下即可,比如我的就出现下图的参数类型不匹配的错误: 图8.可能遇到的错误 这里是应为n的定义类型与sqrt()函数输入类型不匹配的问题,所以我们这里稍微改一下就好了,如下图: 图9.编译成功 这里所做的修改就是对n进行下强制变换。 g.最后我们就可以在相应的文件爱夹下得到库文件了,我用的是debug模式所以就在该文件下:
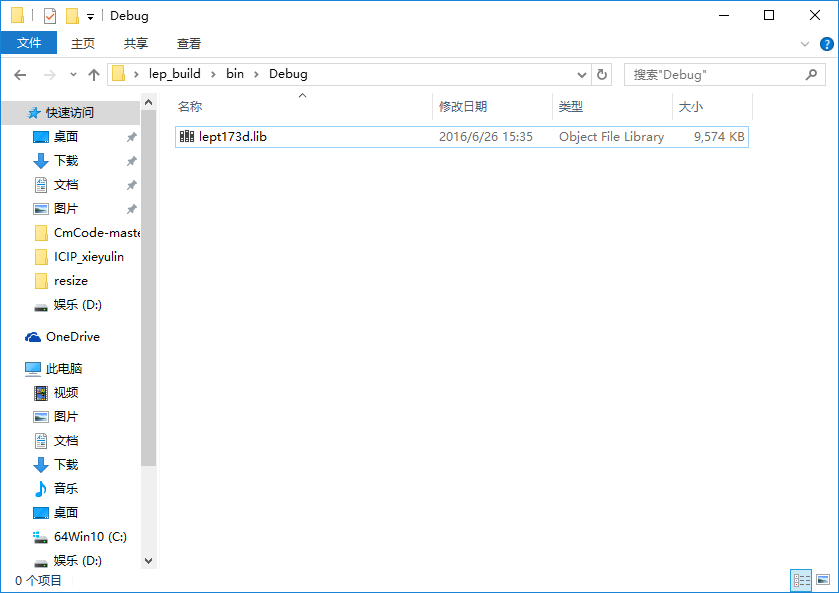
这样就完成编译了,这是leptonica源码编译,同样适用VS2008, 上述过程是本人试验所得,要是有什么错误,还望指正。我把我自己编译的工程文件传一下:lep_build,下次再说Tesseract最新源码的编译。