出现的原因
原因:
由于我们申请的空间有时会太小,而频繁的去申请这样的小空间就会造成太多小额区块造成的内存碎片。对于这些小额区块所带来的不仅仅是内存碎片,更是配置时的额外负担。而额外的负担也是一个大问题,因为我们还要靠这一部分去管理我们所使用的内存空间,如果我们所需要的空间越小,那么相比于开辟的空间来说,额外负担越大,就越显得浪费。
二级空间配置器的原理
1.解决问题:对于上述的问题,二级空间配置器是这样解决的:
①:首先,它会用128字节的大小去划分我们申请的内存是使用一级空间配置器和二级空间配置的,如果超过申请的内存128字节,那么就用一级空间配置器去申请空间,如果不大于128字节,就用二级空间配置器来申请内存。
②:其次,它是以内存池的方式来管理的。
③:内存池:而内存池的管理方式为哈希桶加自由链表,每次申请节点的时候,我们在对应哈希桶下的自由链表申请一块大的内存空间,然后用户需要的我们给其用,这样等第二次申请内存的时候,直接从内存池中去拿即可,这样就避免了对于小空间不断的对内存进行申请的问题了,提高了运行效率。当然,如果当用户释放了自己在内存池中拿的空间,那么这个空间还是会被返回来,等下一次分配的时候,就可以用这块内存了。
④:节点的选择:申请内存小,那么就会显得管理内存的额外负担是大的,这个问题是这样解决的---------申请节点的时候,我们使用的是联合体的结构,这样直接提高了我们对内存的利用率,其底层的union实现如下:
union obj
{
union obj* free_list_link;//指向下一个节点
char client_data[1];//用户存储的数据
}
⑤:自由链表和哈希桶的管理方式:
SGI二级空间配置器会将用户需要的内存会自动上调至8的倍数,这是为了方便去管理数据,所以对于128个字节一共维护了16个自由链表如下:

而当我们对应申请内存的时候,他会对申请的内存进行上调,然后上调完找到对应的哈希桶下的自由链表,然后去取数据或者去填充完成后再去取数据。
上调函数的底层实现如下:
static size_t ROUND_UP(size_t bytes)
{
return(((bytes)+_ALIGN-1) & ~(_ALIGN-1));
}
其中bytes是用户所需要的数据,而_ALIGN为8,因为是通过8的倍数来去申请内存的。
例如:我们需要用9个内存,那么上调函数会给我们上调到16个字节,然后在对应16个字节下的自由链表进行使用。
2.自由链表对空间如何开辟和使用:
①:开辟
对于用户需要取申请空间的时候,二级空间配置器的上调函数会将将其上调至8的倍数,然后再通过对应的哈希函数找到其哈希桶的下标,然后对其进行开辟空间。
首先,哈希函数的定义如下:
static size_t FREELIST_INDEX(size_t bytes)
{
return ((bytes)+_ALIGN-1)/_ALIGN-1);
}
其中,bytes是我们上调后的数据,而_ALIGN是8。
其次,对于其内存的开辟,他不会开辟的只有需要的大小,他会一次性开辟大的内存,对于SGI的二级内存配置他会一次性开辟用户所需要的内存的20倍。然后将用户所需要的第一个节点返回给用户去使用,而后的19个节点会交给哈希桶对应的自由链表去管理。
例如下图:
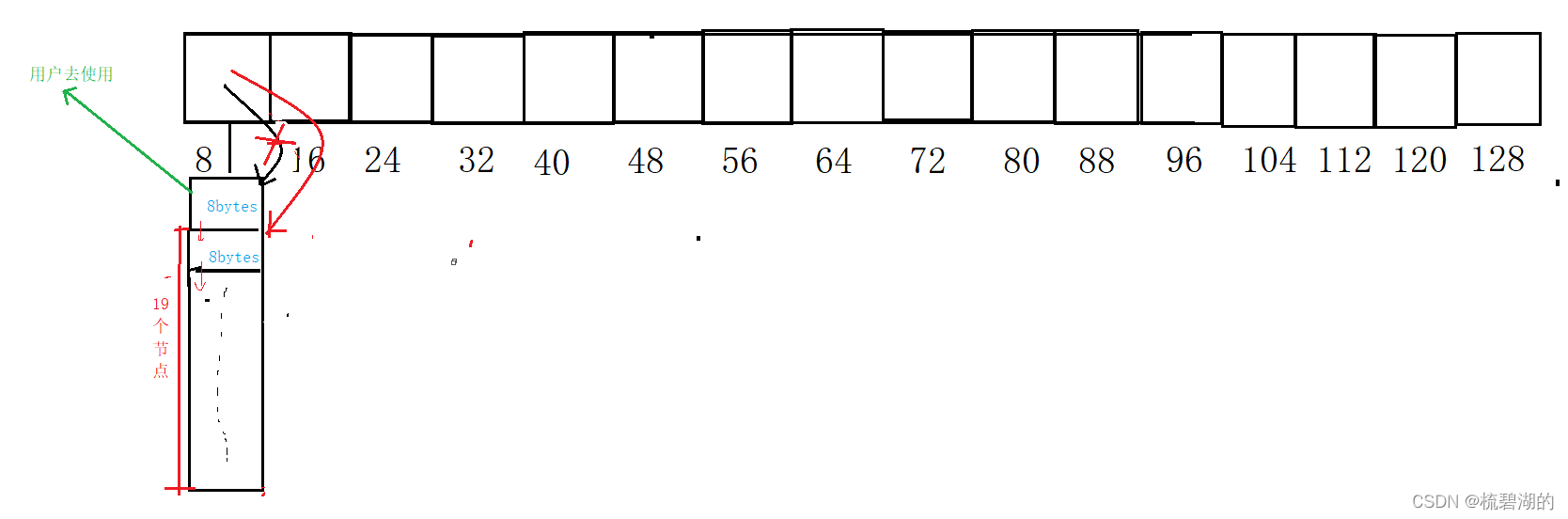
他会让自由链表直接管理第二块内存了,第一块内存给客户去使用。
而当客户释放了对应的那块内存,自然会让自由链表指向第二个节的哪个指针指回来,继续管理释放后的加上以前管理的全部内存,等待用户的下一次使用。
②:使用:
首先对于使用内存他会有三个情况:
- 情况一:如果我们需要用的内存(这个内存是20倍后的),在内存池中是存在的,可以直接拿来用的,那么就直接拿来用。
- 情况二:如果我们需要的已经20倍后的内存在原有的内存池中是没有的,但是对于用户目前需要使用的内存是存在的,那么就先拿来用。
- 情况三:我们需要内存的最低要求都没有,这个时候我们就需要对底层去申请空间了,但是在申请内存之前,我们会将内存池中可用的内存先全部编起来,然后去申请更大块的内存(此时可能会出现意外,如果出现意外,他会将内存池中的可以释放的内存先释放,然后去在递归调用),(如果在上一步的意外之后,还是没有得到解决,就只能通过一级空间配置器去解决了)然后再递归调用。
二级空间配置器的底层代码解析
#include<iostream>
#include<new>
#include<thread>
using namespace std;
/二级配置器的模拟实现
enum{_ALIGN = 8};//代表小区块的上调边界
enum{_MAX_BYTES = 128};//代表小区块的上限
enum{ _NFREELISTS = _MAX_BYTES / _ALIGN };//代表自由链表的数量
template<bool threads,int inst>
class _default_alloc_template
{
public:
static void* allocate(size_t n);//申请空间函数
static void deallocate(void* p, size_t n);//释放空间函数
static void* reallocate(void* p, size_t old_sz, size_t new_sz);//空间不够,需要添加的申请空间函数
private:
static size_t ROUND_UP(size_t bytes)//上调函数:申请空间如果不是8的倍数,那么就上调到8的倍数。
{ //主要是为了refill函数的工作。
return (bytes + (_ALIGN - 1) & ~(_AlIGN - 1));
}
private:
union obj//自由链表的节点构造,用了联合体也是大大的提高了内存的利用率。
{
union obj* free_list_link;
char client_data[1];//用户需要存的数据
};
private:
static obj* free_list[_NFREELISTS];//哈希桶
static size_t freelist_index(size_t bytes)//找到要在哪个哈希桶里面进行操作。
{
return (((bytes)+_ALIGN - 1) / _ALIGN - 1);
}
static void* refill(size_t n);//填充函数,如果要操作的哈希桶为空,那么就得先填充好空间,再从里面拿空间。
static char* chunk_alloc(size_t size, int& nobjs);//从内存池中取空间。
private:
static char* start_free;//内存池起始位置
static char* end_free;//内存池终止位置
static size_t heap_size;//一个哈希桶下的自由链表的大小
};
//初始化阶段,将指针和自由链表开始都置为空。
template<bool threads, int inst>
char* _default_alloc_template<threads, inst>::start_free = 0;
template<bool threads, int inst>
char* _default_alloc_template<threads, inst>::end_free = 0;
template<bool threads, int inst>
size_t _default_alloc_template<threads, inst>::heap_size = 0;
template<bool threads, int inst>
obj* _default_alloc_template<threads, inst>::free_list[_NFREELISTS] = { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 };
//申请空间
template<bool threads, int inst>
void* _default_alloc_template<threads, inst>::allocate(size_t n)
{
if (n > 128)//如果申请的字节数大于128,那么就交给一级空间配置器去操作。
return (malloc_alloc::allocate(n));
obj** my_free_list;
obj* result;
my_free_list = free_list + freelist_index(n);//找到要使用的哈希桶
result = *my_free_list;
if (result == 0)//此时这个哈希桶还未初始化
{
void* r = refill(ROUND_UP(n));
return r;
}
*my_free_list = result->free_list_link;//修改哈希桶的指针,让其指向未被利用的空间。
return (result);
}
template<bool threads, int inst>
void* _default_alloc_template<threads, inst>::refill(size_t n)
{
int nobjs = 20;//这是我们要开辟多少个需要的字节个数的倍数。
char* chunk = chunk_alloc(n, nobjs);//这个函数主要是帮助我们去获取空间,获取我们需要申请的总空间大小。
obj** my_free_list;//自由链表
obj* result;//返回的空间大小
obj* current_obj;//当前的节点
obj* next_obj;//下一个节点
int i;
if (nobjs == 1)//我们只需要一个节点,那么就直接将其返回即可。(就可以不用调整free_list了)
return (chunk);
//申请节点过多,需要调整free_list
my_free_list = free_list + freelist_index(n);
result = (obj*)chunk;//对申请来的空间进行强制转换。
*my_free_list = next_obj = (obj*)(chunk + n);//让对应的哈希桶指向的自由链表进行修改。
//连接自由链表的各个节点
for (i = 1;; ++i)
{
current_obj = next_obj;//让当前节点指向下一个节点
next_obj = (obj*)((char*)next_obj + n);//让下一个节点指向其下一个其加上一个节点的大小的位置。
if (nobjs - 1 == i)//当此时i等于申请的最后一个节点的时候,那么就可以让其下一个节点为空,因为就申请了这么多小节点
{
current_obj->free_list_link = 0;
break;
}
else
{
current_obj->free_list_link = next_obj;//那就让他们再连接起来。
}
}
return (result);
}
template<bool threads, int inst>
char* _default_alloc_template<threads, inst>::chunk_alloc(size_t size, int& nobjs)
{
char* result;//返回的内存
size_t total_bytes = size* nobjs;
size_t left_bytes = end_free - start_free;//内存池还剩多少内存。
if (left_bytes >= total_bytes)//如果剩余的内存量大于或者等于需要的申请的内存,那么直接拿就完了。
{
result = start_free;
start_free += total_bytes;
return(result);
}
else if (left_bytes >= size)//此时剩余内存量不够申请的内存,但是可以满足正准备需要的,那么还可以先拿出来这部分。
{
nobjs = left_bytes / size;//修改nobjs,此时能申请几个就申请几个,要求不那么严格了,先满足当下需要,其他再说。
total_bytes = size*nobjs;
result = start_free;
start_free += total_bytes;
return(result);
}
else//此时就是大问题了,内存连最基本的需求都不够了,这下得去申请空间了。
{
size_t bytes_to_get = 2 * total_bytes + ROUND_UP(heap_size >> 4);//反正此时都摊牌了,给底层要空间了,那么必须得多要。
if (bytes_left > 0)//但是在要之前,先看看内存池中到底还有没有内存,如果有,先垫着。
{
obj** my_free_list = free_list + freelist_index(bytes_left);
((obj*)start_free)->free_list_link = *my_free_list;
*my_free_list = (obj*)start_free;
}
//然后去malloc申请空间
start_free = (char*)malloc(bytes_to_get);
if (start_free == 0)//申请空间失败
{
int i;
obj** my_free_list;
obj* p;
for (i = size; i <= _MAX_BYTES; i += _ALIGN)//那就不去自己申请了,先保住我们自己所剩余的内存,拿去用。
{
my_free_list = free_list + freelist_index(i);
p = *my_free_list;
if (p != 0)//如果p所指的自由链表下面还有空间,那么就直接拿来用。
{
*my_free_list = p->free_list_link;
start_free = (char*)p;
end_free = start_free + i;
return(chunk_alloc(size, nobjs));//递归调用,就是看拿来用的内存如果够了那么就可以直接先用着。
}
}
end_free = 0;
start_free = (char*)malloc_alloc::allocate(bytes_to_get);//如果不够,那就用一级内存配置器的行为去申请空间,此时有内存申请失败的处理,安全些。
}
heap _size += bytes_to_get;
end_free = start_free + bytes_to_get;
return(chunk_alloc(size, nobjs));
}
}