sklearn-多元线性回归
和简单线性回归使用单一解释变量和单一系数不同,多元线性回归使用任意数量的解释变量,每个解释变量对应一个系数。用于线性回归的模型也可以被表示为向量计法
多元线性回归
Y = Xβ
Y是一个由训练实例响应变量组成的列向量。β 是一个由模型参数值组成的列向量。X有时也被称为设计矩
阵,是一个由训练实例解释变量组成的mn的矩阵。m是训练实例的数量,n是特征的数量
我们可以使用NumPy库解出β 值
β = [(XT ∙ X)](-1) ∙(XT∙y)
dot:点乘
inv:逆
transpose:转置
from numpy.linalg import inv
from numpy import dot, transpose
X = [[1, 6, 2], [1, 8, 1], [1, 10, 0], [1, 14, 2], [1, 18, 0]]
y = [[7], [9], [13], [17.5], [18]]
print(dot(inv(dot(transpose(X), X)), dot(transpose(X), y)))
NumPy库也提供了一个最小二乘函数,它能被用来更简洁地解出参数值
lstsq()是scipy.linalg库的线性方程组最小二乘法求解的功能
lstsq()具有以下基本用法:
import scipy.linalg
x, residuals, rank, s =lstsq(a, b,rcond=None)
将a和b视为numpy ndarrays。
这里:
a - nxm的float64 numpy矩阵,即系数基底矩阵。
b - length为m的float64 numpy一维阵列或n维蚁形幅广阵列,即要拟合的观测值。
x - length为n的Numpy一维阵列,包含最小二乘解x的元素。
residuals - 误差的平方和。 使得||Ax - b||^2 = residuals。
rank和s - 分别为a的秩和奇异值。
rcond参数是非常重要的,因为它控制小于阈值的奇异值被视为零的机制。通过设置rcond,我们可以控制解的稳定性和精度
from numpy.linalg import lstsq
X = [[1, 6, 2], [1, 8, 1], [1, 10, 0], [1, 14, 2], [1, 18, 0]]
y = [[7], [9], [13], [17.5], [18]]
print(lstsq(X, y, rcond=None)[0])
简单测试
from sklearn.linear_model import LinearRegression
X = [[6, 2], [8, 1], [10, 0], [14, 2], [18, 0]]
y = [[7], [9], [13], [17.5], [18]]
model = LinearRegression()
model.fit(X, y)
X_test = [[8, 2], [9, 0], [11, 2], [16, 2], [12, 0]]
y_test = [[11], [8.5], [15], [18], [11]]
predictions = model.predict(X_test)
for i, prediction in enumerate(predictions):
print('Predicted: %s, Target: %s' % (prediction, y_test[i]))
print('R-squared: %.2f' % model.score(X_test, y_test))
enumerate()是一个非常实用的内置python函数。它可以将一个可迭代的对象(如列表、元组或字符串)同时映射到其索引和值。这可以用来处理或列举每个元素及其相应的索引。
基本用法如下:
enumerate(iterable)
这里:
iterable - 任何可迭代的对象,如列表、元组、字符串等。
例如:
fruits = [‘apple’, ‘banana’, ‘cherry’]
for index, fruit in enumerate(fruits):
print(index, fruit)
0 apple
1 banana
2 cherry
二阶多项式回归
y= α+ β_1 x+ β_2 x^2
np.linspace()方法用于生成均匀间隔的数字序列。
PolynomialFeatures() 是NumPy中的一个工具,用于特征工程和多项式回归。 它可以用来生成多项式项特征,以用于模型训练。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
X_train = [[6], [8], [10], [14], [18]]
y_train = [[7], [9], [13], [17.5], [18]]
X_test = [[6], [8], [11], [16]]
y_test = [[8], [12], [15], [18]]
regressor = LinearRegression()
regressor.fit(X_train, y_train)
xx = np.linspace(0, 26, 100)
yy = regressor.predict(xx.reshape(xx.shape[0], 1))
plt.plot(xx, yy)
quadratic_featurizer = PolynomialFeatures(degree=2)
X_train_quadratic = quadratic_featurizer.fit_transform(X_train)
X_test_quadratic = quadratic_featurizer.transform(X_test)
#print(quadratic_featurizer.get_feature_names())
#print(quadratic_featurizer.n_input_features_)
#print(quadratic_featurizer.n_output_features_)
regressor_quadratic = LinearRegression()
regressor_quadratic.fit(X_train_quadratic, y_train)
xx_quadratic = quadratic_featurizer.transform(xx.reshape(xx.shape[0], 1))
plt.plot(xx, regressor_quadratic.predict(xx_quadratic), c='r', linestyle='--')
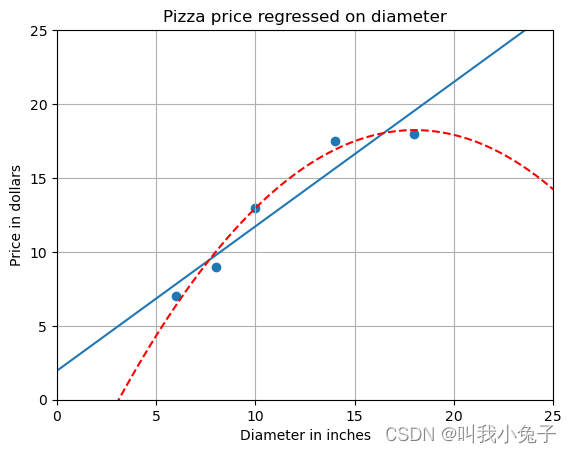
plt.title('Pizza price regressed on diameter')
plt.xlabel('Diameter in inches')
plt.ylabel('Price in dollars')
plt.axis([0, 25, 0, 25])
plt.grid(True)
plt.scatter(X_train, y_train)
plt.show()
print(X_train)
print(X_train_quadratic)
print(X_test)
print(X_test_quadratic)
print('Simple linear regression r-squared', regressor.score(X_test,
y_test))
print('Quadratic regression r-squared',regressor_quadratic.score(X_test_quadratic, y_test))
[[6], [8], [10], [14], [18]]
[[ 1. 6. 36.]
[ 1. 8. 64.]
[ 1. 10. 100.]
[ 1. 14. 196.]
[ 1. 18. 324.]]
[[6], [8], [11], [16]]
[[ 1. 6. 36.]
[ 1. 8. 64.]
[ 1. 11. 121.]
[ 1. 16. 256.]]
Simple linear regression r-squared 0.809726797707665
Quadratic regression r-squared 0.8675443656345054
应用线性回归
探索数据winequality-red.csv链接: winequality-red.csv
相对酸度、挥发性酸度、柠檬酸、剩余糖量、氯化物、自由硫化氢、总硫化氢、密度、pH、二氧化硫、酒精度、质量
import pandas as pd
df = pd.read_csv('./winequality-red.csv', sep=';')
df.describe()
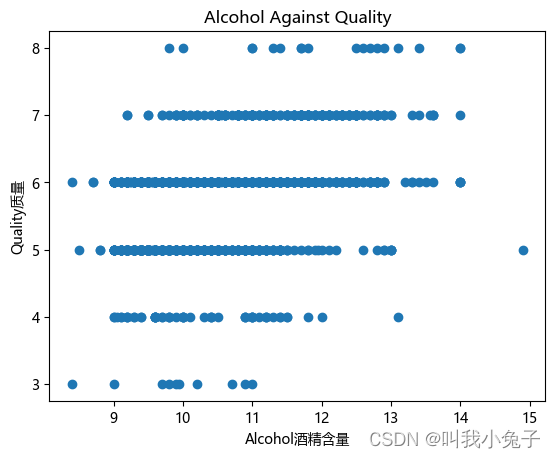
酒精含量和质量之间存在弱正相关关系
import matplotlib.pylab as plt
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.scatter(df['alcohol'], df['quality'])
plt.xlabel('Alcohol酒精含量')
plt.ylabel('Quality质量')
plt.title('Alcohol Against Quality')
plt.show()
拟合和评估模型
train_test_split是scikit-learn库中用于划分训练和测试集的非常常用的工具。 它具有以下主要参数:
X - 特征数据集,以NumPy矩阵或Pandas DataFrame形式提供。 y - 目标变量,以Numpy数组或Pandas Series形式提供。
from sklearn.linear_model import LinearRegression
import pandas as pd
import matplotlib.pylab as plt
from sklearn.model_selection import train_test_split
df = pd.read_csv('./winequality-red.csv', sep=';')
X = df[list(df.columns)[:-1]]
y = df['quality']
X_train, X_test, y_train, y_test = train_test_split(X, y)
regressor = LinearRegression()
regressor.fit(X_train, y_train)
y_predictions = regressor.predict(X_test)
print('R-squared: %s' % regressor.score(X_test, y_test))
评估交叉验证
cross_val_score用于评估交叉验证得分来评估机器学习模型的准确性。
它具有以下主要参数:
estimator - 需要评估的机器学习模型。
X - 特征数据集,以NumPy矩阵或Pandas DataFrame形式提供。
y - 目标变量,以Numpy数组或Pandas Series形式提供。
cv - 交叉验证技术,通常是KFold()、StratifiedKFold()或GroupKFold()。 它用于定义如何将数据划分为训练和验证集。
n_jobs - 用于并行计算的CPU核心数。 默认为1,不进行并行计算。
scoring - 用于评估模型性能的评分方法,例如"accuracy"、"f1_score"等。 默认为None,这将导致模型的默认评估方法。
import pandas as pd
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LinearRegression
df = pd.read_csv('./winequality-red.csv', sep=';')
X = df[list(df.columns)[:-1]]
y = df['quality']
regressor = LinearRegression()
scores = cross_val_score(regressor, X, y, cv=5)
print(scores.mean())
print(scores)
梯度下降法
load_boston() 从scikit-learn中加载波士顿房价数据集。 它包含506行和13列的数据。
SGDRegressor是scikit-learn中实现的随机梯度下降(SGD)回归器。它用于拟合线性回归模型。
SGDRegressor是scikit-learn库中的一种基于增量学习算法的线性回归器。它适用于大规模数据并具有较低的内存开销。
import numpy as np
from sklearn.datasets import load_boston
from sklearn.linear_model import SGDRegressor
from sklearn.model_selection import cross_val_score
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
data = load_boston()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target)
X_scaler = StandardScaler()
y_scaler = StandardScaler()
X_train = X_scaler.fit_transform(X_train)
y_train = y_scaler.fit_transform(y_train.reshape(-1,1)).reshape(-1)
X_test = X_scaler.transform(X_test)
y_test = y_scaler.transform(y_test.reshape(-1,1)).reshape(-1)
regressor = SGDRegressor(loss='squared_loss')
scores = cross_val_score(regressor, X_train, y_train, cv=5)
print('Cross validation r-squared scores: %s' % scores)
print('Average cross validation r-squared score: %s' % np.mean(scores))
regressor.fit(X_train, y_train)
print('Test set r-squared score %s' % regressor.score(X_test, y_test))