之前做的都是监督学习,收集了很多每个图片都有对应的文字
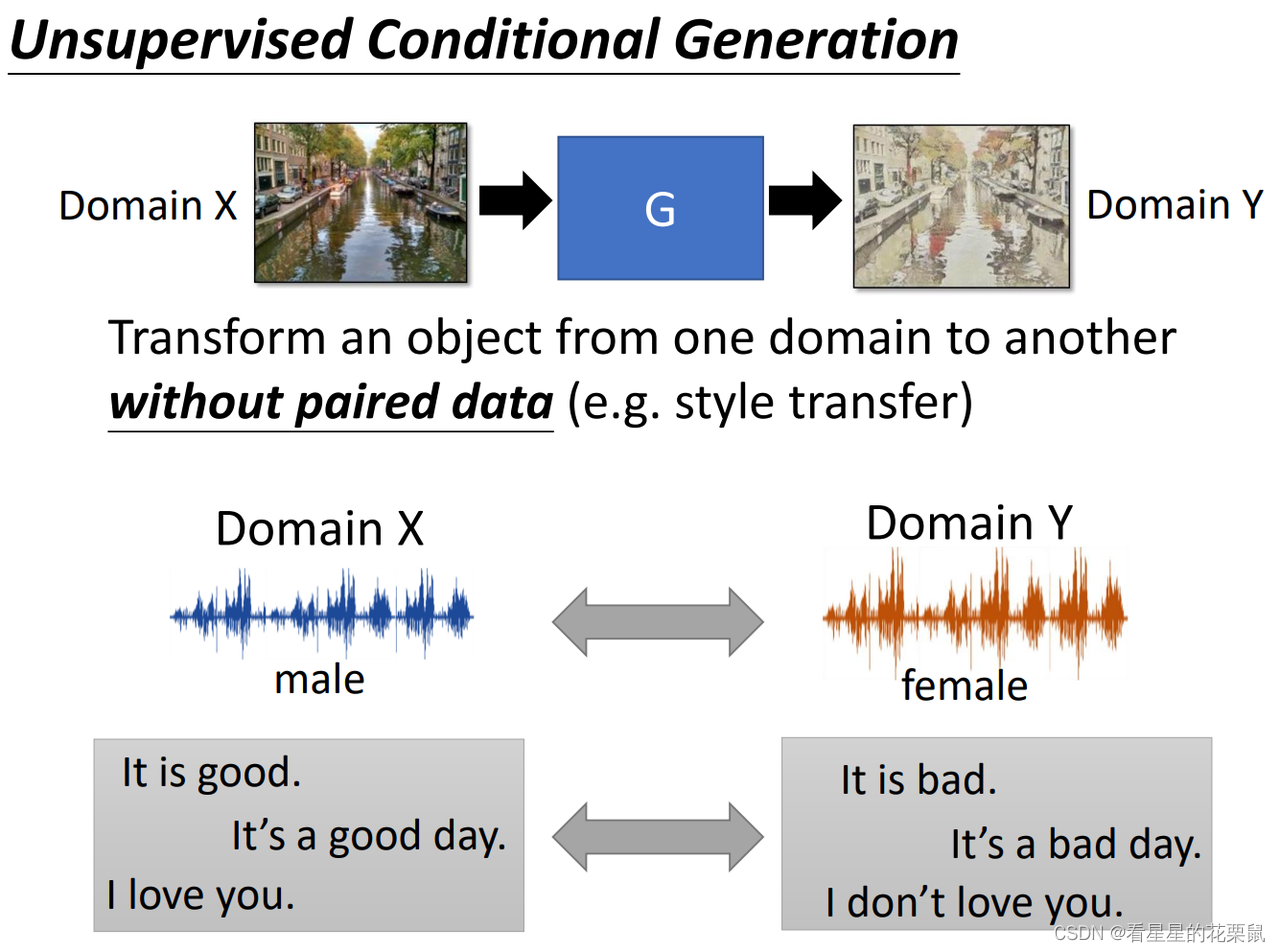
本节是unsupervised的。
以风格迁移(领域迁移)为例:你可能有一些风景照和一些复古照,但他们彼此之间没有联系,你希望把风景照转换成复古照。
两大类做法
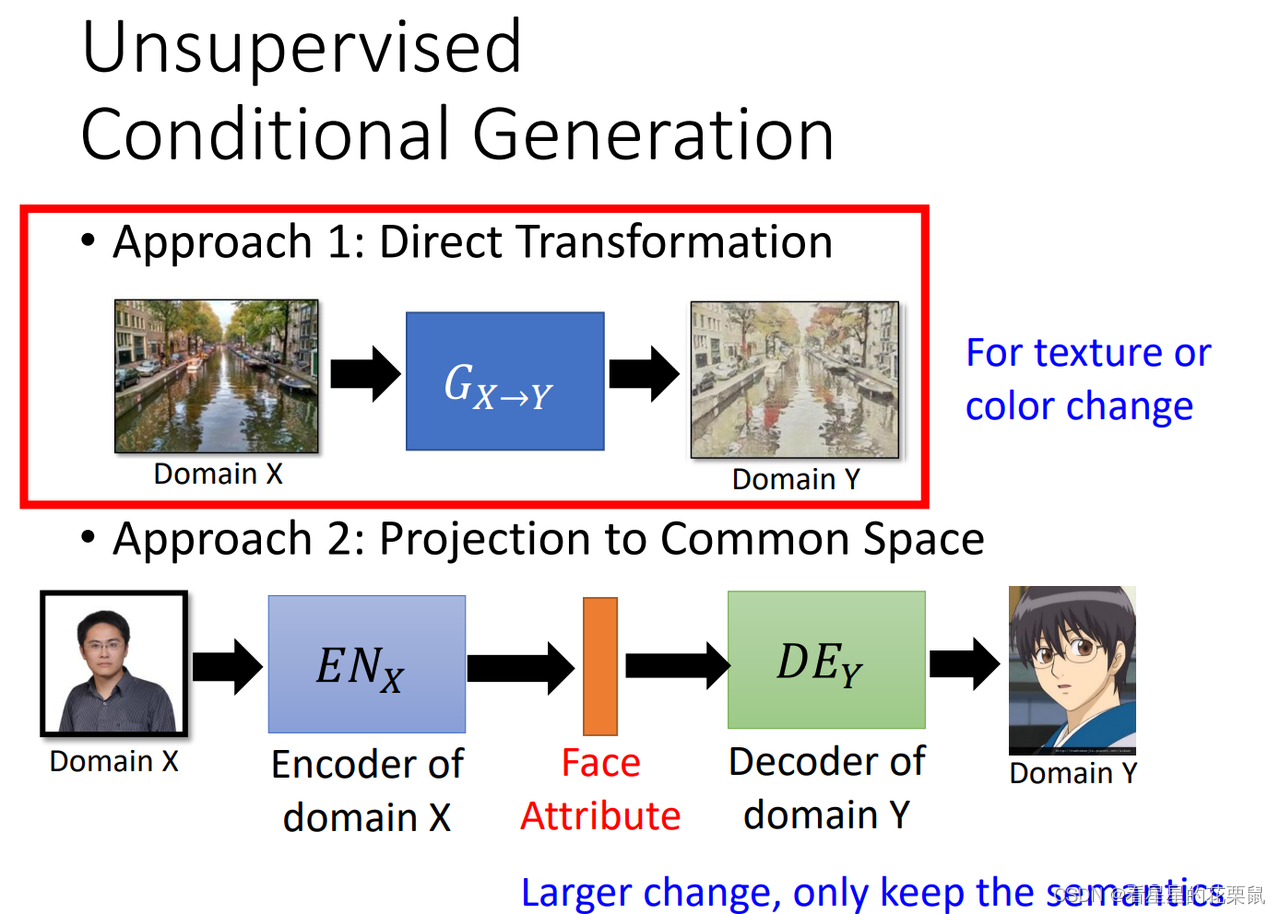
Approach 1: Direct Transformation 直接转
直接学习一个 generator ,输入x domain 的东西,想办法转成 Y domain。
如果要做这种 direct transformation,input output没有办法差太多。generator通常只能小改输入。如果是影像的话,它通常能够改的就是颜色质地。所以如果是画风转换,真实的图片转成画作,比较有可能用第一个方法来实现。假设要转的 input output差距很大,不是只有在颜色纹理上面的转换的话,就要用到第二个方法。
Approach 2: Projection to Common Space 投影到公共空间
先学习一个 encoder ,输入一张人脸的图,把人脸的特征抽出来,比如说这是男的,有戴眼镜的。之后输入Y domain 的decoder,生成动漫图。适用于输入与输出差距很大的情况。
一、Direct Transformation
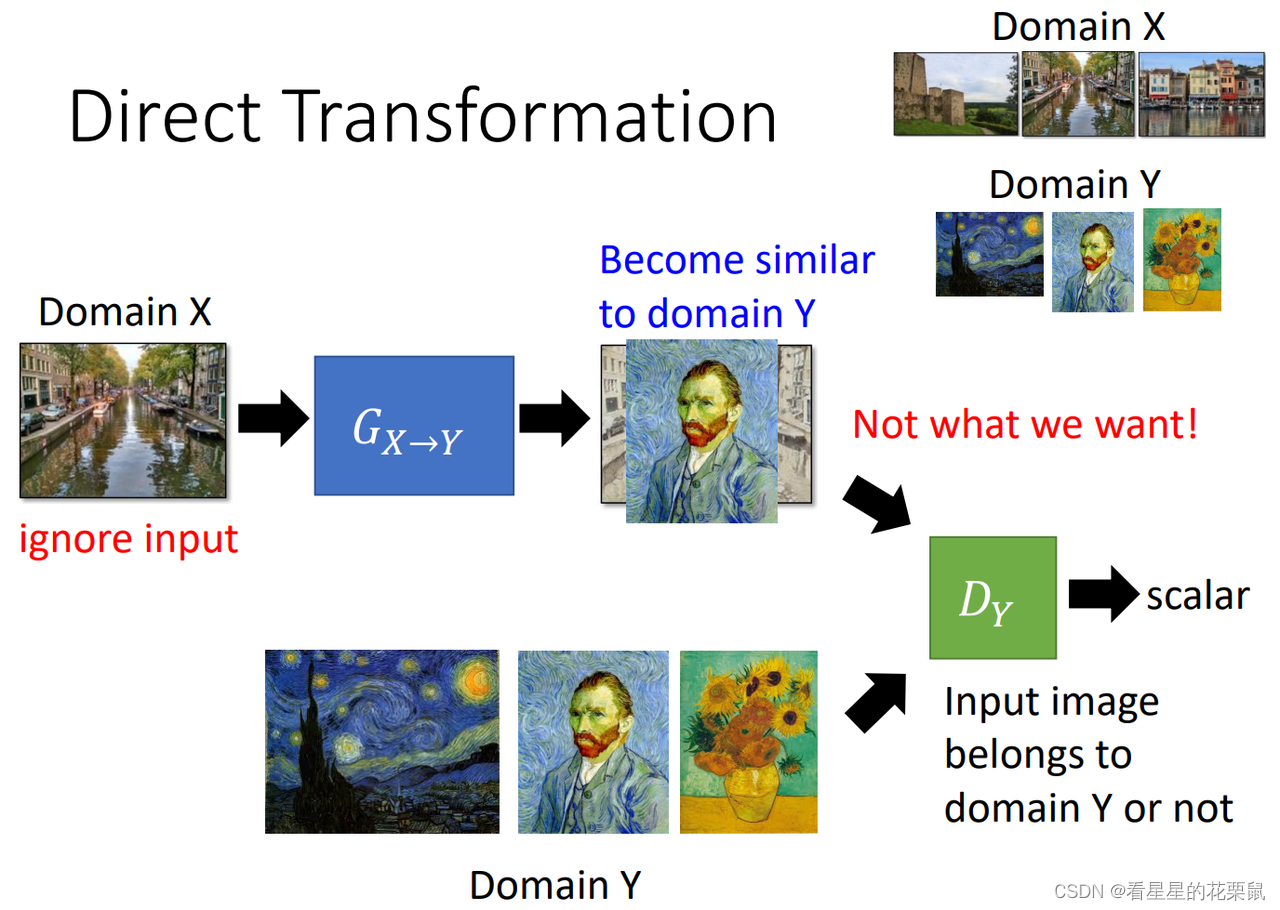
我们要learn一个生成器,他可以将X domain的东西转换为 Y domain的东西;现在我们X domain的东西有一堆,Y domain的东西有一堆,但是合起来的pair没有。那生成器怎么知道给定X domain的东西输出Y domain的东西呢?
- 这个时候就需要一个Y domain的判别器,这个判别器他看过很多Y domian的图片,所以给它一张image,他可以鉴别这个image是不是Y domian的image。
- 生成器要做的就是想办法去骗过判别器,这样就生成Y domain的东西。
- 但是还要注意生成器生成的东西要与输入有关;因此生成器不仅要骗过判别器,还要让输出的东西与输入有关
如何让输入与输出有关?
两种做法:
- 直接无视,不加额外constrain:如果generator不是很深的话,原图变化不会太大
- 拿一个pre-trained好的network, 比如VGG。把生成器的输入和输出image,统统丢给这个pre-train好的网络,就会输出两个embedding vector;接下来在训练的时候,一方面生成器要骗过判别器,同时希望两个embedding的vector不要差太多。

-
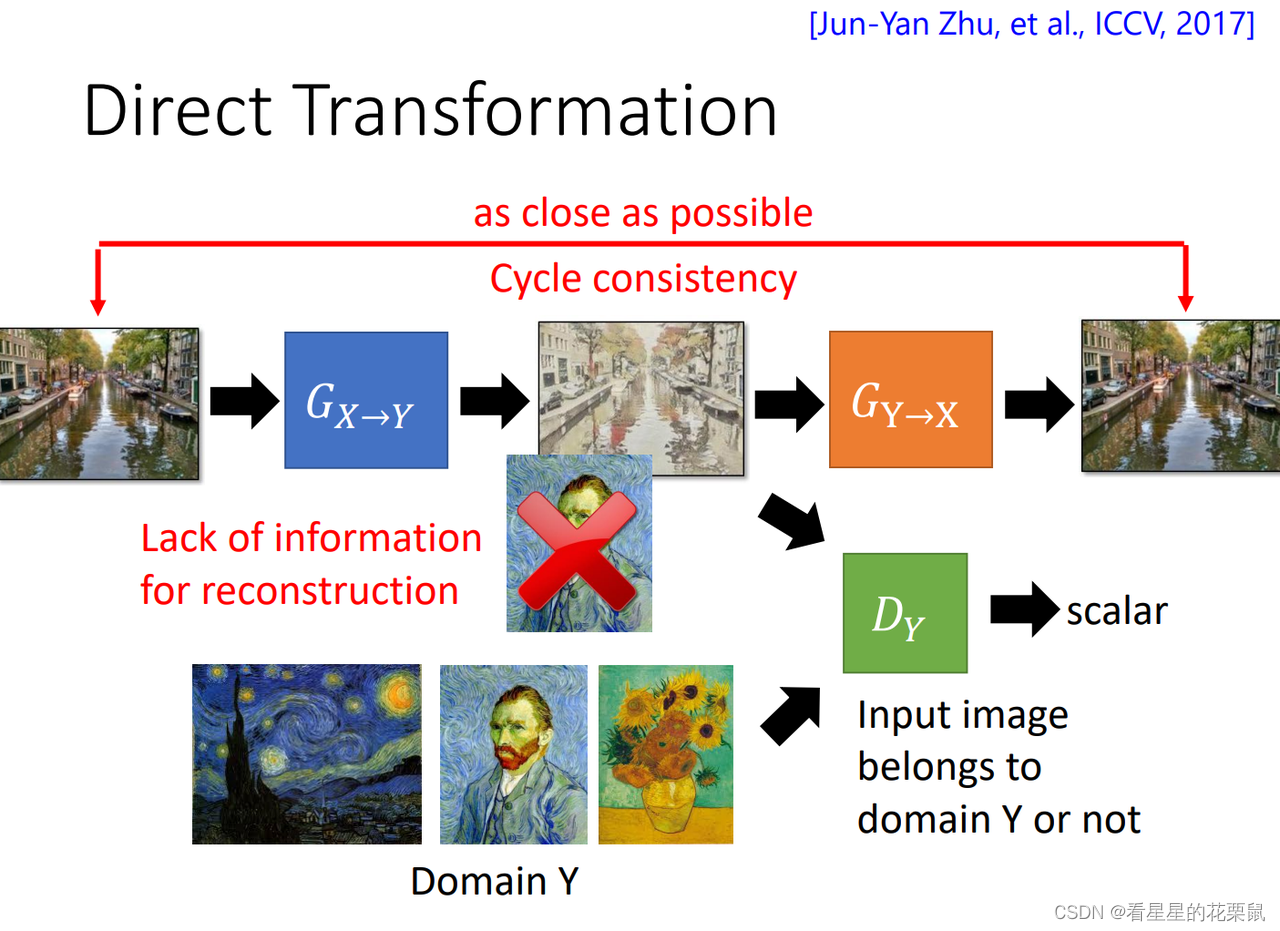
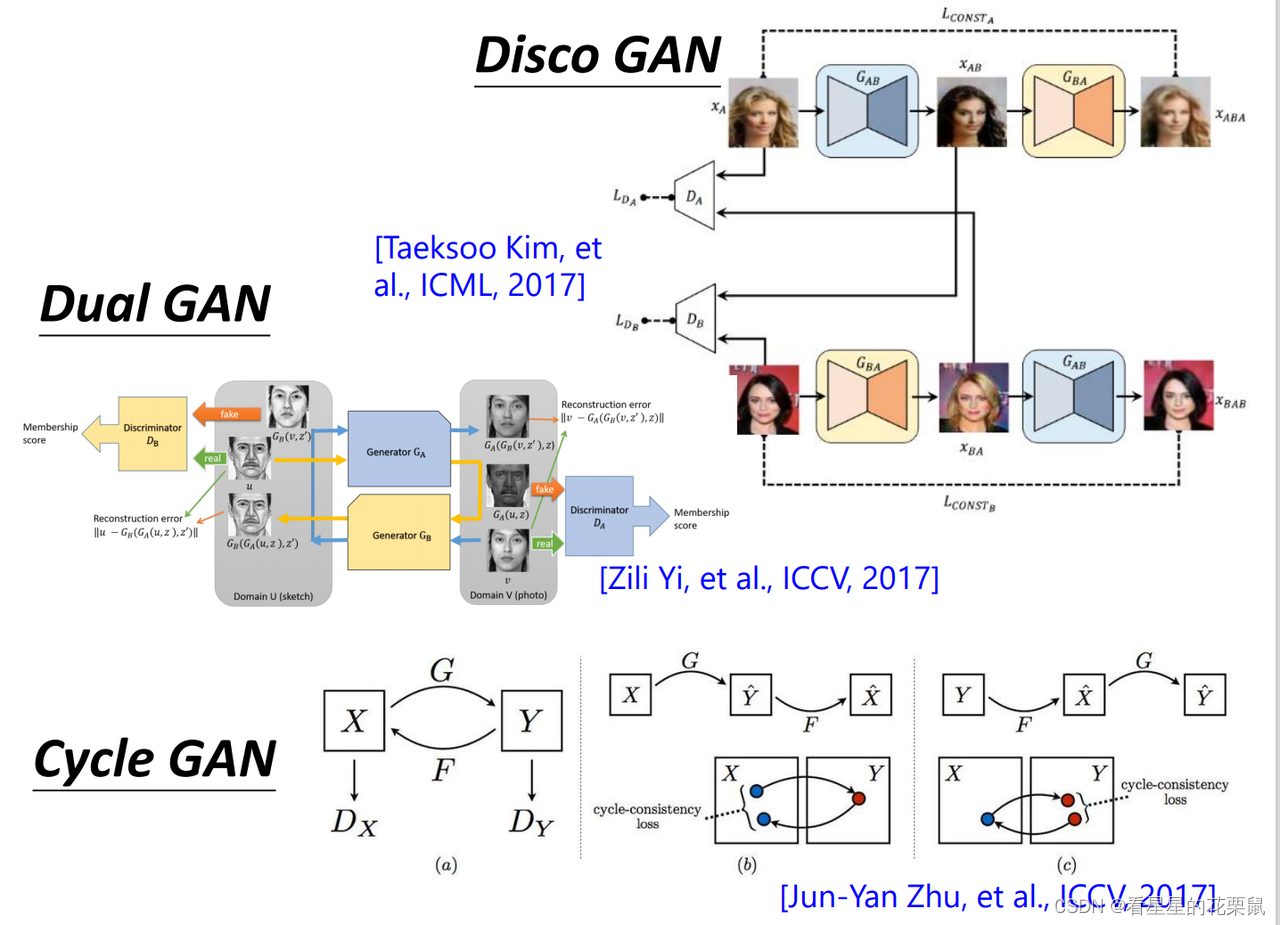
Cycle GAN
- 如果你想train一个X domain到Y domain的生成器,你需要同时train一个Y domain到X domain的生成器;第一个生成器用于将风景画变成复古画,第二个用于将复古画还原为原来一模一样的图;然后目标是两次转换以后的图越接近越好。(这个路径叫做cycle consistency)
- 同时训练Y domain的判别器;
- 重复上面的X domain转换为Y domain;我们再训练一个Y domain到X domain同样的结构;
- 这就是cycle-GAN
除了骗过discriminator以外,generator得到了一个新的任务,要让 input 跟 output 越像越好。不可以在中间产生一个完全无关的图,这张图片必须要保留有原来输入的资讯。
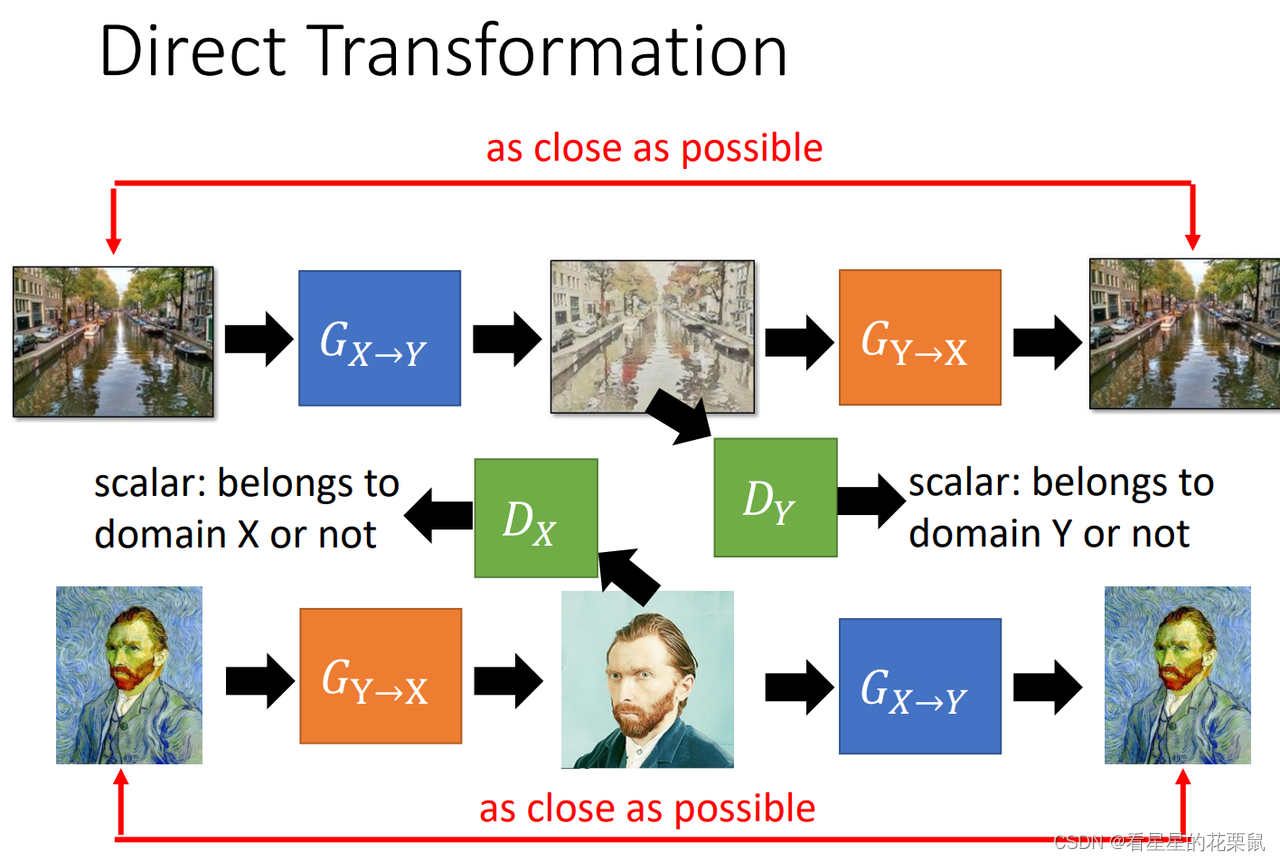
双向的:把两个 generator 两个discriminator一起训练
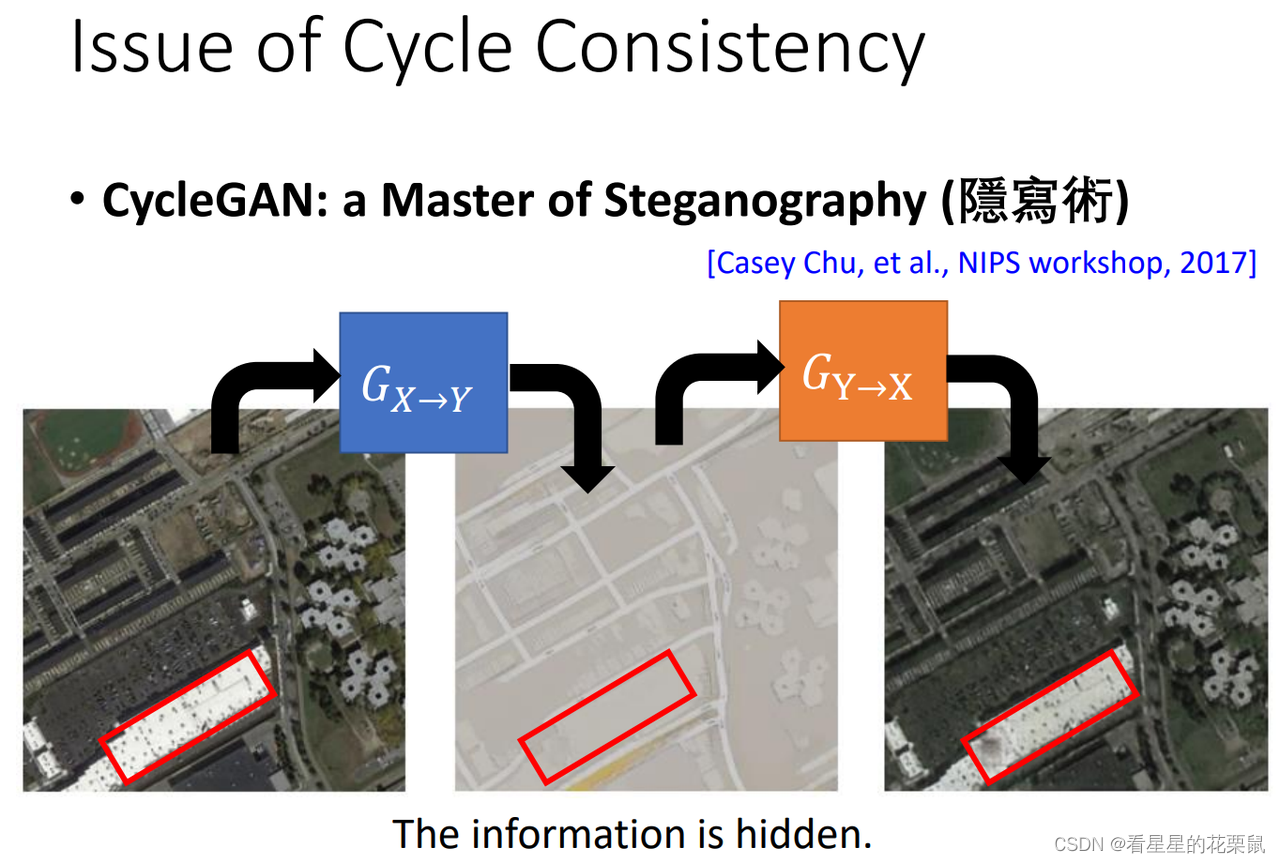
隐藏建筑,还原后屋顶还是有黑点:generator 有很强的能力把资讯藏在人看不出来的地方,比如中间 image 的资讯可能是用非常非常小的数值藏在 image 里面,让你看不出来。这样也许这个屋顶上仍然是有黑点的,只是看不出来而已。
如果generator很擅长藏资讯并且自己解回来,cycle consistency中,中间的图片就有可能和原图差距很大了(尚待研究)。cycle consistency不一定有用,machine可能会自己学到一些方法去避开 cycle consistency 带给你的 constrain
几乎相同的方法:
Star GAN
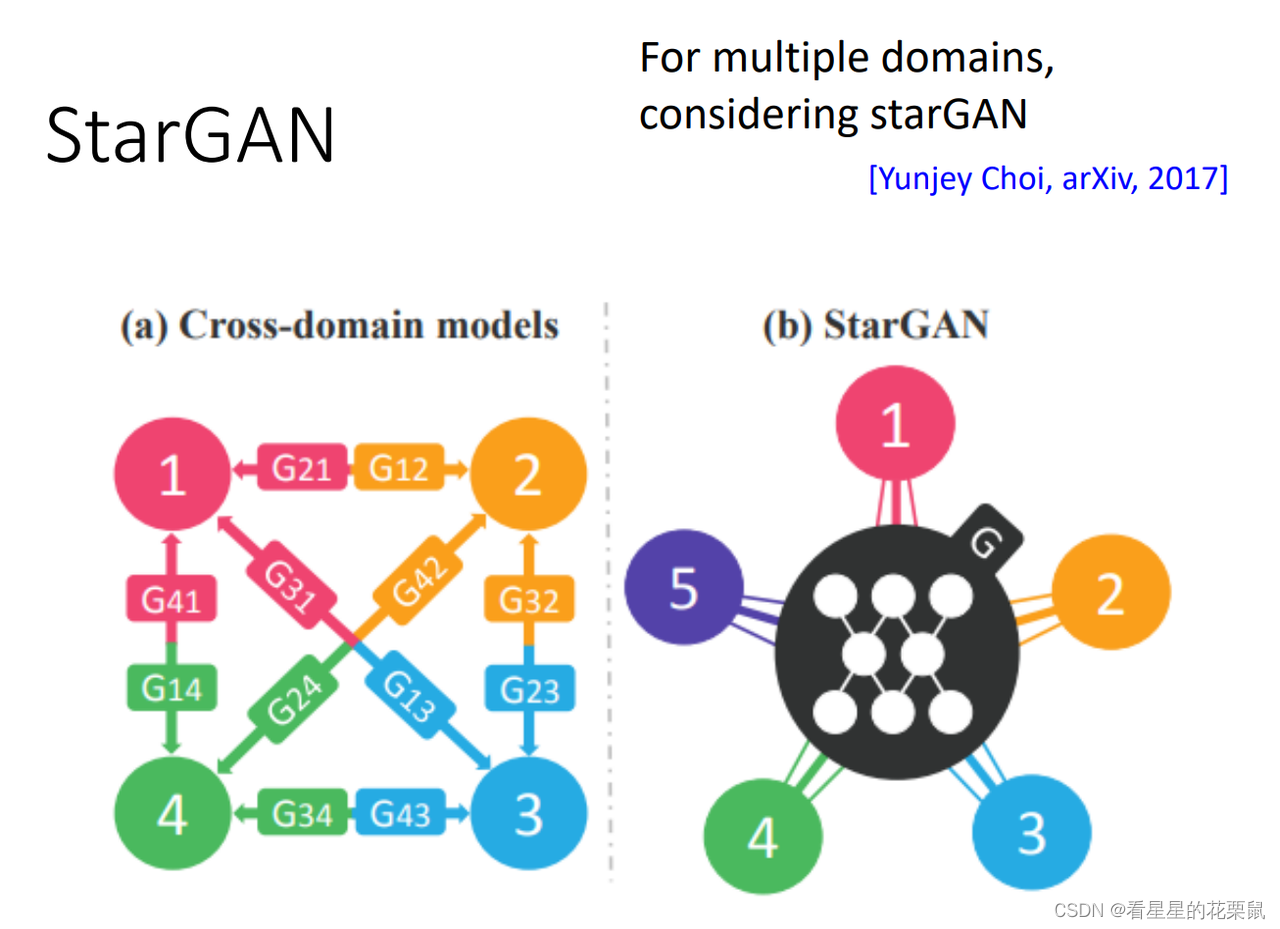
只学习一个generator 就可以多个domain互转

一个discriminator,要做的事:鉴别图片是否真实、来自哪个domain
一个generator :输入一张图&目标domain,输出一张生成的图片
然后再给同样的generator,输入fake image和目标domain,合成回之前的图片,越接近越好
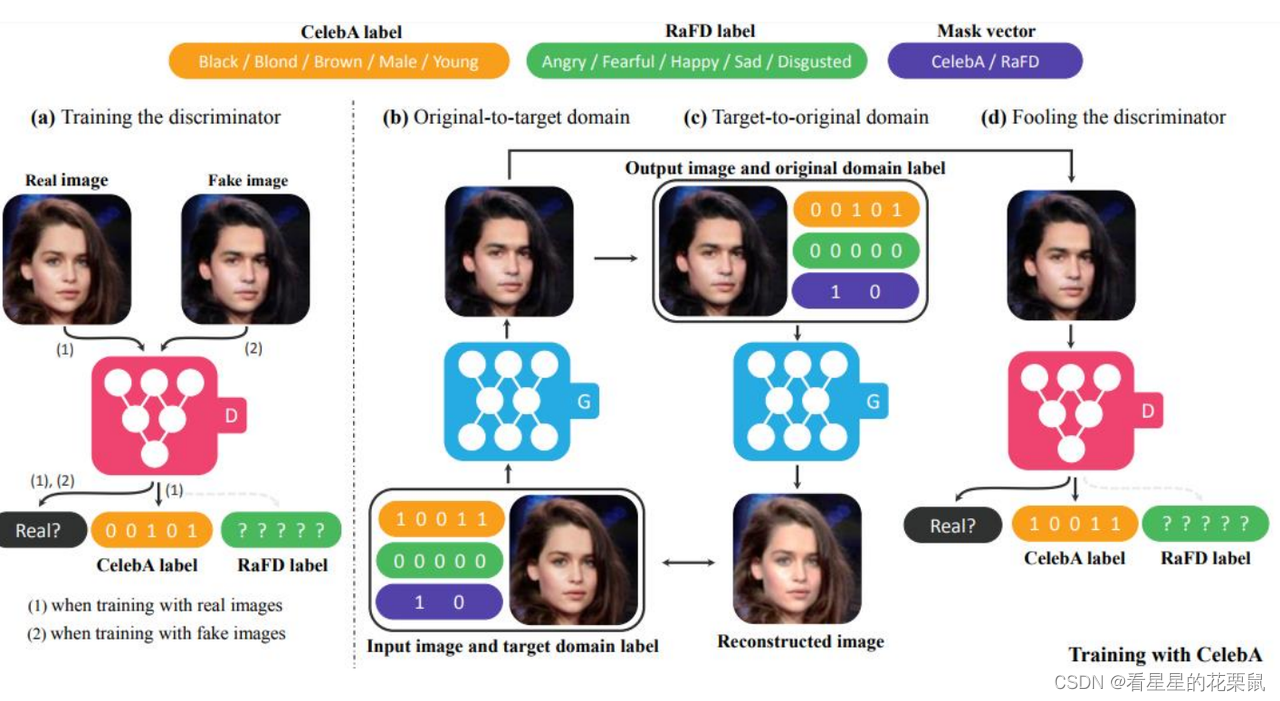
下面是实际的例子: 判别器做的事是首先判断它是real的还是fake;然后还有判断它是不是目标的domain;domain的表示是很多属性编码的,目标domain中:第一个10011黑色头发男性年轻、00000表示没有情绪、10表示只表示前面没有情绪;原始domian中:00101表示棕色女性年轻,00000表示没有情绪,10表示不显示情绪;
- 首先让生成器将棕色女和目标domain转成黑色男,然后黑色男和原始domain通过同样的生成器转换为棕色女然后你希望输入和输出的棕色女越接近越好;(cycle consistency的loss)
- 接下来你要确保输出的黑色男image是real的并且是和目标domain是一样的
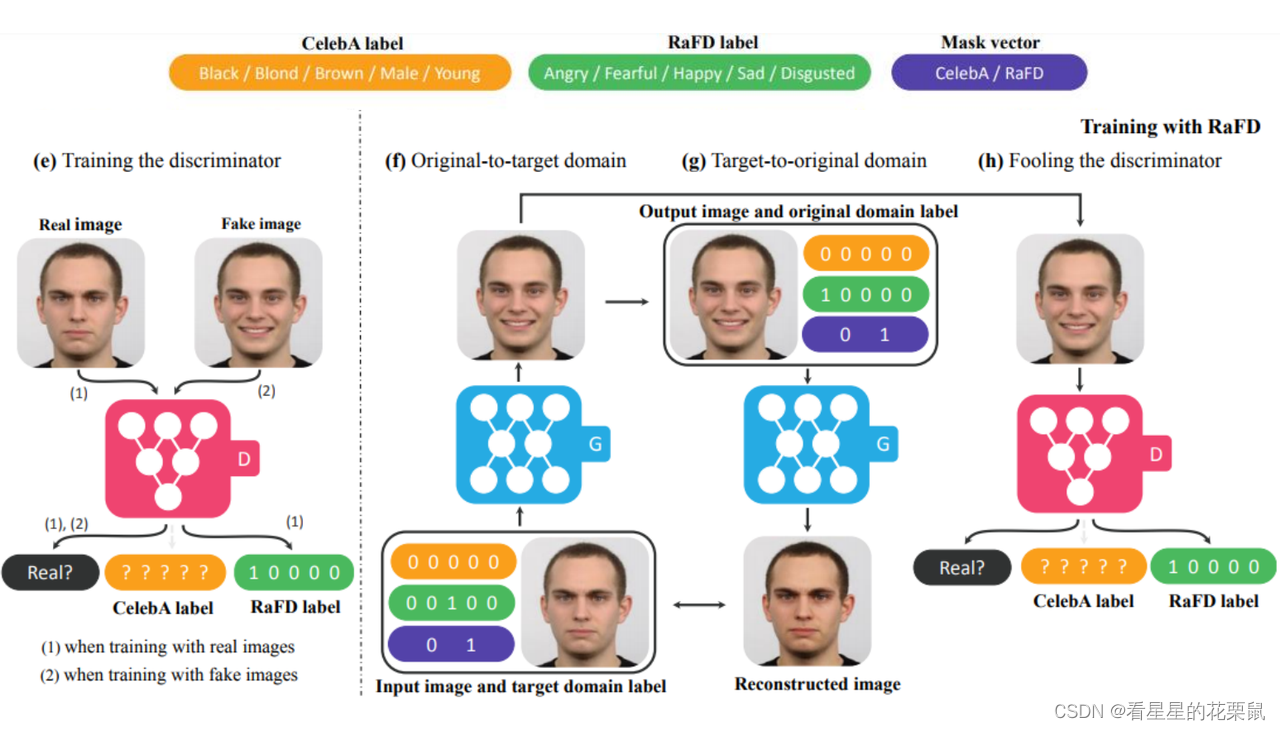
并不是只有几个domain,而是每个domain都有一个编码,代表一些不同特征。discriminator要判断这些特征
二、Projection to Common Space

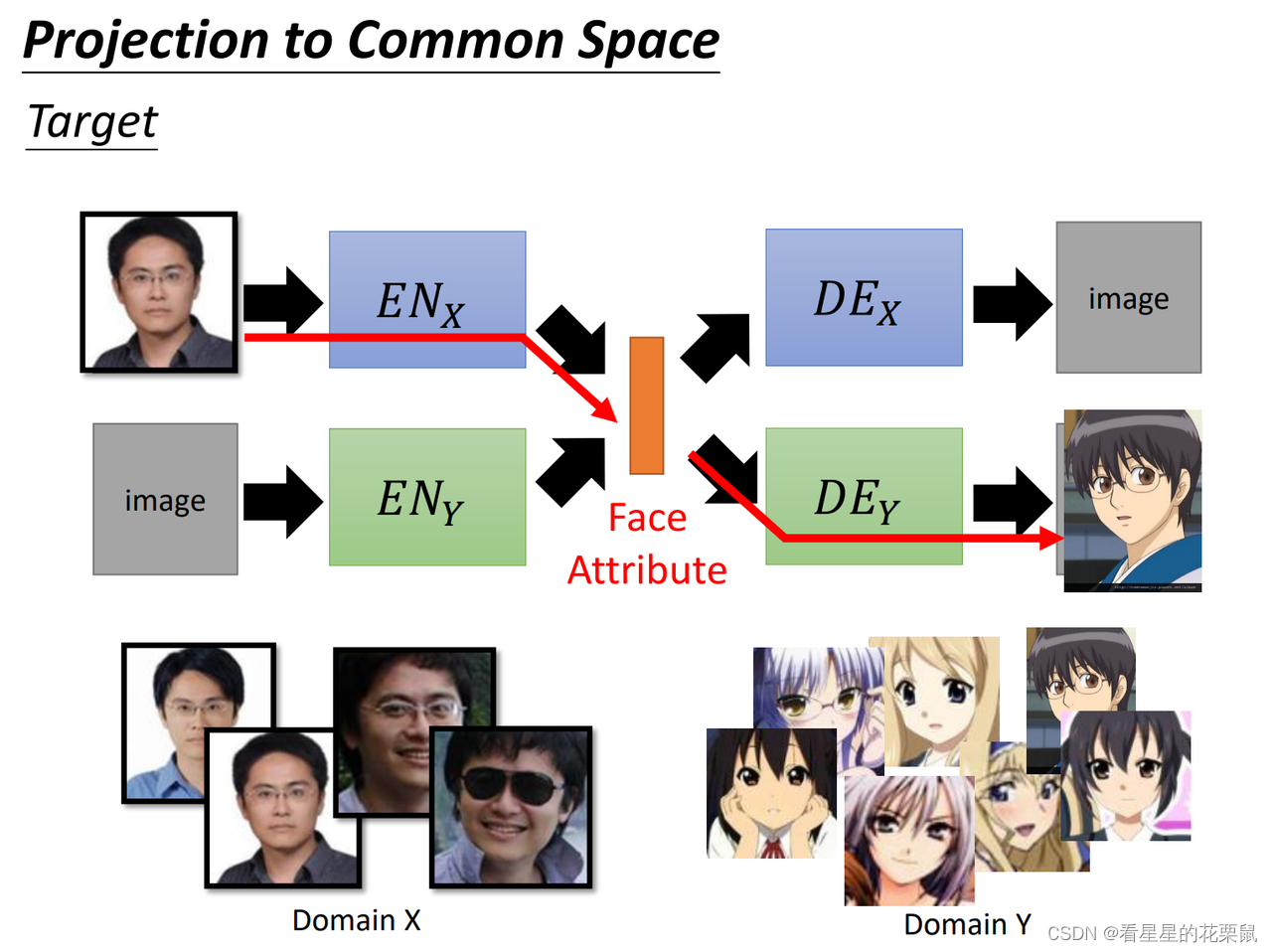
把输入的object投影到某一个latent的space,再用decoder把它合回來。需要一个X domian的encoder,看到一张真正的头像,就把它的特征抽出来······
unsupervised的问题只有X domain的图片。

可以让encoder和decoder组合成auto-encoder,输入一张Xdomain的图,让他reconstruction之前一样的图;Ydomain同理。它們都是要minimize reconstruction error。但是这样得到的两个 encoder和两个 decoder 之间没有任何关联。还可以把discriminator加进来,鉴别是否属于某一个风格,避免模糊。
E
N
X
+
D
E
X
+
D
X
=
V
A
E
G
A
N
,
E
N
Y
+
D
E
Y
+
D
Y
=
V
A
E
G
A
N
EN_X+DE_X+D_X = VAE\ GAN, \ EN_Y+DE_Y+D_Y = VAE\ GAN
ENX+DEX+DX=VAE GAN, ENY+DEY+DY=VAE GAN
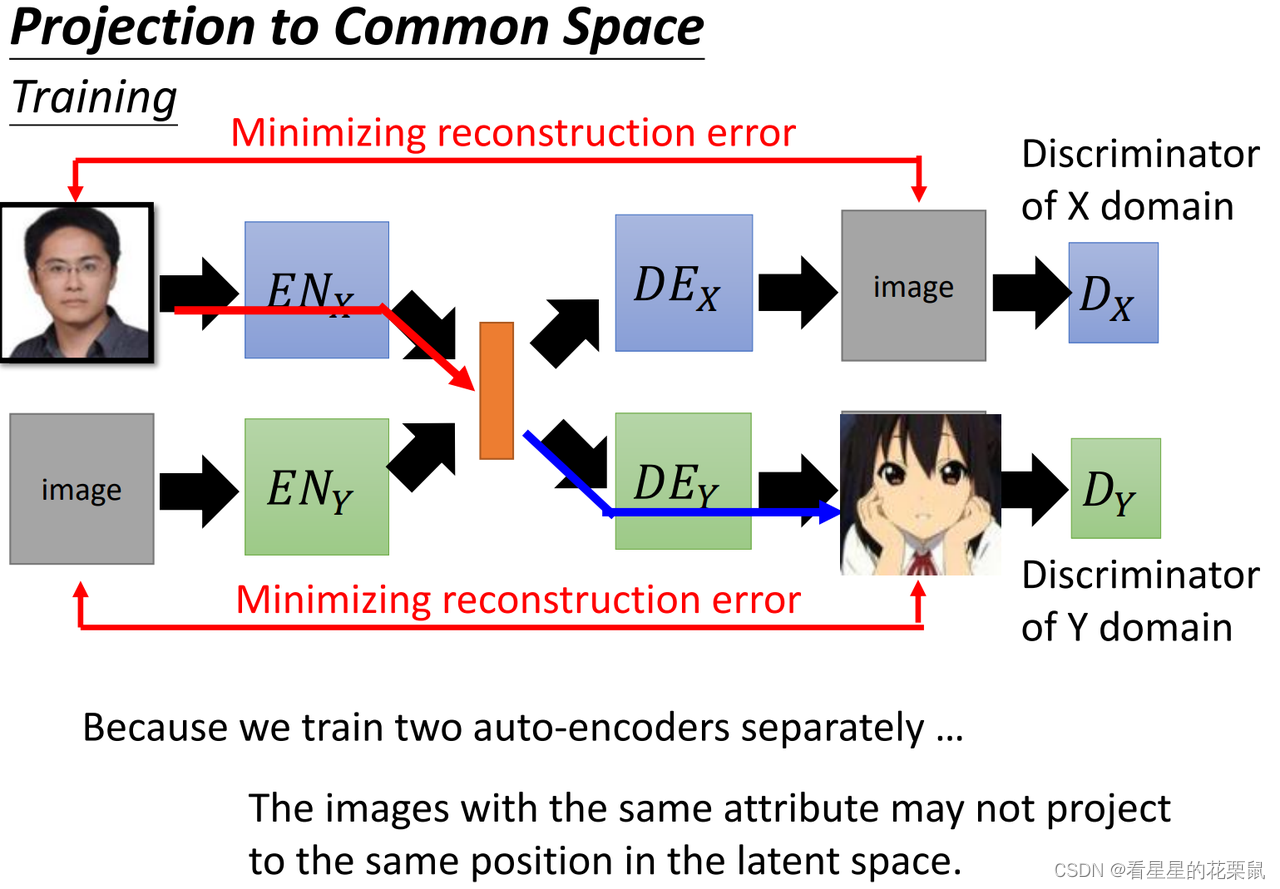
由于两个auto-encoder是分开训练的,所以两者之间是没有关联的;例如当你丢个X domain的人脸进去,变成一个vector,当输如Y domain的encoder中时,可能出现一个截然不同的卡通人物。因为是分开训练的,所以在latent space中每个维度的表示属性是不一样的,如上面的auto-encoder用第一维代表性别,而下面一组则用其他代表性别;
解决方法:
1、共享参数
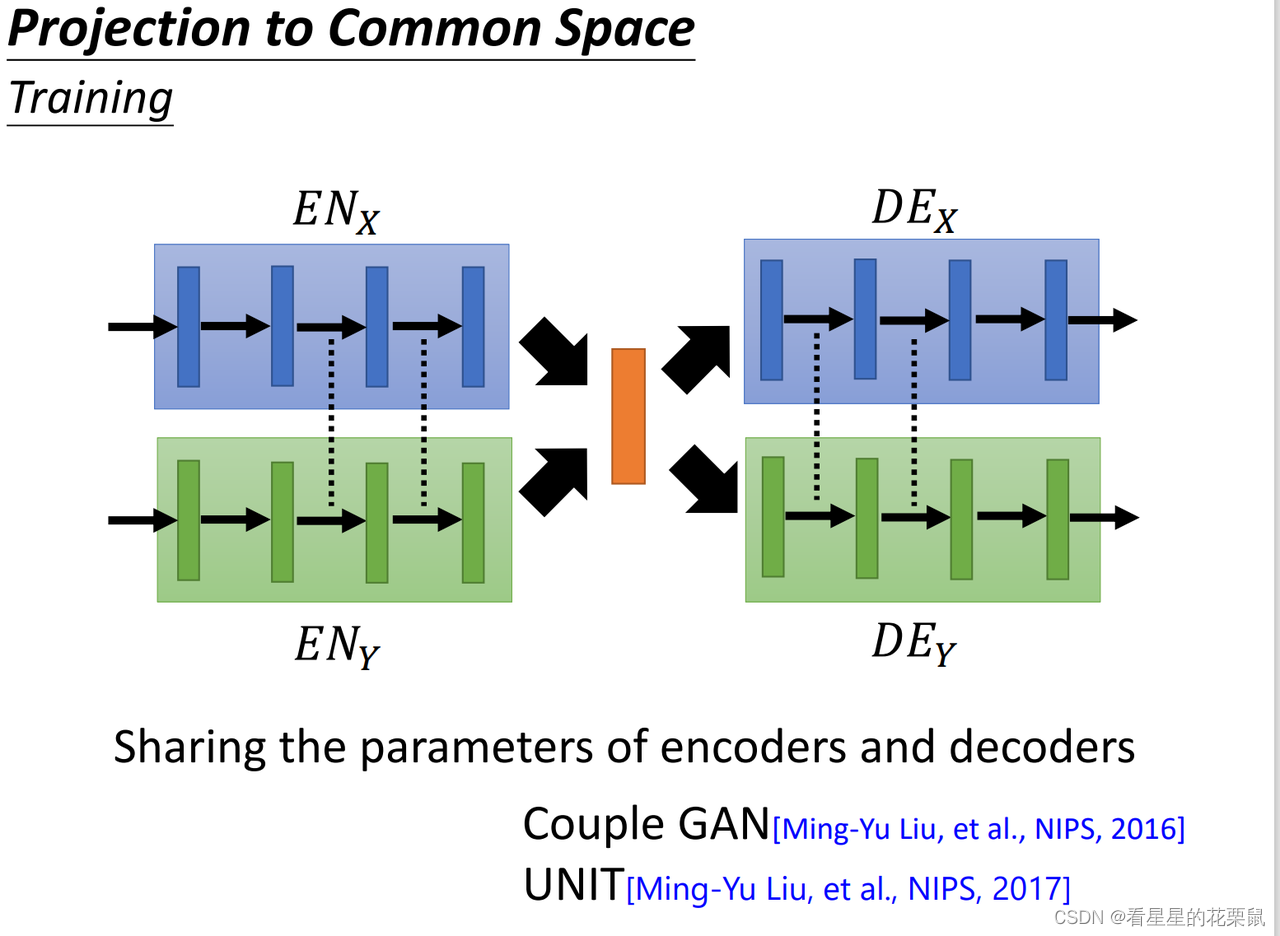 encoder和decoder都有很多hidden layer,可以把不同domain的encoder、decoder的参数联系在一起。encoder前几层可以不同,**后几层要共用;decoder前几层要共用,**后几层可以不一样.
encoder和decoder都有很多hidden layer,可以把不同domain的encoder、decoder的参数联系在一起。encoder前几层可以不同,**后几层要共用;decoder前几层要共用,**后几层可以不一样.
也许会因为最后几个 hide layer 的共用,让这两个 encoder 把 image压到latent space的时候,用同样的 dimension 来表示同样的人脸的特征。最极端的状况是两个encoder他们参数完全一样,只是给他们不同的 input 让他们知道现在是不同的domain.
2、加一个domain discriminator
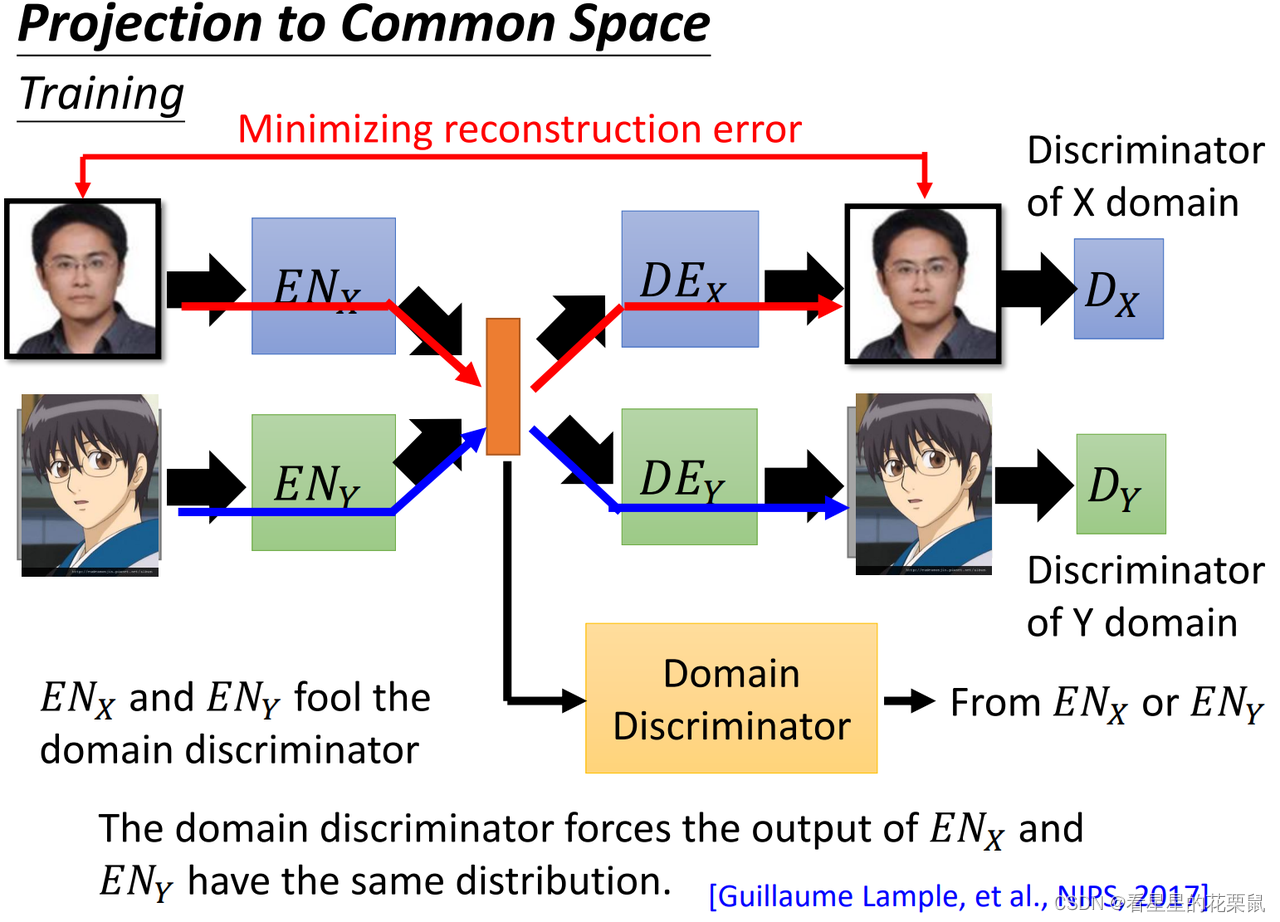
还可以加一个domain的discriminator,判断属于vector来自X domain还是Y domain的image。两个 encoder的工作就是去骗过这个discriminator,让它无法判断来自哪一边,这就意味着两个domain变成vector时distribution是一样的(同样的维度就代表了同样的意思)
3、Cycle Consistency

使input和output接近,与cycle GAN类似。将一张image经过X encoder变成code;再经过Y docoder把它解回来;然后再丢给Y domain的encoder,再透过X domain的decoder把它解回来;然后希望input和output越接近越好。
但是cycle GAN中说X domain到y domain generator是一个network,没有把切成encoder跟decoder,但这里会把X domain到y domain的network切成x domain encoder和y domain decoder
4、Semantic Consistency
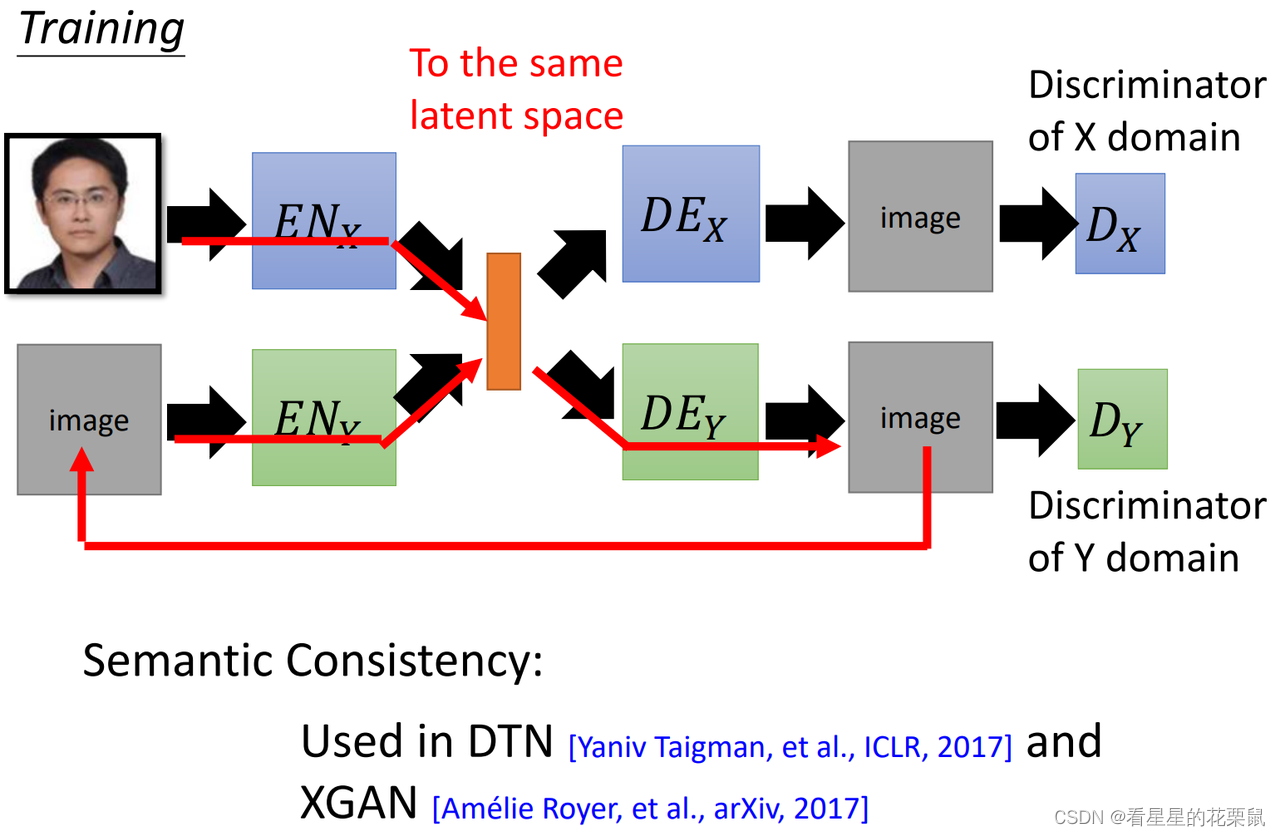
在latent space看consistency
使中间的code接近。不同之处:图像与图像对比时是基于像素的,不用考虑semantic像不像,只考虑表象(有什么区别?),而在中间code考虑时要考虑semantic像不像