解码为给定声学观测序列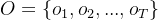 的前提下,找到最有可能出现的词序列
的前提下,找到最有可能出现的词序列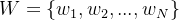 ,由贝叶斯得:
,由贝叶斯得:
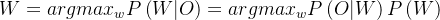
解码的目的:从解码空间中找到一条或多条从初始状态到终止状态的最优路径。
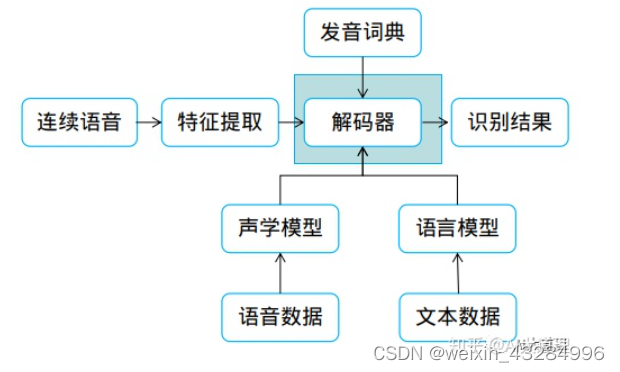
解码器是语音识别系统中的重要一环,主要解码方式有以下几种:
1)动态解码器 (dynamic decoders):动态解码器使用广度优先搜索在原始的搜索网络中同时生成多条假设,并且依靠剪枝算法不会使网络变得太大。
2)有限加权状态转换器 (weighted finte-state transducers ):加权有限状态转换器是使用有限状态自动机算法来表示和优化状态级网络结构,并用最短路径算法搜索得到的图结构。
3)多通道搜索 (multi-pass search):最初使用词内二元语言模型。 可以使用一些简单的模型来生成多个假设;在第一遍获得的 N-best list 或词网格上使用更准确的词间模型重新评分假设。
基于Viterbi的原始动态解码器:
基于Viterbi的原始动态解码器使用广度优先搜索在原始的搜索网络中同时生成多条假设,并且依靠剪枝算法不会使网络变得太大。
动态解码网络仅仅把词典编译为状态网络,构成搜索空间。
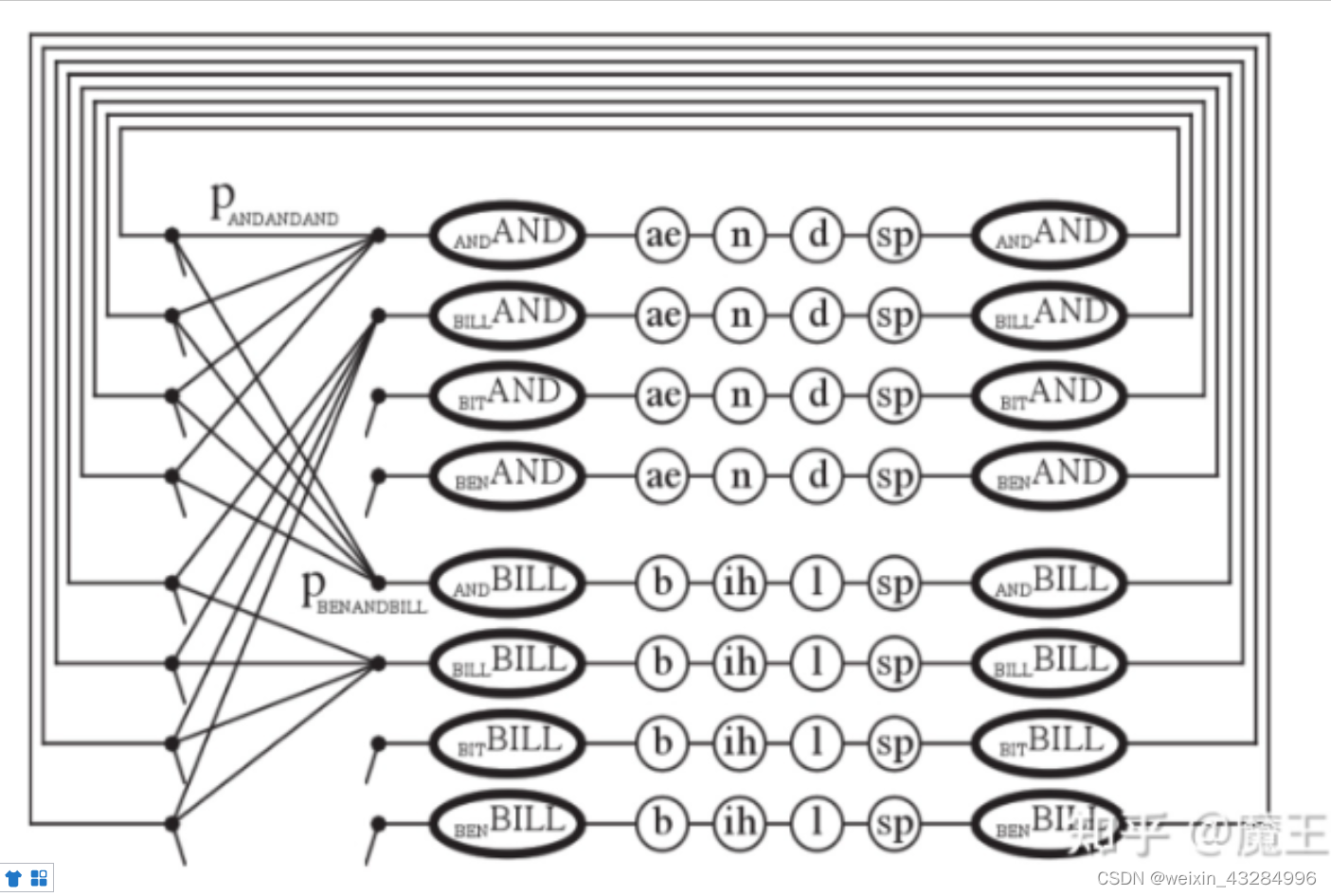
以一个四单词词典来举例,其词典包涵以下四个单词:

构成的搜索空间可以分为:线性词典、树形词典
1)线性词典
首先把词典中的所有单词替换为对应的音素状态序列,并联构成一个并联网络,再结合语言模型决定网络回环连接,如下是使用1-gram语言模型的解码网络示意图:
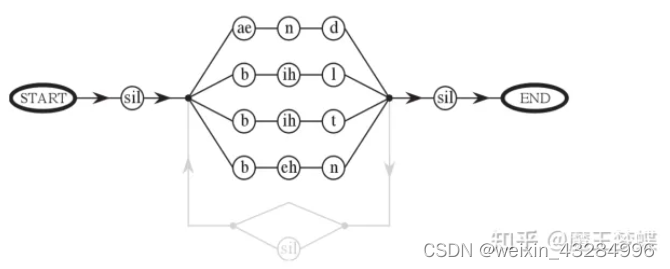
使用2-gram、3-gram语言模型可以排除掉一些生僻组合,从而辅助解码过程剪枝计算,其解码网络示意图分别如下:

其中的 sp 为单词间间隔。
得到有词典构建的并联(回环)网络后,根据观测序列(语音信息)对状态序列进行横向扩展,x 轴为时间, y 轴为状态。
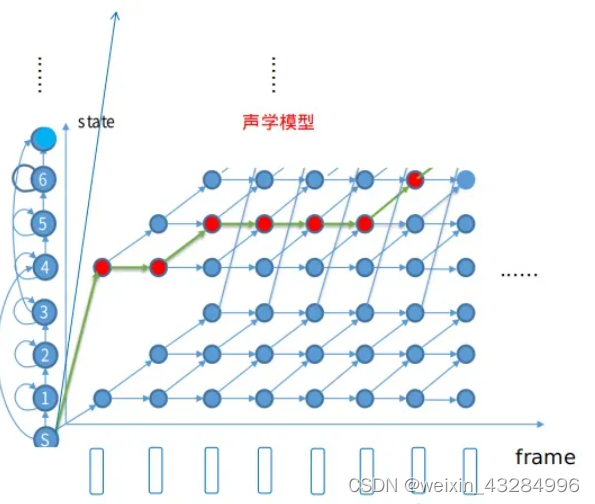
图中,每三个状态代表一个音素。
根据Viterbi算法,随着时间的推移,帧的移动,逐渐对其到最后一个词的最后一个状态,对比每条路径的累计概率,得到最优路径,即最终解码语句,解码结束。
(HMM—解码问题(维特比(Viterbi)、A*、beam search )_weixin_43284996的博客-CSDN博客)
解码过程中可以通过令牌传递( Token Passing)等剪枝算法进行优化。
但可以看出来,上述解码网络是所有单词的音素状态序列并联网络连接而成,如果词汇量很大,存储和计算复杂度都很高。
2)树形词典
为解决线性词典的问题,提出了树形词典。
对每个音素的每个状态建立一个决策树:
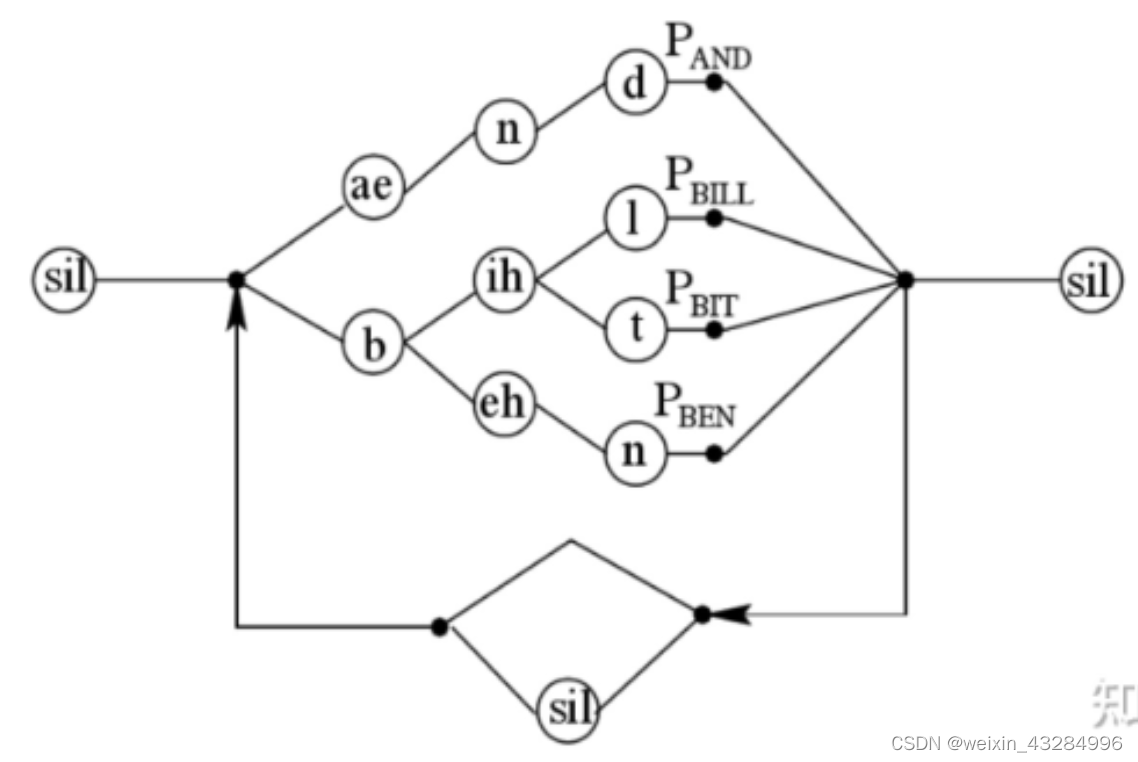
树状结构是根据音素的路径去得到相应的单词,而非线性词典是先估计单词,再由单词进入对应的音素路径。(但是这使得语言模型使用总是在音素路径末端,这可以通过更早引入语言模型?)
由于大量相同状态的节点被合并在一起,因此可以显著降低搜索空间的规模,减少解码过程的运算量。
总结:
基于Viterbi的原始动态解码器对于大词典的解码过程,计算量大,解码速度慢。
为了加速解码速度:
一方面可以进行剪枝处理,在解码中选出最优路径,超过剪枝阈值的路径则直接删除,不再后续运算。
另一方面可以把知识源预先编译成一个静态网络(WFST),在解码中直接使用。
基于WFST的Viterbi静态解码器:
为了加快解码速度,可以把动态知识源提前编译好,形成静态网络,在解码时直接调用。
输入HMM状态序列,直接得到词序列及其相关得分。
用H、C、L、G分别表示上述HMM模型、三音子模型、字典和语言模型的WFST形式。

(WFST简介及网络构建过程可见:加权有限状态转录机(Weighted Finite-State Transducer/WFST)_weixin_43284996的博客-CSDN博客)
此解码器中,声学部分(观测序列到HMM状态序列)还是需要根据输入特征单独计算,其他包涵在HCLG中的信息已经包涵在整个静态网络中,通过网络中转移弧的输入、输出、权重来表示。
由于静态网络已经把搜索空间全部展开,它只需要根据节点间的转移权重计算声学概率和累计概率即可,因此解码速度非常快。
解码过程使用了令牌传播机制Token passing,其实就是viterbi解码的通用版本。
但实际使用过程中,很难保证viterbi解码解码的最优路径即是最合适的输出结果(例如:语言场景变化),故经常用 lattice 保存多种候选的识别结果,以便后续进行其他处理。
基于WFST的Lattice静态解码:
在传统语音识别过程中,声学模型训练通常会占用很多资源,因此声学模型不会频繁的更新,这使得语音识别系统较难快速针对特定场景优化。另一方面,为保证解码效率,对解码图的剪枝是一个必要的步骤,常见的就直接使用beam search。考虑这两个问题便有了Lattice。
在解码时,采用一些剪枝方法,使得最后获得N-best的路径,由这N-best的路径重新进行确定化等操作后得到的WFST就是Lattice。
与HCLG一样,Lattice的输入为HMM状态,输出为单词序列。但在kaldi中,对Lattice的生成和存储做了优化,使其输入输出都是单词序列,并将HMM状态等信息存在transition中,因此,也通常称Lattice为词图或词格。
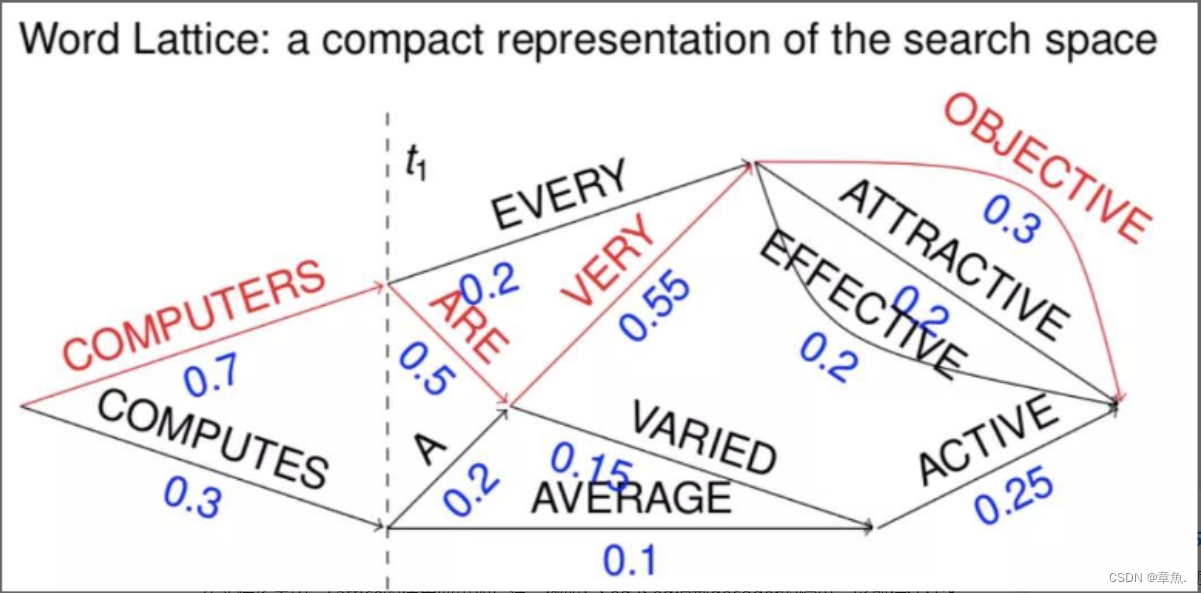
这样语音识别的解码过程就分为两步(two-pass),第一遍解码得到Lattice,第二遍解码在Lattice中进行最短路径搜索得到1-best的解码结果。
具体步骤为:
1)N-best剪枝:原有的 token passing 算法创建新的词链接记录 (word link record, WLR) 时只会保存得分最高即似然概率最大的 token,改进后的算法会保存得分最高的 N 个 token。通过独特的ForwardLink前向链接机制来生成lattice。
ForwardList每帧一个,可以和帧索引建立关联,它记录了Token在发射弧之间的传递,也用链表将当前帧所有状态的所有Token串联在一起。
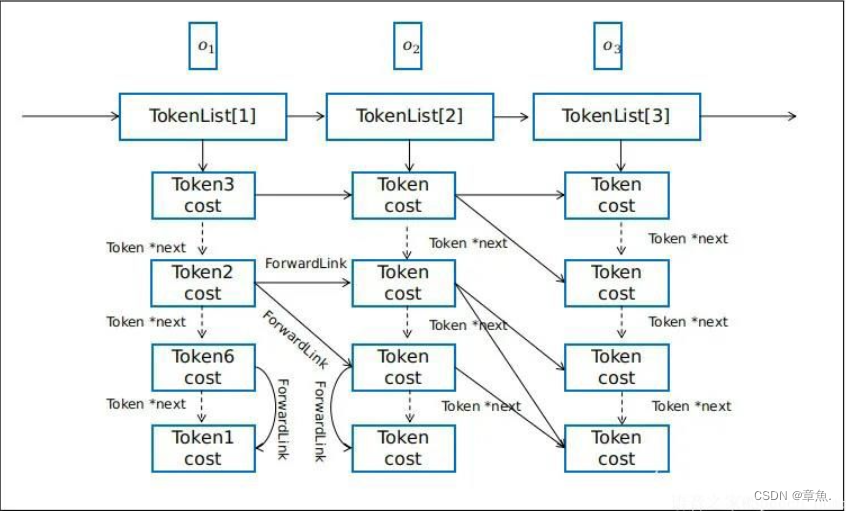
2)构建Lattice:在句末会进行回溯将所有历史信息转换到一个词网格中,这个词网格包含声学模型和语言模型的得分,以及识别出的单词及其对应的时间步,在这样的词网格中就可以找到 N 个最好的路径或假设 (hypotheses)。
3)1-best重新评估:在Lattice对原有的路径重新打分,选出最优路径。在重打分时可以使用更大的语言模型或者与业务相关性更强的模型,这保证了在声学模型不变的情况下,优化了解码效果。
上述解码器的基础上有时还会使用混合静态动态解码器 (hybrid static/dynamic decoders) 来进行优化:
1)Lattice Pruning(晶格修剪)。词网格在生成的时候可能非常大,每个状态都保存了多个 token,但是很大一部分都对最优路径影响不大,所以 lattice 就可以在不降低准确性的前提下进行剪枝,具体方式为,首先找到最优路径及其似然概率,然后对于任意节点或弧线,分别计算其前后向的最大似然概率,即前后向打分,然后相加得到通过该弧线的似然概率作为这条边的后验概率,然后删除后验概率很低的边,以此达到剪枝的目的。
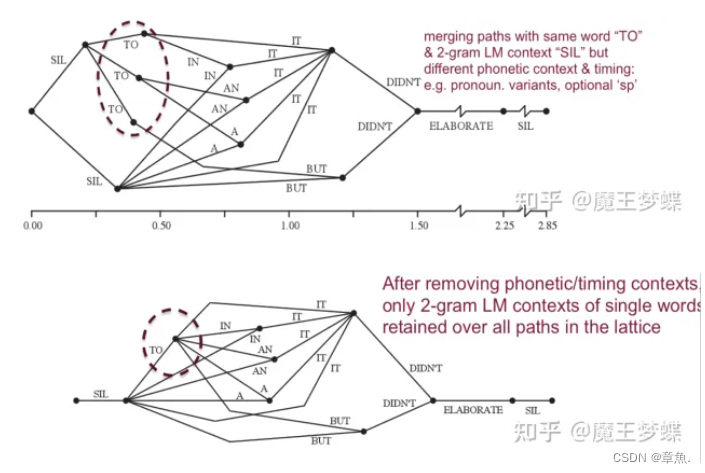
2)Acoustic Model Rescoring(声学模型修改):一个词网格可以作为更复杂声学模型重打分的有限状态限制语法。所以当使用声学模型进行重打分时,原来由于时间以及音素上下文不同而复制的连接弧将被整合,使用一个更小的词网格,下图是单词 "TO" 的弧线被整合后前后 lattice 对比。
3)Language Model Rescoring(语言学模型修改):原始词网格也可以用一个新的语言模型重打分,语言模型重打分不用考虑声学模型的影响,一个最简单的例子就是用三元模型对二元模型生成的 lattice 进行重打分,这就会多引入一些路径,前后对照图如下所示:

4)Confusion Network(混淆网络):生成混淆网络的方法则是先找到最优路径,然后逐步将其他的边对齐添加到混淆网络中,如果添加某条边时超过原网络的长度,仍将该边加入混淆网络并为之前的最优路径添加一条 !NULL 的边。

总结:
解码的目的:从解码空间中找到一条或多条从初始状态到终止状态的最优路径。
基于Viterbi的原始动态解码器使用广度优先搜索在原始的搜索网络中同时生成多条假设,并且依靠剪枝算法不会使网络变得太大。可以使用树状字典代替线性字典,降低空间复杂度。
为进一步提高解码速度,可以把知识源预先编译成一个静态网络,在解码中直接使用。即生成WFST。
在WFST可以使用Viterbi算法的Token passing算法求得最佳路径。
由于不同场景,Viterbi算出的最优路径不一定是最合理的路径,故引入Lattice。选取最优的N-best路径后在重新打分选取最合理的路径。
针对构建的Lattice,还可使用混合静态动态解码器 (hybrid static/dynamic decoders) 来进行优化。