图像聚类
图像聚类
什么是聚类:
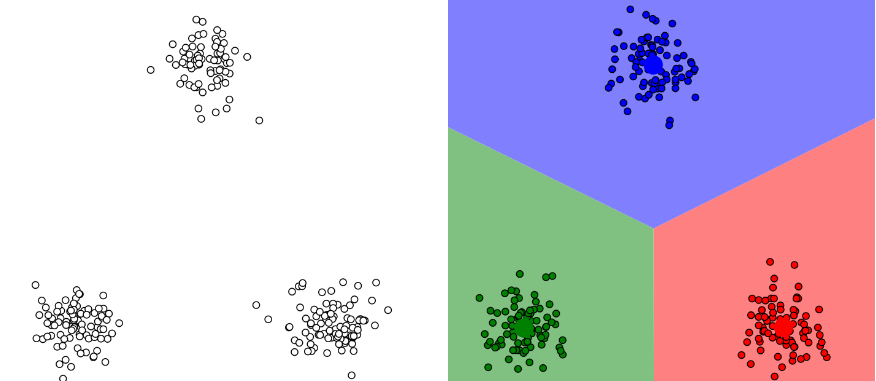
举个简单的例子,给出了左图中的点的数据,对其划分为三类,这个过程就叫做聚类。
聚类实际上就是根据数据的特征进行分类,把相似的东西分在一起。
难点:聚类是无监督的,如何在无监督的情况下尽可能分出更好的类别来是一个比较难以解决的问题。
K-means聚类
什么是k-means聚类
试想一下,如果给一张图如下,要求对这张图中的点分类,你会怎么进行呢?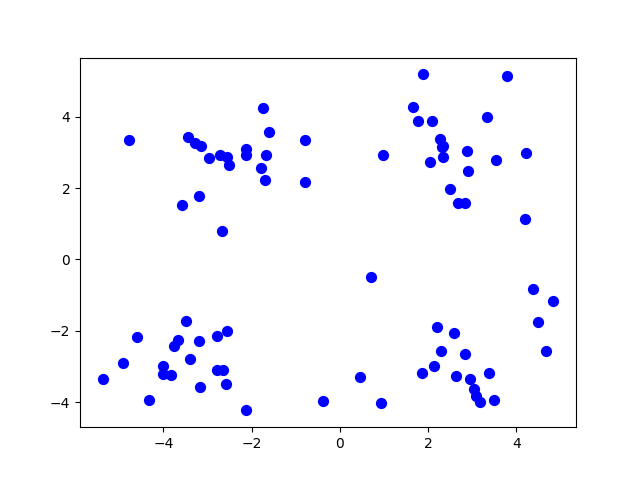
我们当然可以认为所有的点都只有一个种类,毕竟他们本身只有坐标不同,也可以左右分成两个大类,也可以四个角落划分成四类,这一切都取决于最初定的分类个数,而这就是k均值聚类。
所谓k,就是我们的目标要把数据划分为k个类。
所谓聚类,就是向上面的例子一样,实现不给任何标签,让我们自己区随意分类
我们要分类的话,肯定是在同一类中相似度越高越好。也就是说,在特征空间中,他们的距离(欧氏距离或者随便什么距离)整体而言是最近的。k均值聚类正是采取了这种思想,其执行步骤如下:
- 由于要划分k个类,因此首先随机选取k个点(算法结束后这k个点会成为各自类的质点)
- 遍历所有的点,把这些点分类给距离其最近的质点(就是1中的点)
- 更新质点的位置,使其成为所在类的质点(也就是同类所有点的坐标取平均值)
- 重复2和3直至点的分类不变
这里的均值便是k均值聚类中的来源了。现在步骤清楚了,下面可以开始用代码去实现了,同样的,所有需要注意的点已均在代码中注释:
from numpy import *
# 加载数据集
def loadDataSet(fileName):
dataMat = []
fr = open(fileName)
for line in fr.readlines():
curLine = line.strip().split('\t')
# 这里要注意一下,map函数返回的是一个迭代器,需要用list函数转换成列表,原本的书上没有这个list函数,但是在python3中需要加上这个函数
fltLine = list(map(float, curLine))
dataMat.append(fltLine)
return dataMat
# 计算欧式距离
def distEclud(vecA, vecB):
return sqrt(sum(power(vecA - vecB, 2)))
# 为给定数据集构建一个包含k个随机质心的集合
def randCent(dataSet, k):
n = shape(dataSet)[1]
centroids = mat(zeros((k, n)))
for j in range(n):
# 计算最小值,最大值,保证随机点在数据集的边界之内
minJ = min(dataSet[:, j])
rangeJ = float(max(dataSet[:, j]) - minJ)
centroids[:, j] = minJ + rangeJ * random.rand(k, 1)
# 返回质心
return centroids
# k均值聚类算法本体
def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent):
# 数据集的行数
m = shape(dataSet)[0]
# 每个点的簇分配结果矩阵,第一列记录簇索引值,第二列存储误差
clusterAssment = mat(zeros((m, 2)))
# 创建质心
centroids = createCent(dataSet, k)
clusterChanged = True
# 只要簇分配结果改变就一直迭代
while clusterChanged:
clusterChanged = False
# 计算每个点到质心的距离
for i in range(m):
minDist = inf
minIndex = -1
for j in range(k):
distJI = distMeas(centroids[j, :], dataSet[i, :])
# 寻找最近的质心
if distJI < minDist:
minDist = distJI
minIndex = j
# 若任一点的簇分配结果发生改变,则更新clusterChanged标志
if clusterAssment[i, 0] != minIndex:
clusterChanged = True
# 更新簇分配结果
clusterAssment[i, :] = minIndex, minDist ** 2
# 更新质心的位置
for cent in range(k):
ptsInClust = dataSet[nonzero(clusterAssment[:, 0].A == cent)[0]]
centroids[cent, :] = mean(ptsInClust, axis=0)
return centroids, clusterAssment
def main():
# test kMeans
dataMat = mat(loadDataSet('testSet.txt'))
myCentroids, clustAssing = kMeans(dataMat, 4)
# 画图,画出聚类结果
fig = plt.figure()
# 将dataMat中的点画出来
ax = fig.add_subplot(111)
ax.scatter(dataMat[:, 0].flatten().A[0], dataMat[:, 1].flatten().A[0], s=50, c='blue')
# 将聚类中心画出来
ax.scatter(myCentroids[:, 0].flatten().A[0], myCentroids[:, 1].flatten().A[0], s=300, c='red', marker='+')
plt.show()
if __name__ == '__main__':
main()
最终得到的结果如下图: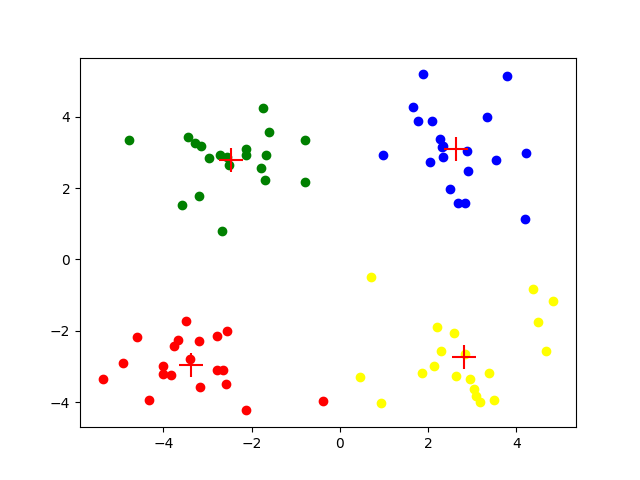
这只是最基本的k均值聚类,虽然它有很多缺点,也有很多人为其做过优化,不过我们了解到这里就已经足够了。我们后续即使使用这个算法也多半是调用封装好的包。下面我们来看一下K-均值聚类时怎么实际运用到图像处理上的。
图像处理
# -*- coding: utf-8 -*-
from scipy.cluster.vq import *
import scipy
from skimage.transform import resize
from pylab import *
from PIL import Image, ImageFont
def clusterpixels(infile, k, steps):
im = array(Image.open(infile))
dx = im.shape[0] / steps
dy = im.shape[1] / steps
# compute color features for each region
features = []
for x in range(steps):
for y in range(steps):
R = mean(im[int(x * dx):int((x + 1) * dx), int(y * dy):int((y + 1) * dy), 0])
G = mean(im[int(x * dx):int((x + 1) * dx), int(y * dy):int((y + 1) * dy), 1])
B = mean(im[int(x * dx):int((x + 1) * dx), int(y * dy):int((y + 1) * dy), 2])
features.append([R, G, B])
features = array(features, 'f') # make into array
# 聚类, k是聚类数目
centroids, variance = kmeans(features, k)
code, distance = vq(features, centroids)
# create image with cluster labels
codeim = code.reshape(steps, steps)
return codeim
k = 3
img = 'images/empire.jpg'
img_src = array(Image.open(img))
steps = (50, 100) # image is divided in steps*steps region
print(steps[0], steps[-1])
# 显示原图empire.jpg
figure()
subplot(131)
title(u'src')
axis('off')
imshow(img_src)
# 用50*50的块对empire.jpg的像素进行聚类
codeim = clusterpixels(img, k, steps[0])
subplot(132)
title(u'k=3,steps=50')
# ax1.set_title('Image')
axis('off')
imshow(codeim)
# 用100*100的块对empire.jpg的像素进行聚类
codeim = clusterpixels(img, k, steps[-1])
ax1 = subplot(133)
title(u'k=3,steps=100')
# ax1.set_title('Image')
axis('off')
imshow(codeim)
show()
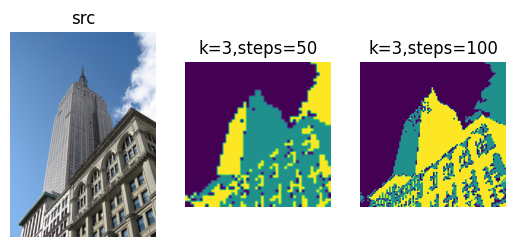
可以看到聚类的结果还是很不错的,能够将不同通道的像素聚类得到很好的结果。
层次聚类
什么是层次聚类
层次聚类是一种用于将数据点分组成层次结构的方法。简单来说,它是一种把数据点逐步合并成不断更大的群组的过程,直到所有数据点都被合并到一个大的群组中为止。这个过程形成了一个树状结构,称为"聚类树"或"树状图"。
在层次聚类中,起始阶段每个数据点都被视为一个单独的群组,然后根据它们之间的相似度逐步合并。合并的标准可以是不同的相似度度量,比如欧氏距离、曼哈顿距离等,具体取决于应用领域和问题。
在聚类过程中,合并的顺序可以通过不同的方法来确定,主要有两种主要类型的层次聚类:
- 凝聚型(自底向上): 这种方法从单个数据点开始,逐步合并相似度最高的群组,直到所有数据点都被合并到一个大的群组中。
- 分裂型(自顶向下): 这种方法从所有数据点作为一个整体开始,然后逐步将群组分割成更小的子群组,直到每个数据点都成为一个单独的群组。
层次聚类的结果可以用树状图表示,其中树的每个分支代表一个合并或分裂的步骤,叶节点代表最终的群组。通过在树状图中选择一个合适的截断点,可以将数据点分成不同数量的群组。
总而言之,层次聚类是一种将数据点组织成层次结构的方法,逐步合并或分割群组,以便于理解和分析数据的相似性和关系。
图像处理
首先我们来直接看一下代码:
from numpy import *
from PIL import Image
# 创建图像列表
path = 'flickr-sunsets-small/'
imlist = [os.path.join(path, f) for f in os.listdir(path) if f.endswith('.jpg')]
# 提取特征向量,每个颜色通道量化成 8 个小区间
features = zeros([len(imlist), 512])
for i, f in enumerate(imlist):
im = array(Image.open(f))
# 多维直方图
h, edges = histogramdd(im.reshape(-1, 3), 8, range=[(0, 255), (0, 255), (0, 255)])
features[i] = h.flatten()
tree = hcluster.hcluster(features)
# 设置一些(任意的)阈值以可视化聚类簇
clusters = tree.extract_clusters(0.23 * tree.distance)
# 绘制聚类簇中元素超过 3 个的那些图像
for c in clusters:
elements = c.get_cluster_elements()
nbr_elements = len(elements)
if nbr_elements > 3:
figure()
for p in range(minimum(nbr_elements, 20)):
subplot(4, 5, p + 1)
im = array(Image.open(imlist[elements[p]]))
imshow(im)
axis('off')
show()
hcluster.draw_dendrogram(tree, imlist, filename='sunset.pdf')
这里我们是直接调用了别人封装好的方法,下面来看一下效果:


树状图的高和子部分由距离决定,随着坐标向下传递到下一级,会递归绘制出这些节点,上述代码用 20×20 像素绘制叶节点的缩略图,使用 get_height() 和 get_depth() 这两个辅助函数可以获得树的高和宽。最后展示了日落图像层次聚类后的树状图。可以看到,树中挨的相近的图像具有相似的颜色分布。
谱聚类
什么是谱聚类
谱聚类是一种基于图论的数据聚类方法,它的思想有点像音乐的频谱,但是在这里用于数据而不是声音。让我用更简单的话来解释一下:
想象你有一堆数据点,就像是散落在空间中的小星星。你想要将这些星星分成几个群组,每个群组里的星星彼此更加相似。谱聚类就像是把这些星星之间的关系转换成一张图,其中星星是图的节点,而它们之间的相似度则是图的边。
然后,我们开始思考这个图的结构。在这个图中,有些星星之间的连接很强,它们可能在空间中比较靠近;而有些星星之间的连接可能较弱,它们可能离得比较远或者相似度较低。
谱聚类的核心思想是,找到这个图中连接较强的部分,也就是那些相似度较高的星星,然后将它们组合成一个个聚类。这就好像你在图中找到了一些星星群,每个群都代表一个聚类。
为了实际操作,我们使用一种叫做“拉普拉斯矩阵”的工具来处理图的结构。这个矩阵可以帮助我们找到连接紧密的星星群,然后对它们进行聚类分组。
总结一下,谱聚类是一种通过将数据点之间的相似性转化为图结构,然后利用图的连接来进行数据聚类的方法。就像找到一片片星星群一样,它能够帮助我们发现数据中的隐藏群组。
当执行谱聚类时,可以遵循以下步骤:
创建相似度图: 将数据点之间的相似性转化为图结构。每个数据点都是图中的一个节点,而它们之间的相似度则是图的边。相似度可以使用不同的度量,如欧氏距离、相关系数等。
构建邻接矩阵: 根据相似度图,创建一个称为邻接矩阵的矩阵。邻接矩阵表示了数据点之间的连接情况,其中矩阵的元素表示节点之间的相似度或距离。
计算拉普拉斯矩阵: 从邻接矩阵出发,计算图的拉普拉斯矩阵。拉普拉斯矩阵帮助捕捉图的结构和连接。
计算特征向量: 对拉普拉斯矩阵进行特征值分解,得到其特征值和特征向量。特征向量对应于图的不同分支或星星群。
降维: 选择与较小特征值相对应的特征向量,将它们作为新的低维表示。这可以帮助保留数据的关键信息,减少维度。
K-Means聚类: 使用降维后的数据作为输入,应用K-Means等聚类算法来将数据分为不同的聚类。通常,你可以根据K-Means的聚类中心数量来决定需要的聚类数。
得到最终聚类结果: 根据K-Means的结果,将数据点分配到不同的聚类中,形成最终的谱聚类结果。
谱聚类作为一种聚类方法,具有以下优势和劣势:
优势:
适应复杂结构: 谱聚类在处理非凸、复杂形状的数据分布时表现良好,可以捕捉数据中的各种聚类结构。
灵活性: 由于谱聚类是基于图的,它不受数据的维度限制。这意味着它可以处理高维数据,而不会受到“维度灾难”的影响。
不受聚类大小影响: 谱聚类不会受到聚类大小不均匀的影响,即使是小的聚类也能被有效地发现。
捕捉局部结构: 谱聚类能够捕捉数据的局部结构,这对于处理具有噪声的数据非常有用。
劣势:
计算复杂度: 谱聚类的计算复杂度较高,特别是在大规模数据集上,需要进行特征值分解等运算,可能导致较长的计算时间。
参数选择: 谱聚类需要选择一些参数,如选择特征向量的数量或聚类的数量。这些参数的选择可能会影响最终的聚类结果。
对参数敏感: 谱聚类的性能对于参数的选择非常敏感,不同的参数设置可能会导致不同的聚类结果。
可扩展性: 虽然谱聚类适用于许多数据集,但在处理非常大规模的数据时,其可扩展性可能会受到限制。
图像处理
下面我们先看一下代码:
# -*- coding: utf-8 -*-
from PCV.tools import imtools, pca
from PIL import Image, ImageDraw
from pylab import *
from scipy.cluster.vq import *
imlist = imtools.get_imlist('a_thumbs')
imnbr = len(imlist)
# Load images, run PCA.
immatrix = array([array(Image.open(im)).flatten() for im in imlist], 'f')
V, S, immean = pca.pca(immatrix)
# Project on 2 PCs.
projected = array([dot(V[[0, 1]], immatrix[i] - immean) for i in range(imnbr)]) # P131 Fig6-3左图
# projected = array([dot(V[[1, 2]], immatrix[i] - immean) for i in range(imnbr)]) # P131 Fig6-3右图
n = len(projected)
# 计算距离矩阵
S = array([[sqrt(sum((projected[i] - projected[j]) ** 2))
for i in range(n)] for j in range(n)], 'f')
# 创建拉普拉斯矩阵
rowsum = sum(S, axis=0)
D = diag(1 / sqrt(rowsum))
I = identity(n)
L = I - dot(D, dot(S, D))
# 计算矩阵 L 的特征向量
U, sigma, V = linalg.svd(L)
k = 5
# 从矩阵 L 的前k个特征向量(eigenvector)中创建特征向量(feature vector) # 叠加特征向量作为数组的列
features = array(V[:k]).T
# k-means 聚类
features = whiten(features)
centroids, distortion = kmeans(features, k)
code, distance = vq(features, centroids)
# 绘制聚类簇
for c in range(k):
ind = where(code == c)[0]
figure()
gray()
for i in range(minimum(len(ind), 39)):
im = Image.open(imlist[ind[i]])
subplot(4, 10, i + 1)
imshow(array(im))
axis('equal')
axis('off')
show()
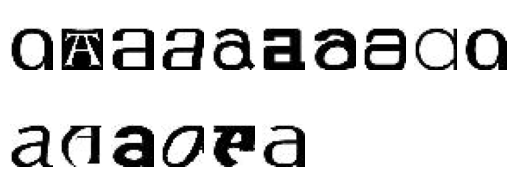
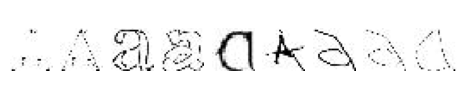
可以看到不同类别的图像还是比较好的聚合在了一起。