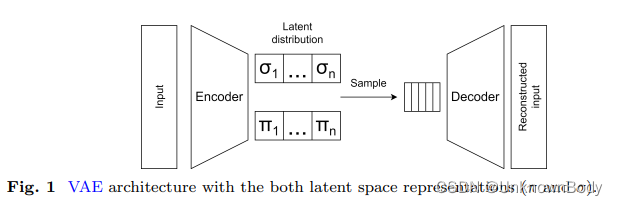
自深度学习(DL)出现以来,研究和工业界的一项重要工作就是解决和改进监督训练任务。监督学习需要具有各种特征的数据集,其中每个样本都必须标记。使用监督学习技术解决的最具代表性的问题是分类、回归和结构化模式输出问题。 传统上,用于监督任务的机器学习(ML)模型属于区分模型类别。区分建模与监督学习同义,或使用标记数据集学习将输入映射到输出的函数。从形式的角度来看,区分建模估计
p
(
y
∣
x
)
p(y|x)
p(y∣x), 即根据观察
x
x
x标签的概率
y
y
y. 然而,当试图在不完整、不平衡或隐私受到挑战的数据集上训练其中一个模型时,存在一个主要问题。通常,这些问题通过预处理数据集技术(如子采样)解决,或者在数据集不够大的情况下,通过DA技术解决。 然而,随着问题的出现,技术不断发展以解决这些边界。近年来,人工神经网络(ANN)及其在DL领域的应用经历了一个巨大的发展时期。虽然有多种模型促成了这一扩展,但Ian Goodfellow提出的最具革命性的模型之一出现在2014年,他提出了生成对抗网络(GANs)。 GANs肯定不是有史以来引入的最早的生成式体系结构;早在1987年,Yann Lecun就在他的论文中提出了自编码器(AE)架构,该架构能够生成作为输入接收的数据修改。但是,直到将定向概率模型并入AE架构(也称为变分自动编码器(VAE)[58]),模型才开始显示为能够生成合成数据。 尽管这些网络显示了令人印象深刻的结果,但GANs的能力已被证明遥遥领先,并在图像领域取得了令人印象的结果。然而,这不是唯一的应用领域;合成数据生成是合成敏感数据(如电信领域的敏感数据)的强大推动力。 因此,本文旨在回顾DA和数据生成的所有现有技术,并回顾每种技术的积极和消极方面。
GANs是一种基于两个神经网络(NN)之间竞争的生成神经模型,由Ian Goodfello于2014年首次引入。该体系结构的目标是复制给定的数据分布,以合成分布的新样本。为了实现这一目标,GAN架构由生成器(G)模型和鉴别器(D)模型组成。前者负责生成数据分布的合成样本,而后者试图区分真实样本和合成样本。 为了实现生成与输入数据分布不可区分的全新数据的目标,两个模型相互作用。G生成试图复制分布的样本,而不复制分布,而D区分真实样本和假样本。这样,当D对两个分布进行微分时,它会负反馈G;另一方面,当D不能区分每个分布时,其正反馈G。在这样做的过程中,G演变为欺骗D。同时,当正确进行区分时,D得到正奖励。 这种竞争鼓励两个网络一起进化。如果D在其任务中失败,G将不会进化,因为不管合成样本的质量如何,它总是会成功。尽管如果D总是完美区分两种分布,G将无法欺骗D,使其不可能进化。 标准GAN架构如图2所示。 从数学角度来看,这种竞争行为是基于博弈论的,两个参与者在零和博弈中竞争。D估计
p
(
y
∣
x
)
p(y|x)
p(y∣x), 其中