前言
大家好,这次写作的目的是为了加深对数据可视化pyecharts的认识,也想和大家分享一下。如果下面文章中有错误的地方还请指正,哈哈哈!!!
本次主要用到的第三方库:
requests
pandas
pyecharts
之所以数据可视化选用pyecharts,是因为它含有丰富的精美图表,地图,也可轻松集成至 Flask,Django 等主流 Web 框架中,并且在html渲染网页时把图片保存下来(这里好像截屏就可以了,),任君挑选!!!
这次的数据采集是从招聘网址上抓取到的python招聘岗位信息,嗯……其实这抓取到的数据有点少(只有1200条左右,也没办法,岗位太少了…),所以在后面做可视化图表的时候会导致不好看,骇。本来也考虑过用java(数据1万+)的数据来做测试的,但是想到写的是python,所以也就只能将就用这个数据了,当然如果有感兴趣的朋友,你们可以用java,前端这些岗位的数据来做测试,下面提供的数据抓取方法稍微改一下就可以抓取其它岗位了。
好了,废话不多说,直接开始吧!
演示使用的谷歌浏览器。
一、数据抓取篇
更新爬虫代码(2023.3.11)
逆向sign参数,逆向参考文章https://blog.csdn.net/qq_59142194/article/details/129443287
注意:更新代码未写完,可根据自己需求进行修改!!!
import requests, urllib.parse, hmac, time, random
from hashlib import sha256
class QianChengWuYou:
def __init__(self, keyword:str='python 爬虫', city='全国', start_page=1, end_page=1, sortType=0):
'''
:param keyword: 搜索关键字
:param city: 城市
:param start_page: 从第几页开始爬取
:param end_page: 到第几页爬取结束
:param sortType: 排序类型(0:综合排序,1:最新优先,3:薪资优先)
其它更多参数 请自行去封装(如:salary:月薪范围,workYear:工作年限,degree:学历要求 等等)
'''
self.keyword = keyword
if city=='全国':
self.city_code = "000000"
else:
raise Exception("自定义城市需请自行去研究>请求携带的参数(jobArea)!!!")
self.start_page = start_page
self.end_page = end_page
self.sortType = sortType
self.headers = {
"Accept": "application/json, text/plain, */*",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"From-Domain": "51job_web",
"Origin": "https://we.51job.com",
"Pragma": "no-cache",
"Referer": "https://we.51job.com/",
"Sec-Fetch-Dest": "empty",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Site": "same-site",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36",
"account-id": "",
"partner": "www_baidu_com",
# "property": "%7B%22partner%22%3A%22www_baidu_com%22%2C%22webId%22%3A2%2C%22fromdomain%22%3A%2251job_web%22%2C%22frompageUrl%22%3A%22https%3A%2F%2Fwe.51job.com%2F%22%2C%22pageUrl%22%3A%22https%3A%2F%2Fwe.51job.com%2Fpc%2Fsearch%3Fkeyword%3Djava%26searchType%3D2%26sortType%3D0%26metro%3D%22%2C%22identityType%22%3A%22%22%2C%22userType%22%3A%22%22%2C%22isLogin%22%3A%22%E5%90%A6%22%2C%22accountid%22%3A%22%22%7D",
"sec-ch-ua": "\"Chromium\";v=\"110\", \"Not A(Brand\";v=\"24\", \"Google Chrome\";v=\"110\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sign": "",
"user-token": "",
"uuid": "01e694edebd8638b9402b5feb2436cb6"
}
self.session = requests.Session()
self.requestId = ""
def get_sign(self, msg):
key = 'abfc8f9dcf8c3f3d8aa294ac5f2cf2cc7767e5592590f39c3f503271dd68562b'.encode('utf-8')
return hmac.new(key=key, msg=msg.encode('utf-8'), digestmod=sha256).hexdigest()
def get_data(self, page):
time.sleep((random.random()+0.3)*2)
try:
params = {
"api_key": "51job",
"timestamp": str(int(time.time())),
"keyword": self.keyword,
"searchType": "2",
"function": "",
"industry": "",
"jobArea": str(self.city_code),
"jobArea2": "",
"landmark": "",
"metro": "",
"salary": "",
"workYear": "",
"degree": "",
"companyType": "",
"companySize": "",
"jobType": "",
"issueDate": "",
"sortType": str(self.sortType),
"pageNum": str(page),
"requestId": self.requestId,
"pageSize": "50",
"source": "1",
"accountId": "",
"pageCode": "sou|sou|soulb"
}
self.headers['sign'] = self.get_sign('/open/noauth/search-pc?' + urllib.parse.urlencode(params))
self.data = self.session.get("https://cupid.51job.com/open/noauth/search-pc", headers=self.headers,
params=params).json()
if not params['requestId']:
self.requestId = self.data['resultbody']['requestId']
except Exception as e:
print("异常(get_data)msg>>>", e)
raise Exception(f"请求第{page}页时出现异常!!!")
def parse_data(self):
print(self.data)
print(type(self.data))
def save_data(self):
pass
def main(self):
for page in range(self.start_page, self.end_page+1):
print(f"第{page}页,爬取中...")
try:
self.get_data(page)
self.parse_data()
self.save_data()
except Exception as e:
print("异常msg>>>", e)
break
self.session.close()
if __name__ == '__main__':
QianChengWuYou(keyword='python 爬虫', end_page=2).main()
1.简单的构建反爬措施
这里为大家介绍一个很好用的网站,可以帮助我们在写爬虫时快速构建请求头、cookie这些。但是这个网站也不知为什么,反正在访问时也经常访问不了!额……,介绍下它的使用吧!首先,我们只需要根据下面图片上步骤一样。
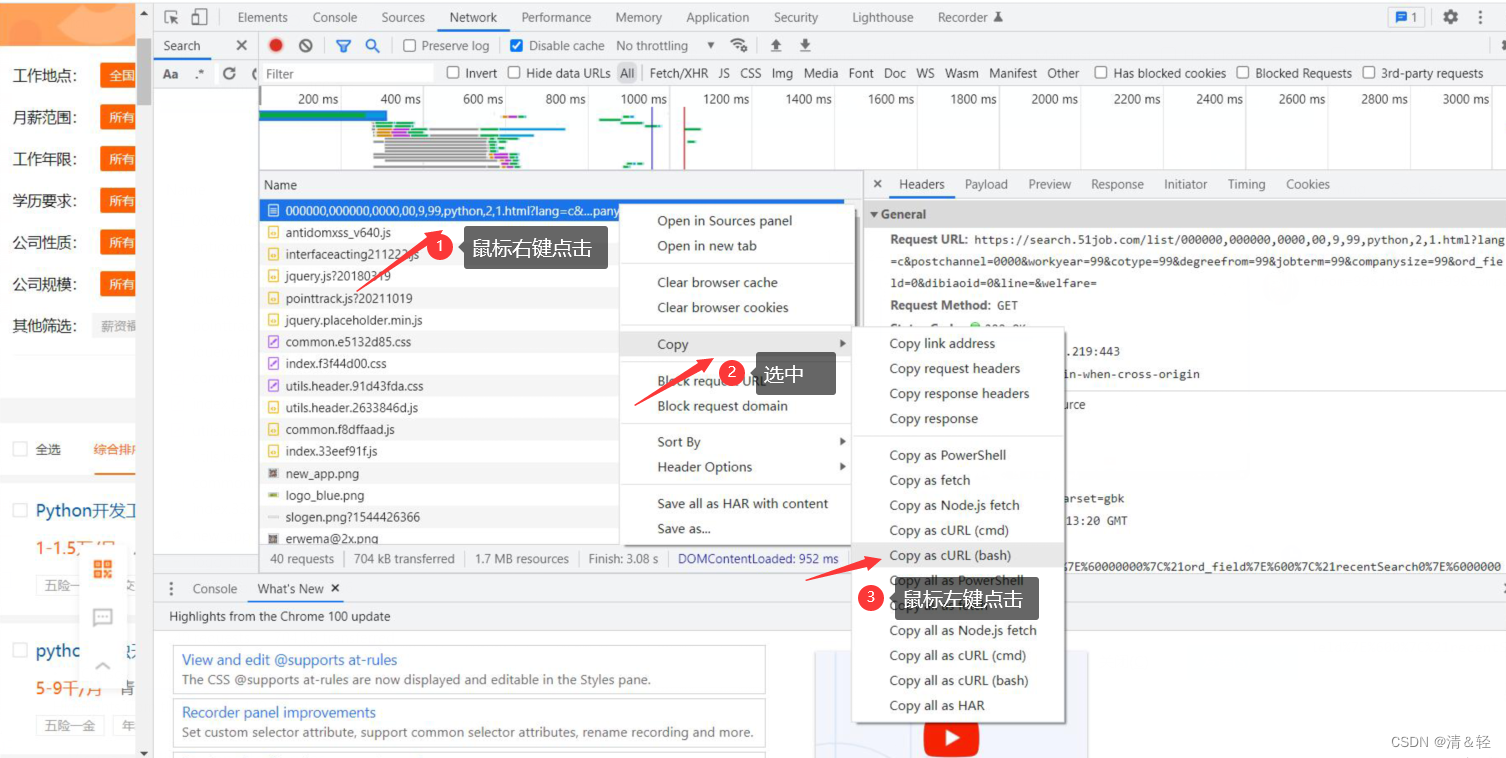
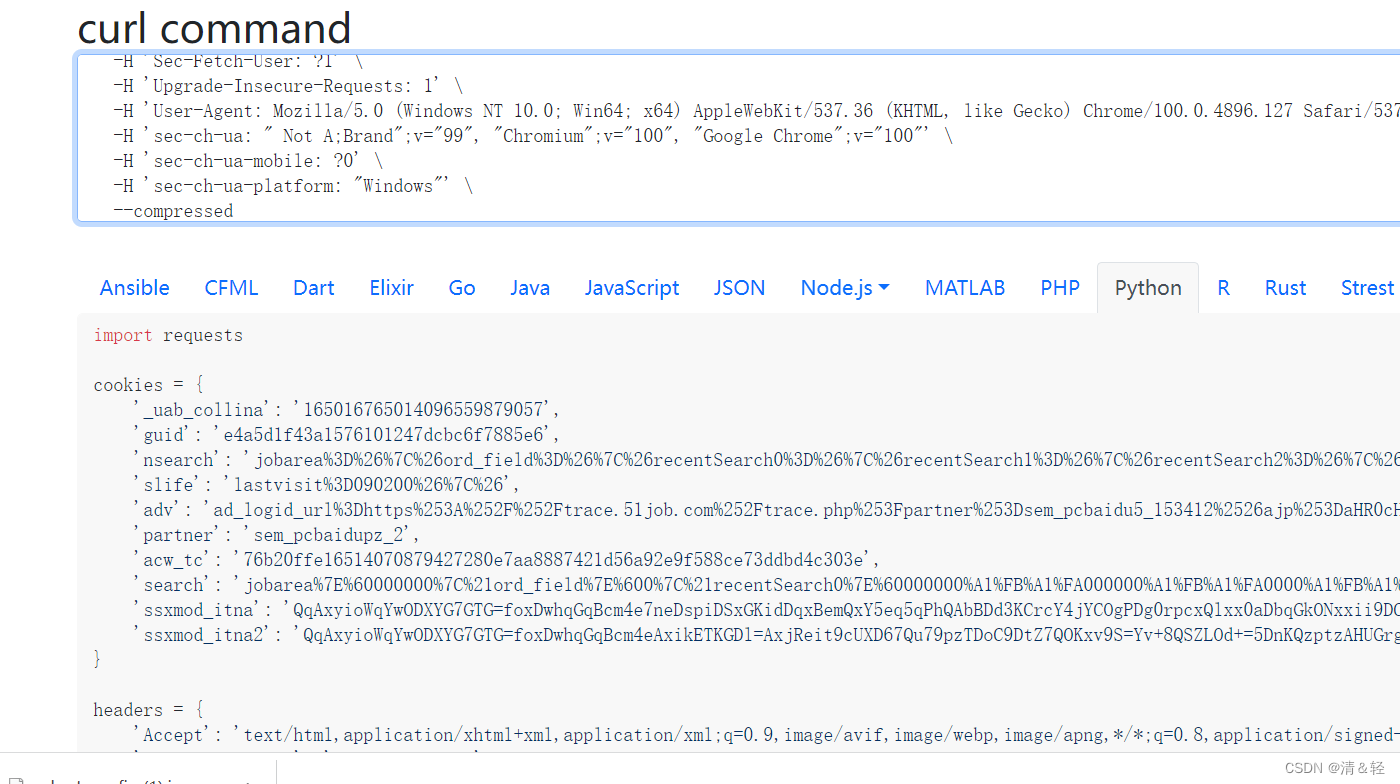
完成之后,我们就复制好了请求头里面的内容了,然后打开网址https://curlconverter.com/ 进入后直接在输入框里Ctrl+v粘贴即可。然后就会在下面解析出内容,我们直接复制就完成了,快速,简单,哈哈哈。
2.解析数据
这里我们请求网址得到的数据它在script js元素标签里面,所以就不能用lxml,css选择器等这些来解析数据。这里我们用re正则来解析数据,得到的数据看到起来好像字典类型,但是它并不是,所以我们还需要用json来把它转化成字典类型的数据方便我们提取。
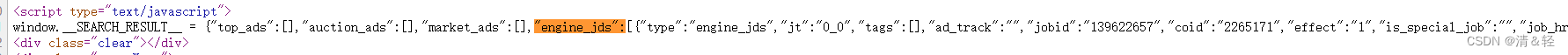

这里用json转化为字典类型的数据后,不好查看时,可以用pprint来打印查看。
3.完整代码
import requests
import re, json, csv, time, random
### url = '这里你们自己构建url吧,从上面的图片应该能看出,我写出来的话实在是不行,过不了审核,难受!!!'
from base64 import b64decode
b64encode_url = 'aHR0cHM6Ly9zZWFyY2guNTFqb2IuY29tLw=='
b64decode_url = b64decode(b64encode_url.encode("utf-8")).decode("utf-8")
print("url:", b64decode_url)
# 浏览器请求头,从列表中随机返回一个
def chrome_ua():
fake_ua_list = ['Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.2 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1664.3 Safari/537.36',
'Mozilla/5.0 (X11; CrOS i686 3912.101.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.17 Safari/537.36']
return random.choice(fake_ua_list)
def spider_data(query, start_page=1,end_page=1,write_mode="w+"):
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
# Requests sorts cookies= alphabetically
# 'Cookie': 'guid=3e7fe47d0c9f737c7199a4f351e8df3d; nsearch=jobarea%3D%26%7C%26ord_field%3D%26%7C%26recentSearch0%3D%26%7C%26recentSearch1%3D%26%7C%26recentSearch2%3D%26%7C%26recentSearch3%3D%26%7C%26recentSearch4%3D%26%7C%26collapse_expansion%3D; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%223e7fe47d0c9f737c7199a4f351e8df3d%22%2C%22first_id%22%3A%221835f92e9f44c9-04bbbbbbbbbbbbc-26021c51-1327104-1835f92e9f5a50%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24latest_referrer%22%3A%22%22%7D%2C%22identities%22%3A%22eyIkaWRlbnRpdHlfY29va2llX2lkIjoiMTgzNWY5MmU5ZjQ0YzktMDRiYmJiYmJiYmJiYmJjLTI2MDIxYzUxLTEzMjcxMDQtMTgzNWY5MmU5ZjVhNTAiLCIkaWRlbnRpdHlfbG9naW5faWQiOiIzZTdmZTQ3ZDBjOWY3MzdjNzE5OWE0ZjM1MWU4ZGYzZCJ9%22%2C%22history_login_id%22%3A%7B%22name%22%3A%22%24identity_login_id%22%2C%22value%22%3A%223e7fe47d0c9f737c7199a4f351e8df3d%22%7D%2C%22%24device_id%22%3A%221835f92e9f44c9-04bbbbbbbbbbbbc-26021c51-1327104-1835f92e9f5a50%22%7D; adv=ad_logid_url%3Dhttps%253A%252F%252Ftrace.51job.com%252Ftrace.php%253Fpartner%253Dsem_pcbaidu5_153287%2526ajp%253DaHR0cHM6Ly9ta3QuNTFqb2IuY29tL3RnL3NlbS9MUF8yMDIwXzEuaHRtbD9mcm9tPWJhaWR1YWQ%253D%2526k%253Dd946ba049bfb67b64f408966cbda3ee9%2526bd_vid%253D11472256346800030279%26%7C%26; partner=51jobhtml5; acw_tc=ac11000116673048509656210e00de5ff8daa4dc09143457b9d79eae3d2f69; acw_sc__v3=63610d9543621eaca0736d477fb79ad95c463726; search=jobarea%7E%60000000%7C%21ord_field%7E%600%7C%21recentSearch0%7E%60000000%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FApython%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21recentSearch1%7E%60090200%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FApython%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21recentSearch2%7E%60090200%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA01%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FApython%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21recentSearch3%7E%60090200%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA01%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FAJava%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21recentSearch4%7E%60000000%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA01%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FAJava%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21collapse_expansion%7E%601%7C%21; ssxmod_itna=QqmxgDnDy7K7wbxl4x+rF10xDKi=q3tCaTKHaDlagoxA5D8D6DQeGTbRYDB0or0hG5tMWm8BDQGCm8vqeLliGi3PC7RopN4bDCPGnDBFxoMmDYYkDt4DTD34DYDigQGIDieDFGkVtCDbxi7DiKDpx0kho5DWa5DED5DFaYDvPYCMDv8DYHGDD5Qsx07DQ5CyZcIP33Dn=01aWxCD75EDlp59RxCzzkUCjy1XKLwEA9h5boDjaYCDmW7+4GducvwVDPxYY2FIg23qW2to02DNo2DPBhx1jidqgx4K00l706ZCDDWM7KHaYD==; ssxmod_itna2=QqmxgDnDy7K7wbxl4x+rF10xDKi=q3tCaTKaD6hFxGq4DsheDLA=y4u=wQyZF1w0GzaKeMKiNKzEk7PtQXhQSiN3zrdLwADoCaHFtiMzwaW8alC/9yOnKG7oGFBglfl3llCkLC4SCG6HldiPeWU4fhXx57YqdOidIg2MGkRPrnGOnebl9uUxsf5Q=eWg9qAQ7CK1SeAFoDKlIO9gAOFYcxjKs2xFCuy=g0Y0Ur6FXxIHPW5CPo3VI2jIr1LILYc6DbttXS95cIFWX8YgAlYUHnDrevwSGA6I4ZyhmPhZnnYg490Mebf/CNF6wxZN17N=10xED1=qcB58AwMGGsoNYt05KvxfN4er5KEDO2bG2Y2wyW0+Z0xldGAXlYp5Sp=KfpPTN3LqQiVg2MlLO1vr+YE=Ysbw5IK8OnYpnN3v3b0T2WOOAAoLRxeOPAOEXL9nZQdLbdjtY6FXaEiSidu3W0+4DQFPtxgnhxR4dBmCwxifLkUMtlDDFqD+2xxD',
'Pragma': 'no-cache',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36',
'sec-ch-ua': '"Google Chrome";v="107", "Chromium";v="107", "Not=A?Brand";v="24"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
save_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()).replace(' ', '_').replace(':','_')
file_path = f'./全国{query}岗位数据-{save_time}.csv'
f_csv = open(file_path, mode=write_mode, encoding='utf-8', newline='')
fieldnames = ['公司名字', '职位名字', '薪资', '工作地点',
'招聘要求', '公司待遇','招聘更新时间', '招聘发布时间',
'公司人数', '公司类型', 'companyind_text', 'job_href', 'company_href']
dict_write = csv.DictWriter(f_csv, fieldnames=fieldnames)
dict_write.writeheader() # 写入表头
error_time = 0 #在判断 职位名字中是否没有关键字的次数,这里定义出现200次时,while循环结束
# (因为在搜索岗位名字时(如:搜索python),会在网站20多页时就没有关于python的岗位了,但是仍然有其它的岗位出现,所以这里就需要if判断,使其while循环结束)
for page in range(start_page,end_page+1):
print(f'第{page}页抓取中……')
headers['User-Agent'] = chrome_ua()
url = b64decode_url + f'list/000000,000000,0000,00,9,99,{query},2,{page}.html'
url = url + '?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare='
headers['Referer'] = url
try:
response = requests.get(url=url, headers=headers, cookies=cookies)
parse_data = re.findall('"engine_jds":(.*?),"jobid_count"',response.text)
parse_data_dict = json.loads(parse_data[0])
except:
f_csv.close()
print('\033[31m可更换cookies后再尝试!!!\033[0m')
raise Exception(f"第{page}页——请求异常!")
for i in parse_data_dict:
###在这里要处理下异常,因为在爬取多页时,可能是网站某些原因会导致这里的结构变化
try:
companyind_text = i['companyind_text']
except Exception as e:
# print(f'\033[31m异常:{e}\033[0m')
companyind_text = None
dic = {
'公司名字': i['company_name'],
'职位名字': i['job_name'],
'薪资': i['providesalary_text'],
'工作地点': i['workarea_text'],
'招聘要求': ' '.join(i['attribute_text']),
'公司待遇': i['jobwelf'],
'招聘更新时间': i['updatedate'],
'招聘发布时间': i['issuedate'],
'公司人数': i['companysize_text'],
'公司类型': i['companytype_text'],
'companyind_text': companyind_text,
'job_href': i['job_href'],
'company_href': i['company_href'],
}
if 'Python' in dic['职位名字'] or 'python' in dic['职位名字']:
dict_write.writerow(dic) # 写入数据
print(dic['职位名字'], '——保存完毕!')
else:
error_time += 1
if error_time == 200:
break
if error_time >= 200:
break
time.sleep((random.random() + 0.5) * 3) #这里随机休眠一下(0-3秒),简单反爬处理,反正我们用的是单线程爬取,也不差那一点时间是吧
print('抓取完成!')
f_csv.close()
###这里还是要添加cookies的好,我们要伪装好不是?防止反爬,如果你用之前提到的方法,也就很快的构建出cookies。
cookies = {
'guid': '3e7fe47d0c9f737c7199a4f351e8df3d',
'nsearch': 'jobarea%3D%26%7C%26ord_field%3D%26%7C%26recentSearch0%3D%26%7C%26recentSearch1%3D%26%7C%26recentSearch2%3D%26%7C%26recentSearch3%3D%26%7C%26recentSearch4%3D%26%7C%26collapse_expansion%3D',
'sensorsdata2015jssdkcross': '%7B%22distinct_id%22%3A%223e7fe47d0c9f737c7199a4f351e8df3d%22%2C%22first_id%22%3A%221835f92e9f44c9-04bbbbbbbbbbbbc-26021c51-1327104-1835f92e9f5a50%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24latest_referrer%22%3A%22%22%7D%2C%22identities%22%3A%22eyIkaWRlbnRpdHlfY29va2llX2lkIjoiMTgzNWY5MmU5ZjQ0YzktMDRiYmJiYmJiYmJiYmJjLTI2MDIxYzUxLTEzMjcxMDQtMTgzNWY5MmU5ZjVhNTAiLCIkaWRlbnRpdHlfbG9naW5faWQiOiIzZTdmZTQ3ZDBjOWY3MzdjNzE5OWE0ZjM1MWU4ZGYzZCJ9%22%2C%22history_login_id%22%3A%7B%22name%22%3A%22%24identity_login_id%22%2C%22value%22%3A%223e7fe47d0c9f737c7199a4f351e8df3d%22%7D%2C%22%24device_id%22%3A%221835f92e9f44c9-04bbbbbbbbbbbbc-26021c51-1327104-1835f92e9f5a50%22%7D',
'adv': 'ad_logid_url%3Dhttps%253A%252F%252Ftrace.51job.com%252Ftrace.php%253Fpartner%253Dsem_pcbaidu5_153287%2526ajp%253DaHR0cHM6Ly9ta3QuNTFqb2IuY29tL3RnL3NlbS9MUF8yMDIwXzEuaHRtbD9mcm9tPWJhaWR1YWQ%253D%2526k%253Dd946ba049bfb67b64f408966cbda3ee9%2526bd_vid%253D11472256346800030279%26%7C%26',
'partner': '51jobhtml5',
'acw_tc': 'ac11000116673048509656210e00de5ff8daa4dc09143457b9d79eae3d2f69',
'acw_sc__v3': '63610d9543621eaca0736d477fb79ad95c463726',
'search': 'jobarea%7E%60000000%7C%21ord_field%7E%600%7C%21recentSearch0%7E%60000000%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FApython%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21recentSearch1%7E%60090200%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FApython%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21recentSearch2%7E%60090200%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA01%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FApython%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21recentSearch3%7E%60090200%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA01%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FAJava%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21recentSearch4%7E%60000000%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA01%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FAJava%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21collapse_expansion%7E%601%7C%21',
'ssxmod_itna': 'Yqjx0Dg7qQqWqD5iQDXDnWpe4BKIoRRR0Yk0hb4GNoWDZDiqAPGhDC+b94RG872hxYCWPmr35QYA44xdjCQ7G3tKF8iaXxWDCPGnDBKw6iADYYkDt4DTD34DYDi2QGIDieDFzHy/kDbxi7DiKDpx0kGP5DWr5DElKDFrYDvxBkilF8DY5GDD5Qzx07DQyk9gpIeK3Dn2G1bY2kD7yADlpqc80k18dUKAv1U4kwfmIhKtoDjrBkDme7h4GdR2Hw/lnDFihFpgDdQYxeYQ+b8u07tG05F0x3xgGPY0x4RvR99kDDioro/m+DD=',
'ssxmod_itna2': 'Yqjx0Dg7qQqWqD5iQDXDnWpe4BKIoRRR0Yk0xA=WmxqD/CQYDF2+xOF4qR179o55HF/PnPwOCRrAH=wex3rYb88CrTEnLufRmKewbQmqEFjdy4Fd0f4Okld8++sIkl8RArfFAXjZvr=IIMXImAQIUT4wUMthKTiHKLiD82vAeRRmiTu9ChRPpYnQZr+bsQvbTQawD=NLnmXNd1nNq=naETLkOjA11RfPdqcisrQpKwDK704kvhRgBrT3uRhOs9nFo4n8hKMYxPodon965BWkZ2ba6aE2kZ0v5AkSD6LN2hkBx4Wns5ng0eixKigANZDjP0qbqD93KBUjEPA=K3hq71wvaoKAtOroKjYf2ExBUAY0Tm2FaGv=Qkr03ohlEmucRvEKoQd2O2Qox/pPxFX32iFSrg2o2rt+S3oY=/=5LPbXor/2b2QIr/pPBjMlro6bnDR8EtQg4i+YR/QRotN66YtAXPKgOF3zb6QHf3NC=egOi/=DP3UYRxWDG2iGtI4mKwPlMQQjPIR+GG+Ojq7DDFqD+ODxD===',
}
if __name__ == '__main__':
# key_word = 'java' ##这里不能输入中文,网址做了url字体加密,简单的方法就是直接从网页url里面复制下来用(如:前端)
# key_word = '%25E5%2589%258D%25E7%25AB%25AF' #前端
query = 'python'
'''
这里将测试爬取1到3页的数据
网站的页数,可根据自己的需求更改页数
'''
spider_data(query,start_page=1,end_page=3)
二、数据可视化篇
1.数据可视化库选用
本次数据可视化选用的是pyecharts第三方库,它制作图表是多么的强大与精美!!!想要对它进行一些简单地了解话可以前往这篇博文:
https://blog.csdn.net/qq_59142194/article/details/124540409?spm=1001.2014.3001.5501
安装: pip install pyecharts
2.案例实战
本次要对薪资、工作地点、招聘要求里面的经验与学历进行数据处理并可视化。

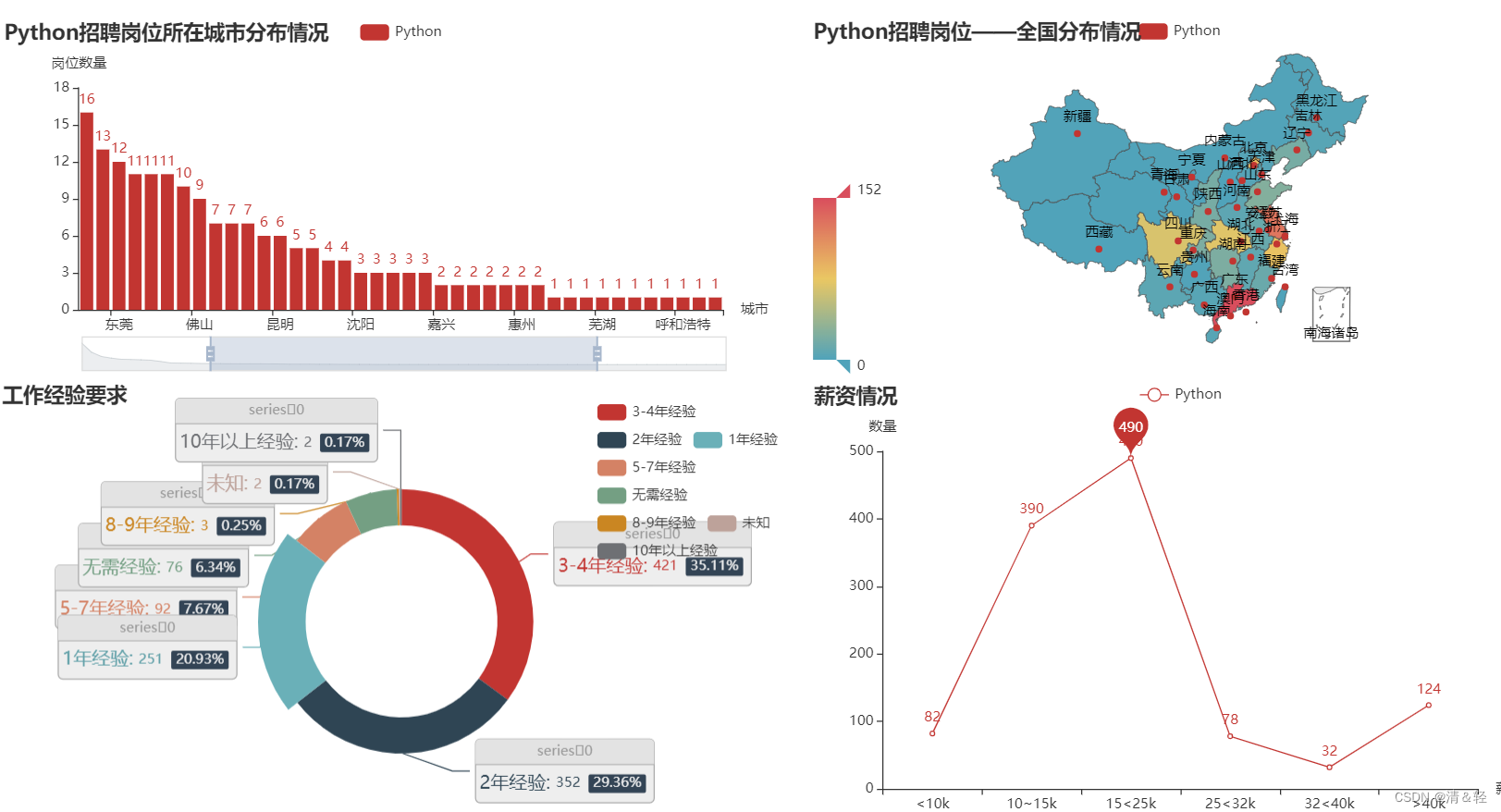
(1).柱状图Bar
按住鼠标中间滑轮或鼠标左键可进行调控。
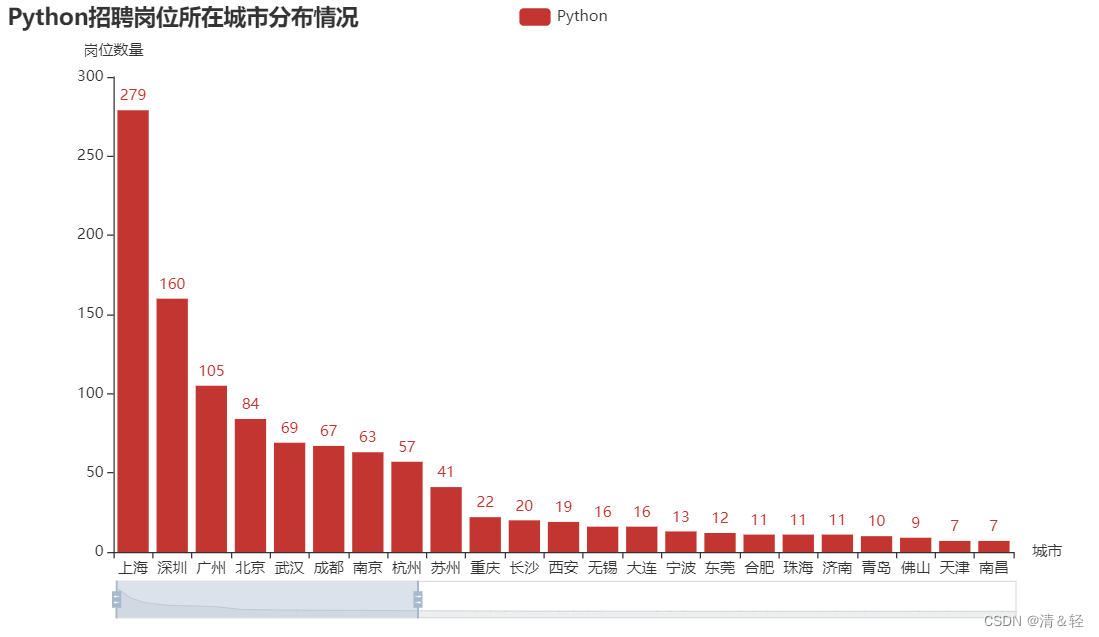
import pandas as pd
from pyecharts import options as opts
python_data = pd.read_csv('./testDataPython-2022-05-01_11_48_36.csv')
python_data['工作地点'] = [i.split('-')[0] for i in python_data['工作地点']]
city = python_data['工作地点'].value_counts()
###柱状图
from pyecharts.charts import Bar
c = (
Bar()
.add_xaxis(city.index.tolist()) #城市列表数据项
.add_yaxis("Python", city.values.tolist())#城市对应的岗位数量列表数据项
.set_global_opts(
title_opts=opts.TitleOpts(title="Python招聘岗位所在城市分布情况"),
datazoom_opts=[opts.DataZoomOpts(), opts.DataZoomOpts(type_="inside")],
xaxis_opts=opts.AxisOpts(name='城市'), # 设置x轴名字属性
yaxis_opts=opts.AxisOpts(name='岗位数量'), # 设置y轴名字属性
)
.render("bar_datazoom_both.html")
)
(2).地图Map
省份
这里对所在省份进行可视化。
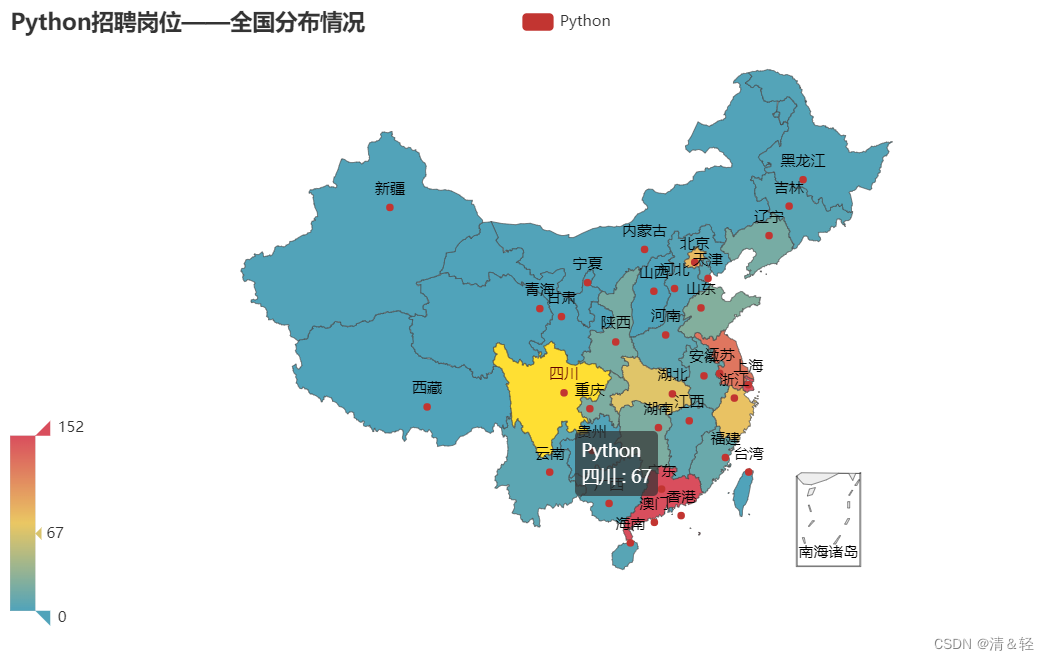
import pandas as pd
import copy
from pyecharts import options as opts
python_data = pd.read_csv('./testDataPython-2022-05-01_11_48_36.csv')
python_data_deepcopy = copy.deepcopy(python_data) #深复制一份数据
python_data['工作地点'] = [i.split('-')[0] for i in python_data['工作地点']]
city = python_data['工作地点'].value_counts()
city_list = [list(ct) for ct in city.items()]
def province_city():
'''这是从接口里爬取的数据(不太准,但是误差也可以忽略不计!)'''
area_data = {}
with open('./中国省份_城市.txt', mode='r', encoding='utf-8') as f:
for line in f:
line = line.strip().split('_')
area_data[line[0]] = line[1].split(',')
province_data = []
for ct in city_list:
for k, v in area_data.items():
for i in v:
if ct[0] in i:
ct[0] = k
province_data.append(ct)
area_data_deepcopy = copy.deepcopy(area_data)
for k in area_data_deepcopy.keys():
area_data_deepcopy[k] = 0
for i in province_data:
if i[0] in area_data_deepcopy.keys():
area_data_deepcopy[i[0]] = area_data_deepcopy[i[0]] +i[1]
province_data = [[k,v]for k,v in area_data_deepcopy.items()]
best = max(area_data_deepcopy.values())
return province_data,best
province_data,best = province_city()
#地图_中国地图(带省份)Map-VisualMap(连续型)
c2 = (
Map()
.add( "Python",province_data, "china")
.set_global_opts(
title_opts=opts.TitleOpts(title="Python招聘岗位——全国分布情况"),
visualmap_opts=opts.VisualMapOpts(max_=int(best / 2)),
)
.render("map_china.html")
)
这是 中国省份_城市.txt 里面的内容,通过[接口]抓取到的中国地区信息。

爬取中国省份_城市.txt的源码:
import requests
import json
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36",
}
response = requests.get('https://j.i8tq.com/weather2020/search/city.js',headers=header)
result = json.loads(response.text[len('var city_data ='):])
print(result)
each_province_data = {}
f = open('./中国省份_城市.txt',mode='w',encoding='utf-8')
for k,v in result.items():
province = k
if k in ['上海', '北京', '天津', '重庆']:
city = ','.join(list(v[k].keys()))
else:
city = ','.join(list(v.keys()))
f.write(f'{province}_{city}\n')
each_province_data[province] = city
f.close()
print(each_province_data)
城市
这里对所在城市进行可视化。
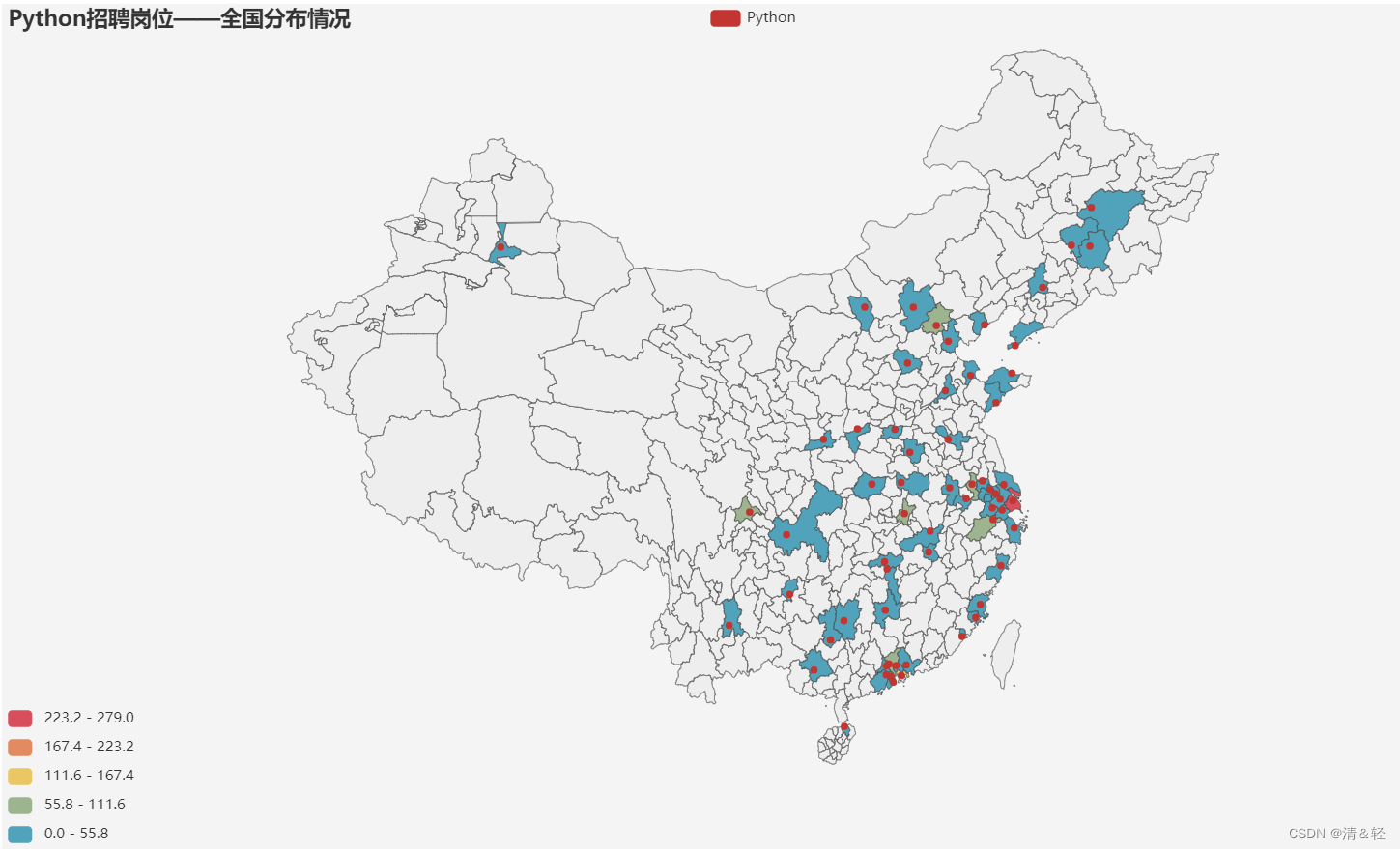
import pandas as pd
import copy
from pyecharts import options as opts
python_data = pd.read_csv('./testDataPython-2022-05-01_11_48_36.csv')
python_data_deepcopy = copy.deepcopy(python_data) #深复制一份数据
python_data['工作地点'] = [i.split('-')[0] for i in python_data['工作地点']]
city = python_data['工作地点'].value_counts()
city_list = [list(ct) for ct in city.items()]
###地图_中国地图(带城市)——Map-VisualMap(分段型)
from pyecharts.charts import Map
c1 = (
Map(init_opts=opts.InitOpts(width="1244px", height="700px",page_title='Map-中国地图(带城市)', bg_color="#f4f4f4"))
.add(
"Python",
city_list,
"china-cities", #地图
label_opts=opts.LabelOpts(is_show=False),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="Python招聘岗位——全国分布情况"),
visualmap_opts=opts.VisualMapOpts(max_=city_list[0][1],is_piecewise=True),
)
.render("map_china_cities.html")
)
地区
这里对上海地区可视化。
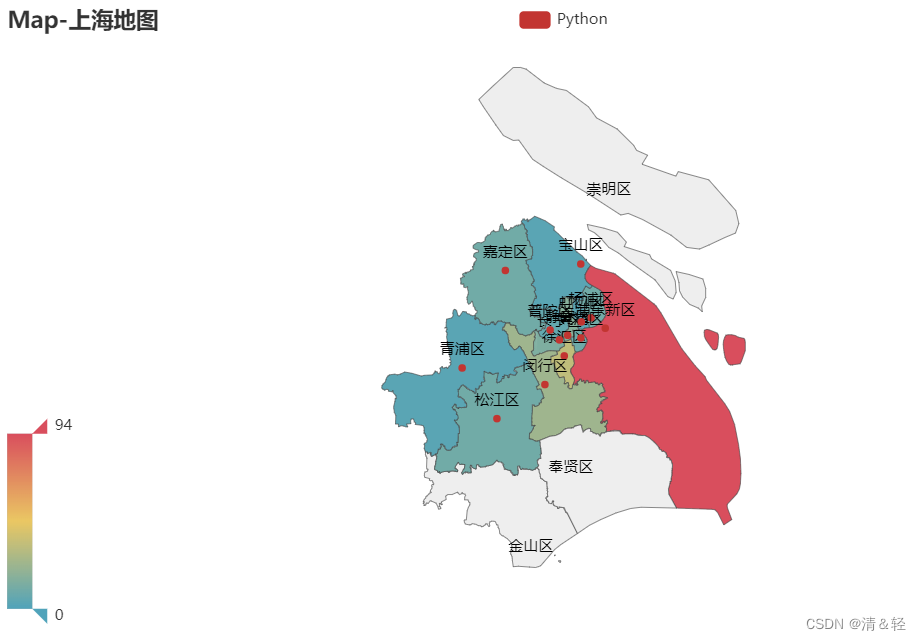
import pandas as pd
import copy
from pyecharts import options as opts
python_data = pd.read_csv('./testDataPython-2022-05-01_11_48_36.csv')
python_data_deepcopy = copy.deepcopy(python_data) #深复制一份数据
shanghai_data = []
sh = shanghai_data.append
for i in python_data_deepcopy['工作地点']:
if '上海' in i:
if len(i.split('-')) > 1:
sh(i.split('-')[1])
shanghai_data = pd.Series(shanghai_data).value_counts()
shanghai_data_list = [list(sh) for sh in shanghai_data.items()]
#上海地图
c3 = (
Map()
.add("Python", shanghai_data_list, "上海") ###这个可以更改地区(如:成都)这里改了的话,上面的数据处理也要做相应的更改
.set_global_opts(
title_opts=opts.TitleOpts(title="Map-上海地图"),
visualmap_opts=opts.VisualMapOpts(max_=shanghai_data_list[0][1])
)
.render("map_shanghai.html")
)
(3).饼图Pie
Pie1
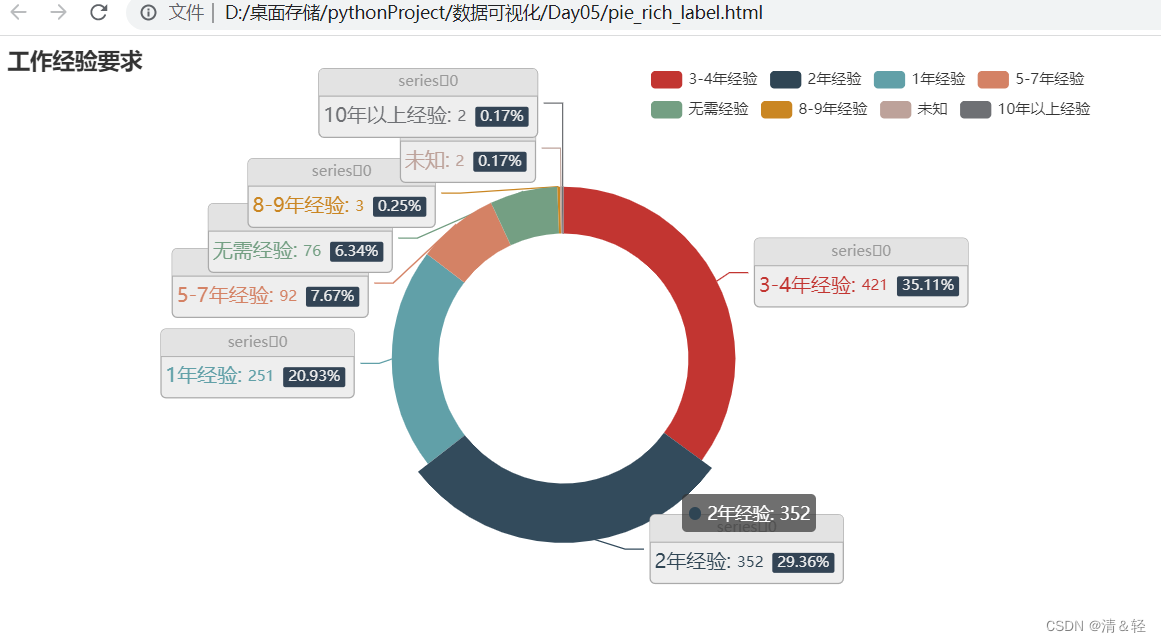
from pyecharts import options as opts
from pyecharts.charts import Pie
import pandas as pd
python_data = pd.read_csv('./testDataPython-2022-05-01_11_48_36.csv')
require_list = []
rl = require_list.append
for i in python_data['招聘要求']:
if '经验' in i:
rl(i.split(' ')[1])
else:
rl('未知')
python_data['招聘要求'] = require_list
require = python_data['招聘要求'].value_counts()
require_list = [list(ct) for ct in require.items()]
print(require_list)
c = (
Pie()
.add(
"",
require_list,
radius=["40%", "55%"],
label_opts=opts.LabelOpts(
position="outside",
formatter="{a|{a}}{abg|}\n{hr|}\n {b|{b}: }{c} {per|{d}%} ",
background_color="#eee",
border_color="#aaa",
border_width=1,
border_radius=4,
rich={
"a": {"color": "#999", "lineHeight": 22, "align": "center"},
"abg": {
"backgroundColor": "#e3e3e3",
"width": "100%",
"align": "right",
"height": 22,
"borderRadius": [4, 4, 0, 0],
},
"hr": {
"borderColor": "#aaa",
"width": "100%",
"borderWidth": 0.5,
"height": 0,
},
"b": {"fontSize": 16, "lineHeight": 33},
"per": {
"color": "#eee",
"backgroundColor": "#334455",
"padding": [2, 4],
"borderRadius": 2,
},
},
),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="工作经验要求"),
legend_opts=opts.LegendOpts(padding=20, pos_left=500),
)
.render("pie_rich_label.html")
)
Pie2
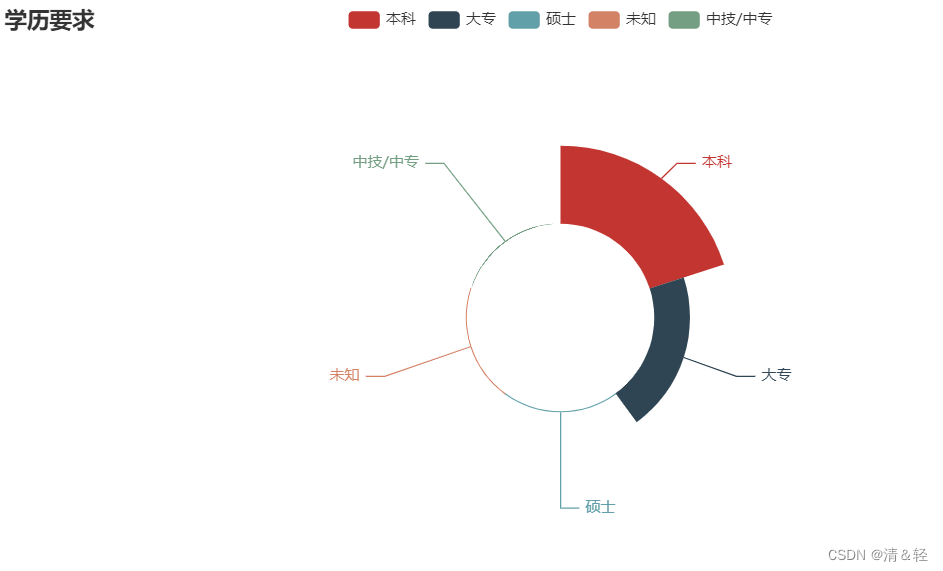
from pyecharts import options as opts
from pyecharts.charts import Pie
import pandas as pd
python_data = pd.read_csv('./testDataPython-2022-05-01_11_48_36.csv')
xueli_list = []
xl = xueli_list.append
for i in python_data['招聘要求']:
if len(i.split(' ')) == 3:
xl(i.split(' ')[2])
else:
xl('未知')
python_data['招聘要求'] = xueli_list
xueli_require = python_data['招聘要求'].value_counts()
xueli_require_list = [list(ct) for ct in xueli_require.items()]
c = (
Pie()
.add(
"",
xueli_require_list,
radius=["30%", "55%"],
rosetype="area",
)
.set_global_opts(title_opts=opts.TitleOpts(title="学历要求"))
.render("pie_rosetype.html")
)
(4).折线图Line
这里对薪资情况进行可视化。
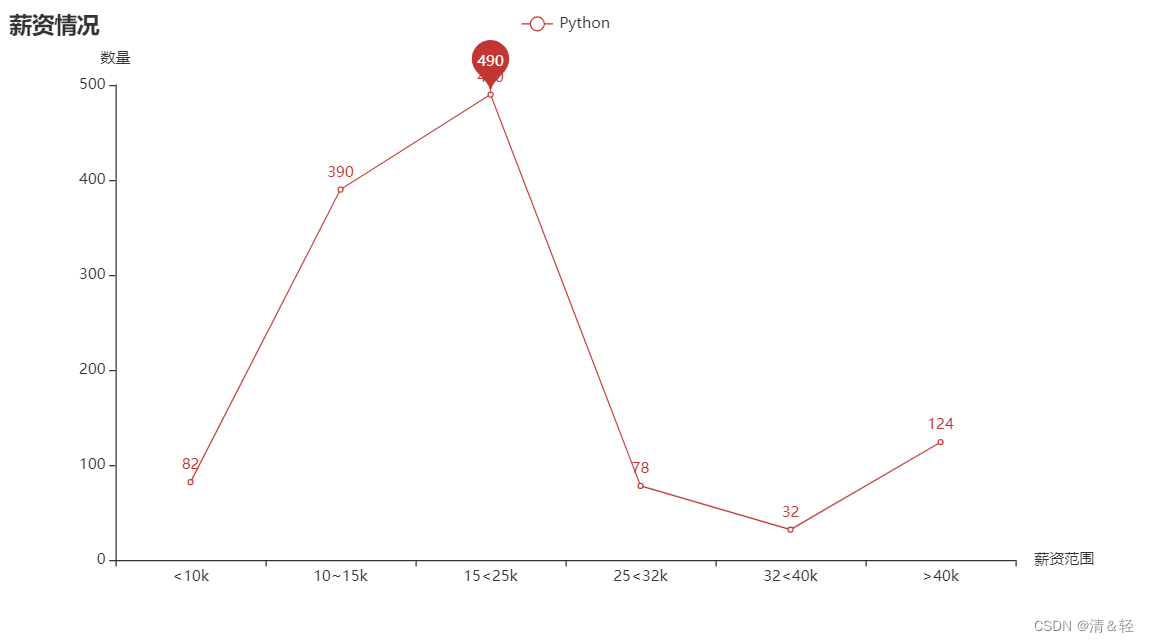
import pandas as pd
import re
python_data = pd.read_csv('./testDataPython-2022-05-01_11_48_36.csv')
sal = python_data['薪资']
xin_zi1 = []
xin_zi2 = []
xin_zi3 = []
xin_zi4 = []
xin_zi5 = []
xin_zi6 = []
for s in sal:
s = str(s)
if '千' in s:
xin_zi1.append(s)
else:
if re.findall('-(.*?)万',s):
s = float(re.findall('-(.*?)万',s)[0])
if 1.0<s<=1.5:
xin_zi2.append(s)
elif 1.5<s<=2.5:
xin_zi3.append(s)
elif 2.5<s<=3.2:
xin_zi4.append(s)
elif 3.2<s<=4.0:
xin_zi5.append(s)
else:
xin_zi6.append(s)
xin_zi = [['<10k',len(xin_zi1)],['10~15k',len(xin_zi2)],['15<25k',len(xin_zi3)],
['25<32k',len(xin_zi4)],['32<40k',len(xin_zi5)],['>40k',len(xin_zi6),]]
import pyecharts.options as opts
from pyecharts.charts import Line
x, y =[i[0] for i in xin_zi],[i[1] for i in xin_zi]
c2 = (
Line()
.add_xaxis(x)
.add_yaxis(
"Python",
y,
markpoint_opts=opts.MarkPointOpts(
data=[opts.MarkPointItem(name="max", coord=[x[2], y[2]], value=y[2])] #name='自定义标记点'
),
)
.set_global_opts(title_opts=opts.TitleOpts(title="薪资情况"),
xaxis_opts=opts.AxisOpts(name='薪资范围'), # 设置x轴名字属性
yaxis_opts=opts.AxisOpts(name='数量'), # 设置y轴名字属性
)
.render("line_markpoint_custom.html")
)
(5).组合图表
最后,将多个html上的图表进行合并成一个html图表。
首先,我们执行下面这串格式的代码(只写了四个图表,自己做相应添加即可)
import pandas as pd
from pyecharts.charts import Bar,Map,Pie,Line,Page
from pyecharts import options as opts
python_data = pd.read_csv('./testDataPython-2022-05-01_11_48_36.csv')
python_data['工作地点'] = [i.split('-')[0] for i in python_data['工作地点']]
city = python_data['工作地点'].value_counts()
city_list = [list(ct) for ct in city.items()]
###柱状图
def bar_datazoom_slider() -> Bar:
c = (
Bar()
.add_xaxis(city.index.tolist()) #城市列表数据项
.add_yaxis("Python", city.values.tolist())#城市对应的岗位数量列表数据项
.set_global_opts(
title_opts=opts.TitleOpts(title="Python招聘岗位所在城市分布情况"),
datazoom_opts=[opts.DataZoomOpts(), opts.DataZoomOpts(type_="inside")],
xaxis_opts=opts.AxisOpts(name='城市'), # 设置x轴名字属性
yaxis_opts=opts.AxisOpts(name='岗位数量'), # 设置y轴名字属性
)
)
return c
# 地图_中国地图(带省份)Map-VisualMap(连续型)
def map_china() -> Map:
import copy
area_data = {}
with open('./中国省份_城市.txt', mode='r', encoding='utf-8') as f:
for line in f:
line = line.strip().split('_')
area_data[line[0]] = line[1].split(',')
province_data = []
for ct in city_list:
for k, v in area_data.items():
for i in v:
if ct[0] in i:
ct[0] = k
province_data.append(ct)
area_data_deepcopy = copy.deepcopy(area_data)
for k in area_data_deepcopy.keys():
area_data_deepcopy[k] = 0
for i in province_data:
if i[0] in area_data_deepcopy.keys():
area_data_deepcopy[i[0]] = area_data_deepcopy[i[0]] + i[1]
province_data = [[k, v] for k, v in area_data_deepcopy.items()]
best = max(area_data_deepcopy.values())
c = (
Map()
.add("Python", province_data, "china")
.set_global_opts(
title_opts=opts.TitleOpts(title="Python招聘岗位——全国分布情况"),
visualmap_opts=opts.VisualMapOpts(max_=int(best / 2)),
)
)
return c
#饼图
def pie_rich_label() -> Pie:
require_list = []
rl = require_list.append
for i in python_data['招聘要求']:
if '经验' in i:
rl(i.split(' ')[1])
else:
rl('未知')
python_data['招聘要求'] = require_list
require = python_data['招聘要求'].value_counts()
require_list = [list(ct) for ct in require.items()]
c = (
Pie()
.add(
"",
require_list,
radius=["40%", "55%"],
label_opts=opts.LabelOpts(
position="outside",
formatter="{a|{a}}{abg|}\n{hr|}\n {b|{b}: }{c} {per|{d}%} ",
background_color="#eee",
border_color="#aaa",
border_width=1,
border_radius=4,
rich={
"a": {"color": "#999", "lineHeight": 22, "align": "center"},
"abg": {
"backgroundColor": "#e3e3e3",
"width": "100%",
"align": "right",
"height": 22,
"borderRadius": [4, 4, 0, 0],
},
"hr": {
"borderColor": "#aaa",
"width": "100%",
"borderWidth": 0.5,
"height": 0,
},
"b": {"fontSize": 16, "lineHeight": 33},
"per": {
"color": "#eee",
"backgroundColor": "#334455",
"padding": [2, 4],
"borderRadius": 2,
},
},
),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="工作经验要求"),
legend_opts=opts.LegendOpts(padding=20, pos_left=500),
)
)
return c
#折线图
def line_markpoint_custom() -> Line:
import re
sal = python_data['薪资']
xin_zi1 = []
xin_zi2 = []
xin_zi3 = []
xin_zi4 = []
xin_zi5 = []
xin_zi6 = []
for s in sal:
s = str(s)
if '千' in s:
xin_zi1.append(s)
else:
if re.findall('-(.*?)万',s):
s = float(re.findall('-(.*?)万',s)[0])
if 1.0<s<=1.5:
xin_zi2.append(s)
elif 1.5<s<=2.5:
xin_zi3.append(s)
elif 2.5<s<=3.2:
xin_zi4.append(s)
elif 3.2<s<=4.0:
xin_zi5.append(s)
else:
xin_zi6.append(s)
xin_zi = [['<10k',len(xin_zi1)],['10~15k',len(xin_zi2)],['15<25k',len(xin_zi3)],
['25<32k',len(xin_zi4)],['32<40k',len(xin_zi5)],['>40k',len(xin_zi6),]]
x, y =[i[0] for i in xin_zi],[i[1] for i in xin_zi]
c = (
Line()
.add_xaxis(x)
.add_yaxis(
"Python",
y,
markpoint_opts=opts.MarkPointOpts(
data=[opts.MarkPointItem(name="MAX", coord=[x[2], y[2]], value=y[2])]
),
)
.set_global_opts(title_opts=opts.TitleOpts(title="薪资情况"),
xaxis_opts=opts.AxisOpts(name='薪资范围'), # 设置x轴名字属性
yaxis_opts=opts.AxisOpts(name='数量'), # 设置y轴名字属性
)
)
return c
#合并
def page_draggable_layout():
page = Page(layout=Page.DraggablePageLayout)
page.add(
bar_datazoom_slider(),
map_china(),
pie_rich_label(),
line_markpoint_custom(),
)
page.render("page_draggable_layout.html")
if __name__ == "__main__":
page_draggable_layout()
执行完后,会在当前目录下生成一个page_draggable_layout.html。
然后我们用浏览器打开,就会看到下面这样,我们可以随便拖动虚线框来进行组合,组合好后点击Save Config就会下载一个chart_config.json,然后在文件中找到它,剪切到py当前目录。
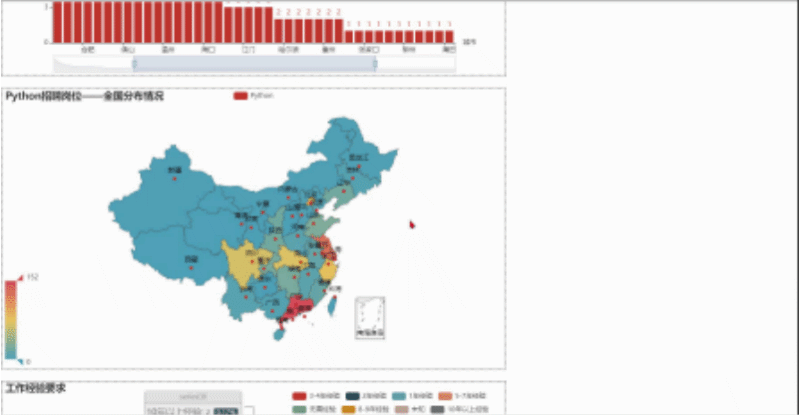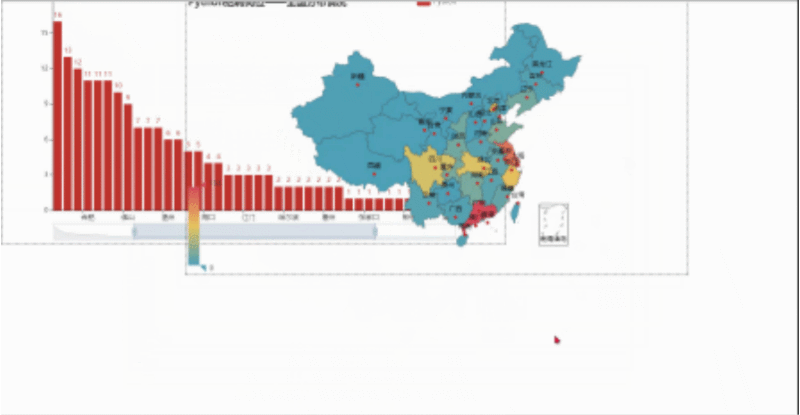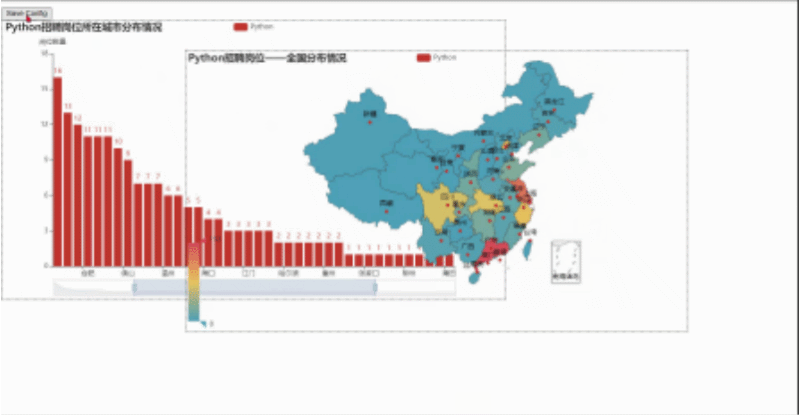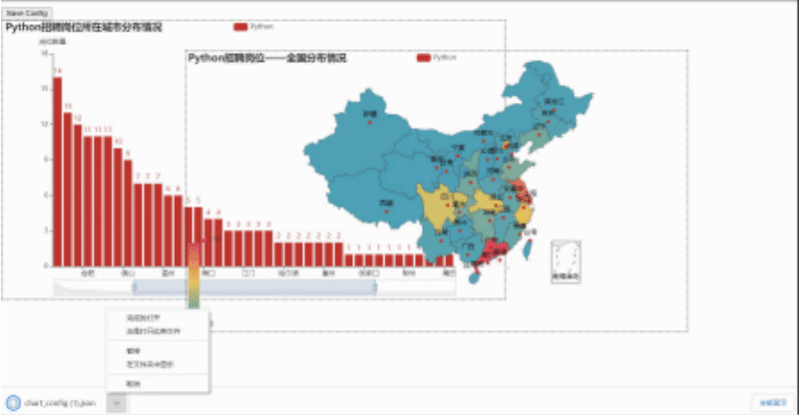
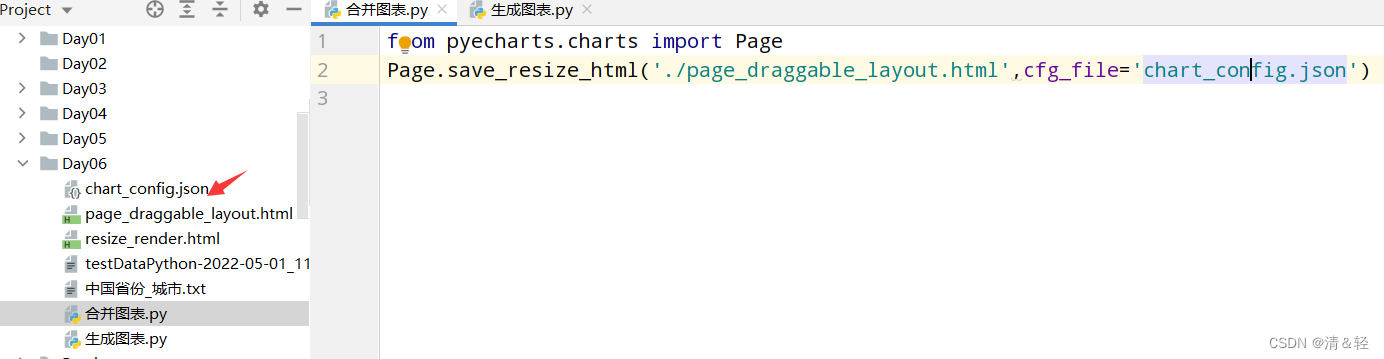
文件放置好后,可以新建一个py文件来执行以下代码,这样就会生成一个resize_render.html,也就完成了。
from pyecharts.charts import Page
Page.save_resize_html('./page_draggable_layout.html',cfg_file='chart_config.json')
最后,点击打开resize_render.html,我们合并成功的图表就是这样啦!
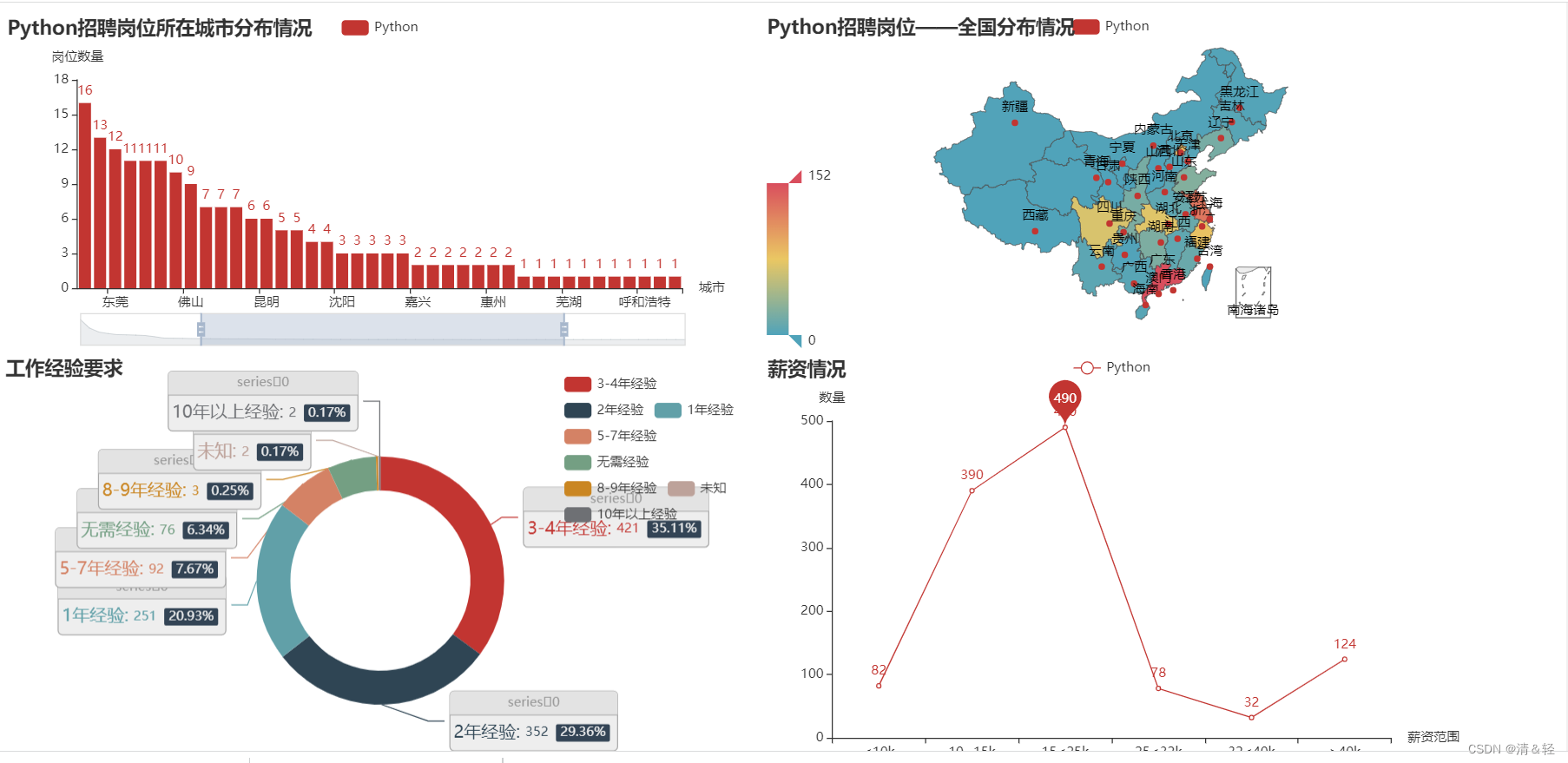
对大家有用的话,记得点赞收藏一下!!!