原始题目:RetinaFace: Single-stage Dense Face Localisation in the Wild
中文翻译:自然场景下的单阶段密集人脸定位
发表时间:2019年5月2日
平台:CVPR
来源:帝国理工学院(Imperial College London)
文章链接:https://arxiv.org/abs/1905.00641
开源代码:
GitHub - biubug6/Pytorch_Retinaface: Retinaface get 80.99% in widerface hard val using mobilenet0.25.
https://github.com/serengil/retinaface
注意该复现并没有使用 3D 密集回归分支。
摘要
自然场景下精确和高效的人脸定位仍是一个挑战。该文提出了一种 robust 的single-stage人脸检测器:RetinaFace,它利用联合的额外监督( joint extra-supervised)(贡献1)和自监督多任务学习( self-supervised multi-task learning)(贡献2),在不同尺度的人脸上进行像素化的人脸定位。
五个方面贡献:
- 在WIDER FACE 数据集上手工标注了五个人脸 landmarks,并观察到在这种额外的监督信号的帮助下,困难( hard)人脸检测有了显著的改善。
- 添加了一个自监督网格解码器分支( self supervised mesh decoder branch),用于预测一个像素级( pixel-wise)的3D形状人脸信息(3D shape face information)。该分支与已存在的监督分支并行。
- 在WIDER FACE 困难测试集( WIDER FACE hard test set)上,RetinaFace 超过最先进的算法的平均精度( average precision (AP)) 1.1%,达到了AP = 91.4%。
- 在IJB-C测试集( IJB-C test set)上,RetinaFace使当前最好的ArcFace在人脸认证(face verification)上进一步提升(TAR=89.59 FAR=1e-6)。
- 通过采用轻量级 backbone 网络,RetinaFace可以在单核CPU下实时运行VGA分辨率( VGA-resolution)的图像。
5. 结论
该文研究了图像中
任意比例的人脸同时密集定位和对齐这一具有挑战性的问题。据我们所知,我们提出了
第一个 one-stage解决方案(RetinaFace)。并在当前最具挑战性的人脸检测基准测试中超过了 最先进的 方法。此外,当
RetinaFace与最新的人脸识别实践相结合时,它明显地提高了准确性。这些数据和模型已经公开提供,以促进对这一主题的进一步研究。
1.引言
自动人脸定位是人脸图像分析如人脸属性(表情,年龄,ID识别)的先决步骤。人脸定位狭义上可能指的是传统的人脸检测,它旨在于在没有任何尺度和位置先验下估计人脸检测框。然而,本文指的是人脸定位的广义定义,包括人脸检测( face detection)、人脸对齐(face alignment)、像素化人脸解析( pixelwise face parsing )和3D密集对应回归(3D dense correspondence regression)。这种密集的人脸定位为所有不同的尺度提供了精确的人脸位置信息。
受通用目标检测方法的启发,这些检测包含了深度学习的所有最新进展,人脸检测近年来取得了显著进展。与通用目标检测不同,人脸检测具有较小的比例变化(从1:1到1:1.5),但尺度变化更大(从几个像素到上千像素)。最新的最先进方法集中于single stage设计,该设计在特征金字塔上密集采样人脸位置和尺度,与两阶段方法相比,展示了有前景的性能和更快的速度。依据这种路线,我们通过利用来自强监督和自监督信号( strongly supervised and self-supervised signals)的多任务损失,提升了 single-stage 人脸检测框架,提出了当前最好的密集人脸定位方法。思想如图1:

图1。提出的单阶段像素级( single-stage pixel-wise)人脸定位方法,采用额外监督(extra-supervised)和自监督多任务学习,与现存的box分类和回归分支并行。每个positive anchor 输出是:(1) 1个人脸得分;(2) 1个人脸框;(3) 5个人脸 landmarks;(4)投影在图像平面上的密集3D人脸顶点( vertices)。
通常,人脸检测训练过程包含分类和box回归损失。 Chen et al. [6] 基于对齐的人脸形状 为人脸分类提供了更好的特征的观察,提出将 face detection 和 alignment结合在一个联合级联框架中。受到[6] (Joint cascade face detection and alignment. ) 的启发,MTCNN和STN同时检测人脸和5个人脸标志。由于训练数据的限制,JDA、MTCNN和STN 还没有验证 tiny(小的)人脸检测是否可以受益于对5个人脸 landmarks 的额外监督。在本文中,我们旨在回答的问题之一是,我们是否可以通过使用由5个人脸 landmarks 构建的额外监督信号,来推动目前在WIDER FACE hard test set[60]上的最佳表现(90.3%[67])。
在Mask R-CNN中,通过在已有的分支(边界框识别和回归 bounding box recognition and regression)上, 并行增加 一个分支用于预测目标mask,检测性能得到了显著提高。这证明了密集的像素级的标注也有助于改进检测。不幸的是,对于WIDER FACE具有挑战性的人脸,不可能进行密集的人脸标注(以更多 landmarks 或语义分割的形式的任一种)。由于有监督信号不易获得,问题在于我们是否可以应用无监督方法来进一步改善人脸。
FAN提出了一种 anchor级 的注意力 (attention)图来改善遮挡人脸的检测。然而,所提出的注意力图非常粗糙,且不包含语义信息。不过最近,自监督的3D 形变模型( 3D morphable models)已经实现了不错的自然环境下3D人脸建模。特别是网格解码器(Mesh Decoder)通过 联合形状和纹理( joint shape and texture)利用图卷积( graph convolutions)来实现实时速度。然而,将网格解码器应用到单阶段检测器(single-stage detector)中的挑战有: (1)相机参数难以准确估计(2) 预测 联合潜在形状和纹理的表示 来自一个单个特征向量(特征金字塔上的1×1 Conv),而不是ROI池化( RoI pooled)特征,这会有特征转移( feature shift)的风险。在本文中,我们使用了一个通过自监督学习的网格解码器分支,用于与现有的监督分支并行地预测像素级的3D人脸形状。总的来说我们的主要贡献如下:
- 在 single-stage 设计的基础上,提出了一种名为RetinaFace的像素级的人脸定位方法,该方法采用多任务学习策略来同时预测人脸评分、人脸框、5个人脸关键点以及每个人脸像素的3D位置和对应关系( correspondence)。
- 在WIDER FACE hard子集上,RetinaFace比当前最先进的 two-stage方法的AP 高出了1.1%(AP=91.4%)
- 在IJB-C数据集上,RetinaFace有助于提高ArcFace的验证精度(当FAR=1e-6时,TAR =89.59% )。这表明更好的人脸定位可以显著提高人脸识别能力。
- 通过采用轻量级 backbone网络,RetinaFace可以在单CPU核心上实时运行VGA分辨率的图像。
- 已经发布额外的注释和代码,以促进未来的研究。
2.相关工作
图像金字塔vs特征金字塔:
滑动窗口范式可以追溯到几十年前(即将分类器应用在一个密集的图像网格中)。Viola-Jones的里程碑式工作探索了级联链( cascade chain),可以实时高效地从图像金字塔中剔除虚假的人脸区域,这种尺度不变( scale-invariant)的人脸检测框架开始被广泛采用。虽然图像金字塔上的滑动窗口是主要的检测范式,但随着特征金字塔的出现,多尺度特征图上的 sliding-anchor 迅速占据了人脸检测的主导地位。
两阶段 vs 单阶段:
目前的人脸检测方法继承了通用目标检测方法的一些成果,可以分为两类:两阶段方法(如 Faster R-CNN)和单阶段方法(如SSD 和 RetinaNet)。两阶段方法采用了“建议和改进(proposal and refinement)”机制,具有很高的定位精度。相比之下,单阶段方法密集采样人脸位置和尺度,导致训练过程中正样本和负样本极不平衡。为了处理这种不平衡,广泛采用了采样和re-weighting(Focal Loss)的方法。与两阶段方法相比,单阶段方法效率更高,召回率更高,但存在假阳性率( false positive rate)更高、定位精度下降的风险。
上下文建模:
为了增强模型捕捉tiny(小)人脸时的上下文推理能力,SSH 和 PyramidBox在特征金字塔上应用上下文模块来扩大 欧几里得网格(Euclidean grids)中获取的感受野。为了增强CNNs的非刚性变换建模能力,可变形卷积网络( deformable convolution network (DCN)采用了一种新的可变形层来建模几何变换。 WIDER Face Challenge 2018 的冠军解决方案表明,刚性(扩展)和非刚性(变形) 上下文建模是互补和正交的( complementary and orthogonal),可以提高人脸检测的性能。
多任务学习:
人脸检测与对齐的结合被广泛应用,因为对齐后的人脸形状为人脸分类提供了更好的特征。在Mask R-CNN中,通过在已有的分支中并行添加一个预测目标 Mask 的分支,显著提高了检测性能。Densepose采用了Mask-RCNN的架构,获得每个选定区域内的密集( dense)部分标签和坐标。不过,密集回归分支是通过监督学习来训练的。此外,密集分支是一个小的FCN应用于每个RoI,以预测 像素到像素( pixel-to-pixel) 的密集映射。
3.RetinaFace

图2: 所提出的单阶段密集人脸定位方法的概述。 RetinaFace 是基于具有独立上下文模块的特征金字塔设计的。 在上下文模块之后,我们计算每个 anchor 的多任务损失。
3.1多任务损失
对于任意训练的 anchor i , 最小化多任务损失函数:
 (1)
(1)
(1) 人脸分类损失  ,其中
,其中  为 anchor i 为一个 人脸的预测概率,并且
为 anchor i 为一个 人脸的预测概率,并且  对于positive anchor 是1,对于 negative anchor 是0。 分类损失
对于positive anchor 是1,对于 negative anchor 是0。 分类损失 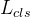 是二分类(脸/非脸)的 softmax loss。
是二分类(脸/非脸)的 softmax loss。
(2)人脸边框回归损失  , 其中
, 其中  表示预测框的坐标,
表示预测框的坐标,  表示 与positive anchor 关联的真实框的坐标。按照 Fast r-cnn 标准化( normalise)box 回归目标(即中心位置、宽度和高度) , 并且使用
表示 与positive anchor 关联的真实框的坐标。按照 Fast r-cnn 标准化( normalise)box 回归目标(即中心位置、宽度和高度) , 并且使用  ,这里 R是 Fast r-cnn 中 定义的鲁棒损失函数:smooth-L1 。
,这里 R是 Fast r-cnn 中 定义的鲁棒损失函数:smooth-L1 。
(3)人脸关键点回归损失  , 其中
, 其中  表示预测的5个人脸关键点,
表示预测的5个人脸关键点,  表示 与 positive anchor 关联的真实值。与 box centre 回归相似,5个人脸关键点回归也采用基于anchor 中心的目标归一化方法。
表示 与 positive anchor 关联的真实值。与 box centre 回归相似,5个人脸关键点回归也采用基于anchor 中心的目标归一化方法。
(4) 密集回归损失 (参考公式3)。
(参考公式3)。
损失平衡参数  设为 0.25、0.1和 0.01,意味着我们增加了来自监督信号 更好的边框定位和关键点定位的重要性。
设为 0.25、0.1和 0.01,意味着我们增加了来自监督信号 更好的边框定位和关键点定位的重要性。
3.2. Dense Regression Branch
Mesh Decoder. 网格解码器
我们直接使用 [70, 40] 中的网格解码器(网格卷积和网格上采样),这是一种基于快速局部谱滤波 [10] 的图卷积方法。 为了实现进一步的加速,我们还使用类似于[70]中的方法的联合形状和纹理解码器,与仅解码形状的[40]相反。
下面我们将简要解释图卷积的概念,并概述为什么它们可以用于快速解码。 如图 3(a) 所示,2D 卷积运算是欧几里得网格感受野内的“邻近加权求和”。 类似地,图卷积也采用了与图 3(b) 所示相同的概念。 但是,通过计算连接两个顶点的最小边数,在图上计算相邻距离。 我们按照 [70] 定义了一个彩色人脸网格 G = (V, E),其中  是一组包含 联合 形状和纹理信息的人脸顶点,
是一组包含 联合 形状和纹理信息的人脸顶点, 是 一个稀疏邻接矩阵 来编码顶点之间的连接状态。 拉普拉斯图定义为
是 一个稀疏邻接矩阵 来编码顶点之间的连接状态。 拉普拉斯图定义为  其中
其中  是
是 的对角矩阵 。
的对角矩阵 。

图3: (a) 2D Convolution 是欧几里得网格感受野内的邻近加权求和。每个卷积层都有  个参数。
个参数。
(b) 图卷积也是采用邻近加权求和 的形式,但在图上通过 计数 连接两个顶点的最小边数来计算邻近距离。每个卷积层都有  参数,切比雪夫系数
参数,切比雪夫系数  以 K 阶截断。
以 K 阶截断。
在 [10, 40, 70] 之后,具有 kernel gθ 的图卷积可以表示为以 K 阶截断的递归 Chebyshev 多项式:

其中  是切比雪夫系数的向量,
是切比雪夫系数的向量, 是在 scaled 拉普拉斯
是在 scaled 拉普拉斯 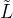 处计算的 k 阶切比雪夫多项式。 表示
处计算的 k 阶切比雪夫多项式。 表示  ,我们可以循环计算 ̄
,我们可以循环计算 ̄ ,其中 ̄
,其中 ̄ 和
和 。 整个滤波操作非常高效,包括 K 次稀疏矩阵向量(matrix-vector)乘法和一个密集矩阵向量乘法
。 整个滤波操作非常高效,包括 K 次稀疏矩阵向量(matrix-vector)乘法和一个密集矩阵向量乘法  。
。
Differentiable Renderer 可微渲染器
在我们预测形状和纹理参数  之后,我们采用高效的可微 3D 网格渲染器 [14] 将彩色网格
之后,我们采用高效的可微 3D 网格渲染器 [14] 将彩色网格  投影到具有相机参数
投影到具有相机参数  (即相机位置、相机姿态和焦距)光照参数
(即相机位置、相机姿态和焦距)光照参数 (即点光源的位置 ,颜色值和环境照明的颜色) 的 2D 图像平面上。
(即点光源的位置 ,颜色值和环境照明的颜色) 的 2D 图像平面上。
Dense Regression Loss. 密集回归损失
一旦我们得到渲染的 2D 人脸  ,我们使用以下函数比较渲染的人脸和原始 2D 人脸间的像素级差异:
,我们使用以下函数比较渲染的人脸和原始 2D 人脸间的像素级差异:

其中 W 和 H 分别是 anchor crop  的宽度和高度
的宽度和高度
4. 实验
4.1. Dataset
WIDER FACE 数据集 [60] 由 32,203 个图像和 393,703 个人脸边界框组成,在尺度、姿态、表情、遮挡和照明方面具有高度可变性。 通过从 61 个场景类别中随机采样,WIDER FACE 数据集分为训练 (40%)、验证 (10%) 和测试 (50%) 子集。 基于 EdgeBox [76] 的检测率,三个难度级别(即 Easy、Medium 和 Hard)通过逐步合并hard样本来定义。
Extra Annotations 额外标注
如图 4 和表1所示。 我们定义了人脸图像质量的5个级别(根据标注人脸关键点的难易程度),在人脸上标注 5个人脸关键点(即眼睛中心、鼻尖和嘴角)可以在WIDER FACE训练和验证集进行标注。总的来说,我们在训练集上标注了 84.6k 人脸,在验证集上标注了 18.5k 人脸。

图 4. 我们在可以从 WIDER FACE 训练和验证集中标注的人脸上添加5个人脸关键点的额外标注(我们称它们为“可标注的”)。

表 1. 五个级别的人脸图像质量。 在无可争议的类别中,人类可以不费吹灰之力地定位地标。 在可标注的类别中找到一个大概的位置需要一些努力。
4.2. Implementation details
Feature Pyramid.
RetinaFace 使用从 P2 到 P6 的特征金字塔级别,其中 P2 到 P5 是使用 [28、29] 中的自上而下( top-down)和横向连接(lateral connections)从相应的 ResNet 残差阶段(C2 到 C5)的输出计算出来的。 P6 是通过 C5 上 stride=2 的 3×3 卷积计算的。 C1 到 C5 是在 ImageNet-11k 数据集上预训练的 ResNet-152 [21] 分类网络,而 P6 是使用“Xavier”方法 [17] 随机初始化的。
Context Module.
受 SSH [36] 和 Pyramid-Box [49] 的启发,我们还在5个特征金字塔级别上应用了独立的上下文模块,以增加感受野并增强刚性上下文建模能力。 借鉴 WIDER Face Challenge 2018 [33] 冠军的经验,我们还将横向连接和上下文模块中的所有 3×3 卷积层替换为可变形卷积网络 (DCN) [9, 74],进一步增强了非 - 刚性上下文建模能力。
Loss Head.
对于 negative anchors,只应用分类损失。 对于 positive anchors,计算提出的多任务损失。 我们在不同的特征图  使用一个共享loss head(1 × 1 conv)。 对于网格解码器,我们应用了预训练模型 [70],这是一个小的计算开销,可以进行高效的推理。
使用一个共享loss head(1 × 1 conv)。 对于网格解码器,我们应用了预训练模型 [70],这是一个小的计算开销,可以进行高效的推理。
Anchor Settings.
如表2所示。我们在从 P2 到 P6 的特征金字塔级别上使用尺度特定的锚点 [56]。 在这里,P2 旨在通过平铺小锚点来捕获小人脸,但代价是更多的计算时间和更多误报的风险。 我们将比例步长设置为 21/3,纵横比设置为 1:1。 输入图像大小为 640 × 640,anchors 可以覆盖特征金字塔级别上从 16 × 16 到 406 × 406 的尺度。 总共有 102,300 个主播,其中 75% 的主播来自 P2。
Data Augmentation.
Training Details.
Testing Details.