adaboost
二分类问题,给定一个数据集T={(x1,y1),(x2,y2)…,(xn,yn)} ,其中y取1和-1。
- **** 权值初始化,D1为第一轮的权重集合,w1i为第一轮第i个样本的权值
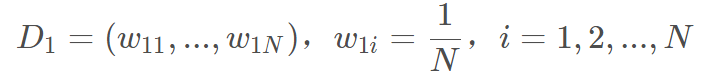
2. 用初始化权值的训练样本,训练出第一个基分类器。Gm(x)表示第m个基分类器。
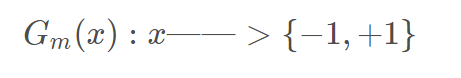
3. 计算基分类器Gm(x)在训练数据上的分类误差率。I为一个输出只有0和1的函数,所有样本的权值都相同且权值之和为1,所以权值之和代表误差率。在之后调整权值之后,也就是分类错误的样本权值增大后,下一轮迭代为了降低误差率,就会尽量把拥有较大权值的上一轮分类错误样本判断正确。
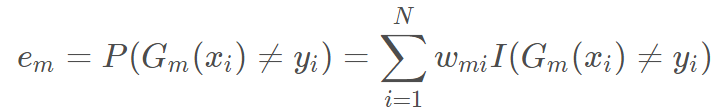
4. 基学习器结合,通过特定的系数线性加和,这里的对数是自然对数,这个系数实际是在衡量基分类器在最终分类器重的作用大小。当em≤1/2时,am≥0,am随着em的减小而增大
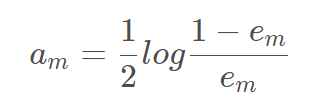
5. 学习下一个基学习器之前要根据之前的预测结果来调整权值,Zm是规范化因子,它使Dm+1成为一个概率分布。这个规范化因子就是个总和,作为分母使得权值即使调整但仍然压缩在0到1之间,因为误差率就是错误样本的权值之和,而压缩在0到1之间对成为概率是非常必要的。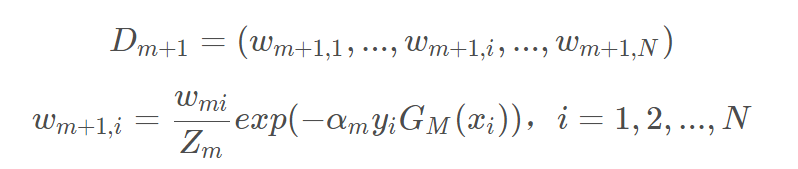
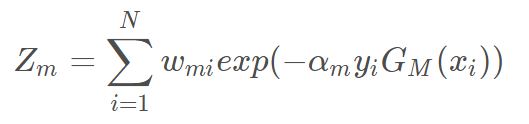
6. 调整完权值之后,继续学出一个基学习器,然后循环直至基学习器的数量到达设定。然后将所有的基分类器线性组合起来f(x),最后得到最终分类器G(x)。最终分类器f(x)的符号决定样本的分类,而f(x)的绝对值表示 分类的确信程度。
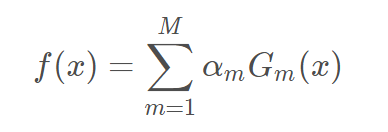
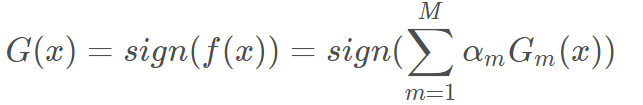
AdaBoost的训练误差是以指数速率下降的。
AdBoost不容易过拟合,其实是不容易,完全不会是不可能的。
参考:https://blog.csdn.net/zhaojc1995/article/details/84800437
GBDT(回归问题)
1.初始化弱学习器,损失函数为平方损失,平方损失函数是一个凸函数,直接求导,倒数等于零,得到c,初始化时,c取值为所有训练样本标签值的均值。
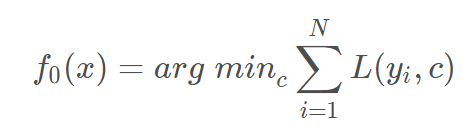
2.对于m个学习器:
a.对每个样本i=1,2,…,N计算负梯度,即残差.
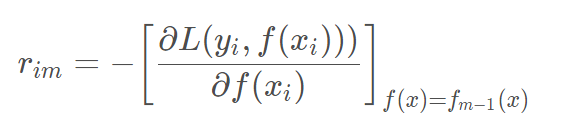
b.将上步得到的残差作为样本新的真实值,将数据(xi,rim)作为下棵树的训练数据,得到一颗新的回归树fm(x),其对应的叶子节点区域为Rjm,其中J为回归树t的叶子节点的个数。
c.对叶子区域j=1,2,…J计算最佳拟合值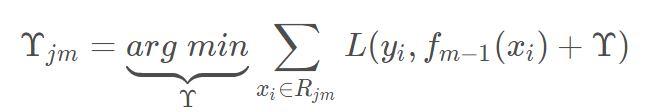
d.更新强学习器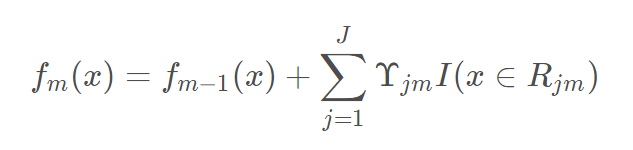
3.得到最终学习器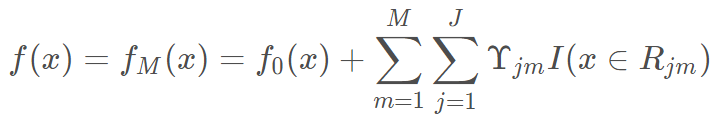
参考:https://blog.csdn.net/zpalyq110/article/details/79527653
XGBOOST
1.传统的GBDT以CART树作为基学习器,XGBoost还支持线性分类器,在使用线性分类器的时候可以使用L1,L2正则化。
2.传统的GBDT在优化的时候只用到一阶导数信息,XGBoost则对代价函数进行了二阶泰勒展开,得到一阶和二阶导数。在GBDT中我们通过求损失函数的负梯度(一阶导数),利用负梯度替代残差来拟合树模型。在XGBoost中直接用泰勒展开式将损失函数展开成二项式函数(前提是损失函数一阶、二阶都连续可导,而且在这里计算一阶导和二阶导时可以并行计算)。


上面式子把样本都合并到叶子节点中了。此时我们对wj求导并令导数为0,可得
 3.在代价函数中加入了正则项,用于控制模型的复杂度。式子中的T为叶子节点数。XGBoost的提升模型也是采用残差,不同的是分裂结点选取的时候不一定是最小平方损失,其损失函数如下,较GBDT其根据树模型的复杂度加入了一项正则化项。
3.在代价函数中加入了正则项,用于控制模型的复杂度。式子中的T为叶子节点数。XGBoost的提升模型也是采用残差,不同的是分裂结点选取的时候不一定是最小平方损失,其损失函数如下,较GBDT其根据树模型的复杂度加入了一项正则化项。
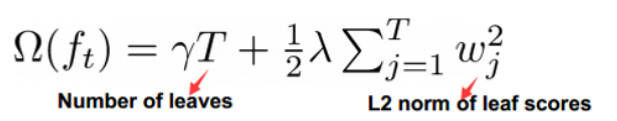
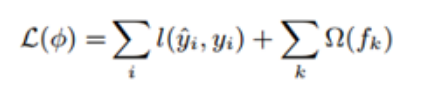
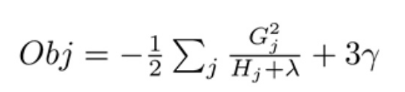
上面的Obj值代表当指定一个树结构时,在目标上面最多减少多少,我们可以把它称为结构分数。分数越小,树的结构越好。Gain 作为判断是否分割的条件,Gain是未分割前的Obj减去分割后的左右Obj,因此如果Gain<0,则此叶节点不做分割。

4.shrinkage(缩减),学习率。在寻找最佳分割点时,考虑到传统的贪心算法效率较低,实现了一种近似贪心算法,用来加速和减小内存消耗,除此之外还考虑了稀疏数据集和缺失值的处理,对于特征的值有缺失的样本,XGBoost依然能自动找到其要分裂的方向。在逻辑实现上,为了保证完备性,会分别处理将missing该特征值的样本分配到左叶子结点和右叶子结点的两种情形,计算增益后选择增益大的方向进行分裂即可。可以为缺失值或者指定的值指定分支的默认方向,这能大大提升算法的效率。如果在训练中没有缺失值而在预测中出现缺失,那么会自动将缺失值的划分方向放到右子树。
split and default directions with max gain!
5.支持列抽样,防止过 拟合,还能减少计算。采用特征子采样方法,和RandomForest中的特征子采样一样,可以降低模型的方差。
6.XGBoost工具支持并行。XGBoost的并行不是tree粒度的并行,XGBoost也是一次迭代完才能进行下一次迭代的(第t次迭代的代价函数里包含了前面t-1次迭代的预测值)。XGBoost的并行是在特征粒度上的。决策树的学习最耗时的一个步骤就是对特征的值进行排序(要确定最佳分割点),XGBoost在训练之前,预先对数据进行了排序,然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行。
block:
Block中的数据以稀疏格式CSC进行存储。csc的目的是为了压缩矩阵,减少矩阵存储所占
用的空间,手法无法就是通过增加一些"元信息"来描述矩阵中的非零元素存储的位置(基于
列),然后结合非零元素的值来表示矩阵。这样在一些场景下可以减少矩阵存储的空间。
Block中的特征进行排序(不对缺失值排序),且只需要排序一次,以后分裂树的过程可以复用。
参考:https://blog.csdn.net/qq_28031525/article/details/70207918
关于并行:https://blog.csdn.net/anshuai_aw1/article/details/85093106
关于缺失值:https://www.jianshu.com/p/5b8fbbb7e754
lightgbm
LightGBM的优化部分:
一、基于Histogram的决策树算法
histogram算法简单来说,就是先对特征值进行装箱处理,形成很多的bins。对于连续特征来说,装箱处理就是特征工程中的离散化:如[0,0.3)—>0,[0.3,0.7)—->1等。在Lightgbm中默认的#bins为256(1个字节的能表示的长度,可以设置)。对于分类特征来说,则是每一种取值放入一个bin,且当取值的个数大于max bin数时,会忽略那些很少出现的category值。
在histogram算法上一个trick是histogram 做差加速。一个容易观察到的现象:一个叶子的直方图可以由它的父亲节点的直方图与它兄弟的直方图做差得到。利用这个方法,Lightgbm 可以在构造一个叶子(含有较少数据)的直方图后,可以用非常微小的代价得到它兄弟叶子(含有较多数据)的直方图。
优势:
1.Pre-sorted 算法需要的内存约是训练数据的两倍,它需要用32位浮点(4Bytes)来保存 feature value,并且对每一列特征,都需要一个额外的排好序的索引,这也需要32位(4Bytes)的存储空间,一共是是(2 * data * features* 4Bytes)。而对于 histogram 算法,则只需要(#data * #features * 1Bytes)的内存消耗,仅为 pre-sorted算法的1/8。因为 histogram 算法仅需要存储 feature bin value (离散化后的数值),不需要原始的 feature value,也不用排序,而 bin value 用 1Bytes(256 bins) 的大小一般也就足够了。
2.大幅减少了计算分割点增益的次数。对于每一个特征,pre-sorted 需要对每一个不同特征值都计算一次分割增益,代价是O(#feature*#distinct_values_of_the_feature);而 histogram 只需要计算#bins次,代价是(#feature*#bins)。数据越多,速度差距越明显。
3.还有一个很重要的点是cache-miss。cache-miss对速度的影响特别大。预排序中有2个操作频繁的地方会造成cache miss,一是对梯度的访问,在计算gain的时候需要利用梯度,不同特征访问梯度的顺序都是不一样的,且是随机的,因此这部分会造成严重的cache-miss。二是对于索引表的访问,预排序使用了一个行号到叶子节点号的索引表(row_idx_to_tree_node_idx ),来防止数据切分时对所有的数据进行切分,即只对该叶子节点上的样本切分。在与level-wise进行结合的时候, 每一个叶子节点都要切分数据,这也是随机的访问。这样会带来严重的系统性能下降。而直方图算法则是天然的cache friendly。在直方图算法的第3个for循环的时候,就已经统计好了每个bin的梯度,因此,在计算gain的时候,只需要对bin进行访问,造成的cache-miss问题会小很多。
劣势:
histogram 算法不能找到很精确的分割点,训练误差没有 pre-sorted 好。但从实验结果来看, histogram 算法在测试集的误差和 pre-sorted 算法差异并不是很大,甚至有时候效果更好。实际上可能决策树对于分割点的精确程度并不太敏感,而且较“粗”的分割点也自带正则化的效果,再加上boosting算法本身就是弱分类器的集成
参考:https://blog.csdn.net/anshuai_aw1/article/details/83040541
二、 带深度限制的 Leaf-wise 的叶子生长策略
Level-wise 过一次数据可以同时分裂同一层的叶子,容易进行多线程优化,也好控制模型复杂度,不容易过拟合。实际上 Level-wise 是一种低效的算法,因为它不加区分的对待同一层的叶子,带来了很多没必要的开销,因为实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。Leaf-wise 则是一种更为高效的策略,每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。因此同 Level-wise 相比,在分裂次数相同的情况下,Leaf-wise 可以降低更多的误差,得到更好的精度。Leaf-wise 的缺点是可能会长出比较深的决策树,产生过拟合。因此 LightGBM 在 Leaf-wise 之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合。
三、直接支持类别特征
A. 离散特征建立直方图的过程:
统计该特征下每一种离散值出现的次数,并从高到低排序,并过滤掉出现次数较少的特征值, 然后为每一个特征值,建立一个bin容器, 对于在bin容器内出现次数较少的特征值直接过滤掉,不建立bin容器。
B. 计算分裂阈值的过程:
B.1
先看该特征下划分出的bin容器的个数,如果bin容器的数量小于4,直接使用one vs other方式, 逐个扫描每一个bin容器,找出最佳分裂点;
B.2
对于bin容器较多的情况, 先进行过滤,只让子集合较大的bin容器参加划分阈值计算, 对每一个符合条件的bin容器进行公式计算(公式如下: 该bin容器下所有样本的一阶梯度之和 / 该bin容器下所有样本的二阶梯度之和 + 正则项(参数cat_smooth),这里为什么不是label的均值呢?其实上例中只是为了便于理解,只针对了学习一棵树且是回归问题的情况, 这时候一阶导数是Y, 二阶导数是1),得到一个值,根据该值对bin容器从小到大进行排序,然后分从左到右、从右到左进行搜索,得到最优分裂阈值。但是有一点,没有搜索所有的bin容器,而是设定了一个搜索bin容器数量的上限值,程序中设定是32,即参数max_num_cat。
LightGBM中对离散特征实行的是many vs many 策略,这32个bin中最优划分的阈值的左边或者右边所有的bin容器就是一个many集合,而其他的bin容器就是另一个many集合。
B.3
对于连续特征,划分阈值只有一个,对于离散值可能会有多个划分阈值,每一个划分阈值对应着一个bin容器编号,当使用离散特征进行分裂时,只要数据样本对应的bin容器编号在这些阈值对应的bin集合之中,这条数据就加入分裂后的左子树,否则加入分裂后的右子树。
https://blog.csdn.net/anshuai_aw1/article/details/83275299
四丶LightGBM并行优化
- Feature Parallel
特征并行算法目的是在决策树生成过程中的每次迭代,高效地找到最优特征分裂点。特征并行的主要思想是在不同机器在不同的特征集合上分别寻找最优的分割点,然后在机器间同步最优的分割点。
传统的特征并行算法
根据不同的特征子集,将数据集进行垂直切分。(不同机器worker有不同的特征子集)
每个worker寻找局部的最优分裂特征以及分裂点。
不同worker之间进行网络传输,交换最优分裂信息,最终得到最优的分裂信息。
具有最优分裂特征的worker,局部进行分裂,并将分裂结果广播到其他worker。
其他worker根据接收到的数据进行切分数据。
该方法不能有效地加速特征选择的效率,当数据量#data很大时,该并行方法不能加快效率。并且,最优的分裂结果需要在worker之间进行传输,需要消耗很多的传输资源以及传输时间。
LightGBM的特征并行算法
LightGBM并没有垂直的切分数据集,而是每个worker都有全量的训练数据,因此最优的特征分裂结果不需要传输到其他worker中,只需要将最优特征以及分裂点告诉其他worker,worker随后本地自己进行处理。处理过程如下:
每个worker在基于局部的特征集合找到最优分裂特征。
workder间传输最优分裂信息,并得到全局最优分裂信息。
每个worker基于全局最优分裂信息,在本地进行数据分裂,生成决策树。
然而,当数据量很大时,特征并行算法还是受限于特征分裂效率。因此,当数据量大时,推荐使用数据并行算法。
水平切分数据集。
每个worker基于数据集构建局部特征直方图(Histogram)。
归并所有局部的特征直方图,得到全局直方图。
找到最优分裂信息,进行数据分裂。
缺点:网络传输代价比较大,如果使用point-to-point的传输算法,每个worker的传输代价为O(#machine * #feature * #bin). 如果使用All Reduce并行算子,传输代价为O(2* #feature * #bin).
LightGBM的数据并行算法
LightGBM算法使用Reduce Scatter并行算子归并来自不同worker的不同特征子集的直方图,然后在局部归并的直方图中找到最优局部分裂信息,最终同步找到最优的分裂信息。
除此之外,LightGBM使用直方图减法加快训练速度。我们只需要对其中一个子节点进行数据传输,另一个子节点可以通过histogram subtraction得到。
LightGBM可以将传输代价降低为O(0.5 * #feature * #bin)。
基于投票的并行算法
基于投票机制的并行算法,是在每个worker中选出top k个分裂特征,然后将每个worker选出的k个特征进行汇总,并选出全局分裂特征,进行数据分裂。有理论证明,这种voting parallel以很大的概率选出实际最优的特征,因此不用担心topk的问题。
参考:https://blog.csdn.net/ictcxq/article/details/78736442
并行算子:数据并行方式的训练过程中,每个计算节点只对自己存放的数据进行计算得到局部结果,然后再对局部结果进行全局归约。在并行计算中,数值归约是非常重要且使用频率非常高的一种操作。数值归约算法实现方式的好坏直接影响整个计算过程的速度。常用的一些归约算子包括:Allreduce、Reduce、Allgather、Broadcast、ReduceScatter等。
https://blog.csdn.net/qrqpjxq/article/details/78625574
参考:https://blog.csdn.net/weixin_39807102/article/details/81912566#1-lightgbm%E5%8E%9F%E7%90%86
bagging和boosting
Bagging组合算法是bootstrap aggregating的缩写。我们可以让上述决策树学习算法训练多轮,每轮的训练集由从初始的训练集中有放回地随机抽取n个训练样本组成,某个初始训练样本在某轮训练集中可以出现多次或根本不出现,训练之后就可以得到一个决策树群h_1,……h_n ,也类似于一个森林。最终的决策树H对分类问题采用投票方式,对回归问题采用简单平均方法对新示例进行判别
Boosting组合算法
此类算法中其中应用最广的是AdaBoost(Adaptive Boosting)。在此算法中,初始化时以等权重有放回抽样方式进行训练,接下来每次训练后要特别关注前一次训练失败的训练样本,并赋以较大的权重进行抽样,从而得到一个预测函数序列h_1,⋯, h_m , 其中h_i也有一定的权重,预测效果好的预测函数权重较大,反之较小。最终的预测函数H对分类问题采用有权重的投票方式,所以Boosting更像是一个人学习的过程,刚开始学习时会做一些习题,常常连一些简单的题目都会弄错,但经过对这些题目的针对性练习之后,解题能力自然会有所上升,就会去做更复杂的题目;等到他完成足够多题目后,不管是难题还是简单题都可以解决掉了。
区别
1)样本选择上:
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
2)样例权重:
Bagging:使用均匀取样,每个样例的权重相等
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
3)预测函数:
Bagging:所有预测函数的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
4)并行计算:
Bagging:各个预测函数可以并行生成
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
5)这个很重要面试被问到了
为什么说bagging是减少variance,而boosting是减少bias?

bagging中的模型是强模型,偏差低,方差高。目标是降低方差。在bagging中,每个模型的bias和variance近似相同,但是互相相关性不太高,因此一般不能降低Bias,而一定程度上能降低variance。典型的bagging是random forest。
boosting中每个模型是弱模型,偏差高,方差低。目标是通过平均降低偏差。boosting的基本思想就是用贪心法最小化损失函数,显然能降低偏差,但是通常模型的相关性很强,因此不能显著降低variance。典型的Boosting是adaboost,另外一个常用的并行Boosting算法是GBDT(gradient boosting decision tree)