前言
纸上的来终觉浅,绝知此事要躬行。
naive写法
一个矩阵的乘法简单如下:C=A*B, 一般用gemm(A,B,C,M,N,K)来表示,其中的m,n,k代表的位置如下,默认是k表示消失的纬度。

上图的红色虚线围起来的是一个block要负责的数据区域,具体的代码如下:
__global__
void matrixMul(const float *A, const float *B, float *C, int M, int N, int K)
{
int col = blockIdx.x * blockDim.x + threadIdx.x;
int row = blockIdx.y * blockDim.y + threadIdx.y;
if(row < M && col < N)
{
float c = 0;
for(int i = 0; i < K; ++i)
{
c += A[row * K + i] * B[i * N + col];
}
C[row * N + col] = c;
}
}
第一步先写一个简单的矩阵乘法,不要觉得简单就不写,后面不管怎么耍花招,都是基于当下的核心逻辑和计算流程的。
share memory优化
代码我们可以看到,每一个线程要k次乘法和K次加法,每做计算一次 FMA(乘累加)之前需要读一次 A 和读一次 B,读取 Global Memory 的代价很大,通常都需要几百个 cycle(时钟周期),而计算一次 FMA 通常只需要几个 cycle,大量的时间被花费在了访存上, 那么如何减少访问global memory呢?我们知道share_memory是片上内存,访问速度比较快,我们考虑把A和B中的虚线内的数据放在share_memory上,然后计算的时候从share_memeory上取,这样的话其实会多一次数据从global转移到share上的操作,但是每次做乘加计算取数的时候,省的时间会远远多于这一次操作。

上面我们假设是把A、B中的虚线部分数据导入到share中,但其实share的大小有限,所以还是继续分片,原理如下:

具体的伪代码是:
//分为j块
for(int i = 0; i < j; i+1)
{
load_gmem_to_smem(A, i, smemA);
load_gmem_to_smem(B, i, smemB);
__syncthreads();
//compute
C_i=gemm(a_i,b_i);
//累加
C += C_i;
}
可以运行的代码:
template <int BLOCK_SIZE>
__global__
void MatrixMulCUDA(
const float * __restrict__ A,
const float * __restrict__ B,
float * __restrict__ C,
const int M,
const int K,
const int N) {
// Block index
int bx = blockIdx.x;
int by = blockIdx.y;
// Thread index
int tx = threadIdx.x;
int ty = threadIdx.y;
//对应上图a2的左上角位置
int aBegin = K * BLOCK_SIZE * by;
//对应上图aj的右上角位置(注意上图有溢出到A矩阵外,这里代码默认是刚刚在A矩阵里的)
int aEnd = aBegin + K - 1;
//每一个a矩阵的左上角位置距离差
int aStep = BLOCK_SIZE;
// 对应上图b2的左上角位置
int bBegin = BLOCK_SIZE * bx;
// 每一个b矩阵的左上角位置距离差
int bStep = BLOCK_SIZE * N;
float Csub = 0;
// 存储aj的share memory
__shared__ float As[BLOCK_SIZE][BLOCK_SIZE];
// 存储bj的share memory
__shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE];
//对应上图就是循环3次
for (int a = aBegin, b = bBegin; a < aEnd; a += aStep, b += bStep) {
//每个线程下载一个元素到share memory
As[ty][tx] = A[a + K * ty + tx];
Bs[ty][tx] = B[b + N * ty + tx];
// Synchronize 为了确保share memory需要的数据都下载到位
__syncthreads();
// 每个线程计算cj中的一个位置的结果
#pragma unroll
for (int k = 0; k < BLOCK_SIZE; ++k) {
Csub = fma(As[ty][k], Bs[k][tx], Csub);
}
// 确保cj中的所有位置的结果都算好了
__syncthreads();
}
//最后把每个线程负责的算的结果从寄存器导入到device memory
C[N * ( BLOCK_SIZE * by + ty ) + BLOCK_SIZE * bx + tx ] = Csub;
}
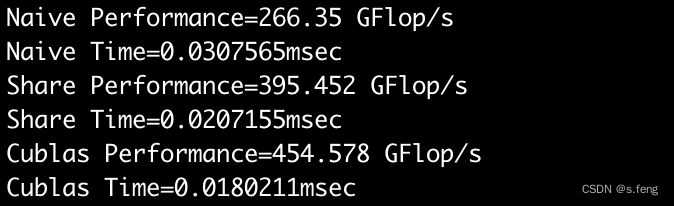
实验结果如下,当M=160,K=160, N=160的时候,实现效果显示还不错,比naive好但是比cublas还是有差距。
第二次优化
第一次优化后,访存代价从几百 cycle 降低到几十 cycle,并不改变问题的本质。问题的关键在于主体循环由两条 Load 指令与一条 FMA 指令构成,计算指令只占总体的 1/3,计算访存比过低,最终导致了访存延迟不能被隐藏,从而性能不理想.
这里解释一下,线程的指令会发给调度器,调度器分配对应的执行单元。这里比如有20个线程,机器上一个调度器,一个计算单元和访存单元,此刻线程1告诉调度器要执行加法计算,计算单元需要10s可以得到结果, 等待期间调度器就会问问其他线程有需要访存的吗?毕竟有一个访存单元在闲着,这时候线程8说他需要访存操作,不过一次访存需要200s, 因为计算单元速度很快,所以当20个线程的计算任务都完成时,只有一个线程的访存任务完成,所以后面还要200s*19这么长的时间。这里可以发现一共需要200S*20的时间,我们计算时间10s*20被完成隐藏了用户感知不到,这就是所谓的隐藏延迟,知道了原理,我们的任务说白了就是别让计算单元闲着,如果一个线程的计算时间如果和访存时间一模一样,那么完全就可以隐藏计算或者是访存的时间了,这不是美滋滋?但是但是,这里的前提是只有一个访存单元和计算单元,实际上底层硬件还是差距很大的,不同架构和型号的显卡也不一样,这也是为啥同样的的代码在不同机器上的性能不一样,此外调度器的规则,计算与访存任务的依赖等等都有可能导致性能差异。
float c[4][4] = {{0}};
float a_reg[4];
float b_reg[4];
for(int i = 0; i < K; i += tile_with)
{
load_gmem_tile_to_smem(A, i, smemA);
load_gmem_tile_to_smem(B, i, smemB);
__syncthreads();
//compute
for(int j = 0; j < tile_with; ++j)
{
// load tile from shared mem to register
load_smem_tile_to_reg(smemA, j, a_reg);
load_smem_tile_to_reg(smemB, j, b_reg);
// compute matrix multiply accumulate 4x4
mma4x4(a_reg, b_reg, c);
}
// 累加
C += C_i;
}
未完待续。。。
参考:https://zhuanlan.zhihu.com/p/410278370