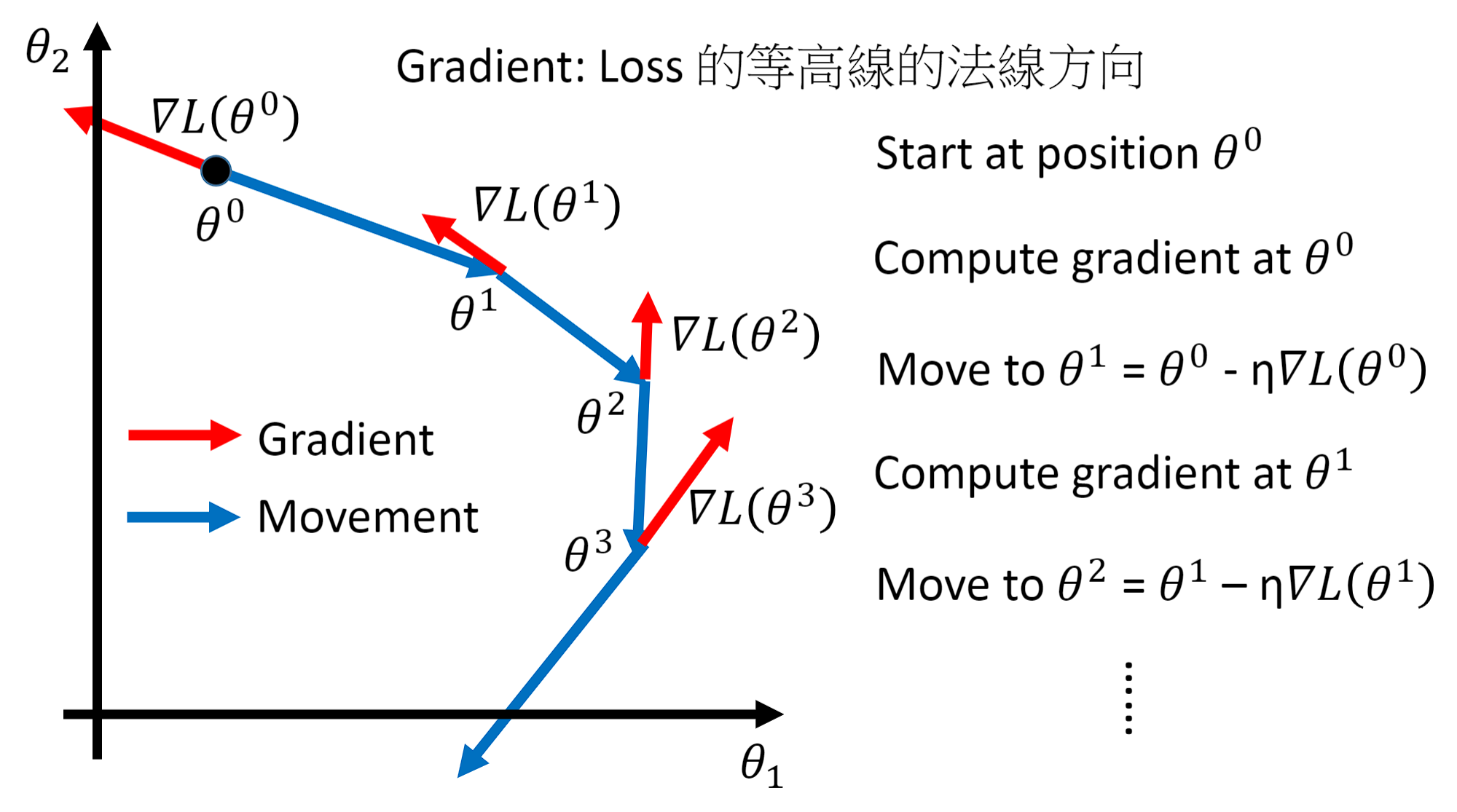
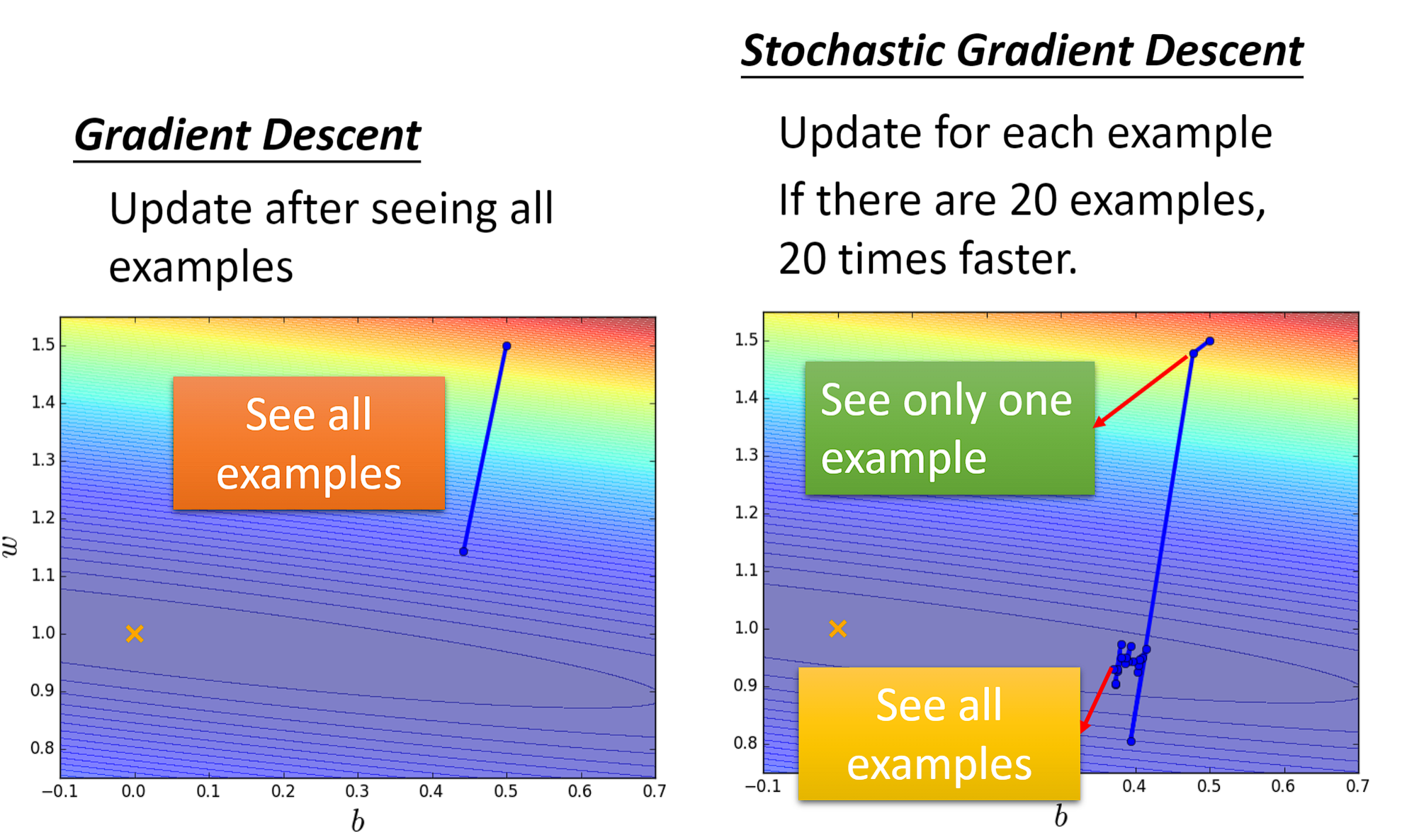
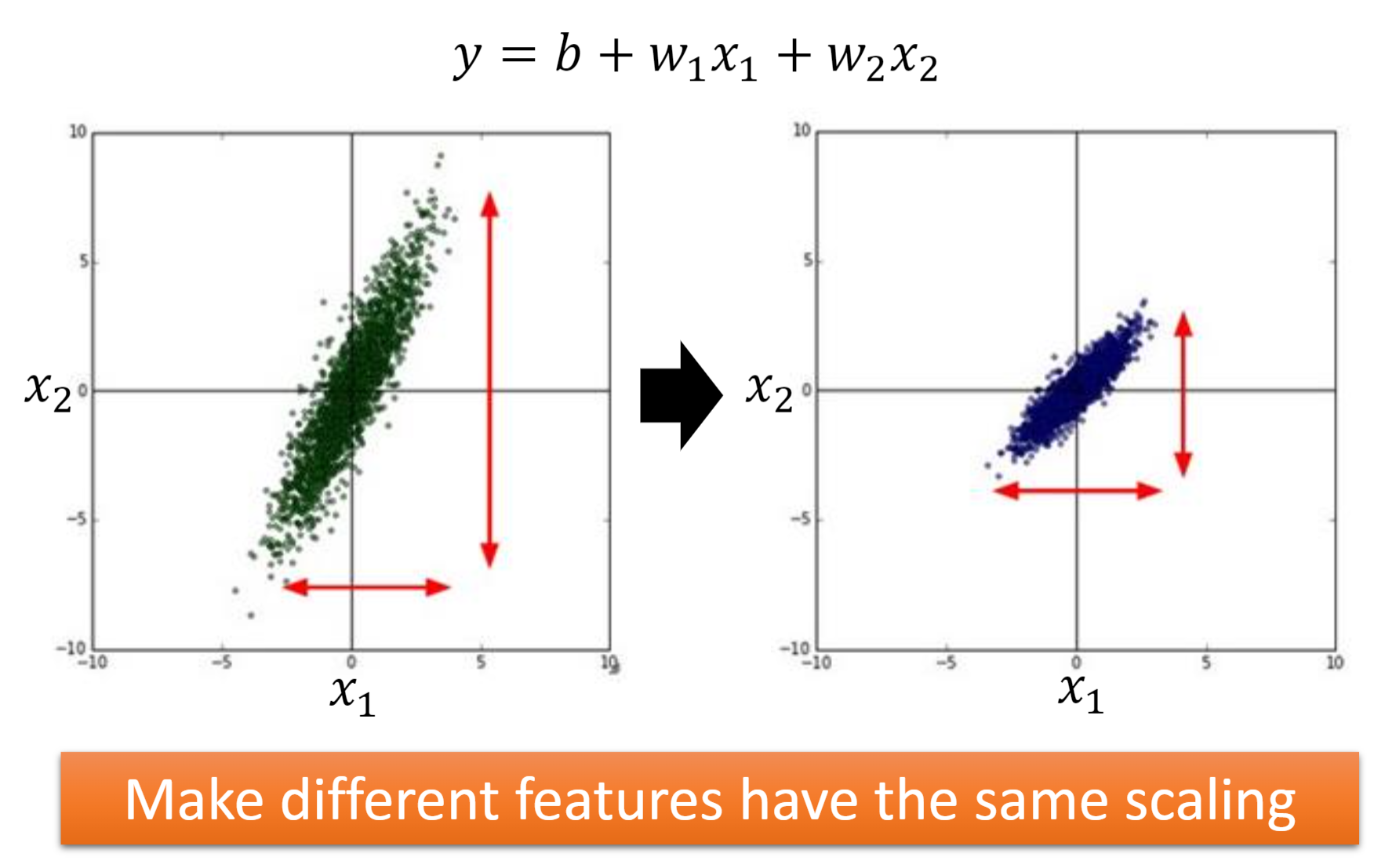
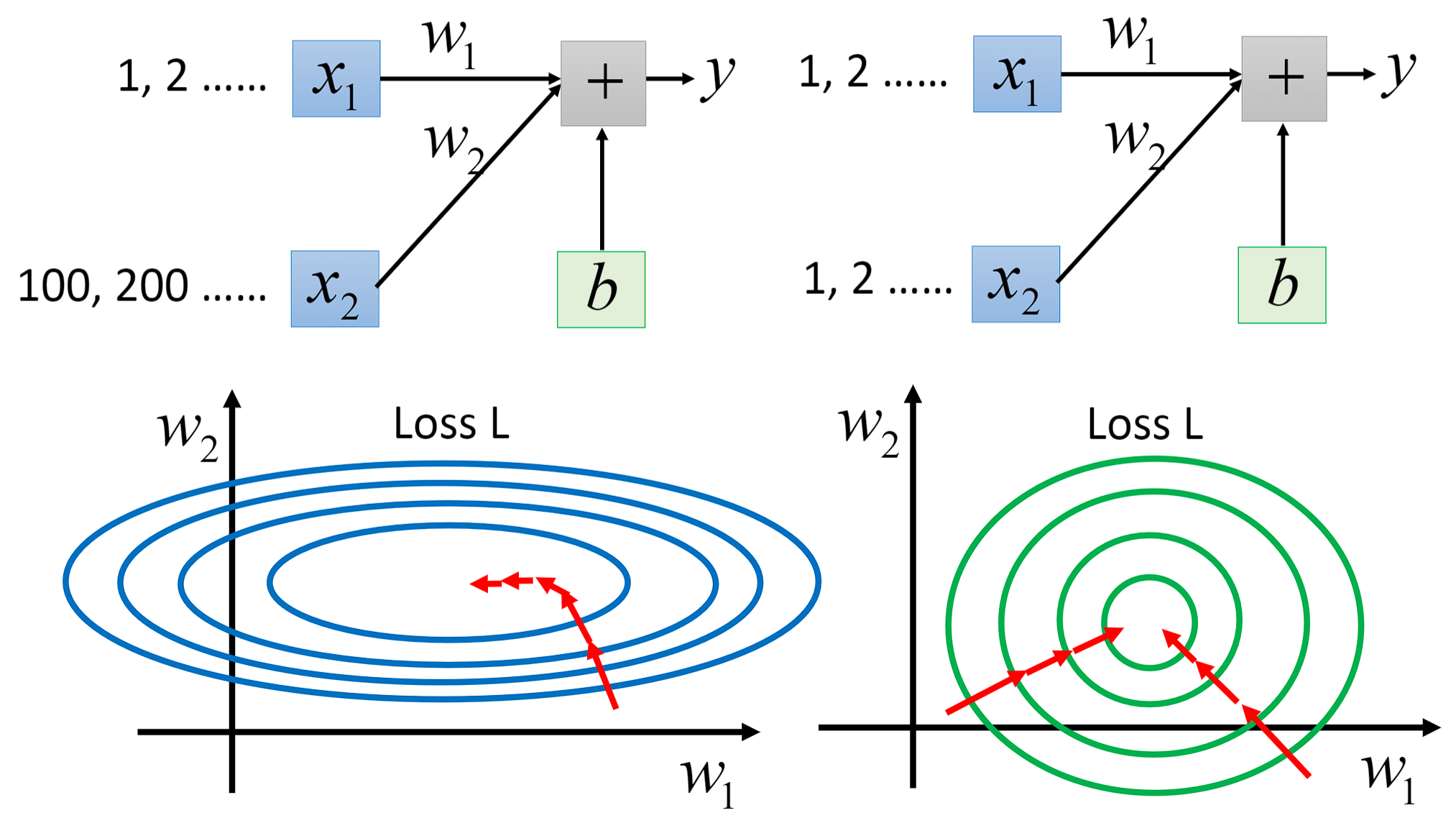
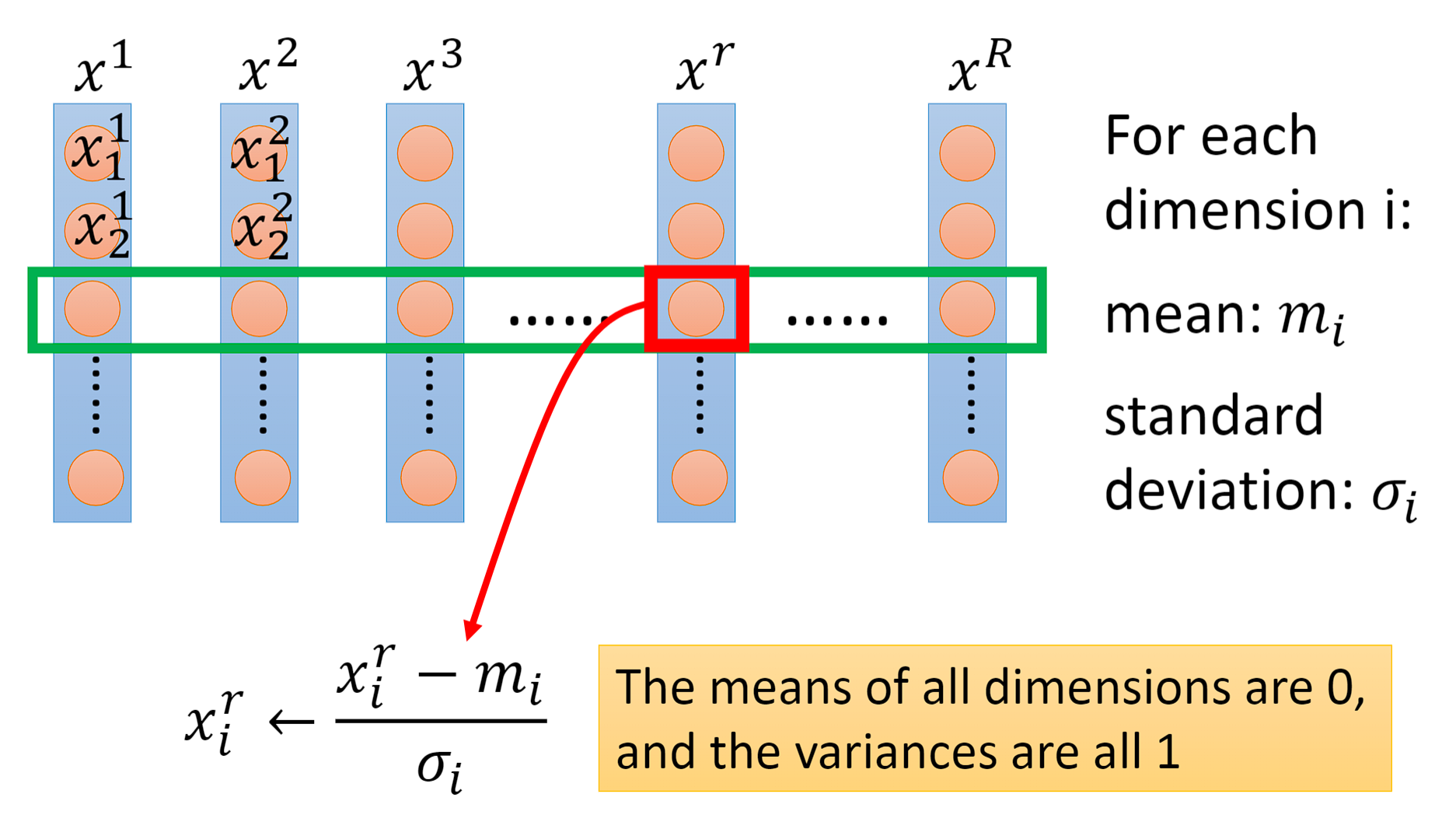
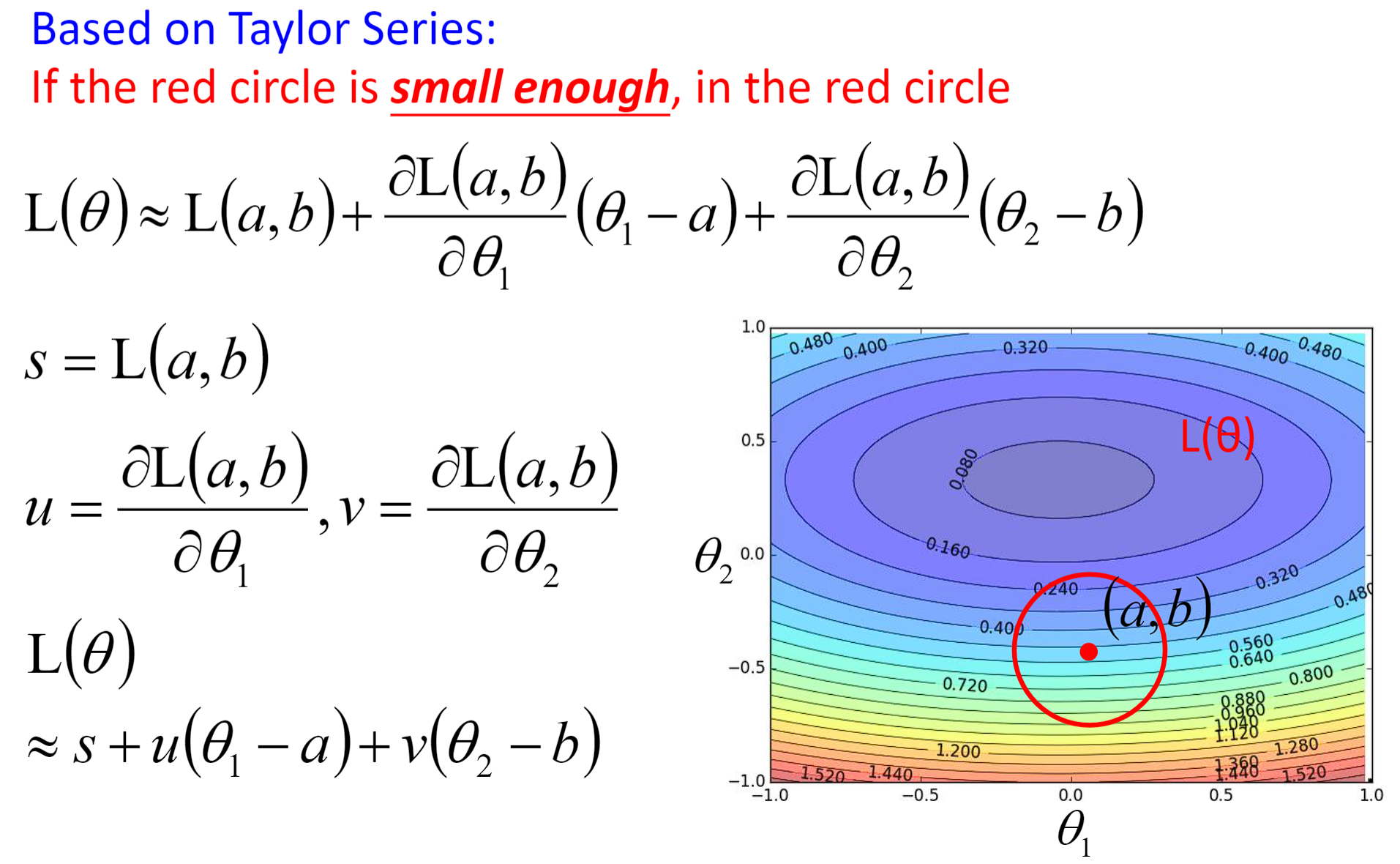
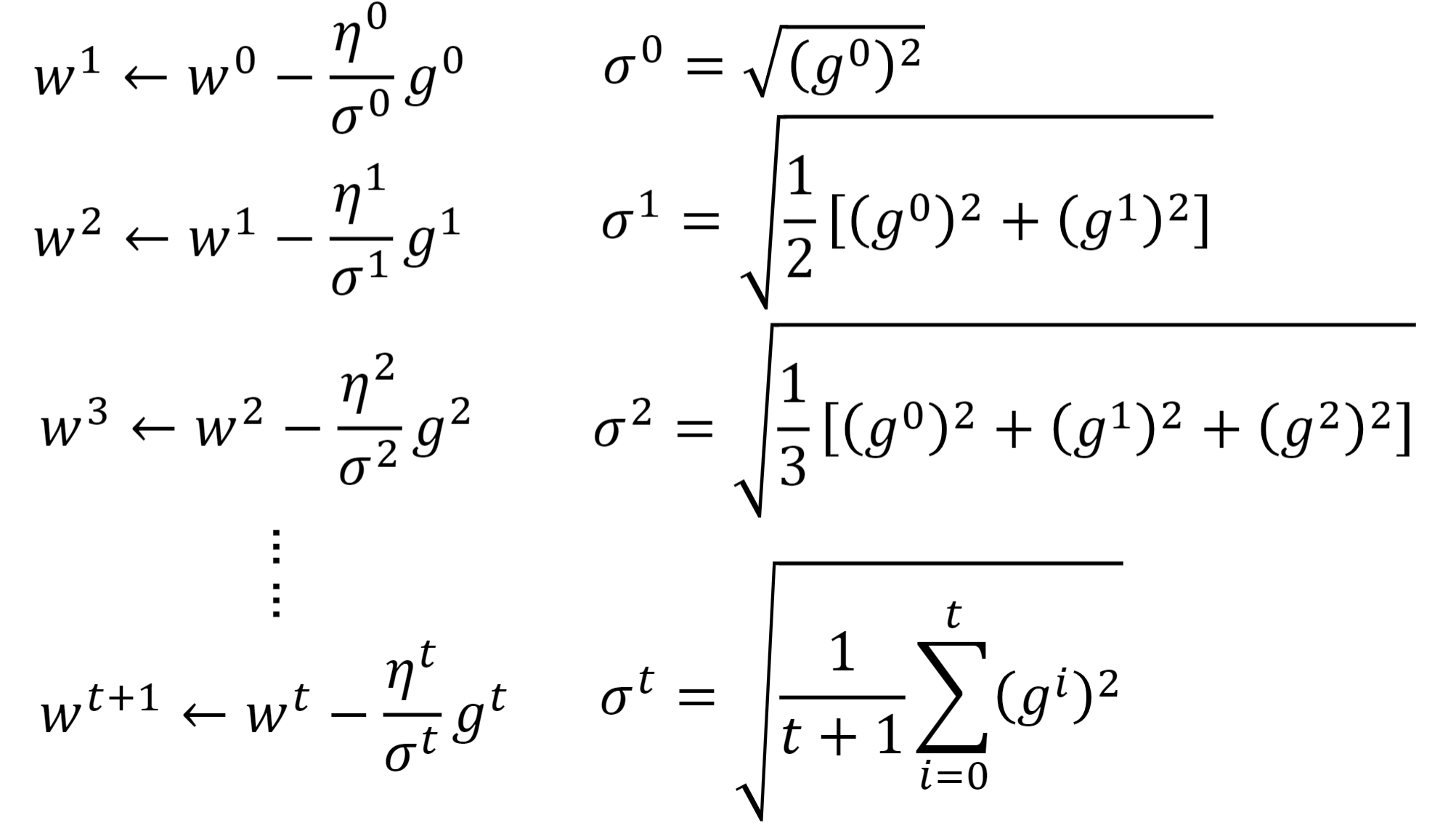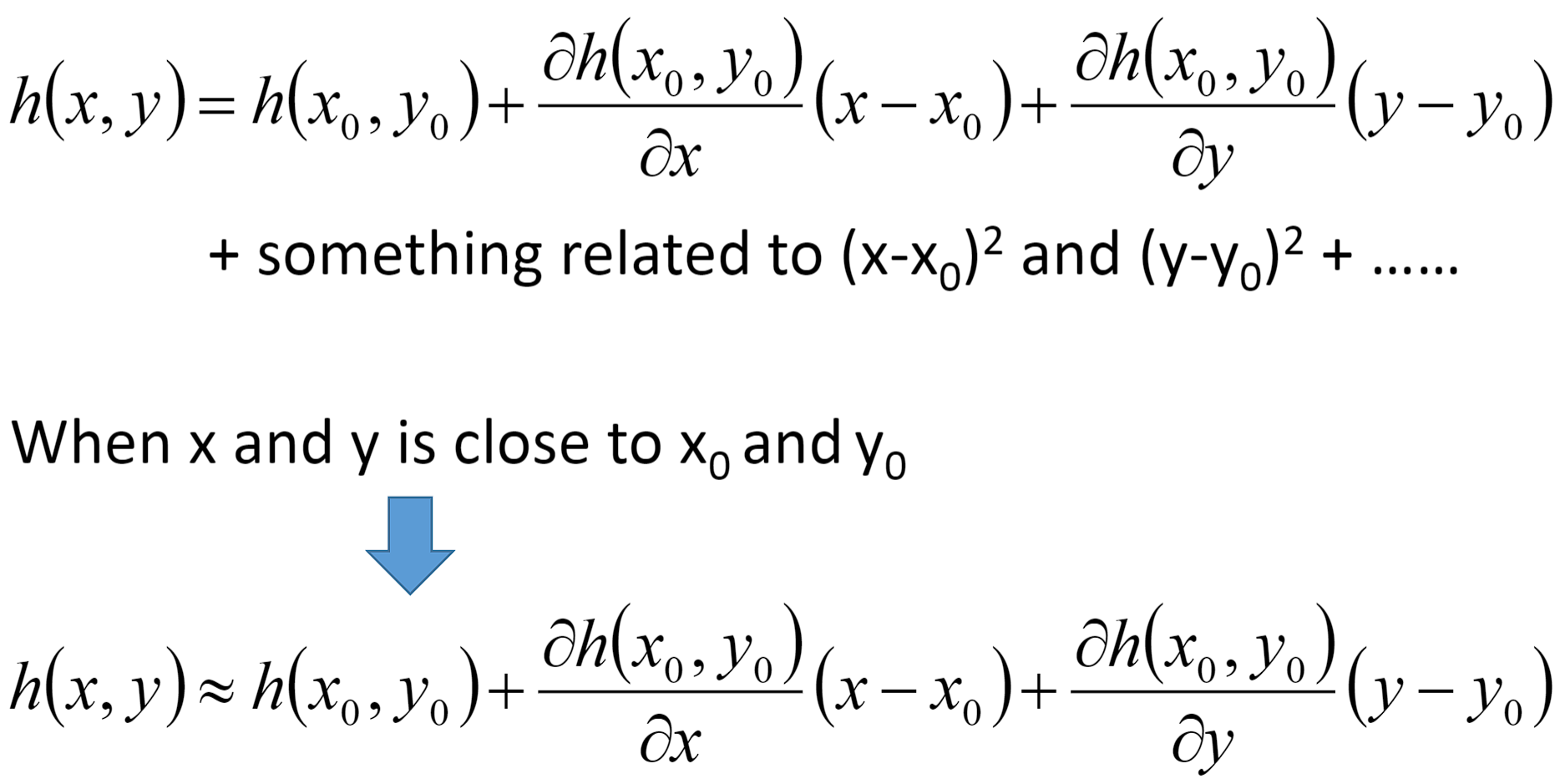在上一章回归那节,我们讨论了如何找到一个最好模型的过程,也就是去找一组参数θ,让这个loss函数越小越好: θ ∗ = a r g m i n θ L ( θ ) θ^{*}=arg\underset{θ}{min}L(θ) θ∗=argθminL(θ) 当θ有两个参数 { θ 1 , θ 2 } \{\theta _{1},\theta _{2}\} {θ1,θ2}时,随机选择一组起始的点 θ 0 = [ θ 1 0 θ 2 0 ] \theta ^{0}=\begin{bmatrix} \theta _{1}^{0}\\ \theta _{2}^{0} \end{bmatrix} θ0=[θ10θ20],上标0代表为初始的那一组参数,下标1,2代表是这一组参数中的第一个参数和第二个参数。
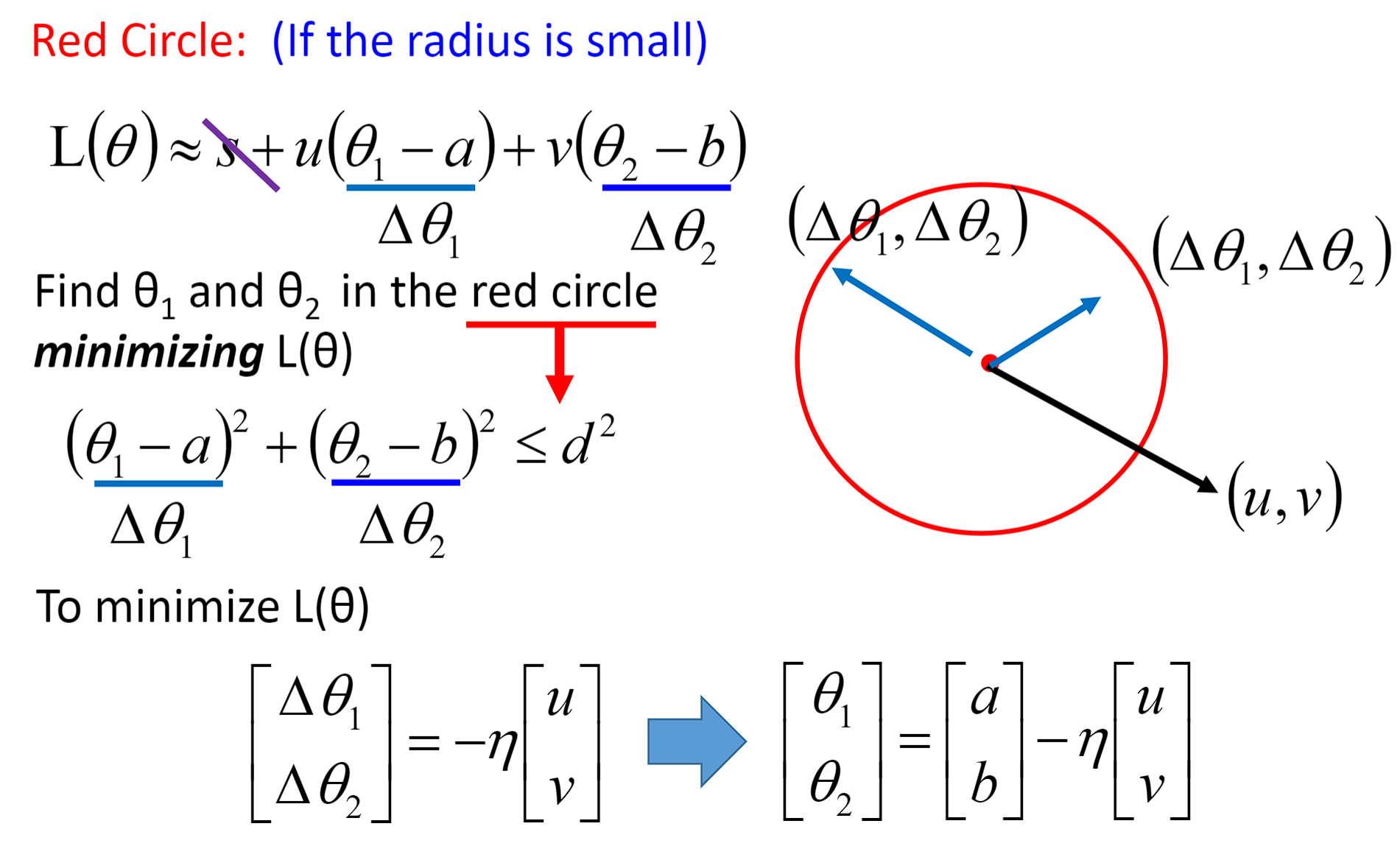
接下来计算 { θ 1 , θ 2 } \{\theta _{1},\theta _{2}\} {θ1,θ2}各自的偏微分:
[ θ 1 1 θ 2 1 ] = [ θ 1 0 θ 2 0 ] − η [ ∂ L ( θ 1 0 ) ∂ θ 1 ∂ L ( θ 2 0 ) ∂ θ 2 ] \begin{bmatrix} \theta _{1}^{1}\\ \theta _{2}^{1} \end{bmatrix}=\begin{bmatrix} \theta _{1}^{0}\\ \theta _{2}^{0} \end{bmatrix}-\eta \begin{bmatrix} \frac{\partial L(\theta _{1}^{0})}{\partial \theta _{1}}\\ \frac{\partial L(\theta _{2}^{0})}{\partial \theta _{2}} \end{bmatrix} [θ11θ21]=[θ10θ20]−η[∂θ1∂L(θ10)∂θ2∂L(θ20)]
[ θ 1 2 θ 2 2 ] = [ θ 1 1 θ 2 1 ] − η [ ∂ L ( θ 1 1 ) ∂ θ 1 ∂ L ( θ 2 1 ) ∂ θ 2 ] \begin{bmatrix} \theta _{1}^{2}\\ \theta _{2}^{2} \end{bmatrix}=\begin{bmatrix} \theta _{1}^{1}\\ \theta _{2}^{1} \end{bmatrix}-\eta \begin{bmatrix} \frac{\partial L(\theta _{1}^{1})}{\partial \theta _{1}}\\ \frac{\partial L(\theta _{2}^{1})}{\partial \theta _{2}} \end{bmatrix} [θ12θ22]=[θ11θ21]−η[∂θ1∂L(θ11)∂θ2∂L(θ21)]
对于 { θ 1 , θ 2 } \{\theta _{1},\theta _{2}\} {θ1,θ2}的偏微分还有另外一种写法: ▽ L ( θ ) \bigtriangledown L(\theta) ▽L(θ)也被叫做梯度(Gradient),代表一组向量(vector) ▽ L ( θ ) = [ ∂ L ( θ 1 ) ∂ θ 1 ∂ L ( θ 2 ) ∂ θ 2 ] \bigtriangledown L(\theta)=\begin{bmatrix} \frac{\partial L(\theta _{1})}{\partial \theta _{1}}\\ \frac{\partial L(\theta _{2})}{\partial \theta _{2}} \end{bmatrix} ▽L(θ)=[∂θ1∂L(θ1)∂θ2∂L(θ2)]
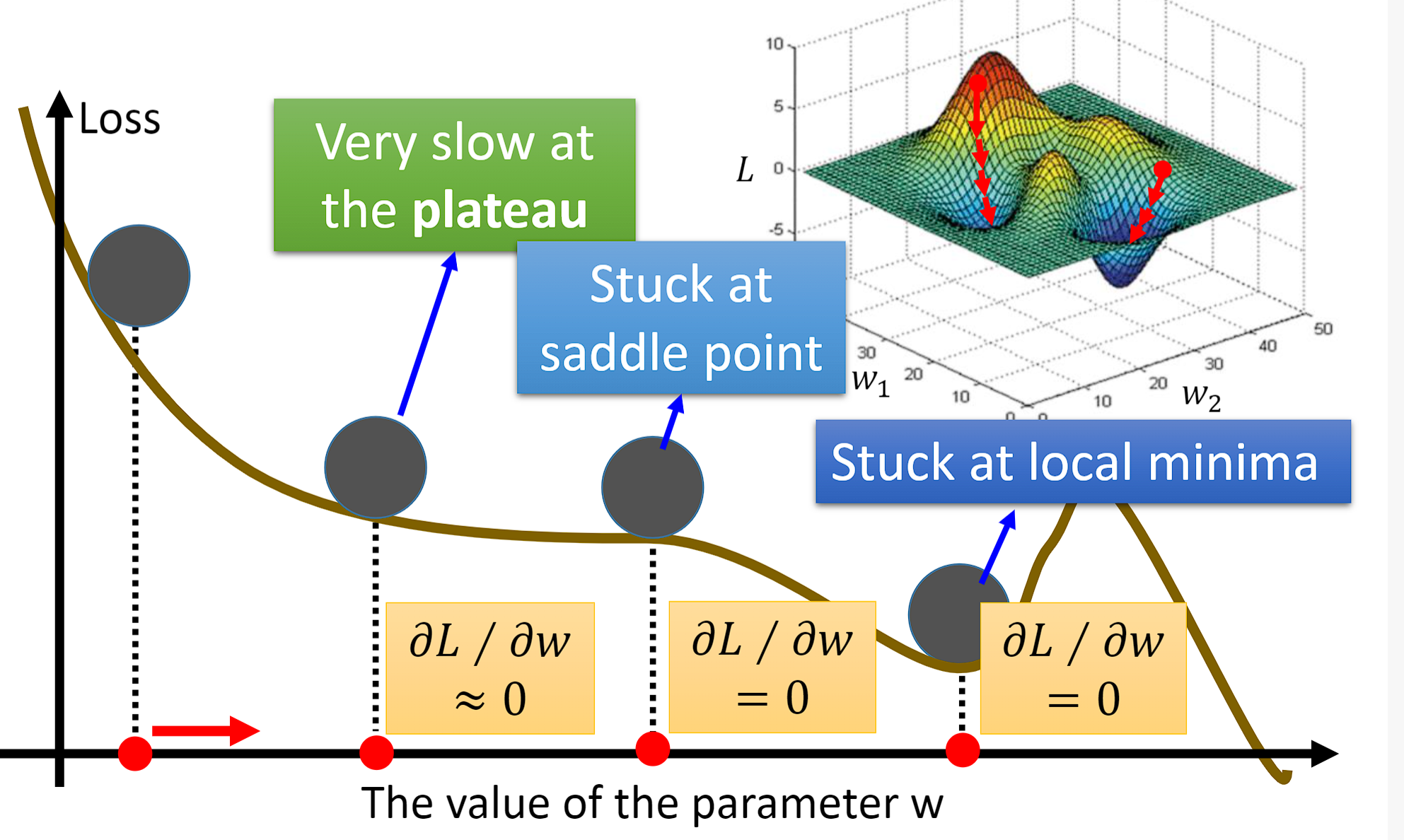
下图是梯度下降(Gradient Descent)的可视化过程:红色的箭头代表梯度的方向,蓝色的箭头代表参数更新的方向,两者是相反的。
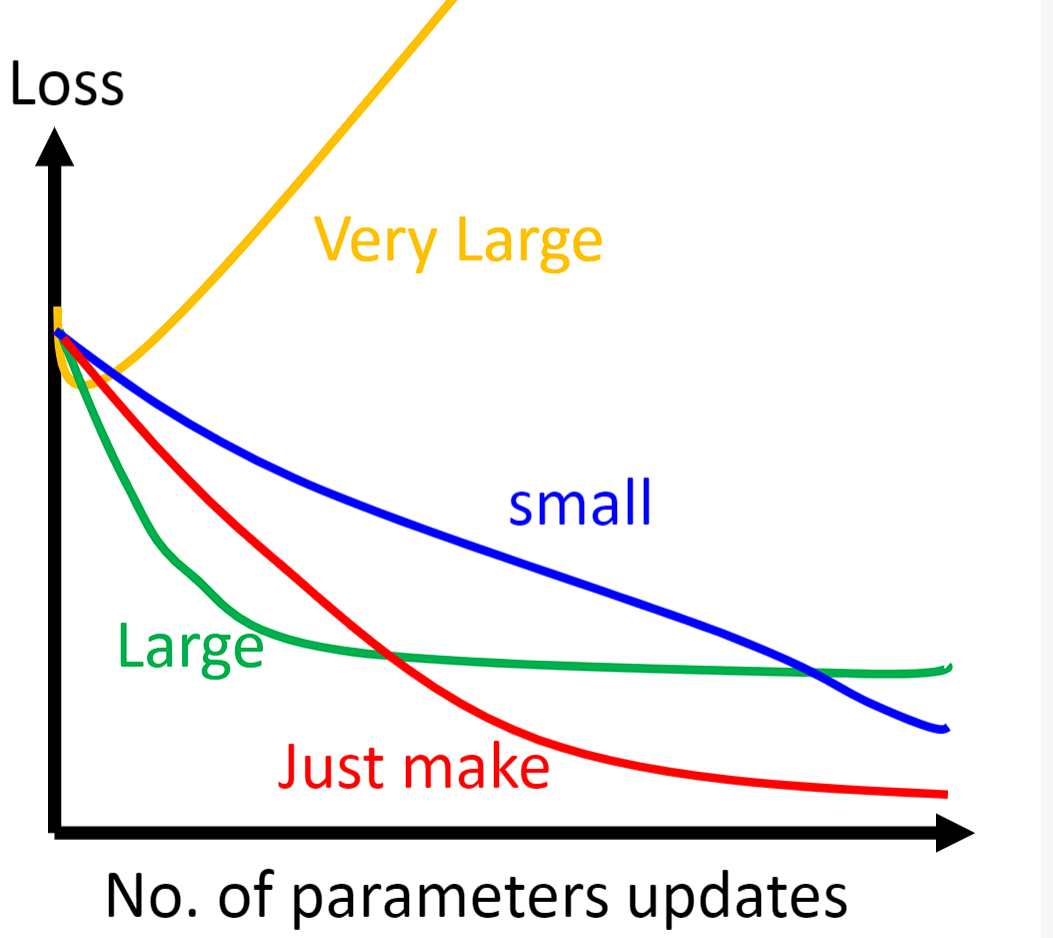
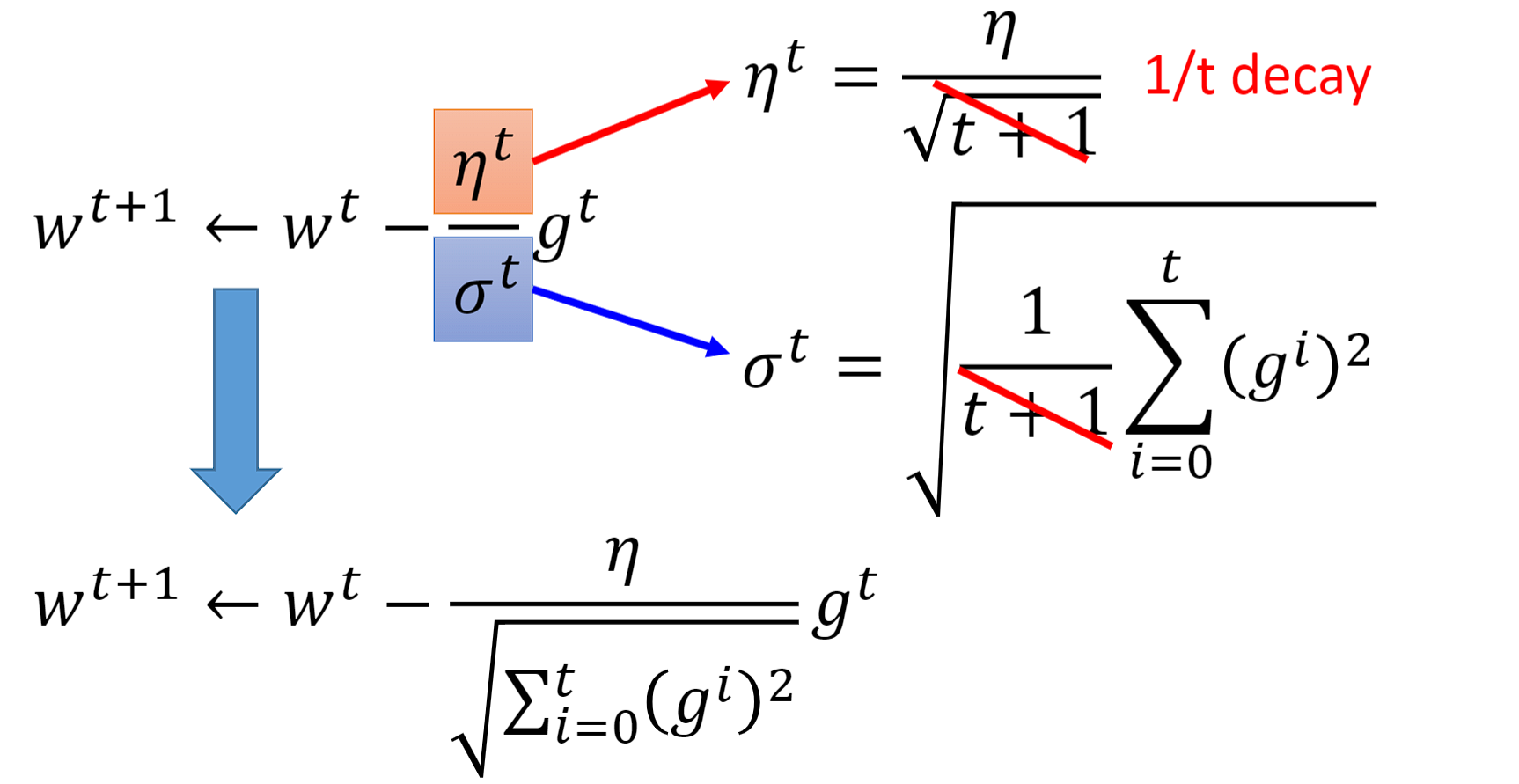
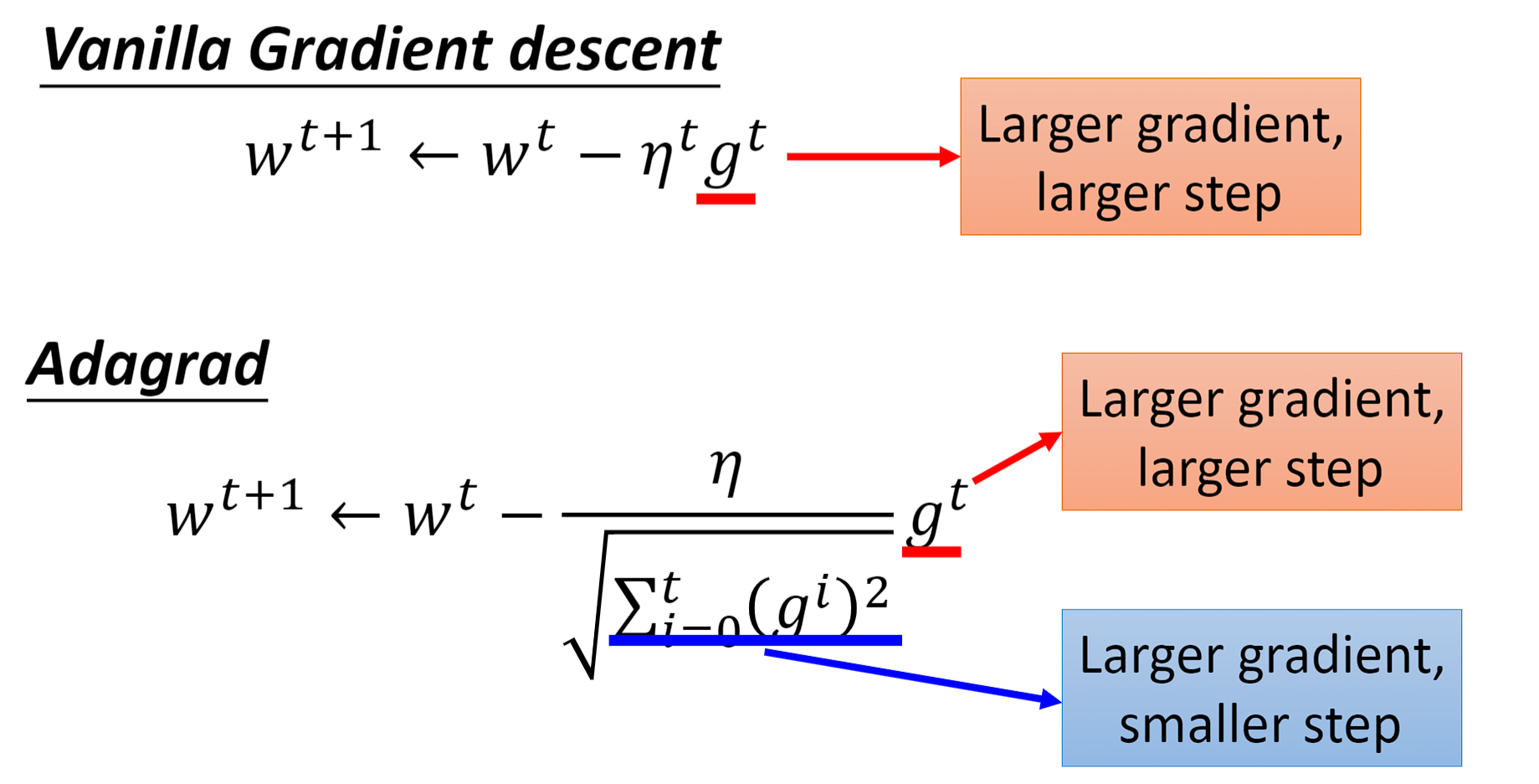
让我们来看一看普通的梯度下降(Vanilla Gradient descent)和Adagrad之间的区别:
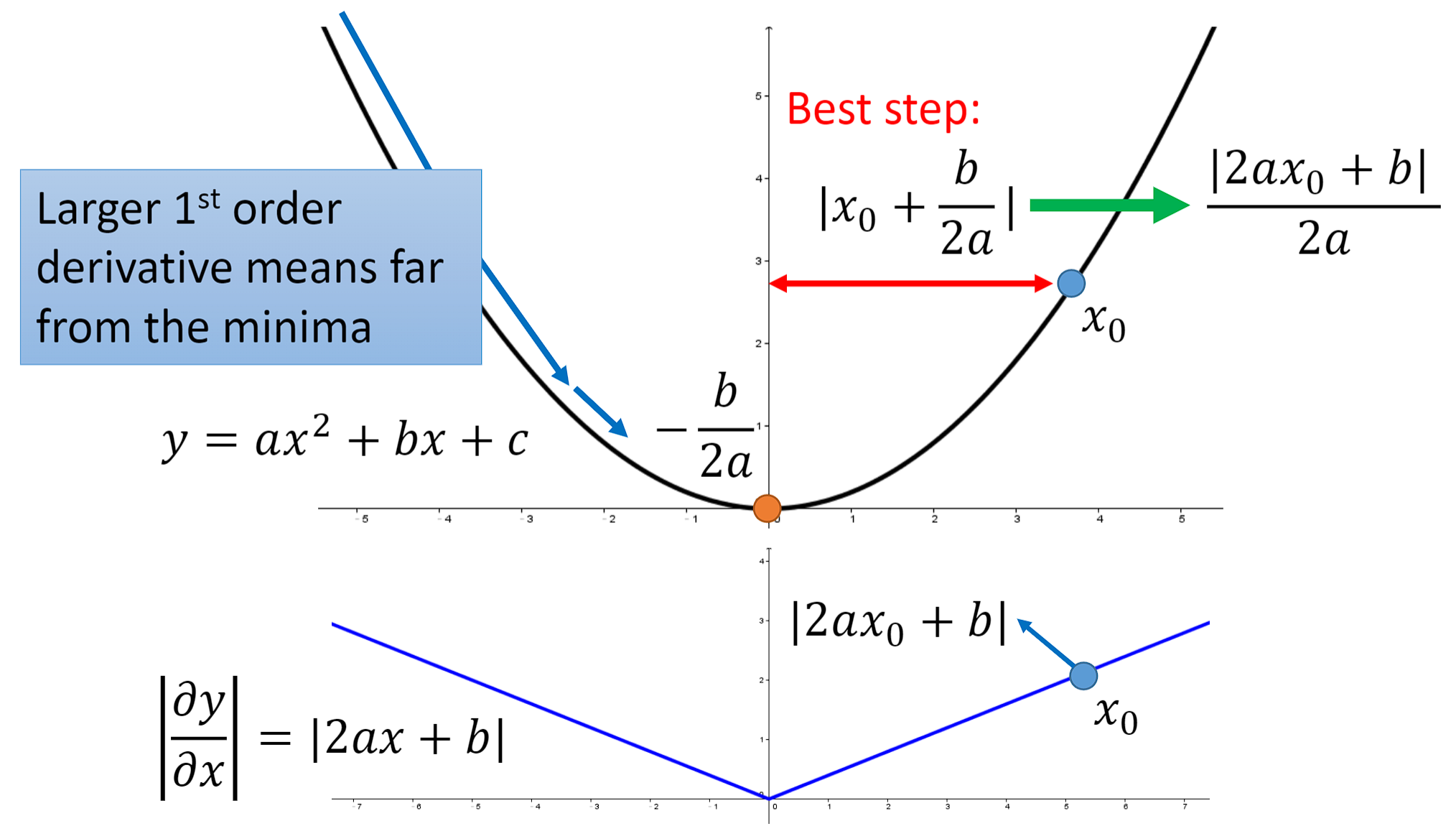
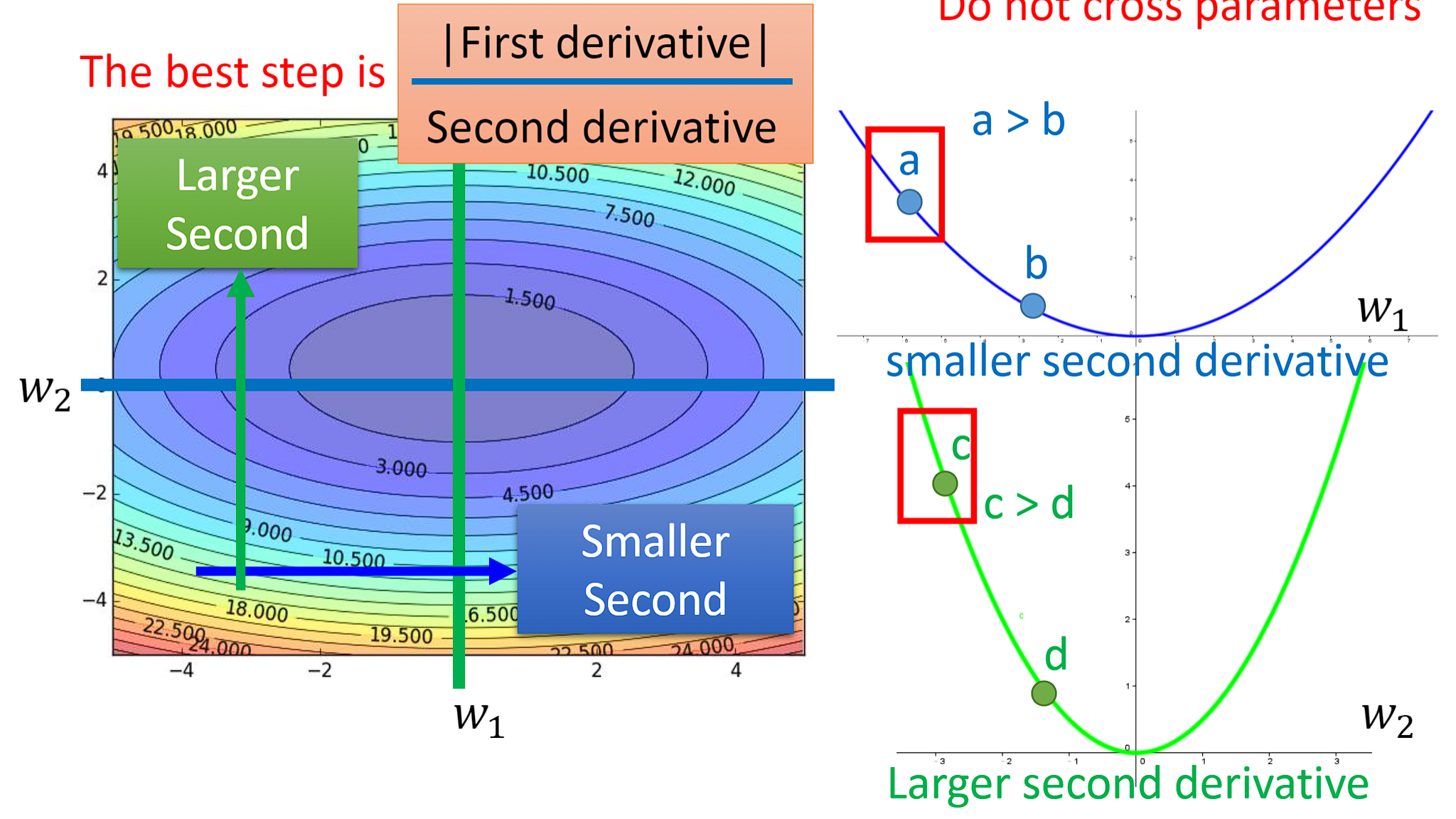
对于这个问题,有这样两种解释:
更正式的解释:
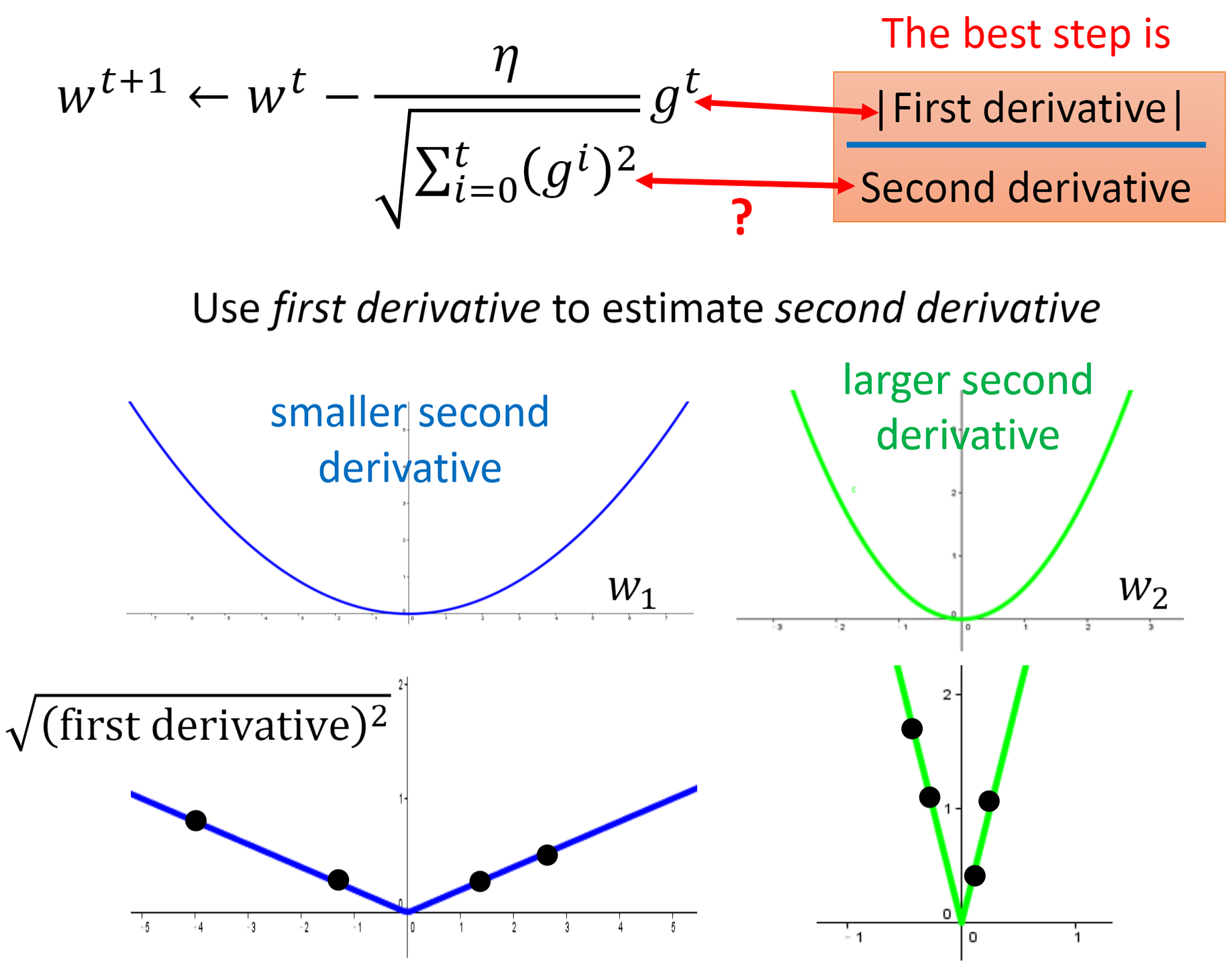
下图是对式子中分母这一项来估计二次微分的解释:当采样足够多的点,梯度g的平方和再开根号就可以近似等于梯度g的二次微分