1.信息熵
(1)熵
熵代表随机分布不确定程度,熵越大,不确定越大。随机变量X熵的定义如下:
H
(
X
)
=
−
∑
i
=
1
n
p
(
x
i
)
l
o
g
p
(
x
i
)
=
−
∫
x
p
(
x
)
l
o
g
p
(
x
)
d
x
H(X)=-\sum_{i=1}^{n}p(x_i)log\,p(x_i)=-\int_{x}p(x)log\,p(x)dx
H(X)=−i=1∑np(xi)logp(xi)=−∫xp(x)logp(x)dx
注:
熵只依赖于随机变量的分布,与随机变量取值无关;
定义0log0=0(因为可能出现某个取值概率为0的情况);
熵越大,随机变量的不确定性就越大,分布越混乱,随机变量状态数越多。
(2)联合熵
推广到多维随机变量的联合分布,其联合信息熵为:
H
(
X
,
Y
)
=
−
∑
i
=
1
n
∑
j
=
1
m
p
(
x
i
,
y
j
)
l
o
g
p
(
x
i
,
y
j
)
H(X,Y)=-\sum_{i=1}^{n}\sum_{j=1}^{m}p(x_i,y_j)log \, p(x_i,y_j)
H(X,Y)=−i=1∑nj=1∑mp(xi,yj)logp(xi,yj)
(3)条件熵
在X给定条件下,Y的条件概率分布的熵对X的数学期望,(X,Y)发生所包含的熵,减去X单独发生包含的熵:在X发生的情况下,Y发生“新”带来的熵。
H
(
Y
∣
X
)
=
H
(
X
,
Y
)
−
H
(
X
)
=
−
∑
x
,
y
p
(
x
,
y
)
l
o
g
p
(
x
,
y
)
+
∑
x
p
(
x
)
l
o
g
p
(
x
)
=
−
∑
x
,
y
p
(
x
,
y
)
l
o
g
p
(
x
,
y
)
+
∑
x
(
∑
p
(
x
,
y
)
)
l
o
g
p
(
x
)
=
−
∑
x
,
y
p
(
x
,
y
)
l
o
g
p
(
x
,
y
)
+
∑
x
,
y
p
(
x
,
y
)
l
o
g
p
(
x
)
=
−
∑
x
,
y
p
(
x
,
y
)
l
o
g
p
(
x
,
y
)
p
(
x
)
=
−
∑
x
,
y
p
(
x
,
y
)
l
o
g
p
(
y
∣
x
)
\begin{aligned} H(Y|X)=&H(X,Y)-H(X) \\ =&-\sum_{x,y}p(x,y)log\,p(x,y) + \sum_{x}p(x)log\,p(x)\\ =&-\sum_{x,y}p(x,y)log\,p(x,y) + \sum_x(\sum p(x,y))log\,p(x) \\ =&-\sum_{x,y}p(x,y)log\,p(x,y) + \sum_{x,y}p(x,y)log\,p(x)\\ =& - \sum_{x,y}p(x,y)log \frac{p(x,y)}{p(x)} \\ =&- \sum_{x,y}p(x,y)log\,p(y|x) \end{aligned}
H(Y∣X)======H(X,Y)−H(X)−x,y∑p(x,y)logp(x,y)+x∑p(x)logp(x)−x,y∑p(x,y)logp(x,y)+x∑(∑p(x,y))logp(x)−x,y∑p(x,y)logp(x,y)+x,y∑p(x,y)logp(x)−x,y∑p(x,y)logp(x)p(x,y)−x,y∑p(x,y)logp(y∣x)
根据条件熵的定义式,可以得到
H
(
Y
∣
X
)
=
−
∑
x
,
y
p
(
x
,
y
)
l
o
g
p
(
y
∣
x
)
=
−
∑
x
∑
y
p
(
x
,
y
)
l
o
g
p
(
y
∣
x
)
=
−
∑
x
∑
y
p
(
y
∣
x
)
p
(
x
)
l
o
g
p
(
y
∣
x
)
=
−
∑
x
p
(
x
)
∑
y
p
(
y
∣
x
)
l
o
g
p
(
y
∣
x
)
=
∑
x
p
(
x
)
(
−
∑
y
p
(
y
∣
x
)
l
o
g
p
(
y
∣
x
)
)
=
∑
x
p
(
x
)
H
(
Y
∣
X
=
x
)
\begin{aligned} H(Y|X)=&- \sum_{x,y}p(x,y)log\,p(y|x) \\ =&-\sum_{x}\sum_{y}p(x,y)log\,p(y|x)\\ =&-\sum_{x}\sum_{y}p(y|x)p(x)log\,p(y|x)\\ =&-\sum_xp(x)\sum_yp(y|x)log\,p(y|x)\\ =&\sum_xp(x)(-\sum_yp(y|x)log\,p(y|x))\\ =&\sum_xp(x)H(Y|X=x)\\ \end{aligned}
H(Y∣X)======−x,y∑p(x,y)logp(y∣x)−x∑y∑p(x,y)logp(y∣x)−x∑y∑p(y∣x)p(x)logp(y∣x)−x∑p(x)y∑p(y∣x)logp(y∣x)x∑p(x)(−y∑p(y∣x)logp(y∣x))x∑p(x)H(Y∣X=x)
(4)互信息
一个随机变量由于已知另一个随机变量而减少的不确定性。
I
(
X
,
Y
)
=
H
(
X
)
−
H
(
X
∣
Y
=
y
)
=
H
(
Y
)
−
H
(
Y
∣
X
=
x
)
=
H
(
X
)
+
H
(
Y
)
−
H
(
X
,
Y
)
\begin{aligned} I(X,Y)=&H(X)-H(X|Y=y)=H(Y)-H(Y|X=x)\\ =&H(X)+H(Y)-H(X,Y) \end{aligned}
I(X,Y)==H(X)−H(X∣Y=y)=H(Y)−H(Y∣X=x)H(X)+H(Y)−H(X,Y)
2.决策树学习算法
(1) 决策树
决策树是一种树形模型,其中每一个内部节点表示在一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一个类别。
决策树采用的是自顶向下的递归方法,其基本思想是以信息熵为度量构造一颗熵值下降最快的树,到叶子节点处熵值为0,此时在每个节点中的实例都属于同一个类别。
决策树特点:可以自学习,不需要使用者了解过多背景知识,只需要对训练数据做好标记,是一个有监督学习,从一类无序无规则的事务中推断出决策树表示的规则。决策树示意图如下:

(2) 决策树生成算法
建立决策数的关键是在当前状态下选择哪个属性作为分类依据。根据不同的目标函数,决策树主要有三种算法:ID3,C4.5,CART。
(3)信息增益
概念:表示得知特征A的信息而使得类X的不确定性减少的程度。当熵和条件熵中的概率由数据估计(特别是极大似然估计)得到时,所对应的熵和条件熵分别称为经验熵和经验条件熵。
数学定义:特征A对训练数据集D的信息增益
g
(
D
,
A
)
g(D,A)
g(D,A),定义为集合D的经验熵
H
(
D
)
H(D)
H(D)与特征A给定条件下D的经验条件熵
H
(
D
∣
A
)
H(D|A)
H(D∣A)之差,即:
g
(
D
,
A
)
=
H
(
D
)
−
H
(
D
∣
A
)
g(D,A)= H(D) - H(D|A)
g(D,A)=H(D)−H(D∣A)
信息增益计算方法:
记号:训练数据集D,
∣
D
∣
|D|
∣D∣表示样本个数;设有K个类
C
k
(
k
=
1
,
2
,
⋯
,
K
)
C_k(k=1,2,\cdots,K)
Ck(k=1,2,⋯,K),
∣
C
k
∣
|C_k|
∣Ck∣属于类
C
k
C_k
Ck的样本个数,则有
∑
k
∣
C
k
∣
=
∣
D
∣
\sum_k|C_k|=|D|
∑k∣Ck∣=∣D∣;设特征A有n个不同的取值
{
a
1
,
a
2
,
⋯
,
a
n
}
\{a_1,a_2,\cdots,a_n\}
{a1,a2,⋯,an},根特征A将D划分为n个子集
D
1
,
D
2
,
⋯
,
D
n
D_1,D_2,\cdots,D_n
D1,D2,⋯,Dn,
∣
D
i
∣
|D_i|
∣Di∣为
D
i
D_i
Di的样本个数,有
∑
i
∣
D
i
∣
=
∣
D
∣
\sum_i|D_i|=|D|
∑i∣Di∣=∣D∣;记子集|D_i|中,属于类
C
k
C_k
Ck的样本的集合为
D
i
k
D_{ik}
Dik,
∣
D
i
k
∣
|D_{ik}|
∣Dik∣为
D
i
k
D_{ik}
Dik的样本个数。
计算方法:
(i)计算数据D的经验熵
H
(
D
)
=
−
∑
k
=
1
K
∣
C
k
∣
∣
D
∣
l
o
g
∣
C
k
∣
∣
D
∣
H(D)=-\sum_{k=1}^{K}\frac{|C_k|}{|D|}log\frac{|C_k|}{|D|}
H(D)=−∑k=1K∣D∣∣Ck∣log∣D∣∣Ck∣
(ii)遍历所有特征,对特征A有:
计算特征A对数据集D的经验条件熵
H
(
D
∣
A
)
H(D|A)
H(D∣A);
计算A的特征增益
g
(
D
,
A
)
=
H
(
D
)
−
H
(
D
∣
A
)
g(D,A)= H(D) - H(D|A)
g(D,A)=H(D)−H(D∣A);
选择信息增益最大的特征作为当前的分裂特征。
经验条件熵:
H
(
D
∣
A
)
=
−
∑
i
,
k
p
(
D
k
,
A
i
)
l
o
g
p
(
D
k
∣
A
i
)
=
−
∑
i
,
k
p
(
A
i
)
p
(
D
k
∣
A
i
)
l
o
g
p
(
D
k
∣
A
i
)
=
−
∑
i
=
1
n
∑
k
=
1
K
p
(
A
i
)
p
(
D
k
∣
A
i
)
l
o
g
p
(
D
k
∣
A
i
)
=
−
∑
i
=
1
n
p
(
A
i
)
∑
k
=
1
K
p
(
D
k
∣
A
i
)
l
o
g
p
(
D
k
∣
A
i
)
=
−
∑
i
=
1
n
∣
D
i
∣
∣
D
∣
∑
k
=
1
K
∣
D
i
k
∣
∣
D
i
∣
l
o
g
∣
D
i
k
∣
∣
D
i
∣
\begin{aligned} H(D|A)=&-\sum_{i,k}p(D_k,A_i)log\,p(D_k|A_i)\\ =&-\sum_{i,k}p(A_i) p(D_k|A_i)log\,p(D_k|A_i)\\ =&-\sum_{i=1}^{n}\sum_{k=1}^{K}p(A_i) p(D_k|A_i)log\,p(D_k|A_i)\\ =&-\sum_{i=1}^{n}p(A_i)\sum_{k=1}^{K}p(D_k|A_i)log\,p(D_k|A_i)\\ =&-\sum_{i=1}^{n}\frac{|D_i|}{|D|}\sum_{k=1}^{K}\frac{|D_{ik}|}{|D_i|}log\frac{|D_{ik}|}{|D_i|} \end{aligned}
H(D∣A)=====−i,k∑p(Dk,Ai)logp(Dk∣Ai)−i,k∑p(Ai)p(Dk∣Ai)logp(Dk∣Ai)−i=1∑nk=1∑Kp(Ai)p(Dk∣Ai)logp(Dk∣Ai)−i=1∑np(Ai)k=1∑Kp(Dk∣Ai)logp(Dk∣Ai)−i=1∑n∣D∣∣Di∣k=1∑K∣Di∣∣Dik∣log∣Di∣∣Dik∣
(4)信息增益率
g
r
(
D
,
A
)
=
H
(
D
,
A
)
H
(
A
)
g_{r}(D,A)=\frac{H(D,A)}{H(A)}
gr(D,A)=H(A)H(D,A)
(5)Gini系数
G
i
n
i
(
p
)
=
∑
k
=
1
K
p
k
(
1
−
p
k
)
=
1
−
∑
k
=
1
K
p
k
2
=
1
−
∑
k
=
1
K
(
∣
C
k
∣
∣
D
∣
)
2
Gini(p)=\sum_{k=1}^{K}p_k(1-p_k)=1-\sum_{k=1}^{K}p_k^2=1-\sum_{k=1}^{K}(\frac{|C_k|}{|D|})^2
Gini(p)=k=1∑Kpk(1−pk)=1−k=1∑Kpk2=1−k=1∑K(∣D∣∣Ck∣)2
(6)ID3算法举例
我们使用不真实账号检测的例子说明如何使用ID3算法构造决策树,ID3使用信息增益作为属性分类的标准。为了简单起见,我们假设训练集合包含10个元素。

python代码如下:
#在决策树当中,设D用为类别对训练元组进行的划分,则D的熵(entropy)表示为:
info_D = -0.7*math.log2(0.7)-0.3*math.log2(0.3)
#计算日志密度的信息增益
info_L = 0.3*(-1/3*math.log2(1/3)-2/3*math.log2(2/3))+0.4*(-1/4*math.log2(1/4)-3/4*math.log2(3/4))+0.3*(-math.log2(1))
l = info_D - info_L
#计算是否使用真实头像的信息增益
info_H = 0.5*(-2/5*math.log2(2/5)-3/5*math.log2(3/5))+0.5*(-1/5*math.log2(1/5)-4/5*math.log2(4/5))
h = info_D - info_H
#计算好友密度的信息增益
info_F = 0.4*(-3/4*math.log2(3/4)-1/4*math.log2(1/4))+0.4*(-math.log2(1))+0.2*(-math.log2(1))
f = info_D - info_F
print(l,h,f)


在上图的基础上,再递归使用这个方法计算子节点的分裂属性,最终就可以得到整个决策树
(7)三种决策树学习算法
ID3使用信息增益进行选择,取值多的属性,更容易使数据更纯,其信息增益更大,训练得到一颗庞大且深度较浅的树:不合理;
C4.5使信息增益率;
CART使用基尼系数,Cart可以用作分类和回归,二叉树实现,SKLearn使用此算法。
(8)回归树
回归树是可以用于回归的决策树模型,一个回归树对应着输入空间(即特征空间)的一个划分以及在划分单元上的输出值.与分类树不同的是,回归树对输入空间的划分采用一种启发式的方法,会遍历所有输入变量,找到最优的切分变量j和最优的切分点s,即选择第j个特征
x
j
x^j
xj和它的取值ss将输入空间划分为两部分,然后重复这个操作。
而如何找到最优的j和s是通过比较不同的划分的误差来得到的。一个输入空间的划分的误差是用真实值和划分区域的预测值的最小二乘来衡量的,即
∑
x
i
∈
R
m
(
y
i
−
f
(
x
i
)
)
2
\sum_{x_{i} \in R_{m}}\left(y_{i}-f\left(x_{i}\right)\right)^{2}
xi∈Rm∑(yi−f(xi))2

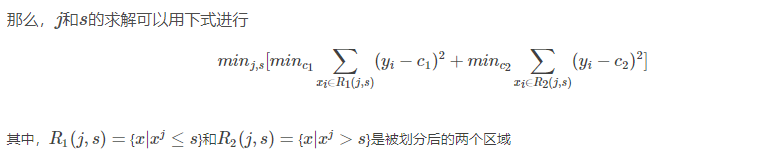

3.决策树的评价
记号:
假定样本总类别是K;
对于决策树的某叶节点,假定该叶节点中所含的样本个数为n,其中第K类样本个数为
n
k
n_k
nk,
k
=
1
,
2
,
⋯
,
K
k=1,2,\cdots,K
k=1,2,⋯,K,若某类样本
n
j
=
n
n_j=n
nj=n,而
n
1
,
⋯
,
n
j
−
1
,
n
j
+
1
,
⋯
,
n
K
=
0
n_1,\cdots,n_{j-1},n_{j+1},\cdots,n_K=0
n1,⋯,nj−1,nj+1,⋯,nK=0,则称该节点为纯节点,若各类样本数目
n
1
=
n
2
=
⋯
=
n
K
=
n
K
n_1=n_2=\cdots=n_K=\frac{n}{K}
n1=n2=⋯=nK=Kn,则称该样本为均样本;
纯节点熵
H
p
=
0
H_p=0
Hp=0,最小;
均节点熵
H
u
=
l
n
K
H_u=lnK
Hu=lnK,最大;
对所有叶节点熵求和,该值越小,说明对样本的分类越精确,各叶节点包含的样本数目不同,可使用样本数加权求熵和。
评价函数:
C
(
T
)
=
∑
t
∈
l
e
a
f
N
t
⋅
H
(
t
)
C(T)=\sum_{t\in leaf}N_t \cdot H(t)
C(T)=t∈leaf∑Nt⋅H(t)
该损失函数越小越好,也可叫做“损失函数”。
4.决策树的过拟合
决策树对训练集有很好的分类能力,但对未知的测试数据未必有好的分类能力,泛化能力弱,即可能发生过拟合现象。
解决过拟合方法:随机森林。
(1)Bagging策略
从样本集中重采样(有重复的)选出n个样本;
在所有属性中,对这n个样本建立分类器(ID3,C4.5,CART,SVM,logistic回归);
重复以上以上两步m次,即获取了m个分类器;
将数据放在这m个分类器中,根据投票结果,决定数据属于哪一类。
Bagging策略如下图示意:

(2)OOB数据
可以看出,Bootstrap(有放回采样)每次约有
36.79
36.79%
36.79的样本不会出现在Bootstrap所采集的样本集合中,将未参与模型训练的数据叫做袋外数据(OOB),他可以取代测试集用于误差估计。Breiman以经验性实例的形式证明袋外数据误差估计与同训练集一样大小的测试集精度相同,得到的模型参数是无偏估计。
(3)随机森林
从样本集中用Bootstrap采样选出了n个样本;
从所有属性中随机选择k个属性,选择最佳分割属性作为节点建立CART决策树;
重复以上两步m次,即建立了m棵CART决策树;
这m个CART形成了随机森林,通过投票表决结果,决定数据属于哪一类。
4.随机森林和决策树的关系
可以使用决策树作为基本分类器,但也可以使用SVM,Logistic回归等其他分类器,习惯上,这些分类器组成的“总分类器“,仍然叫随机森林。
5.样本不均衡的常用处理方法
假定样本数目A类比B类多,且严重不平衡:
A类欠采样:随机欠采样,将A类分成若干子类,分别与B类进入ML模型,基于聚类的A类分割。
B类过采样,避免欠采样造成的信息丢失。
B类数据合成Synthetic Data Generation:随机插值得到新样本。
敏感学习:降低A类权值,提高B类权值。
6.随机森林的应用
(1)使用RF建立计算样本间相似度:
原理:若两个样本同时出现在相同叶节点的次数越多,则二者越相似。
算法过程:
记样本个数为N,初始化
N
×
N
N\times N
N×N的零矩阵S,
S
[
i
,
j
]
S[i,j]
S[i,j]表示样本i和样本j的
相似度。
对于m棵决策树形成的随机森林,遍历所有决策树的所有叶子节点:
记该叶子节点包含的样本为
s
a
m
p
l
e
[
1
,
2
,
⋯
,
k
]
sample[1,2,\cdots,k]
sample[1,2,⋯,k],则
S
[
i
]
[
j
]
S[i][j]
S[i][j]累加1。样
本
i
,
j
∈
s
a
m
p
l
e
[
1
,
2
,
⋯
,
k
]
i,j\in sample[1,2,\cdots,k]
i,j∈sample[1,2,⋯,k],样本
i
.
j
i.j
i.j出现在相同叶节点的次数增加1次。
遍历结束,则S为样本间相似度矩阵。
(2)使用RF计算特征重要度
随机森林是常用的衡量特征重要性的方法。计算正例经过的节点,使用经过节点的数目,经过节点的gini系数和等指标。或者,随机替换一列数据,重新建立决策树,计算新模型的正确率变化,从而考虑这一列特征的重要性。
(3)Isolation Forest
随机选择特征,随机选择分割点,生成一定深度的决策树iTree,若干课iTree组成iForest。计算iTree中样本x从根到叶子节点的长度f(x),计算iForest中f(x)的总和
F
(
x
)
F(x)
F(x)。异常检测:若样本x为异常值,他应该在大多数iTree中很快达到叶子节点,即F(x)较小。