源码
源码:https://github.com/facebookresearch/FiD
目录
源码
数据集
数据格式
预训练模型
训练
测试
src
slurm.py 资源调度管理
util.py 配置管理
evaluation.py 查找、确认、评估文档中的答案
data.py 数据处理,将数据tokenizer返回相关的信息 Collator处理器
model.py Wrapper条件构造器
index.py 找出topk个索引
preprocess.py 对数据进行预处理,数据集:TQA,NQ
options.py 添加各种参数
train_reader.py
test_reader.py
数据集
NaturalQuestions 和 TriviaQA 数据可以使用 get-data.sh 下载。两个数据集都从原始来源获得,维基百科转储是从 DPR存储库下载的。除了问题和答案之外,此脚本还检索用于训练已发布的预训练模型的 Wikipedia 段落。
Dense Passage Retrieval (DPR) - is a set of tools and models for state-of-the-art open-domain Q&A research. It is based on the following paper:
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, Wen-tau Yih. Dense Passage Retrieval for Open-Domain Question Answering. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6769–6781, 2020.
数据格式
预期的数据格式是 list 示例列表,其中每个条目示例是字典包含
- id:例子的id,可选
- question:问题文本
- target:用于模型训练的答案,如果没有给出,则从“answer”列表中随机抽取目标
- answers:用于评估答案的文本列表,如果没有给出目标,也可以用于训练
- ctxs:是一个文章列表,其中每一项都是包含 - title:文章标题 - 文本:段落文本
实例:
{
'id': '0',
'question': 'What element did Marie Curie name after her native land?',
'target': 'Polonium',
'answers': ['Polonium', 'Po (chemical element)', 'Po'],
'ctxs': [
{
"title": "Marie Curie",
"text": "them on visits to Poland. She named the first chemical element that she discovered in 1898 \"polonium\", after her native country. Marie Curie died in 1934, aged 66, at a sanatorium in Sancellemoz (Haute-Savoie), France, of aplastic anemia from exposure to radiation in the course of her scientific research and in the course of her radiological work at field hospitals during World War I. Maria Sk\u0142odowska was born in Warsaw, in Congress Poland in the Russian Empire, on 7 November 1867, the fifth and youngest child of well-known teachers Bronis\u0142awa, \"n\u00e9e\" Boguska, and W\u0142adys\u0142aw Sk\u0142odowski. The elder siblings of Maria"
},
{
"title": "Marie Curie",
"text": "was present in such minute quantities that they would eventually have to process tons of the ore. In July 1898, Curie and her husband published a joint paper announcing the existence of an element which they named \"polonium\", in honour of her native Poland, which would for another twenty years remain partitioned among three empires (Russian, Austrian, and Prussian). On 26 December 1898, the Curies announced the existence of a second element, which they named \"radium\", from the Latin word for \"ray\". In the course of their research, they also coined the word \"radioactivity\". To prove their discoveries beyond any"
}
]
}
预训练模型
预训练模型的下载可以用: get-model.sh. 现在可用的模型有 [nq_reader_base, nq_reader_large, nq_retriever, tqa_reader_base, tqa_reader_large, tqa_retriever].
bash get-model.sh -m model_name
预训练模型的性能:
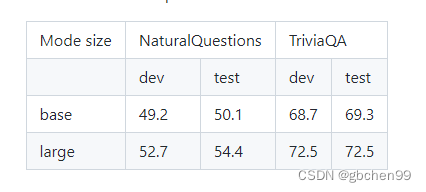
Fusion-in-Decoder
Fusion-in-Decoder 训练用 train_reader.py and 评估用 test_reader.py.
训练
train_reader.py 为训练模型的代码. 使用实例如下:
python train_reader.py \
--train_data train_data.json \
--eval_data eval_data.json \
--model_size base \
--per_gpu_batch_size 1 \
--n_context 100 \
--name my_experiment \
--checkpoint_dir checkpoint \
用 100 个段落训练这些模型是内存密集型的。为了缓解这个问题,使用带有 --use_checkpoint 选项的检查点。可变大小的张量会导致内存开销。编码器输入张量默认具有固定大小,但解码器输入张量没有。解码器端的张量大小可以使用 --answer_maxlength 来固定。大型阅读器已在 64 个 GPU 上接受了以下超参数的训练:
python train_reader.py \
--use_checkpoint \
--lr 0.00005 \
--optim adamw \
--scheduler linear \
--weight_decay 0.01 \
--text_maxlength 250 \
--per_gpu_batch_size 1 \
--n_context 100 \
--total_step 15000 \
--warmup_step 1000 \
参数:
usage: train_reader.py [-h] [--name NAME]
[--checkpoint_dir CHECKPOINT_DIR]
[--model_path MODEL_PATH]
[--per_gpu_batch_size PER_GPU_BATCH_SIZE]
[--maxload MAXLOAD]
[--local_rank LOCAL_RANK]
[--main_port MAIN_PORT]
[--seed SEED]
[--eval_freq EVAL_FREQ]
[--save_freq SAVE_FREQ]
[--eval_print_freq EVAL_PRINT_FREQ]
[--train_data TRAIN_DATA]
[--eval_data EVAL_DATA]
[--model_size MODEL_SIZE]
[--use_checkpoint]
[--text_maxlength TEXT_MAXLENGTH]
[--answer_maxlength ANSWER_MAXLENGTH]
[--no_title]
[--n_context N_CONTEXT]
[--warmup_steps WARMUP_STEPS]
[--total_steps TOTAL_STEPS]
[--scheduler_steps SCHEDULER_STEPS]
[--accumulation_steps ACCUMULATION_STEPS]
[--dropout DROPOUT]
[--lr LR]
[--clip CLIP]
[--optim OPTIM]
[--scheduler SCHEDULER]
[--weight_decay WEIGHT_DECAY]
[--fixed_lr]
测试
使用 test_reader.py 评估模型或预训练模型。下面提供了该脚本的示例用法。
python test_reader.py \
--model_path checkpoint_dir/my_experiment/my_model_dir/checkpoint/best_dev \
--eval_data eval_data.json \
--per_gpu_batch_size 1 \
--n_context 100 \
--name my_test \
--checkpoint_dir checkpoint \
usage: test_reader.py [-h] [--name NAME] [--checkpoint_dir CHECKPOINT_DIR]
[--model_path MODEL_PATH]
[--per_gpu_batch_size PER_GPU_BATCH_SIZE]
[--maxload MAXLOAD] [--local_rank LOCAL_RANK]
[--main_port MAIN_PORT] [--seed SEED]
[--eval_freq EVAL_FREQ] [--save_freq SAVE_FREQ]
[--eval_print_freq EVAL_PRINT_FREQ]
[--train_data TRAIN_DATA] [--eval_data EVAL_DATA]
[--model_size MODEL_SIZE] [--use_checkpoint]
[--text_maxlength TEXT_MAXLENGTH]
[--answer_maxlength ANSWER_MAXLENGTH] [--no_title]
[--n_context N_CONTEXT] [--write_results]
[--write_crossattention_scores]
src
slurm.py 资源调度管理
util.py 配置管理
evaluation.py 查找并评估答案
data.py 数据管理,将数据tokenizer后返回相关的信息
model.py 加载模型初始化权重,Wrapper条件构造器
index.py 找出topk个索引
preprocess.py 对数据集预处理main
options.py 参数管理
slurm.py 资源调度管理
资源调度管理
def sig_handler(signum, frame): # 获取内部环境变量
def term_handler(signum, frame):
def init_signal_handler():
"""
Handle signals sent by SLURM for time limit / pre-emption.
处理资源调度管理中发送的时间限制/预先空置
调用前两个函数
"""
def init_distributed_mode(params): #params有{is_slurm_job, local_rank, is_main, node_id, multi_node, n_nodes, multi_gpu, world_size, global_rank, is_distributed, device}
"""
Handle single and multi-GPU / multi-node / SLURM jobs.
处理单个或多个gpu/多节点/资源调度工作
Initialize the following variables:
初始化以下变量
- n_nodes
- node_id
- local_rank
- global_rank
- world_size
"""
PyTorch分布式DPP的基本概念(并行训练)
node
物理节点,就是一台机器,节点内部可以有多个GPU(一台机器有多卡)。
rank & local_rank
用于表示进程的序号,用于进程间通信。每一个进程对应了一个rank。
rank=0的进程就是master进程。
local_rank: rank是指在整个分布式任务中进程的序号;local_rank是指在一台机器上(一个node上)进程的相对序号,例如机器一上有0,1,2,3,4,5,6,7,机器二上也有0,1,2,3,4,5,6,7。local_rank在node之间相互独立。
nnodes
物理节点数量
node_rank
物理节点的序号
nproc_per_node
每个物理节点上面进程的数量。
group
进程组。默认只有一个组
world size
全局的并行数
全局(一个分布式任务)中,rank的数量。
每个node包含16个GPU,且nproc_per_node=8,nnodes=3,机器的node_rank=5,请问world_size是多少? 答案:world_size = 3*8 = 24
————————————————
版权声明:本文为CSDN博主「hxxjxw」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/hxxjxw/article/details/119606518
util.py 配置管理
配置管理
def init_logger(is_main=True, is_distributed=False, filename=None): #返回日志
def get_checkpoint_path(opt): #opt: {checkpoint_dir, name, is_distributed}
return checkpoint_path, checkpoint_exists
def symlink_force(target, link_name): #创建软链接,失败则返回错误
def save(model, optimizer, scheduler, step, best_eval_metric, opt, dir_path, name): #保存模型
def load(model_class, dir_path, opt, reset_params=False): #加载模型
return model, optimizer, scheduler, opt_checkpoint, step, best_eval_metric
class WarmupLinearScheduler(torch.optim.lr_scheduler.LambdaLR):
def __init__(self, optimizer, warmup_steps, scheduler_steps, min_ratio, fixed_lr,
last_epoch=-1):
self.warmup_steps = warmup_steps
self.scheduler_steps = scheduler_steps
self.min_ratio = min_ratio
self.fixed_lr = fixed_lr
super(WarmupLinearScheduler, self).__init__(
optimizer, self.lr_lambda, last_epoch=last_epoch
)
def lr_lambda(self, step):#返回学习率
class FixedScheduler(torch.optim.lr_scheduler.LambdaLR):
def __init__(self, optimizer, last_epoch=-1):
super(FixedScheduler, self).__init__(optimizer, self.lr_lambda, last_epoch=last_epoch)
def lr_lambda(self, step):
return 1.0
def set_dropout(model, dropout_rate): #设置dropout
def set_optim(opt, model): #设置优化器
return optimizer, scheduler
def average_main(x, opt): #参数opt: {is_distributed, world_size}
return x
def sum_main(x, opt):
return x
def weighted_average(x, count, opt): #参数opt: {is_distributed, device, world_size}
return x, count
return (t_loss / t_total).item(), t_total.item()
def write_output(glob_path, output_path): #参数glob_path: {glob, rmdir},将output写入txt文件
def save_distributed_dataset(data, opt): #参数opt: {checkpoint_dir, name, global_rank, is_distributed, is_main},保存数据分数在'dataset_wscores.json'文件中,
def load_passages(path):
return passages
线性学习率预热,学习率从0线性(也可非线性)增加到优化器中的初始预设lr,之后使其学习率从优化器中的初始lr线性降低到0
1. warmup是什么?
- Warmup是针对学习率优化的一种方式,Warmup是在ResNet论文中提到的一种学习率预热的方法,它在训练开始的时候先选择使用一个较小的学习率,训练了一些epoches,再修改为预先设置的学习率来进行训练。
2. 为什么要使用 warmup?
- 在实际中,由于训练刚开始时,训练数据计算出的梯度 grad 可能与期望方向相反,所以此时采用较小的学习率 learning rate,随着迭代次数增加,学习率 lr 线性增大,增长率为 1/warmup_steps;迭代次数等于 warmup_steps 时,学习率为初始设定的学习率;
- 另一种原因是由于刚开始训练时,模型的权重(weights)是随机初始化的,此时若选择一个较大的学习率,可能带来模型的不稳定(振荡),选择Warmup预热学习率的方式,可以使得开始训练的几个epoches内学习率较小,在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,使得模型收敛速度变得更快,模型效果更佳。
- 迭代次数超过warmup_steps时,学习率逐步衰减,衰减率为1/(total-warmup_steps),再进行微调。
- 刚开始训练时,学习率以 0.01 ~ 0.001 为宜, 接近训练结束的时候,学习速率的衰减应该在100倍以上
3. 如何实现warmup?
- num_train_optimization_steps为模型参数的总更新次数
一般来说:
- t_total 是参数更新的总次数,首先是如果设置了 梯度累积trick会除 gradient_accumulation_steps ,然后乘上 训练 epoch 得到最终的更新次数
- 下面俩例子区别是 len(train_dataloader)=int(total_train_examples) / .train_batch_size 实际上是一样的
num_train_optimization_steps = int(total_train_examples / args.train_batch_size / args.gradient_accumulation_steps)
scheduler = WarmupLinearSchedule(optimizer, warmup_steps=args.warmup_steps, t_total=num_train_optimization_steps)
======================================================================================================
t_total = len(train_dataloader) / args.gradient_accumulation_steps * args.num_train_epochs
scheduler = WarmupLinearSchedule(optimizer, warmup_steps=args.warmup_steps, t_total=t_total)
3. warmup 方法的优势:
- 有助于减缓模型在初始阶段对mini-batch的提前过拟合现象,保持分布的平稳
- 有助于保持模型深层的稳定性
4. optimizer.step()和scheduler.step()的区别
- optimizer.step()通常用在每个mini-batch之中,而scheduler.step()通常用在epoch里面,但是不绝对,可以根据具体的需求来做。只有用了optimizer.step(),模型才会更新,而scheduler.step()是对lr进行调整。
作者:三方斜阳
链接:https://www.jianshu.com/p/1c875d25ce78
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
evaluation.py 查找、确认、评估文档中的答案
查找、确认、评估文档中的答案
"""
Evaluation code from DPR: https://github.com/facebookresearch/DPR
"""
class SimpleTokenizer(object):
return tokens
QAMatchStats = collections.namedtuple('QAMatchStats', ['top_k_hits', 'questions_doc_hits'])
注释如下
def calculate_matches(data: List, workers_num: int):
注释如下
def check_answer(example, tokenizer) -> List[bool]:
"""Search through all the top docs to see if they have any of the answers."""
查找所有top文章是否有答案
def has_answer(answers, text, tokenizer) -> bool:
"""Check if a document contains an answer string."""
确认某个文章是否有答案
由于元组不像字典那样可以为内部的元素命名,因此我们并不知道元组内的元素所表达的意义,在访问元组的时候也只能通过索引访问其中的元素。 于是Python标准库collections引入了namedtuple函数,它可以创建一个和元组类似但更为强大的类型——具名元组(namedtuple),也就是构造一个带字段名的元组。
namedtuple 函数的语法如下所示:
collections.namedtuple(typename, field_names, *, verbose=False, rename=False, module=None)
1
typename:元组名称。可以理解为通过namedtuple创建的类名,通过这样的方式可以初始化各种实例化元组对象。
field_names: 元组中元素的名称。类似于字典的key,在这里定义的元组可以通过这样的key去获取里面对应索引位置的元素值。
rename: 为True时field_names中不能包含有非Python标识符、Python中的关键字以及重复的name,如果有则会默认重命名成‘_index’的样式(index表示该name在field_names中的索引,例:[‘abc’,‘def’, ‘ghi’, ‘abc’]将被转换成[‘abc’, ‘_1’, ‘ghi’, ‘_3’])
创建一个具名元组,需要两个参数,一个是类名,另一个是类的各个字段名。后者可以是有多个字符串组成的可迭代对象,或者是有空格分隔开的字段名组成的字符串。具名元组可以通过字段名或者位置来获取一个字段的信息。
import collections
tupleA = collections.namedtuple('User', ['name', 'age', 'id'])
tupleB = collections.namedtuple('User', 'name age id')
tuple_a = tupleA('Tom', '28', '464643123')
tuple_b = tupleB('Jack', '22', '464643143')
print(tuple_a, tuple_b)
# User(name='Tom', age='28', id='464643123')
# User(name='Jack', age='22', id='464643143')
————————————————
版权声明:本文为CSDN博主「xuange01」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/xuange01/article/details/103309602
def calculate_matches(data: List, workers_num: int):
评估文档集中存在的答案。此功能应该与大量文档和结果一起使用。它在内部分叉多个子流程进行评估,然后合并结果,参数:
all_docs:整个文档数据库的字典。 doc_id -> (doc_text, title)
answers:答案列表的列表。每个问题一个列表:
closest_docs:最高结果的文档 ID 及其分数:
workers_num:处理数据的并行线程数量
match_type:答案匹配的类型。有关可用选项,请参阅 has_answer 代码
返回值:
匹配信息元组。
top_k_hits - 一个列表,其中索引是检索到的顶级文档的数量,值是整个数据集中有效匹配的总数。
questions_doc_hits - 每个问题和每个检索到的文档对应答案的详细信息
reader阅读器评估
def _normalize(text):
def normalize_answer(s): #去除a、an、the,用空格分隔,去除标点,转变成小写
def exact_match_score(prediction, ground_truth): #返回精确匹配的分数
def ems(prediction, ground_truths): #返回最大的匹配分数
retriever检索器评估
def eval_batch(scores, inversions, avg_topk, idx_topk):#调用score
def count_inversions(arr): 计算要转换的次数
def score(x, inversions, avg_topk, idx_topk):修改avg_topk, idx_topk
data.py 数据处理,将数据tokenizer返回相关的信息 Collator处理器
数据处理,将数据tokenizer返回相关的信息
Collator处理器
class Dataset(torch.utils.data.Dataset):
def __init__(self,
data,
n_context=None,
question_prefix='question:',
title_prefix='title:',
passage_prefix='context:'):
def __len__(self):
def get_target(self, example):数据中有target字段的话,获取它并在target的内容中加上' </s>'
def __getitem__(self, index):根据index获取question和target等
return {
'index' : index,
'question' : question,
'target' : target,
'passages' : passages,
'scores' : scores
}
def sort_data(self):
def get_example(self, index):
def encode_passages(batch_text_passages, tokenizer, max_length):获取passage的tokenizer后的id和mask
return passage_ids, passage_masks.bool()
class Collator(object): #处理器,将数据tokenizer之后返回相关的信息
def __init__(self, text_maxlength, tokenizer, answer_maxlength=20):
def __call__(self, batch):
def append_question(example):将question添加到passage后调用encode_passage
return (index, target_ids, target_mask, passage_ids, passage_masks)
def load_data(data_path=None, global_rank=-1, world_size=-1):
return examples
class RetrieverCollator(object):tokenizer之后返回相关信息
def __init__(self, tokenizer, passage_maxlength=200, question_maxlength=40):
def __call__(self, batch):
return (index, question_ids, question_mask, passage_ids, passage_masks, scores)
class TextDataset(torch.utils.data.Dataset):
def __init__(self,
data,
title_prefix='title:',
passage_prefix='context:'):
def __len__(self):
def __getitem__(self, index):
return example[0], text
class TextCollator(object):
def __init__(self, tokenizer, maxlength=200):
def __call__(self, batch):
return index, text_ids, text_mask
model.py Wrapper条件构造器
Wrapper条件构造器
class FiDT5(transformers.T5ForConditionalGeneration):
def __init__(self, config):
def forward_(self, **kwargs):
def forward(self, input_ids=None, attention_mask=None, **kwargs):这里将大小调整
为 B x (N L) 而不是 (B N) x L,因为 T5 前馈运算使用输入张量来推断解码器中使用的维度。
之后再从EncoderWrapper 将输入的大小调整为 (B N) x L。
def generate(self, input_ids, attention_mask, max_length):在这里调整输入的大小,
因为生成方法需要 2D 张量
def wrap_encoder(self, use_checkpoint=False):构造T5encoder以获得 Fusion-in-Decoder 模型
def unwrap_encoder(self):解构FiD的的decoder,用于加载T5的权重
def load_t5(self, state_dict):解构FiD的的encoder,加载T5的权重,然后构造t5的encoder来获取FiD模型
def set_checkpoint(self, use_checkpoint):在encoder中启用或禁用检查点。
def reset_score_storage(self):重置分数存储,仅在保存交叉注意力分数以训练检索器时使用。
def get_crossattention_scores(self, context_mask):聚合交叉注意力分数以获得每个段落的
单个标量。这个标量可以看作是问题和输入段落之间的相似度得分。它是通过对输入通道的头部、层和
令牌上的第一个解码令牌上获得的交叉注意力分数进行平均而获得的。 More details in
Distilling Knowledge from Reader to Retriever:
https://arxiv.org/abs/2012.04584.
def overwrite_forward_crossattention(self):替换cross-attention forward函数,
只用来保存cross-attention分数。
class EncoderWrapper(torch.nn.Module):encoder的构造器构造T5encoder以获得 Fusion-in-Decoder 模型
def __init__(self, encoder, use_checkpoint=False):
def forward(self, input_ids=None, attention_mask=None, **kwargs,):
class CheckpointWrapper(torch.nn.Module):构造器用空张量替换 None 输出,这允许使用 检查点。
def __init__(self, module, use_checkpoint=False):
def forward(self, hidden_states, attention_mask, position_bias, **kwargs):
def apply_checkpoint_wrapper(t5stack, use_checkpoint):构造编码器的每个块以启用检查点
def cross_attention_forward(
self,
input,
mask=None,
kv=None,
position_bias=None,
past_key_value_state=None,
head_mask=None,
query_length=None,
use_cache=False,
output_attentions=False,
):这仅适用于计算输入的交叉注意力
class RetrieverConfig(transformers.BertConfig):检索器配置
def __init__(self,
indexing_dimension=768,
apply_question_mask=False,
apply_passage_mask=False,
extract_cls=False,
passage_maxlength=200,
question_maxlength=40,
projection=True,
**kwargs):
class Retriever(transformers.PreTrainedModel):检索器
config_class = RetrieverConfig
base_model_prefix = "retriever"
def __init__(self, config, initialize_wBERT=False):
def forward(self,
question_ids,
question_mask,
passage_ids,
passage_mask,
gold_score=None):
question_output = self.embed_text(
text_ids=question_ids,
text_mask=question_mask,
apply_mask=self.config.apply_question_mask,
extract_cls=self.config.extract_cls,
)
def embed_text(self, text_ids, text_mask, apply_mask=False, extract_cls=False):
def kldivloss(self, score, gold_score):
index.py 找出topk个索引
找出topk个索引
1.import faiss
faiss是为稠密向量提供高效相似度搜索和聚类的框架。由Facebook AI Research研发。 具有以下特性。
- 1、提供多种检索方法
- 2、速度快
- 3、可存在内存和磁盘中
- 4、C++实现,提供Python封装调用。
- 5、大部分算法支持GPU实现
2.import pickle
pickle,它能够实现任意对象与文本之间的相互转化,也可以实现任意对象与二进制之间的相互转化。也就是说,pickle 可以实现 Python 对象的存储及恢复。
值得一提的是,pickle 是 python 语言的一个标准模块,安装 python 的同时就已经安装了 pickle 库,因此它不需要再单独安装,使用 import 将其导入到程序中,就可以直接使用。
pickle 模块提供了以下 4 个函数供我们使用:
- dumps():将 Python 中的对象序列化成二进制对象,并返回;
- loads():读取给定的二进制对象数据,并将其转换为 Python 对象;
- dump():将 Python 中的对象序列化成二进制对象,并写入文件;
- load():读取指定的序列化数据文件,并返回对象。
以上这 4 个函数可以分成两类,其中 dumps 和 loads 实现基于内存的 Python 对象与二进制互转;dump 和 load 实现基于文件的 Python 对象与二进制互转。
class Indexer(object):
def __init__(self, vector_sz, n_subquantizers=0, n_bits=8):
1.基于乘积量化器的索引。存储的向量是 由 PQ (product quantizer乘积向量化) 码近似。
2.存储完整向量并执行穷举搜索的索引
def index_data(self, ids, embeddings):
def search_knn(self, query_vectors: np.array, top_docs: int, index_batch_size=1024) -> List[Tuple[List[object], List[float]]]:
# knn搜索,从query_vectors中搜索出top_docs返回
def serialize(self, dir_path):
#将索引序列化到文件index.faiss,元数据到index_meta.dpr
def deserialize_from(self, dir_path):
#从上述两个文件中加载出索引
def _update_id_mapping(self, db_ids: List):
preprocess.py 对数据进行预处理,数据集:TQA,NQ
对数据进行预处理,数据集:TQA,NQ
踩坑! 需要在终端运行:
python preprocess.py [参数1] [参数2]
参数为两个文件路径
参数2:open_domain_data/download 参数1:open_domain_data
{
'id': '0',
'question': 'What element did Marie Curie name after her native land?',
'target': 'Polonium',
'answers': ['Polonium', 'Po (chemical element)', 'Po'],
'ctxs': [
{
"title": "Marie Curie",
"text": "them on visits to Poland. She named the first chemical element that she discovered in 1898 \"polonium\", after her native country. Marie Curie died in 1934, aged 66, at a sanatorium in Sancellemoz (Haute-Savoie), France, of aplastic anemia from exposure to radiation in the course of her scientific research and in the course of her radiological work at field hospitals during World War I. Maria Sk\u0142odowska was born in Warsaw, in Congress Poland in the Russian Empire, on 7 November 1867, the fifth and youngest child of well-known teachers Bronis\u0142awa, \"n\u00e9e\" Boguska, and W\u0142adys\u0142aw Sk\u0142odowski. The elder siblings of Maria"
},
{
"title": "Marie Curie",
"text": "was present in such minute quantities that they would eventually have to process tons of the ore. In July 1898, Curie and her husband published a joint paper announcing the existence of an element which they named \"polonium\", in honour of her native Poland, which would for another twenty years remain partitioned among three empires (Russian, Austrian, and Prussian). On 26 December 1898, the Curies announced the existence of a second element, which they named \"radium\", from the Latin word for \"ray\". In the course of their research, they also coined the word \"radioactivity\". To prove their discoveries beyond any"
}
]
}
def select_examples_TQA(data, index, passages, passages_index):
selected_data.append(
{
'question': q,
'answers': answers,
'target': target,
'ctxs': ctxs,
}
)
return selected_data
使用:
TQA_train = select_examples_TQA(originaltrain, TQA_idx['train'], passages, TQA_passages['train'])
def select_examples_NQ(data, index, passages, passages_index):
dico = {
'question': data[k]['question'],
'answers': data[k]['answer'],
'ctxs': ctxs,
}
selected_data.append(dico)
return selected_data
使用:
NQ_train = select_examples_NQ(originaltrain, NQ_idx['train'], passages, NQ_passages['train'])
if __name__ == "__main__":
加载数据集
#load NQ question idx
#load Trivia question idx
json.dump()
这个方法结合了文件的操作,把转换后的json储存在了文件里
dump(obj, fp, skipkeys=False, ensure_ascii=True, check_circular=True,allow_nan=True, cls=None, indent=None, separators=None,default=None, sort_keys=False, **kw)
obj:就是你要转化成json的对象。
fp: 文件参数,一个是关于文件之间的储存
sort_keys =True:是告诉编码器按照字典排序(a到z)输出。如果是字典类型的python对象,就把关键字按照字典排序。
indent:参数根据数据格式缩进显示,读起来更加清晰。
separators:是分隔符的意思,参数意思分别为不同dict项之间的分隔符和dict项内key和value之间的分隔符,把:和,后面的空格都除去了。
skipkeys:默认值是False,如果dict的keys内的数据不是python的基本类型(str,unicode,int,long,float,bool,None),设置为False时,就会报TypeError的错误。此时设置成True,则会跳过这类key 。
ensure_ascii=True:默认输出ASCLL码,如果把这个该成False,就可以输出中文。
check_circular:如果check_circular为false,则跳过对容器类型的循环引用检查,循环引用将导致溢出错误(或更糟的情况)。
allow_nan:如果allow_nan为假,则ValueError将序列化超出范围的浮点值(nan、inf、-inf),严格遵守JSON规范,而不是使用JavaScript等价值(nan、Infinity、-Infinity)。
default:default(obj)是一个函数,它应该返回一个可序列化的obj版本或引发类型错误。默认值只会引发类型错误。
————————————————
版权声明:本文为CSDN博主「爱吃草莓蛋糕的猴」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_46293423/article/details/105785007
sys.argv[1]报错问题
该语句的作用
sys.argv[]是用来获取命令行参数的
sys.argv[0]表示代码本身文件路径
所以在程序中编写的时候参数从1开始
Sys.argv[ ]其实就是一个列表,里边的项为用户输入的参数
问题出现的原因
sys模块的使用是要在cmd命令提示符里的。
由上面的作用可以看出,argv[]里面存放的是参数,既然是参数,就需要我们输入的,那么问题就来了。
当我们在使用IDLE编辑代码文件后之间F5运行时,根本就没有输入,那么列表中自然就不会有对应的项,即当前argv[]只有argv[0],也就是程序文件路径本身
所以,我们就需要手动的进行参数列表的输入
解决方法
解决方法是,在cmd中运行对应的.py文件,并进行参数输入
————————————————
版权声明:本文为CSDN博主「Jingjingjng0504」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Jingjingjng0504/article/details/104499381
options.py 添加各种参数
class Options():
'''
添加各种参数
'''
def add_optim_options(self): #获取优化的参数如学习率、权重衰退、优化函数等
def add_eval_options(self): # 保存结果、保存数据的交叉注意力分数等
def add_reader_options(self): # 阅读器的参数如训练、测试数据源、模型大小,检查点、段落长度等
def add_retriever_options(self): #检索器的参数同上
def initialize_parser(self): #基础参数(模型路径、名称)、数据集参数(gpu上训练的大小)
def print_options(self, opt): # 输出选项
def get_options(use_reader=False, #是否使用上述函数
use_retriever=False,
use_optim=False,
use_eval=False):
train_reader.py
主函数
# 训练阅读器过程
def train(model, optimizer, scheduler, step, train_dataset, eval_dataset, opt, collator, best_dev_em, checkpoint_path):调用评估
# 评估过程
def evaluate(model, dataset, tokenizer, collator, opt)
if __name__ == "__main__":
参数
def train(model: {train},
optimizer: Any,
scheduler: Any,
step: {__lt__, __mod__, __gt__},
train_dataset: Any,
eval_dataset: Any,
opt: {is_main, global_rank, seed, per_gpu_batch_size, total_steps, accumulation_steps, is_distributed, world_size, eval_freq, save_freq},
collator: Any,
best_dev_em: Any,
checkpoint_path: Any) -> None
test_reader.py
def evaluate(model: {eval, generate},
dataset: {data},
dataloader: Any,
tokenizer: {decode},
opt: {write_crossattention_scores, write_results, eval_print_freq, global_rank, is_distributed, device, world_size})
-> tuple[Any, Any]