一、矩阵求导公式
1、总体情况
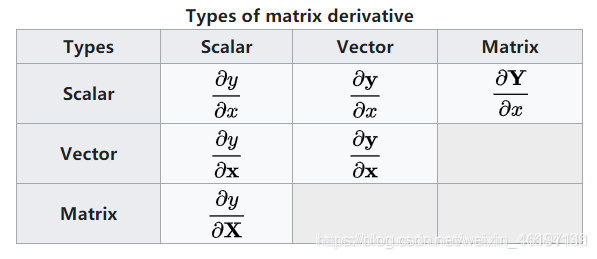
2.分子布局(Numerator layout)和分母布局(Denominator layout)
首先我们常说 y 对 x 求导,这里的 y 和 x 均默认为列向量,y为(mx1), x为(nx1)
(1)分子布局——较为常用
y 对 xT 求导,即对行向量求导。得到mxn的矩阵。比如雅可比矩阵,就是典型的分子布局。雅可比矩阵形式如下:

可见y依然是竖向变化的,而横向是对不同的x求导,也就是说x是横向的。所以是y对 xT 求导。
(2)分母布局——较为常用
yT 对 x 求导,即对列向量求导,得到nxm的矩阵。其实此矩阵是分子布局求出来的矩阵的转置。
而我们知道,梯度ᐁ是导数的转置,,我们一般用分母布局求出的导数需要进行转置才能得到梯度。因此梯度ᐁ可以直接由分子布局的求导得到,也就是上面所说的雅可比矩阵。
海森矩阵是典型的分母布局。
下面建议,将所有的导数均按照分母布局进行计算和解析,然后如果求的是梯度,则取转置即可。
3.计算规律(向量均是列向量)

(2)标量对向量求导
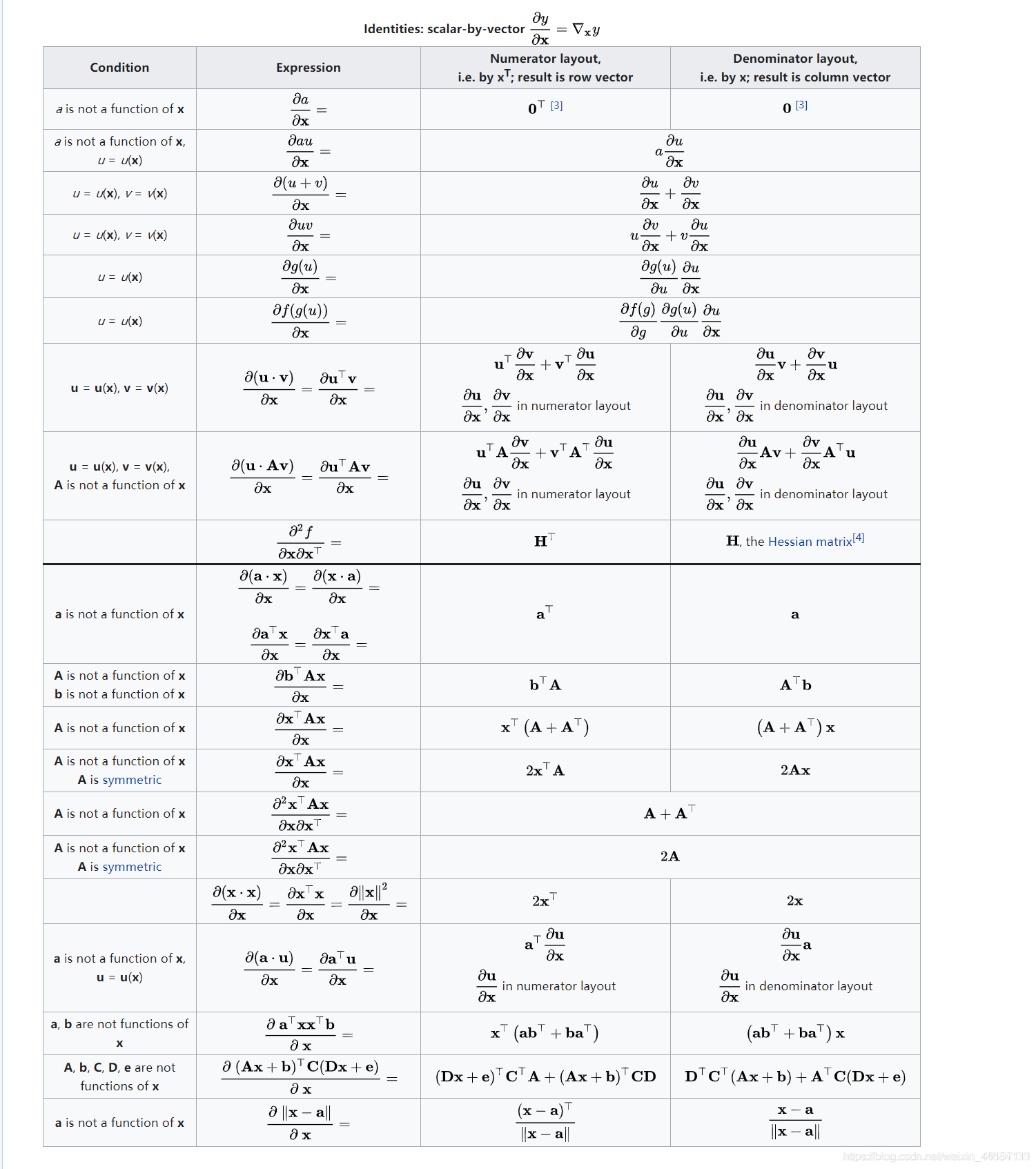
经常,∂x 的二阶导数会被写成(∂x)2,只是为了方便表述而已,其实应该是∂x∂xT 。
(3)向量对标量求导

4.补充
(1)导数和梯度
导数和梯度互为转置,在泰勒展开时,经常会把展开结果写成梯度乘以向量的形式。注意区别。
(2)雅可比矩阵和海森矩阵的形式
雅可比矩阵的形式:

海森矩阵的形式:

声明:以上内容转载自:
https://blog.csdn.net/weixin_44684139/article/details/109676877
二、一元线性回归
概述:
回归是监督学习的一个重要问题,回归用于预测输入变量和输出变量之间的关系
回归模型是表示输入变量到输出变量之间的映射函数
回归问题的学习等价于函数拟合:使用一条函数曲线使其很好的拟合已知函数且很好的预测未知数据。
回归问题按照输入变量的个数可以分为一元回归和多元回归,按照输入变量和输出变量之间的关系可以分为线性回归和非线性回归
一元线性回归模型:
y=ax+b
误差:真实值和预测值之间肯定存在差异,对于每个样本:
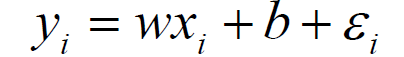

误差是独立并且具有服从均值为0的高斯分布
公式推导过程如下:
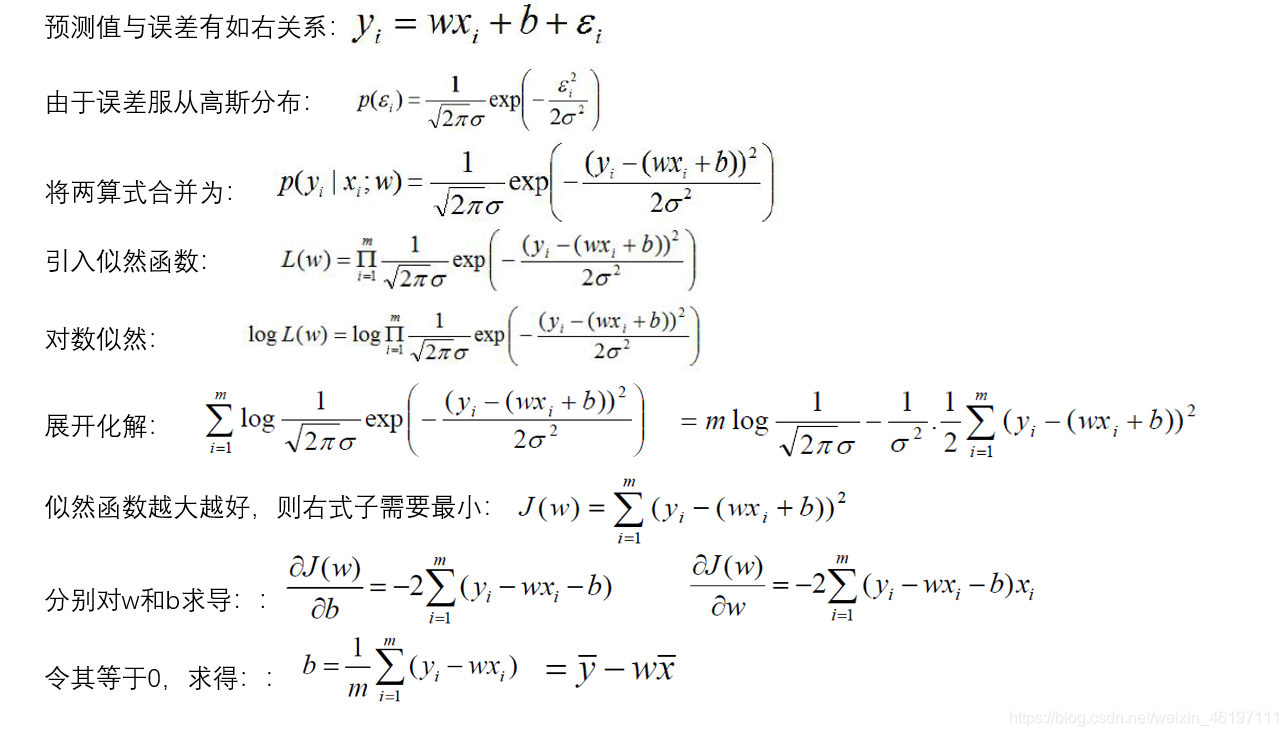
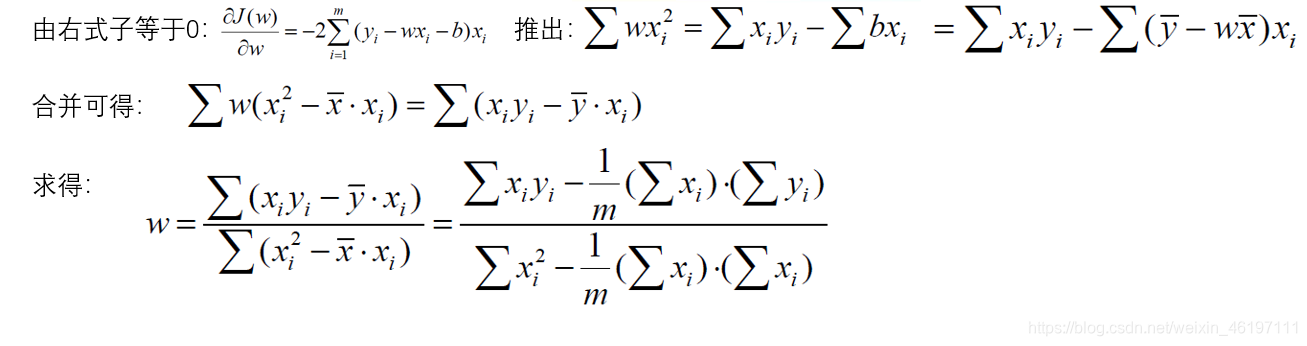
案例代码实现如下:
import numpy as np
import matplotlib.pyplot as plt
def Linnear_Regression(x,y):
x_mean = np.mean(x)
y_mean = np.mean(y)
m = len(x)
numerator=denominator=0
for i in range(m):
numerator+=(x[i]*y[i]-y_mean*x[i])
denominator+= (x[i]**2-x_mean*x[i])
w = numerator/denominator
b = y_mean-w*x_mean
return w,b
def predict_model(w,b,x):
return w*x+b
if __name__ == "__main__":
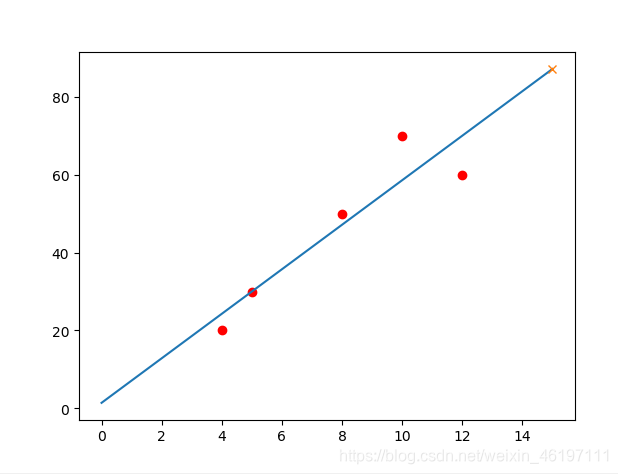
x = [4, 8, 5, 10, 12]
y = [20, 50, 30, 70, 60]
w,b = Linnear_Regression(x,y)
print(w,b)
print(predict_model(w,b,15))
plt.scatter(x,y,marker="o",c="r")
i = np.linspace(0,15,100)
res_i = w*i+b
plt.plot(i,res_i)
mark_res=predict_model(w,b,15)
plt.plot(15,mark_res,marker="x")
plt.show()
输出:
5.714285714285713 1.4285714285714448
87.14285714285714
三、多元线性回归
在回归分析中,如果有两个或两个以上的自变量,就称为多元回归
表达式如下:
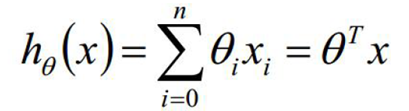
其中:
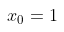
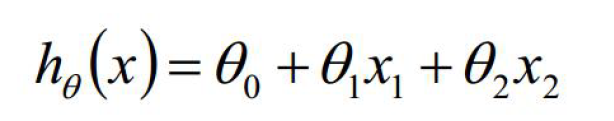
对于输入数据和输出数据y而言。假设y是mn的矩阵,那么x就是m(n+1)列的矩阵,最后一列值全为1。
公式推导过程如下:

多元线性回归的sklearn库包实现
from sklearn import linear_model
model = linear_model.LinearRegression()
x_train = [[1, 0., 3], [1