Probabilistic Knowledge Transfer for Deep Representation Learning
写在前面
建议直接看代码,不要过多浪费时间看论文
Abstract
1.蒸馏的知识:学习表示和label的互信息量 (mutual information between learned representation and a set of (possible unknown) labels )
2.从手工制作的特征提取器 到 跨模式的知识转移—> 跨模态知识转移 ( 将文本模态转换为从数据的视觉模态中提取的表示 )
1. Introduction
KT技术允许学习更准确和更一般化的学生网络,因为教师模型的输出隐式编码了有关训练样本及其分布之间相似性的更多信息(当使用训练集的硬二进制标签时,通常在训练期间忽略). 通过这种方式,KT充当正则化器,提高学生模型的性能[44]。
[44] Recurrent neural network training with dark knowledge transfer
后续存在问题:
a) 是否有可能将现有的KT技术用于表征学习任务,而不仅仅是分类任务?
b) 有没有办法让学生直接回归教师特征空间的几何图形而不是其输出?
c) 是否有可能从手工制作的功能中转移知识,例如。G将[29]和HoG[11]筛选成一个神经网络,然后根据手头的任务进行微调?这可以提供一种方法来利用大量可用的未标记训练样本,并在训练深度神经网络的过程中有效地使用它们,从而克服深度学习模型的一个显著缺点,即。成功培训他们所需的大量标记数据。
d)最后,为解决其他任务(如目标检测[36])而训练的网络知识能否有效地转移到其他较小的网络中?
本文提出的方法:

本文提出了一种概率知识转移方法。首先,教师的知识是使用信息论的度量,即互信息(MI)[10]来建模的。然后,对学生网络进行训练,以在提取的数据表示和一组(可能未知)标签之间保持相同数量的MI。
回归教师表示的概率分布而不是网络的实际输出的教师模型来执行KT
优点:
首先,它允许直接传输知识,即使网络的输出维度不匹配。
此外,即使当网络的输出维度匹配时,直接回归其输出也可能不是最有效的策略,因为教师网络预期不如学生网络强大。使用一种能够放松此约束的方法,例如通过允许旋转和稍微变换特征空间,有望更好地促进知识转移过程。
最后,请注意,还可以使用任何其他信息源来估计或增强概率分布,例如神经网络集成、手工制作的特征提取器、监督信息或甚至来自领域专家或用户的定性信息,增加建议方法的灵活性,并允许使用几个新的KT场景。
贡献
本文的主要贡献是提出了一种概率KT(PKT)技术,该技术通过匹配特征空间中数据的概率分布而不是其实际表示,克服了现有KT方法的一些局限性,如图1所示。据我们所知,所提出的技术是第一种能够
a)执行跨模式知识转移,
b)将知识从手工制作的特征提取程序转移到神经网络,
c)转移知识而不考虑手头的任务(例如,目标检测),
d)将领域知识纳入知识转移程序,提供对知识转移的新见解。
该方法的动机是匹配教师和学生模型的概率密度函数,在数据样本的特征表示和一组(可能未知)标签注释之间保持教师的二次互信息(QMI)[45]。
2 Related Work
摘取部分
求解流程**(FSP)矩阵在剩余网络的一些中间层之间传递知识。然而,与基于提示的传输方法相比,基于FSP的方法要求网络的中间层具有相同的大小和数量的滤波器**,这使得当两个网络之间的层的维数不同时,该方法不适合表示学习(学习较小的网络时,预计会出现这种情况).据我们所知,本文提出的方法是第一种概率KT表示学习方法,其工作原理是直接匹配教师和学生特征空间之间的数据概率分布。所提出的方法简单明了,不需要仔细的domain任何超参数的特定调谐,如softmax温度[17].
3 Probabilistic Knowledge Transfer
首先,本节简要介绍MI及其二次变量。然后,通过学习一个教师模型,该模型在提取的表示和一组标签之间保持与教师模型相同的互信息****量,从而导出所提出的方法。本节详细介绍了所提出的方法,并讨论了几种设计选择。

T={t1,t2,…,tN} : 表示用于在两个模型之间传递知识的N个对象的集合
x=f(t):表示教师模型的输出表示
y=g(t,W):表示学生模型的输出表示,其中W表示学生模型的参数。
在知识转移过程中**,函数g(·)的参数W被学习来“模仿”f(·)的行为**。
注意,只要T和g(·)的每个元素的f(·)的输出是已知的,并且g(·)是一个可微函数,那么函数f(·)和g(·)实际上是什么就没有约束。
教师和学生网络的分布分别使用两个连续随机变量X和Y建模,其中X描述从教师模型中提取的表示,Y描述从学生模型中提取的表示。
MI是随机变量之间相关性的度量[10]。设C为描述样本属性的离散随机变量(比如他们的标签)。对于从 x 绘制的每个特征向量 X,都有一个关联的标签 c。互信息测量观察特征向量后,类标签的不确定性降低了多少[45]。p(c)是观察类标签c的概率。同样,让p(x,c)表示相应联合分布的概率密度函数。
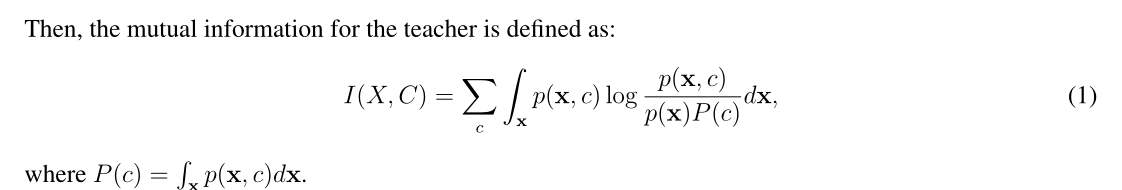
X 样本 C lebel 的互信息量 , x 特征向量 , c lebel ,p(c)是观察类标签c的概率。
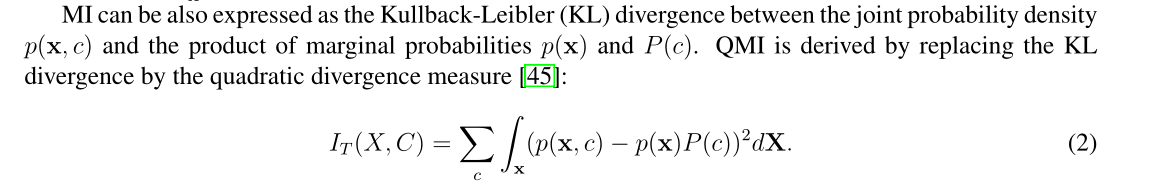
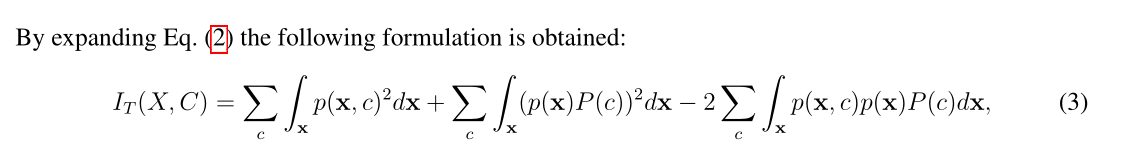
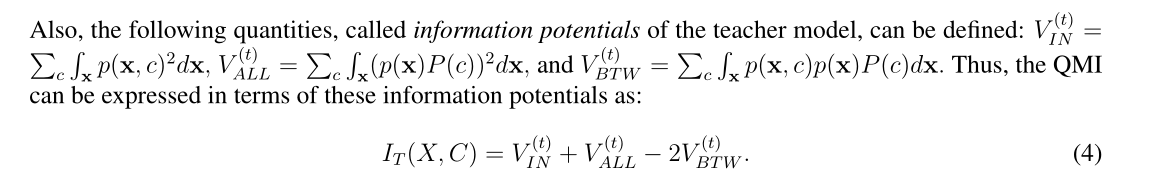
假设存在不同(和可能未知)的类,且每个类由Jp样本组成,则Cp类的类先验概率计算为P(cp)=Jp N,其中N是用于估计QMI的样本总数。

是一个对称核,宽度 σ 和符号xpj用于表示第p类的第j个样本。X的概率密度类似地估计为:

这些概率导出教师模型的更新信息势

VIN表示类内交互,
VALL表示所有样本之间的交互,
VBTW表示每个类与所有其他样本之间的交互。

教师和学生模型必须使用不同(并适当调整)的带宽σ和σ。然后,给定一组类标签C,通过保持两个随机变量X和Y与类标签i之间的MI量相同,知识可以从教师模型转移到学生模型。例如I(X,C)=I(Y,C)。如果二次MI要在模型之间传递,则这意味着两个模型之间的各自信息势必须相等。请注意,可能还有其他具有相同MI的配置,但是使用其中一个就足够了。
为了在两个模型之间具有相等的信息势,所使用的核函数所描述的每对数据样本之间的相似性必须相等,
即 K(xi− xj,2σ2t)= K(xi− xj,2σ2s)∀i、 j。与直接匹配这些核值不同,教师模型P(t)和学生模型P(s)的相应联合密度概率估计之间的差异可以最小化。联合密度概率函数定义为:

在高维数据分布建模的降维技术中,如t-SNE算法[30]。教师模型的条件概率分布定义为:



4 Experimental Evaluation


代码贴出来(并没有论文中那么那样看起来复杂)
from __future__ import print_function
import torch
import torch.nn as nn
class PKT(nn.Module):
"""Probabilistic Knowledge Transfer for deep representation learning
Code from author: https://github.com/passalis/probabilistic_kt"""
def __init__(self):
super(PKT, self).__init__()
def forward(self, f_s, f_t):
return self.cosine_similarity_loss(f_s, f_t)
@staticmethod
def cosine_similarity_loss(output_net, target_net, eps=0.0000001):
# Normalize each vector by its norm
output_net_norm = torch.sqrt(torch.sum(output_net ** 2, dim=1, keepdim=True))
output_net = output_net / (output_net_norm + eps)
# 归一化
output_net[output_net != output_net] = 0
target_net_norm = torch.sqrt(torch.sum(target_net ** 2, dim=1, keepdim=True))
target_net = target_net / (target_net_norm + eps)
target_net[target_net != target_net] = 0
# Calculate the cosine similarity
model_similarity = torch.mm(output_net, output_net.transpose(0, 1))
target_similarity = torch.mm(target_net, target_net.transpose(0, 1))
# Scale cosine similarity to 0..1
model_similarity = (model_similarity + 1.0) / 2.0
target_similarity = (target_similarity + 1.0) / 2.0
# Transform them into probabilities
model_similarity = model_similarity / torch.sum(model_similarity, dim=1, keepdim=True)
target_similarity = target_similarity / torch.sum(target_similarity, dim=1, keepdim=True)
# Calculate the KL-divergence
loss = torch.mean(target_similarity * torch.log((target_similarity + eps) / (model_similarity + eps)))
return loss
import torch
import numpy as np
# 这里看原来的代码就知道,这里的feature经过了fc 连接层了,源代码有两层全连接层,第二层预测10分类了,第一层在这之前
f_t = np.arange(0, 30000)
# print(a)
f_t = torch.from_numpy(f_t).view(3, 1000, 10).float()
# print(a)
f_s = torch.ones([3, 1000, 10]).float()
PKT = PKT()
loss = PKT.forward(f_t[0], f_s[0])