最近很多小伙伴说,不会用浏览器开发者工具,今天我们就一起来深入了解一下开发者工具。
以谷歌浏览器为例
谷歌浏览器开发者工具中的Network 是我们学习经常用到的,那么你都知道他们每个功能的意义吗?

因本人经常有360极速浏览器,谷歌内核,所以本文以360极速浏览器的开发者工具Network为例,基本和谷歌的Network一致
谷歌Network大致可以帮我们实现以下功能
看接口的返回值
看接口的请求头,响应头
查看资源的加载速度
查看资源的大小,缓存情况,响应情况(cdn、waiting 等时间)
谷歌NETWORK的控制面板主要分为7大板块
1、功能区
2、筛选区(功能区漏斗需要开启)
3、快照区(功能区需要打开屏幕捕获)
4、时间轴区(功能区需要开启overview)
5、主显示区
6、信息汇总区
7、控制台
如图所示
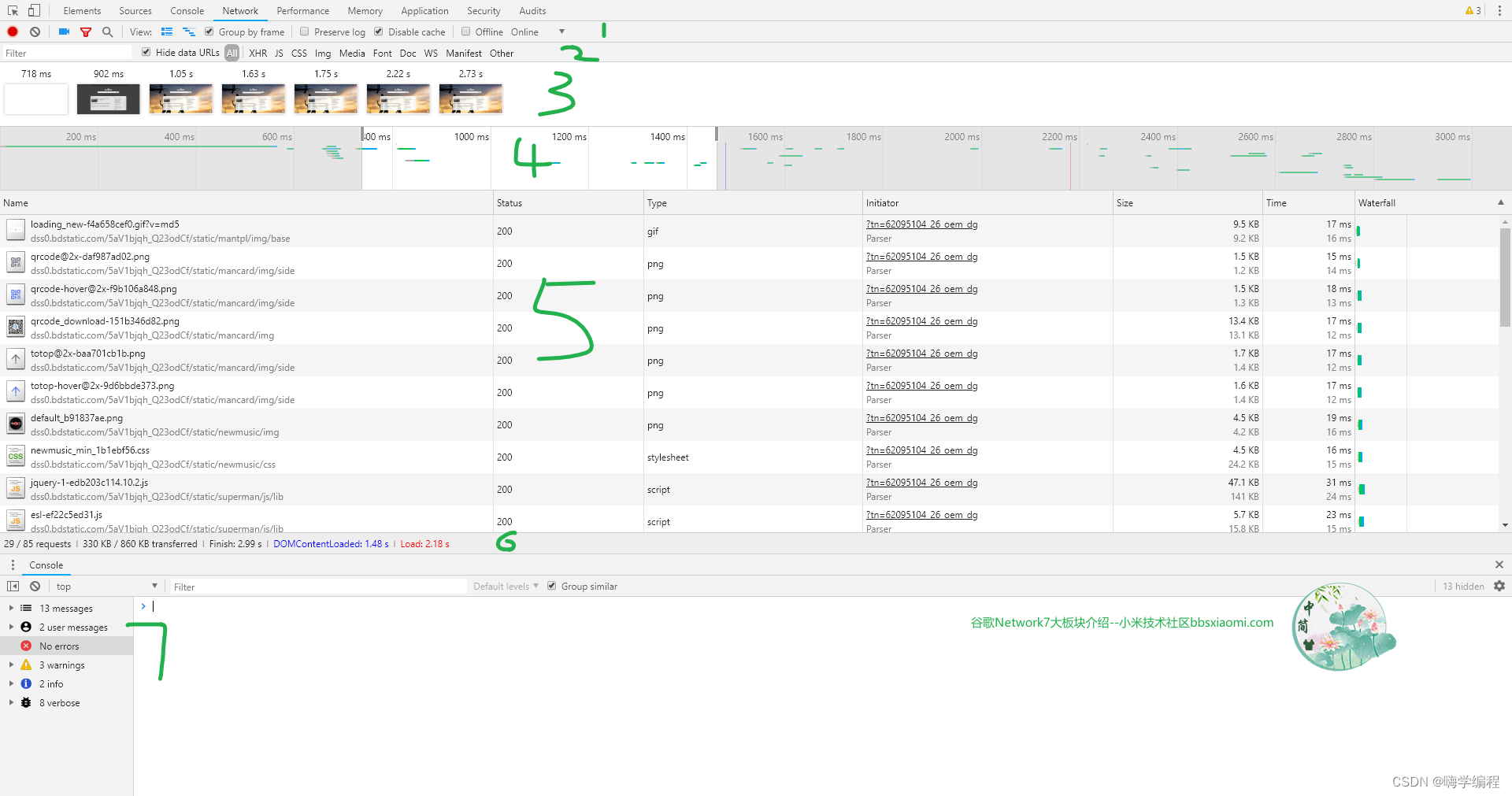
一、功能区

1、红色圆点代表是否开启 network 的日志功能,如果灰色的,就代表未开启,红色的代表已开启.2.
2、清除 network 日志

3、摄像机是捕获屏幕,默认是关闭状态,点击后图标变成蓝色,会记录页面在不同时间下的快照,此按钮开启才会显示3快照区
4、漏斗代表是否开启过滤选项,此按钮开启会才会显示2筛选区
5、放大镜代表快速查找按钮,可以迅速查到当前页面包含**东西,

6、代表是否使用更大的区域显示请求记录,我喜欢大的显示,一般可以开启
7、代表是否显示overview概括,此按钮开启才会显示5时间轴

8、Group by frame,勾选了该选项后,会对网络请求按表单名称进行分组,如下图所示
9、重要:Preserve log,是否保留日志,如果勾上,页面刷新后,日志也不会消失(这功能很有用,比如页面跳转后,你想看页面跳转前发出的请求有哪些,比如查看别人网站登录请求,登录成功返回什么,登录成功后又发起了些什么请求,重定向到什么地址)作用:
(1)我们可以看到一些中间页的跳转,省去了抓包的麻烦。
(2)可以和上个页面的数据比对。
10、Disable cache,缓存开关,开启这个功能,浏览器关于当前网站的js、css、图片…等缓存都会失效,所有请求都会重新发送给服务器。ctrl+F5也可以达到同样的效果。当我们打开 disable cache 之后,我们就不需要关了,每次都是无缓存的加载.
Group by frame勾选后分组效果

11、Offline 是网络连接开关,比如说在测试 PWA。或者说弱网的情况下的一种快速配置。
12、Online这个下拉列表是网速阀值,可以设置上传下载最大网速等.一般可以网页在不同网络状态下的显示效果
二、筛选区
1.作用:请求比较多的页面,我们有可能需要过滤。
2.功能:工具栏提供了,路径过滤(支持正则),类型过滤(All,XHR,js,图片等),方便快速查看,按住CTRL可多选
3.Hide data URLs的作用:网站开发者很多时候会将一些小的图片或者 CSS 脚本,以 BASE64 格式嵌入到 HTML 中,以减少 HTTP 请求数。当勾选了 Hide data URLs 选项后,就可以隐藏掉请求列表中的像 data: 或者 blob: 类请求。

4.filter查找框
除了以上几个 Chrome 提供的过滤器以外,还可以非常灵活的在过滤框中使用过滤属性进行请求日志的筛选。
可以进行模糊搜索(只搜索url地址),如果首尾加上/,则表示使用正则匹配(同时搜索 URL 地址和返回内容)旧版本 chrome 可能会在过滤输入框右边有个 regexp 选项,勾选了正则才会生效
常见的filter过滤属性可参考下表

文本版:
domain:筛选出指定域名的请求,不仅支持自动补全,还支持*匹配。
has-response-header:筛选出包含指定响应头的请求。
is:通过is:running找出WebSocket请求。
larger-than:筛选出请求大于指定字节大小的请求,其中1000表示1k。
method:筛选出指定HTTP方法的请求,比如GET请求、POST请求等。
mime-type:筛选出指定文件类型的请求。
mixed-content:筛选出混合内容的请求(不懂啥意思)。
scheme:筛选出指定协议的请求,比如scheme:http、scheme:https。
set-cookie-domain:筛选出指定cookie域名属性的包含Set-Cookie的请求。
set-cookie-name:筛选出指定cookie名称属性的包含Set-Cookie的请求。
set-cookie-value:筛选出指定cookie值属性的包含Set-Cookie的请求。
status-code:筛选出指定HTTP状态码的请求。
(1)filter使用方法1:我们想筛选网页中来自于不同域名的请求资源,就可以在过滤框中输入 [domain:] ,Chrome 会帮我们自动补齐相关的域名信息。

(2)打开的网页中,如何查看哪些请求使用了缓存?使用命令 [is:from-cache],对应的还有[is:runing]

三、快照区 和 四、时间轴区
这两个区域主要对网页整理的加载情况进行一个分解性的展示
快照区可以更直观的看到浏览器打开网页的流程,和打开整个网页所用时间
而时间轴区可以滑动鼠标滚轮看查看不懂时间加载文件的情况,对找出网页中加载慢的文件还是很有帮助的
五、主显示区
1.主显示区包含了 name(姓名),status(状态),Type(类型),Initiator(发起者),Size(大小),Time(时间),Waterfall(瀑布分析)
Name:请求资源的名称
Status HTTP:状态码
Type:请求资源的 MIME 类型
Initiator:发起请求的对象或进程
Size:服务器返回的响应大小(包括头体和包体),可显示解压后大小
Time:总持续时间,从请求的开始到接收响应中的最后一个字节
Waterfall:各请求相关活动的直观分析图
2.请求列表默认是按照资源请求发起的时间升序排列的,我们也可以选择按指定列排序,点击相关列表头即可
3.通过点击某个资源的Name可以查看该资源的详细信息,根据选择的资源类型显示的信息也不太一样,可能包括如下Tab信息:
Headers 该资源的HTTP头信息。
Preview 根据你所选择的资源类型(JSON、图片、文本)显示相应的预览。
Response 显示HTTP的Response信息。
Cookies 显示资源HTTP的Request和Response过程中的Cookies信息。
Timing 显示资源在整个请求生命周期过程中各部分花费的时间。
针对上面4个Tab进行详细讲解一下各个功能:
① 查看资源HTTP头信息
在Headers标签里面可以看到HTTP Request URL、HTTP Method、Status Code、Remote Address等基本信息和详细的Response Headers 、Request Headers以及Query String Parameters或者Form Data等信息。
② 查看资源预览信息
在Preview标签里面可根据选择的资源类型(JSON、图片、文本、JS、CSS)显示相应的预览信息。下图显示的是当选择的资源是JSON格式时的预览信息。
③ 查看资源HTTP的Response信息
在Response标签里面可根据选择的资源类型(JSON、图片、文本、JS、CSS)显示相应资源的Response响应内容(纯字符串)。下图显示的是当选择的资源是CSS格式时的响应内容。
④ 查看资源Cookies信息
如果选择的资源在Request和Response过程中存在Cookies信息,则Cookies标签会自动显示出来,在里面可以查看所有的Cookies信息。
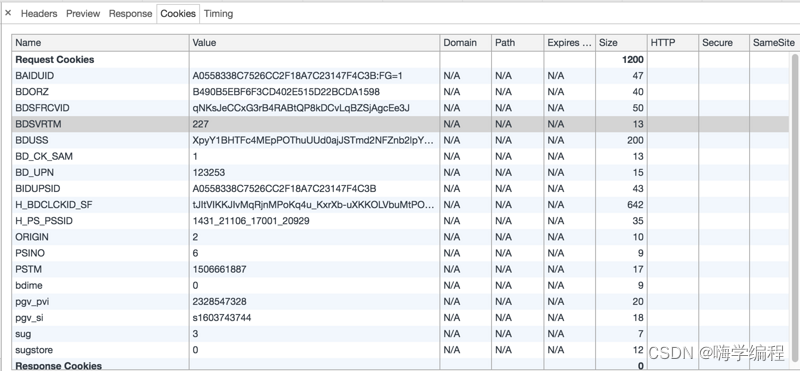
Name:cookie的名称。
Value:cookie的值。
Domain:cookie所属域名。
Path:cookie所属URL。
Expire/Max-Age:cookie的存活时间。
Size:cookie的字节大小。
HTTP:表示cookie只能被浏览器设置,而且JS不能修改。
Secure:表示cookie只能在安全连接上传输。
⑤ 分析资源在请求的生命周期内各部分时间花费信息
在Timing标签中可以显示资源在整个请求生命周期过程中各部分时间花费信息,可能会涉及到如下过程的时间花费情况:
Queuing 排队的时间花费。可能由于该请求被渲染引擎认为是优先级比较低的资源(图片)、服务器不可用、超过浏览器的并发请求的最大连接数(Chrome的最大并发连接数为6).
Stalled 从HTTP连接建立到请求能够被发出送出去(真正传输数据)之间的时间花费。包含用于处理代理的时间,如果有已经建立好的连接,这个时间还包括等待已建立连接被复用的时间。
Proxy Negotiation 与代理服务器连接的时间花费。
DNS Lookup 执行DNS查询的时间。网页上每一个新的域名都要经过一个DNS查询。第二次访问浏览器有缓存的话,则这个时间为0。
Initial Connection / Connecting 建立连接的时间花费,包含了TCP握手及重试时间。
SSL 完成SSL握手的时间花费。
Request sent 发起请求的时间。
Waiting (Time to first byte (TTFB)) 是最初的网络请求被发起到从服务器接收到第一个字节这段时间,它包含了TCP连接时间,发送HTTP请求时间和获得响应消息第一个字节的时间。
Content Download 获取Response响应数据的时间花费。
TTFB这个部分的时间花费如果超过200ms,则应该考虑对网络进行性能优化了,可以参见网络性能优化方案及里面的相关参考文档。
如何查看资源的发起者(请求源)和依赖项(按住Shift)
通过按住Shift并且把光标移到资源名称上,可以查看该资源是由哪个对象或进程发起的(请求源)和对该资源的请求过程中引发了哪些资源(依赖资源)。
在该资源的上方第一个标记为绿色的资源就是该资源的发起者(请求源),有可能会有第二个标记为绿色的资源是该资源的发起者的发起者,以此类推。
在该资源的下方标记为红色的资源是该资源的依赖资源。
六、信息汇总区

信息汇总区中显示[请求数],[数据传输量],[加载时间信息]等信息
DOMContentLoaded事件是在页面上DOM完全加载并解析完毕之后触发,不会等待CSS、图片、子框架加载完成。DOMContentLoaded事件在Overview上用一条蓝色竖线标记,并且在Summary以蓝色文字显示确切的时间。
load事件是在页面上所有DOM、CSS、JS、图片完全加载完毕之后触发。load事件同样会在Overview和Requests Table上用一条红色竖线标记,在Summary也会以红色文字显示确切的时间。
结合DOM文档加载的加载步骤,DOMContentLoaded事件/Load事件触发时机如下:
解析HTML结构。
加载外部脚本和样式表文件。
解析并执行脚本代码。// 部分脚本会阻塞页面的加载
DOM树构建完成。//DOMContentLoaded 事件
加载图片等外部文件。
页面加载完毕。//load 事件
七、console控制区
这个区本来是F12里面单独为一列的,但是因为和network有着紧密的联系,所以集合成一个了,后续单做一个版块来介绍
很多小伙伴在学习Python的过程中,因为没有好的学习资料或者是遇到问题不能及时的得到解决,导致自己学习不下去, 所以小编给大家准备了Python需要的相关软件工具、Python基础教程、各种Python实战案例源码、数百本Python电子书、Python学习路线图都打包好了,免费领取~
文末名片扫码即可,有什么学习问题也是可以问的。
好了,今天的分享就到这结束了,下次见~