结合机器学习的人口模型能够提高心理健康测量的准确性
导语
这篇研究去年发表在GigaScience [IF:7.658],研究基于MRI数据和社会人口学变量使用机器学习方法构建群体模型从而预测个体的心理健康测量。我在这里做个笔记,顺便分享。这里只介绍方法,主要结果和结论。
Dadi K; Varoquaux G; Houenou J; Bzdok D; Thirion B; Engemann D (2021) Population modeling with machine learning can enhance measures of mental health. GigaScience (October 2021). https//doi.org/10.1093/gigascience/giab071
传送:
https://pubmed.ncbi.nlm.nih.gov/34651172/#affiliation-6
关键术语解释
brain imaging 大脑神经影像,这篇研究主要用到了T1w, dMRI, rs-fMRI
machine learning 机器学习
mental health 心理健康
proxy measures 间接测量,这个词在临床上比较常用可能是
sociodemographic factors 社会人口学因素,在这篇研究里非MRI数据都被看成是社会人口学变量
缩写:
AUC: area under the classification accuracy curve;
ICA: independent component analysis;
ICD-10: International Statistical Classification of Diseases and Related Health Problems, 10th Revision;
MRI: magnetic resonance imaging;
UKBB: UK Biobank;
VIF: variance inflation factors 方差膨胀因子
方法
为了便于理解和重复研究结果,作者在 GitHub 上提供了所有数据分析和可视化源代码 Dadi K, Engemann D. Empirical Proxy Measures. 2021. https://github.com/KamalakerDadi/empirical_proxy_measures
Accessed: September 14, 2021.
Operating system(s): Platform independent
Programming language: Python and R
Other requirements: Python 3.6.8 or higher, R 3.4.3 or higher
License: BSD-3
Software
预处理和模型的建立都基于Python 3.7
MRI影像处理:NiLearn库
机器学习:scikit-learn库
R语言:统计建模和可视化,v3.5.3版
Workflow
图1:方法工作流程:建立和评估proxy measures。我们将多种脑成像模态(A)与社会人口学数据(B)结合起来,以接近与健康有关的生物医学和心理学结构(C),即脑年龄(通过预测年龄评估)、认知能力(通过流体智力测试评估)和报告负面情绪的倾向(通过神经质问卷评估)。我们包括了英国生物库的10,000个被试的影像数据。在成像数据(A)中,我们考虑了与皮质和皮质下体积有关的特征,基于ICA网络的rsfMRI的功能连接,以及来自dMRI的白质纤维束(具体可见表1)。然后,我们将社会人口学数据(B)分为5种不同的变量,这些变量与自我报告的情绪和情感、主要人口统计特征、生活方式、教育和早期生活事件有关(具体可见表2)。我们系统地比较了基于大脑图像、社会人口学特征或两者结合的模型得出的三个目标的预测值(C),以评估这些不同特征的相对贡献。
我们以现实世界的健康行为模式(D),即酒精饮料的数量、运动(代谢当量任务,MET)、睡眠时间和吸烟数量为基准,对proxy measures和目标测量的互补性进行评估。proxies 和目标之间的潜在积加作用是用多元线性回归来衡量的。
我们在50%的数据(随机抽取,训练集)上使用蒙特卡洛交叉验证(100 splits)建立了模型。使用另外50%的数据(测试集)作为完全独立的样本评价模型,评估了泛化和健康影响(见 "统计分析 "部分)。学习曲线(Learning curves)表明,这种分割一半的方法为模型构建提供了足够的数据(图1-图s1)。
学习曲线(learning curve)可以用来来判断模型状态,判断是否过拟合或欠拟合,可参考https://blog.csdn.net/geduo_feng/article/details/79547554
数据集
UKbiobank (UKBB) 数据库是迄今为止最广泛的大规模公开访问是数据库,旨在研究普通成年人群中健康状态(outcome)的决定因素。它拥有50万名40-70岁个体的广泛数据,涵盖丰富的表型、健康相关信息、脑成像和遗传数据[1]。被试被邀请进行重复评估,其中一些包括MRI。例如,在初始评估(baseline)中进行的认知测试也在后续访问中进行评估。这使得我们可以获得许多被试≥1次的数据。
[1] Collins, R. (2012). What makes UK Biobank special?. Lancet (London, England), 379(9822), 1173-1174.
数据共享
本文结果和数字的汇总数据可通过GigaScience数据库和 "empirical_proxy_measures "代码库(上边的链接)获得。将来,从这项工作的预测模型中获得的个人层面的proxy measures将按照BBUK的规定进行共享。如果你想获取BBUK的数据,可以去他们官网注册,写一份申请表,说明你的研究计划摘要,你需要的数据包以及数据包里包含的数据和预处理/处理后得到的变量,然后才能获得数据。
UK Biobank website: http://www.ukbiobank.ac.uk
UK Biobank access procedure:
https://www.ukbiobank.ac.uk/enable-your-research/apply-for-access
被试
在UKBB人群的总规模中,我们发现有个包含11,175名被试的数据包,它包含两次MRI数据[2]。其社会人口学变量是在第二次MRI扫描中自我报告的测量到的。其中51.6%的女性(5,572)和48.3%的男性(5,403),年龄范围为40-70岁(Mean[SD]=55[7.5]岁)。用于模型训练的数据是通过随机分半的程序选择的,得到了5,587人。剩余的被试作为测试集,训练集和测试集是不相重叠的。
这里随机分半用到的是scikit-learn中train_test_split这个函数,可参考https://blog.csdn.net/qq_39355550/article/details/82688014
或者https://blog.csdn.net/qq_39355550/article/details/82688014
为了进行基于社会人口学特征、大脑数据以及其组合的模型之间的比较,我们只考虑有MRI扫描的被试。1)对于年龄和流体智力,我们的随机分半程序得到了N=4,203的训练集和N=4,157的测试集。2)神经质,可用的大脑图像较少,最终得到N=3,550的训练集,N=3,509的测试集。
[2] Miller KL, Alfaro-Almagro F, Bangerter NK, et al. Multimodal population brain imaging in the UK Biobank prospective epidemiological study. Nat Neurosci. 2016;19 (11):1523–36.
数据采集
社会人口学数据(非影像学)是通过触摸屏调查问卷进行的自我报告测量来收集的,并辅以口头访谈、体检、生物采样和影像数据。MRI数据是用西门子Skyra 3T获取,使用的是标准的西门子32通道射频接收头线圈。我们考虑了3种MRI模态,因为每一种模式都可能捕捉到独特的神经生物学细节:结构像(sMRI/T1)、静息态功能像(rs-fMRI)和弥散像(dMRI)。
目标测量(Target measures)
作为我们建立脑龄模型的目标测量,我们使用被试基线测试采集的年龄 (UKBB code “21022-0.0”)。
流动智力是使用一种认知成套测验评估的,旨在测量一个人解决需要逻辑和抽象推理的新问题的能力。在UKBB中,流体智力测试(UKBB code “20016-2.0”) 包括13个逻辑和推理问题,通过触摸屏进行测试,记录每个问题在2分钟内的反应。每个正确的答案为1分,共13分。
神经质 (UKBB code “20127-0.0”) 是用修订后的艾森克人格问卷(EPQ-N)的较短版本测量的,包括12个题目。神经质是在UKBB的基线访问中评估的。分数在0-12之间,概括了体验负面情绪的应对倾向。
社会人口统计数据
在本研究中,我们把非成像变量泛指为社会人口学特征(不包括流体智力和神经质)。为了从社会人口学特征中接近潜在的建构,我们包括了86个变量(表S7),这是反映每个被试的人口学和社会因素的变量集合,即性别、年龄、出生日期和月份、体重指数、种族、早期生活中的暴露(如母乳喂养、出生前后母亲吸烟、小时候被收养)、教育、生活方式相关的变量(如职业、家庭家庭收入、家庭人口数量、吸烟习惯)和心理健康变量。所有这些数据都是自我报告的。然后,我们将这86个变量分配到5组:(1)情绪和情感,(2)主要人口特征,如年龄和性别,(3)生活方式,(4)教育,以及(5)早期生活。然后我们计算了所有86个变量之间的相关,以确保内部一致性(图S1)。
缺失值处理:每个变量有不同数量的缺失值,其中一部分缺失值与被试的生活习惯有关,如吸烟和心理健康问题。为了处理这种缺失值,这里使用填补法(imputation )[3]处理数据缺失值,我们用变量的已知部分计算出的中值来逐列替换缺失信息。随后,我们在下游分析中加入了一个indicator,以说明是否存在填补的数值。这种填补法非常适用于预测模型[4]。
这里说的填补法是 sklearn中的 中值填补法,SimpleImputer函数实现的,可参考https://zhuanlan.zhihu.com/p/83173703?from_voters_page=true
然后提到的indicator 是用Missingindicator,它用于将数据集转换为相应的二进制矩阵,以指示数据集中是否存在缺失值,可参考https://blog.51cto.com/u_15127666/3285875
[3] Little RJA, Rubin DB. Statistical Analysis with Missing Data. New York, NY: Wiley; 1986.
[4] Josse J, Prost N, Scornet E, et al. On the consistency of supervised learning with missing values. 2019. Working paper or preprint.
图像处理生成机器学习的表型(特征)
MRI数据的预处理是由UKBB成像团队进行的。下面,我们简要介绍一下我们在已经预处理的输入基础上使用的自定义处理步骤。
结构像Structural MRI
这类对T1加权脑图像的数据分析涉及到灰质区的形态测量,即对ROI区域内的大脑结构和组织类型的大小(size)、体积(volume)及其在大脑疾病条件或行为下的变化进行量化。例如,灰质区域在一生中的体积变化与大脑老化、一般智力和大脑疾病有关。ROI包括皮质和皮质下结构和小脑区域,最终得到157个sMRI特征,包括全脑和灰质的体积以及大脑皮质下结构。所有这些特征都是由UKBB脑成像团队预先提取的,是数据下载的一部分。我们将这些特征与自定义fMRI特征结合起来进行预测分析(特征联合)。
弥散像Diffusion-weighted MRI
dMRI能够沿着水分子的主要扩散方向识别白质束,以及不同灰质区域之间的连接。对这些通过白质的局部解剖连接的研究与理解大脑疾病和功能组织有关。我们纳入了432个dMRI白质骨架特征,包括FA(各向异性,fractional anisotropy)、MO(张量模式,tensor mode)、MD(平均扩散率,mean diffusivity)、ICVF(细胞内体积分数,intra-cellular volume fraction)、ISOVF(各向同性的体积分数,isotropic volume fraction)和OD(方向分散指数,orientation dispersion index),这些特征是根据从神经解剖学中提取的许多脑白质结构建模的(就是用TBSS方法)。我们所包含的骨架特征来自于UKBB脑成像团队提供的134类,我们使用了这些特征,没有做任何修改。
功能像Functional MRI
基于独立成分分析(ICA)提取的时间序列的FC特征,在UKBB rfMRI数据上提取了55个代表各种大脑网络的成分,其中包括默认模式网络default mode network、拓展默认模式网络extended default mode network、带状盖网络cingulo-opercular network、执行控制 executive control和注意网络 attention network、视觉网络visual network和感觉运动网络sensorimotor network。我们用网络间的协方差来测量功能连接(也就是用协方差矩阵来表示FC)。我们使用Ledoit-Wolf缩减法估计协方差矩阵。为了说明协方差矩阵在一个特定的流形上,即一个弯曲的非欧几里得空间,我们使用切空间嵌入将矩阵转化为欧几里得空间。为了进行预测建模,我们将协方差矩阵的下三角部分矢量化为1485个特征。这些步骤是用NiLearn进行的。
比较预测模型和近似目标测量
基于影像的模型
Imaging-based models
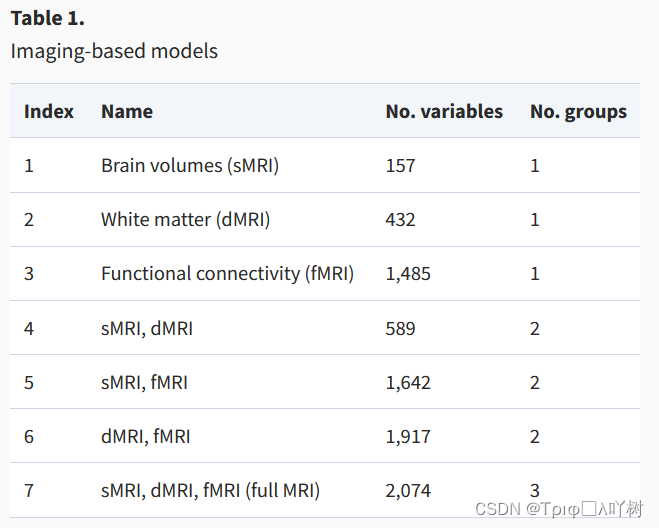 首先,我们构建基于3种MRI模态的详尽组合的纯基于成像的模型(见表1的概述)。这使我们能够研究MRI模式之间的潜在重叠和互补性。初步分析显示,结合所有的MRI数据可以得到合理的结果,对于MRI模式的特定组合没有明显的缺点(图3-图S1);因此,为了简单起见,我们在随后的分析中只关注完整的MRI模型(包含2074个特征)。
首先,我们构建基于3种MRI模态的详尽组合的纯基于成像的模型(见表1的概述)。这使我们能够研究MRI模式之间的潜在重叠和互补性。初步分析显示,结合所有的MRI数据可以得到合理的结果,对于MRI模式的特定组合没有明显的缺点(图3-图S1);因此,为了简单起见,我们在随后的分析中只关注完整的MRI模型(包含2074个特征)。
社会人口学模型
Sociodemographic models
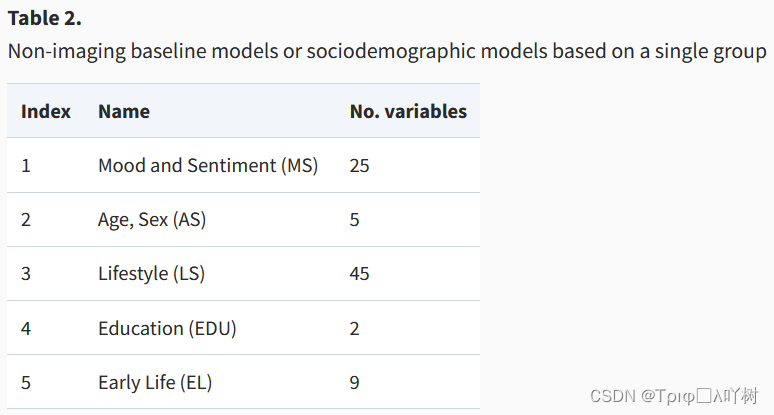 我们根据不同类型的社会人口变量的非详尽组合组成了预测模型。为了研究每一类社会人口学投入的相对重要性,我们进行了系统的模型比较。我们特别感兴趣的是研究早期生活因素与诸如教育等较近期生活事件相关的因素以及诸如情绪、情感和生活方式等与当前环境相关的因素的相对贡献。
我们根据不同类型的社会人口变量的非详尽组合组成了预测模型。为了研究每一类社会人口学投入的相对重要性,我们进行了系统的模型比较。我们特别感兴趣的是研究早期生活因素与诸如教育等较近期生活事件相关的因素以及诸如情绪、情感和生活方式等与当前环境相关的因素的相对贡献。
结合影像和社会人口学的模型
Combined imaging and sociodemographic models
在下一步,我们对与大脑相关的信息如何在这些社会人口模型中相互作用感兴趣。例如,一个人的年龄或教育水平等信息可能为大脑图像增加重要的背景信息。因此,我们考虑了表2中每个模型的替代变体,包括所有与MRI有关的特征(2074个额外的特征)。
预测模型
Predictive model
线性模型被推荐为神经影像研究中的默认选择],特别是当数据集包括<1,000个数据点时。这项研究根据多类异质输入数据,以数千个数据点为基础,对不同的基本机制产生的目标进行了近似分析。因此,我们选择了非参数随机森林算法,该算法可以很容易地应用于不同单位的数据,用于非线性回归和分类,以平均平方误差作为杂质标准。为了改善计算时间,我们将树的深度固定为250棵,这个超参数通常不会被调整,而是设置为一个宽松的数字,因为性能超过一定数量的树就会趋于平稳。初步分析表明,额外的树不会导致性能的大幅提高。我们使用嵌套交叉验证法(5倍网格搜索)来调整树的深度以及考虑分割的变量数量(考虑的超参数的完整列表见表3)。
随机森林是以决策树为基本分类器的一个集成学习模型,它包含多个由Bagging集成学习技术训练得到的决策树,当输入待分类的样本时,最终的分类结果由多个决策树的输出结果投票决定,随机森林克服了决策树过拟合问题,对噪声和异常值有较好的容忍性,对高维数据分类问题具有良好的可扩展性和并行性。可参考https://blog.csdn.net/sinat_32043495/article/details/78728232
这里随机森林使用RandomForestClassifier实现,网格搜索用来自动调参,这里使用GridSearchCV函数
> estimator = RandomForestClassifier(n_estimators=250, criterion='gini',
n_jobs=-1, verbose=1, random_state=0)
n_estimators:这是森林中树木的数量,即基评估器的数量。这个参数对随机森林模型的精确性影响是单调的,n_estimators越大,模型的效果往往越好。但是相应的,任何模型都有决策边界,n_estimators达到一定的程度之后,随机森林的精确性往往不在上升或开始波动,并且,n_estimators越大,需要的计算量和内存也越大,训练的时间也会越来越长。对于这个参数,我们是渴望在训练难度和模型效果之间取得平衡。
n_estimators的默认值在现有版本的sklearn中是10,但是在0.22版本中,这个默认值被修正为100。这个修正显示出了使用者的调参倾向:要更大的n_estimators。
可参考https://blog.csdn.net/weixin_44376037/article/details/122131763
> grid_search = GridSearchCV(pipeline, param_grid=param_grid,
cv=5, verbose=2, n_jobs=-1

分类
Classification analysis
我们还对连续目标进行了分类分析。根据Gelman和Hill的建议,我们对目标进行了离散变量编码,得到基于第33和第66百分位数的极端组(每组的分类样本数见表4)。这种选择避免了包括接近平均结果的样本,因为对于这些样本,输入数据可能是不明确的。我们特别想了解,当走向分类极端群体时,模型性能是否会增加。在这个分析中,我们考虑了所有3种类型的模型(全MRI 2,074个基于成像的模型的特征;所有社会人口学特征变量,共86个变量,全MRI和所有社会人口学特征的组合,共2,160个变量)。在预测年龄时,我们从所有的社会人口学变量中排除了年龄和性别等变量,然后得到了总共81个变量。为了评估分类分析的性能,我们使用受试者操作特征(ROC)曲线的曲线下面积(AUC)作为评价指标。
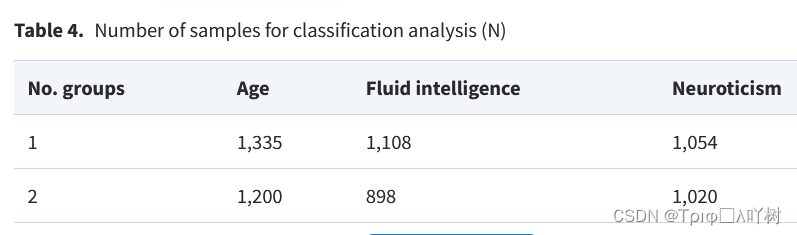
模型发展和泛化测试
泛化能力(generalization ability)是指机器学习算法对新鲜样本的适应能力。学习的目的是学到隐含在数据对背后的规律,对具有同一规律的学习集以外的数据,经过训练的网络也能给出合适的输出,该能力称为泛化能力。
在进行任何实证工作之前,我们产生了2个随机的数据分区,1个验证数据集用于模型的构建,使用经典统计分析研究样本外关联的一个泛化数据集(held-out set)。
为了进行交叉验证,我们按照蒙特卡洛再抽样方案(也被称为洗牌分法)将验证集细分为100个训练和测试split,其中10%的数据用于测试。为了比较基于配对测试的模型性能,我们在所有模型中使用了相同的split。使用小提琴图(图3和图4)总结了非正式推理的Split-wise testing performance。对于泛化测试,从每个交叉验证分割的所有100个模型中产生对held-out数据的预测。
在held-out的数据集上,独特的subject-wise预测是通过跨褶皱和偶尔的重复预测获得的,由于蒙特卡洛抽样,每个被试可能产生多个预测(我们在计算前确保在100个CV分割中,所有被试的预测都可用)。这样的策略被称为CV-bagging,可以提高性能和结果的稳定性(使用CV-bagging可以解释为什么在图3和图4以及图3-图S1中,与验证测试中的交叉验证相比,在held-out组上的性能有时略好)。由此产生的平均预测结果产生了图2中健康相关行为分析的最终proxy measures,并在图3和图4中报告。
统计分析
Resampling statistics for model comparisons on the held-out data
为了评估观察到的模型性能的统计学意义和模型之间的性能差异,我们计算了未用于模型构建的held out 泛化数据上的性能指标的再抽样统计。一旦通过平均来自验证集的每个折叠的预测(CV-bagging)在held-out的泛化数据上获得独特的subject预测,我们计算了在held-out的数据上观察到的测试统计量,即回归的R2分数和分类的AUC分数。
集成学习将多个弱学习器进行结合,通过对样本加权、学习器加权,获得比单一学习器显著优越的泛化性能的强学习器。
Bagging[Breiman,1996]是并行式集成学习方法最著名的代表。给定包含 m 个样本的数据集,我们先随机取出一个样本放入采样集中,再把该样本放回初始数据集,使得下次采样时该样本仍有可能被选中,这样,经过 m 次随机采样操作,我们得到含 m 个样本的采样集,初始训练集中有的样本在采样集里多次出现,有的则从未出现。
Bagging的策略如下: -
- 从样本集中重采样(有重复的)选出n个样本
- 在所有属性上,对这n个样本建立分类器(ID3、C4.5、CART、SVM、Logistic回归等)
- 重复1、2 m 次,即获得了 m 个分类器
- 将数据放在这m个分类器上,最后根据这 m 个分类器的投票结果,决定数据属于哪一类。
随机森林[Breiman,2001a]则是Bagging的一个扩展变体。其在以决策树为基学习器构建 Bagging 集成的基础上,进一步在决策树的训练过程中引入了随机属性选择。
随机森林的策略如下:
- 从样本集中用Bootstrap采样选出n个样本
- 从所有属性中随机选择k个属性,选择最佳分割属性作为节点建立CART决策树
3.重复1、2两个步骤,即建立了m棵CART决策树
4.m个CART形成随机森林,通过投票表决结果,决定数据属于哪一类
参考:https://blog.csdn.net/dkjkls/article/details/79955464
Baseline comparisons
为了获得基线比较的P值(“一个给定模型的预测性能是否可以用偶然chance来解释?”),我们对目标进行了10,000次置换,然后在每次迭代中重新计算测试统计量。然后,P值被定义为无效分布下的测试统计量大于观察到的测试统计量的概率。为了计算不确定性区间,我们使用了non-parametric bootstrap法,在重复取样10000次后重新计算测试统计量,并报告所得分布的2.5和97.5百分位。
模型间成对比较 Pairwise comparisons between models
对于模型的比较,我们考虑任何2个模型之间的R2或AUC的样本外差异。为了获得模型比较的P值(“2个给定模型之间的预测性能差异是否可以解释为偶然?”),对于每个测试数据点,我们将模型A和模型B的预测随机调换10,000次,然后在每次迭代中重新计算测试统计。我们省略了所有只有一个被比较的模型的预测值的情况。然后,P值被定义为无效分布下的测试统计量的绝对值大于观察到的测试统计量的绝对值的概率。绝对值被认为是考虑到了两个方向的差异。不确定性区间是通过计算基于10,000次迭代的non-parametric bootstrap分布的2.5和97.5百分位数得到的。在这里,模型A和模型B的预测采用相同的重采样指数进行重采样,以确保有意义的成对差异。
Out-of-sample association between proxy measures and health-related habits
这part真看不懂
Computation of brain age Δ and de-confounding
首先计算大脑年龄Δ(公式1),即预测年龄和实际年龄之间的差异。
由于年龄预测很少是完美的,残差仍会包含与年龄有关的方差,当把脑年龄与感兴趣的结果(如睡眠时间)联系起来时,这通常会导致脑年龄偏倚。为了减轻年龄相关信息在统计模型中的leakage,我们使用了与前人研究和[公式6-8]一致的去混淆程序,包括通过对年龄的二次项进行多元回归,对感兴趣的测量(如睡眠时间)进行残差。为了尽量减少对保留数据的计算,我们首先在验证集上训练了一个与年龄有关的分数模型,然后为保留的泛化数据推导出一个去混淆的预测器。由此产生的对被保留数据中的变量的去混淆程序相当于通过在验证数据上应用以下二次拟合,从感兴趣的指标(如睡眠时间)中计算出一个age-residualized predictor measure-resid。
 我们对所有目标测量进行了此程序,以研究不受年龄影响的相关性。
我们对所有目标测量进行了此程序,以研究不受年龄影响的相关性。
Health-related habits regression
然后,我们用多元线性回归法计算了感兴趣的proxy measures与健康相关习惯之间的joint association(表5)。为简单起见,我们将所有的脑成像和所有的社会人口学变量结合起来(图3,图3-图S1,图S2,图3)。随后的模型可以表示为
 其中deconfounder 在公式2里得到。在模型拟合之前,省略了输入缺失的行。为便于比较,我们对所有结果和所有预测因素采用标准化缩放standard scaling。
其中deconfounder 在公式2里得到。在模型拟合之前,省略了输入缺失的行。为便于比较,我们对所有结果和所有预测因素采用标准化缩放standard scaling。
Parametric bootstrap是不确定性估计的自然选择,因为我们使用的是标准多元线性回归,它为数学量化其隐含的概率模型提供了一个明确的程序。使用arm包的 "sim "函数进行计算。这个程序可以被直观地视为在统一先验的假设下,从多元线性回归模型的后验分布中得出的结果。为了与以前的分析保持一致,我们计算了10,000次抽样。

 其中deconfounder-FI是流体智力的deconfounder,deconfounder-N是神经质的deconfounder。
其中deconfounder-FI是流体智力的deconfounder,deconfounder-N是神经质的deconfounder。

结果
Validity of Proxy Measures
Complementing the original measures at characterizing real-life health-related habits
为了估计年龄、流体智力和神经质,我们对社会人口数据和大脑图像进行了随机森林回归分析。这些数据分为模型构建的验证数据和独立数据的样本外预测的一般化推论统计学。我们的研究结果表明,一些关于心理结构的信息可以从一般输入中收集,而不是专门用来测量这些结构,如大脑图像和社会人口变量。由此产生的proxy measures可以被视为心理测度的粗略近似,但它们仍然可以捕获目标结构的基本方面。为了探究代理测量的外部效度,我们使用let-out的数据来调查它们与现实世界行为的联系,例如睡眠、体育锻炼、酒精和烟草消费。为了将这些健康行为与我们的proxy measures联系起来,我们使用多个线性回归将它们分别建模为预测脑龄 Δ、流体智力和神经质的加权总和。为了避免循环,我们使用了所有proxy measures的样本外预测。
估计的回归系数(部分相关)显示了proxy measures与健康相关行为之间的互补关系(图2)。如果孤立地考虑proxy measures,也会出现类似的模式(图2-图S1)。与其他proxy measures相比,脑龄Δ的升高与酒精消费的增加有关(图2,第一行)。体育锻炼的水平与所有3个预测目标都有一致的联系,这表明有additive effect(图2,第二行)。对于流体智力来说,这个结果从健康的角度来看是反直觉的,可能意味着更高的测试分数显示了更多的久坐的生活方式。睡眠时间的增加一直伴随着大脑年龄Δ的升高,但预测的神经质水平较低(图2,第三行)。这似乎是反直觉的,但这是以神经质与睡眠时间呈负相关为条件的。流动智力方面没有出现一致的影响。吸烟的数量与所有预测的目标都有独立的联系(图2,最后一行)。强化吸烟与大脑年龄Δ和神经质的升高有关,但流体智力较低。
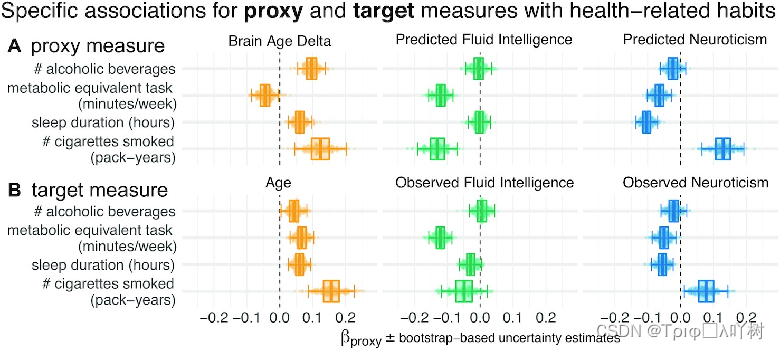 由于只考虑了脑年龄的Δ(预测年龄和实际年龄之间的差异),并且应用了特定年龄的去核,所以这3种proxy measures方法很难在平等的基础上比较。大脑年龄Δ确实是标准做法,在理论上是合理的,因为年龄是在一个度量衡上,预测值和测量值之间的差异有明确的意义。而对于心理测量法所隐含的具有序数尺度的变量,这种差异就不太明显了。其次,年龄对几乎所有的生物医学实体都有普遍的影响,这就促使我们要控制它对代理测量的影响。为了排除proxy measures与健康相关行为的差异是由这种方法上的不对称性所驱动的可能性,我们重复了图2的主要分析,首先,使用预测的年龄而不计算Δ(图2-图S2),其次,引入流体智力和神经质的额外解基因素(图2-图S3)。结果模式几乎没有变化,证实了解释是稳健的。
由于只考虑了脑年龄的Δ(预测年龄和实际年龄之间的差异),并且应用了特定年龄的去核,所以这3种proxy measures方法很难在平等的基础上比较。大脑年龄Δ确实是标准做法,在理论上是合理的,因为年龄是在一个度量衡上,预测值和测量值之间的差异有明确的意义。而对于心理测量法所隐含的具有序数尺度的变量,这种差异就不太明显了。其次,年龄对几乎所有的生物医学实体都有普遍的影响,这就促使我们要控制它对代理测量的影响。为了排除proxy measures与健康相关行为的差异是由这种方法上的不对称性所驱动的可能性,我们重复了图2的主要分析,首先,使用预测的年龄而不计算Δ(图2-图S2),其次,引入流体智力和神经质的额外解基因素(图2-图S3)。结果模式几乎没有变化,证实了解释是稳健的。
剩下的一个问题是,与原来的目标测量相比,proxy measures是否带来了额外的价值。这些原始的目标测量与健康行为显示出类似的关联,在大多数情况下具有相同的标志(图2B)。同时,随之而来的模式更加嘈杂,这表明根据经验得出的代理措施与健康行为产生了更大的关联。这种推论可能很难做出,因为目标和proxy指标之间的差异并不总是容易从视觉上确定。为了实施更严格的统计方法,我们建立了每个各自的健康相关习惯的综合模型,其中我们同时使用所有的代理指标(预测年龄、预测流体智力、预测神经质)和所有目标(年龄、流体智力、神经质)作为预测因素(图2-图S4)。结果显示,在3个目标领域和4个健康习惯中,proxy measures和目标变量具有系统的相加效应。这些趋势被各自线性模型的假设检验很好地捕捉到(补充表S3)。由于目标和proxy measures可能在系统上相互关联,多重共线性可能会破坏这些推论。对方差膨胀因子(VIF)的检查–该指标揭示了一个给定的预测因子被其他预测因子的线性组合所接近的程度–有利于低到中等程度的多重共线性(补充表S4)。事实上,所有的VIF值都在3到1之间,而通常来说,大于5或10的值被认为是病态共线性的阈值。这表明模型的推论在统计学上是合理的。
The relative importance of brain and sociodemographic data depends on the target
在第二步中,我们调查了由大脑信号和不同的社会人口因素建立的proxy measures对3个目标的相对性能:年龄、流体智力和神经质。在社会人口学变量中,每个目标都有一个区块解释了大部分的预测性能(图3,虚线)。结合所有的社会人口学变量并没有导致明显的增强(图3-图S2)。对于年龄的预测,与当前生活方式有关的变量显示出迄今为止最高的性能。在流体智力方面,教育程度迄今表现最好。在神经质方面,情绪和情感明显表现出最强的性能。
 结合核磁共振成像和社会人口学特征,在所有4个变量块中系统地增强了年龄预测(图3实体轮廓和补充表S1)。脑成像特征对预测流体智力或神经质的好处不太明显。对于流体智力,脑成像数据导致了统计意义上的性能改善,然而,效果大小很小(补充表S1)。对于神经质,包括大脑图像和社会人口学特征没有出现系统的好处(补充表S1,底行)。然而,在所有3个目标中,大脑数据足以在统计上显著接近目标测量(补充表S5)。
结合核磁共振成像和社会人口学特征,在所有4个变量块中系统地增强了年龄预测(图3实体轮廓和补充表S1)。脑成像特征对预测流体智力或神经质的好处不太明显。对于流体智力,脑成像数据导致了统计意义上的性能改善,然而,效果大小很小(补充表S1)。对于神经质,包括大脑图像和社会人口学特征没有出现系统的好处(补充表S1,底行)。然而,在所有3个目标中,大脑数据足以在统计上显著接近目标测量(补充表S5)。
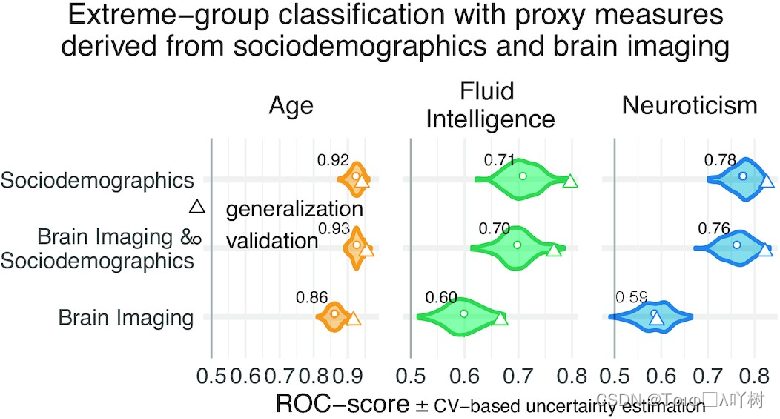
心理测量通常没有物理量表和单位。在实践中,临床医生和教育工作者使用它们与特定的阈值进行决策。为了研究连续回归之外的经验定义的proxy measures,我们按照Gelman和Hill关于离散变量编码策略的建议,对使用第33位和第66位百分位数对目标进行离散化得到的极端群体进行二元分类。此外,我们用分类准确度曲线下的面积(AUC)来衡量准确度,它只对排名敏感,忽略了误差的规模。所有模型的分类性能都明显超过了偶然水平(AUC>0.5)(图4),并接近或超过了被认为实际有用的水平(AUC>0.8)。在整个代理措施中,包括社会人口学特征的模型表现最好,但纯粹的社会人口学模型和基于大脑的模型之间的差异相当弱,在0.01-0.02个AUC点左右(补充表S2)。单独使用脑成像数据导致性能下降,然而,正如 permutation 检验所显示的那样,优于机会(补充表 S6)。
局限
其他的构架和心理测量工具也可以被评估。智力这一更广泛的构架通常是用一个具有多个相关测试的一般因素模型来估计的。虽然这对于规范性评估显然是有用的,但对流动智力的测量也可以作为一种情景适应性信号。具体来说,有大量的问卷用于测量负面情绪和神经质。然而,我们只能研究由UKBB提供的EPQ量表。一个补充的方法是通过汇集所有与神经质有语义关系的非影像学数据来估计潜在的因素。在这里,我们考虑的是既定的目标测量 “原样”,而不是衍生品。
就心理健康研究而言,这项研究没有直接测试估计的proxy measures的临床相关性。即使在像UKBB这样一个非常大的普通人群队列中,也只有几百个有脑成像数据的精神障碍诊断病例(ICD-10精神健康诊断来自F章)。因此,我们无法直接评估proxy measures在临床人群中的表现。在UKBB中,诊断出的精神障碍数量较少,这突出了除诊断出的病症外,将精神健康作为一个连续变量进行研究的实际重要性。事实上,从公共健康的角度来看,需要针对健康的个体差异,而不仅仅是病理。智商和神经质等心理结构是精神障碍流行病学的重要因素,大脑加速老化与各种神经系统疾病有关。然而,很少有队列带有广泛的神经心理学测试。经过验证的这些结构的替代品为将它们作为次要结果或额外的解释变量纳入流行病学研究打开了大门。
结论
在心理健康的群体研究中,个人特征是通过针对特定的大脑和心理构造的冗长评估来获取的。我们已经证明,根据经验从通用数据中建立的proxy measure 可以捕捉到这些建构,并且在研究真实世界的健康模式时可以改进传统的测量。proxy measure法可以使心理建构在更广泛、更生态的研究中使用,这些研究建立在大型流行病学队列或现实世界的证据之上。当心理建构是制定治疗和预防策略的核心,但没有收集到直接的测量方法时,这可能会产生差异。