1=0
2=1
3=2
分片规则属性含义:
3). 测试
配置完毕后,重新启动MyCat,然后在mycat的命令行中,执行如下SQL创建表、并插入数据,查看数据分布情况。
CREATE TABLE tb_user (
id bigint(20) NOT NULL COMMENT 'ID',
username varchar(200) DEFAULT NULL COMMENT '姓名',
status int(2) DEFAULT '1' COMMENT '1: 未启用, 2: 已启用, 3: 已关闭',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
insert into tb_user (id,username ,status) values(1,'Tom',1);
insert into tb_user (id,username ,status) values(2,'Cat',2);
insert into tb_user (id,username ,status) values(3,'Rose',3);
insert into tb_user (id,username ,status) values(4,'Coco',2);
insert into tb_user (id,username ,status) values(5,'Lily',1);
insert into tb_user (id,username ,status) values(6,'Tom',1);
insert into tb_user (id,username ,status) values(7,'Cat',2);
insert into tb_user (id,username ,status) values(8,'Rose',3);
insert into tb_user (id,username ,status) values(9,'Coco',2);
insert into tb_user (id,username ,status) values(10,'Lily',1);
5.3.5 应用指定算法
1). 介绍
运行阶段由应用自主决定路由到那个分片
,
直接根据字符子串(必须是数字)计算分片号。
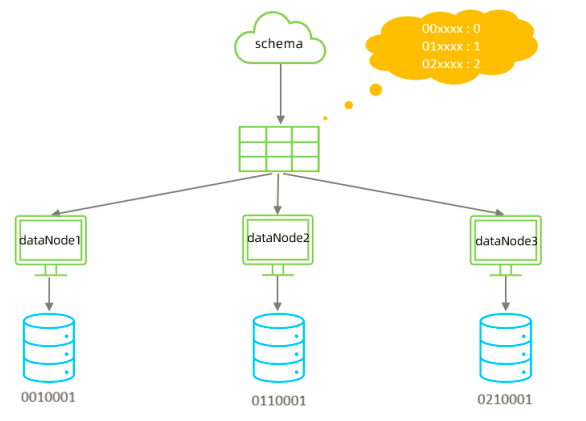
2). 配置
schema.xml
中逻辑表配置:
<!-- 应用指定算法 -->
<table name="tb_app" dataNode="dn4,dn5,dn6" rule="sharding-by-substring" />
schema.xml
中数据节点配置:
<dataNode name="dn4" dataHost="dhost1" database="itcast" />
<dataNode name="dn5" dataHost="dhost2" database="itcast" />
<dataNode name="dn6" dataHost="dhost3" database="itcast" />
rule.xml
中分片规则配置:
<tableRule name="sharding-by-substring">
<rule>
<columns>id</columns>
<algorithm>sharding-by-substring</algorithm>
</rule>
</tableRule>
<function name="sharding-by-substring"
class="io.mycat.route.function.PartitionDirectBySubString">
<property name="startIndex">0</property> <!-- zero-based -->
<property name="size">2</property>
<property name="partitionCount">3</property>
<property name="defaultPartition">0</property>
</function>
分片规则属性含义:
示例说明 :
id=05-100000002 ,
在此配置中代表根据
id
中从
startIndex=0
,开始,截取
siz=2
位数字即
05
,
05
就是获取的分区,如果没找到对应的分片则默认分配到
defaultPartition
。
3). 测试
配置完毕后,重新启动
MyCat
,然后在
mycat
的命令行中,执行如下
SQL
创建表、并插入数据,查看数据分布情况。
CREATE TABLE tb_app (
id varchar(10) NOT NULL COMMENT 'ID',
name varchar(200) DEFAULT NULL COMMENT '名称',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
insert into tb_app (id,name) values('0000001','Testx00001');
insert into tb_app (id,name) values('0100001','Test100001');
insert into tb_app (id,name) values('0100002','Test200001');
insert into tb_app (id,name) values('0200001','Test300001');
insert into tb_app (id,name) values('0200002','TesT400001');
5.3.6 固定分片hash算法
1). 介绍
该算法类似于十进制的求模运算,但是为二进制的操作,例如,取 id 的二进制低 10 位 与
1111111111 进行位 & 运算,位与运算最小值为 0000000000,最大值为1111111111,转换为十
进制,也就是位于0-1023之间。
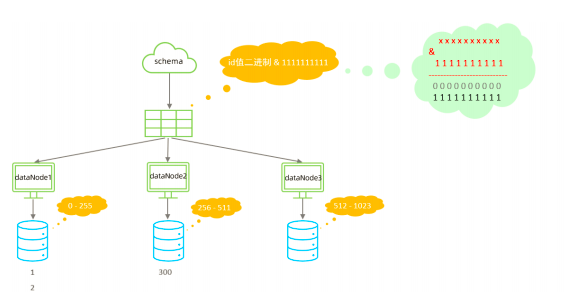
特点:
如果是求模,连续的值,分别分配到各个不同的分片;但是此算法会将连续的值可能分配到相同的
分片,降低事务处理的难度。
可以均匀分配,也可以非均匀分配。
分片字段必须为数字类型。
2). 配置
schema.xml
中逻辑表配置:
<!-- 固定分片hash算法 -->
<table name="tb_longhash" dataNode="dn4,dn5,dn6" rule="sharding-by-long-hash" />
schema.xml
中数据节点配置:
<dataNode name="dn4" dataHost="dhost1" database="itcast" />
<dataNode name="dn5" dataHost="dhost2" database="itcast" />
<dataNode name="dn6" dataHost="dhost3" database="itcast" />
rule.xml
中分片规则配置:
<tableRule name="sharding-by-long-hash">
<rule>
<columns>id</columns>
<algorithm>sharding-by-long-hash</algorithm>
</rule>
</tableRule>
<!-- 分片总长度为1024,count与length数组长度必须一致; -->
<function name="sharding-by-long-hash"
class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">2,1</property>
<property name="partitionLength">256,512</property>
</function>
分片规则属性含义:
约束 :
1).
分片长度
:
默认最大
2^10 ,
为
1024 ;
2). count, length
的数组长度必须是一致的
;
以上分为三个分区
:0-255,256-511,512-1023
示例说明
:
3). 测试
配置完毕后,重新启动
MyCat
,然后在
mycat
的命令行中,执行如下
SQL
创建表、并插入数据,查看数据分布情况。
CREATE TABLE tb_longhash (
id int(11) NOT NULL COMMENT 'ID',
name varchar(200) DEFAULT NULL COMMENT '名称',
firstChar char(1) COMMENT '首字母',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
insert into tb_longhash (id,name,firstChar) values(1,'七匹狼','Q');
insert into tb_longhash (id,name,firstChar) values(2,'八匹狼','B');
insert into tb_longhash (id,name,firstChar) values(3,'九匹狼','J');
insert into tb_longhash (id,name,firstChar) values(4,'十匹狼','S');
insert into tb_longhash (id,name,firstChar) values(5,'六匹狼','L');
insert into tb_longhash (id,name,firstChar) values(6,'五匹狼','W');
insert into tb_longhash (id,name,firstChar) values(7,'四匹狼','S');
insert into tb_longhash (id,name,firstChar) values(8,'三匹狼','S');
insert into tb_longhash (id,name,firstChar) values(9,'两匹狼','L');
5.3.7 字符串hash解析算法
1). 介绍
截取字符串中的指定位置的子字符串
,
进行
hash
算法, 算出分片。
2). 配置
schema.xml
中逻辑表配置:
<!-- 字符串hash解析算法 -->
<table name="tb_strhash" dataNode="dn4,dn5" rule="sharding-by-stringhash" />
schema.xml
中数据节点配置:
<dataNode name="dn4" dataHost="dhost1" database="itcast" />
<dataNode name="dn5" dataHost="dhost2" database="itcast" />
rule.xml
中分片规则配置:
<tableRule name="sharding-by-stringhash">
<rule>
<columns>name</columns>
<algorithm>sharding-by-stringhash</algorithm>
</rule>
</tableRule>
<function name="sharding-by-stringhash"
class="io.mycat.route.function.PartitionByString">
<property name="partitionLength">512</property> <!-- zero-based -->
<property name="partitionCount">2</property>
<property name="hashSlice">0:2</property>
</function>
分片规则属性含义:
示例说明:
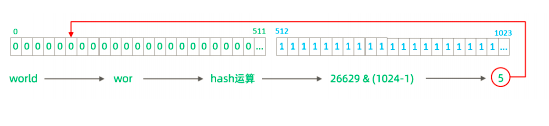
3). 测试
配置完毕后,重新启动
MyCat
,然后在
mycat
的命令行中,执行如下
SQL
创建表、并插入数据,查看数据分布情况。
create table tb_strhash(
name varchar(20) primary key,
content varchar(100)
)engine=InnoDB DEFAULT CHARSET=utf8mb4;
INSERT INTO tb_strhash (name,content) VALUES('T1001', UUID());
INSERT INTO tb_strhash (name,content) VALUES('ROSE', UUID());
INSERT INTO tb_strhash (name,content) VALUES('JERRY', UUID());
INSERT INTO tb_strhash (name,content) VALUES('CRISTINA', UUID());
INSERT INTO tb_strhash (name,content) VALUES('TOMCAT', UUID());
♥️关注,就是我创作的动力
♥️点赞,就是对我最大的认可
♥️这里是小刘,励志用心做好每一篇文章,谢谢大家