下面我将介绍如何一步一步将豆瓣的top250的网页数据爬取并保存在本地。
首先我们需要python的基础:定义变量,列表,字典,元组,if语句,while语句等。
然后利用了解爬虫的基本框架(原理):爬虫就是模仿浏览器去访问网络中的网页,并将网页爬到电脑的内存中并进行解析,最终将我们想要的数据进行存储。在此条件下,我们需要给于爬虫(灵魂)逻辑,也就要求我们对爬取对象的个体和总体进行比对,从而发现规律。也就是说,我们想让爬虫动起来,我们首先要自己能看懂网页。(提前学一下html,会轻松一些)
然后呢,我们就要利用python强大的第三方库,在这个实例中我用到了这么几个库:
import urllib.request,urllib.error
import re
from bs4 import BeautifulSoup
import xlwt
其对应的用法我就不多说了。
对于整个框架无疑就是函数的运行,在主函数内套娃:
#-*- codeing = utf-8 -*-
def main():
print('''
1.网页爬取函数
2.解析数据函数
3.保存数据函数
'''
)
if __name__ == __mian__:
main()
我先把主函数放这里,最后看哟
def main():
baseurl="https://movie.douban.com/top250?start="
savepath="豆瓣电影Top250.xls"
datalist=getData(baseurl)
saveData(datalist,savepath)
1.首先我们要爬取网页
def askURL(url):
head={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36"
}
request=urllib.request.Request(url,headers=head)
html = ""
try:
response=urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
这大致就是浏览器向人家服务器要网页的过程,首先是请求头,一般像这种无需登录的网站,把我们谷歌的’User-Agent'放里头就行,如果是需要登录的网站,几乎需要全套了。剩下的就交给urllib了,由于对象服务的状态是未知的,我们需要对我们爬取过程中的状态有一个了解,即错误捕获。我们给爬虫这么多活,不能因为一个任务不能完成就罢工吧,try一try就可以了,这里是利用了urllib的urllib.error来识别网络报错。最后将获取的网页赋给html就可以走人了。
2.边爬取边解析网页
def getData(baseurl):
datalist=[]
for i in range(0,10):
url = baseurl + str(i*25)
html = askURL(url) #保存获取的网页源码
soup = BeautifulSoup(html,"html.parser")
for item in soup.find_all('div',class_="item"):
#print(item)
data=[]
item = str(item) #转化为字符串
link =re.findall(findlink,item)[0]
data.append(link)
imgSrc =re.findall(findImgSrc,item)[0]
data.append(imgSrc)
datalist.append(data)
title=re.findall(findTitle,item)
data.append(title)
return datalist
我们不可能只爬取一个url,要根据我网页的特性,为爬虫设计爬取路线,每爬取一页就要解析一页,根据观察发现每页有25个电影,一共有250个电影共需要10页,url中的最后几个数字刚好与每页第一个电影的序号有关联,利用for循环遍历一遍就可以了。每循环一边就调用一遍askurl,并用”靓汤“对其进行解析,我们首先要筛选出有关的网页源码对其进行分析,发现每部电影的前面都带有'div',那就把所有div及其子页留下称为item,利用预先用正则表达式制定的规则对留下的东西的数据继续提取,提取出我们想要的数据。下面是放在全局变量中的正则表达式:
findlink = re.compile(r'<a href="(.*?)">',re.S)#让换行符包含在字符串中
findTitle =re.compile(r'<span class="title">(.*)</span>')
findImgSrc =re.compile(r'<img.*src="(.*?)"',re.S)
3.保存数据
def saveData(datalist,savepath):
book =xlwt.Workbook(encoding="utf-8")
sheet = book.add_sheet('豆瓣Top250')
col=("电影详情链接","图片","片名")
for i in range(0,3):
sheet.write(0,i,col[i])
for i in range(0,250):
print("第%d条"%(i+1))
data=datalist[i]
for j in range(0,3):
sheet.write(i+1,j,data[j])
book.save('student.xls')
这里呢是将数据保存在了excel中,毕竟只有250行,如果有几万行的话就必须要用数据库了。存完的效果是这样的:
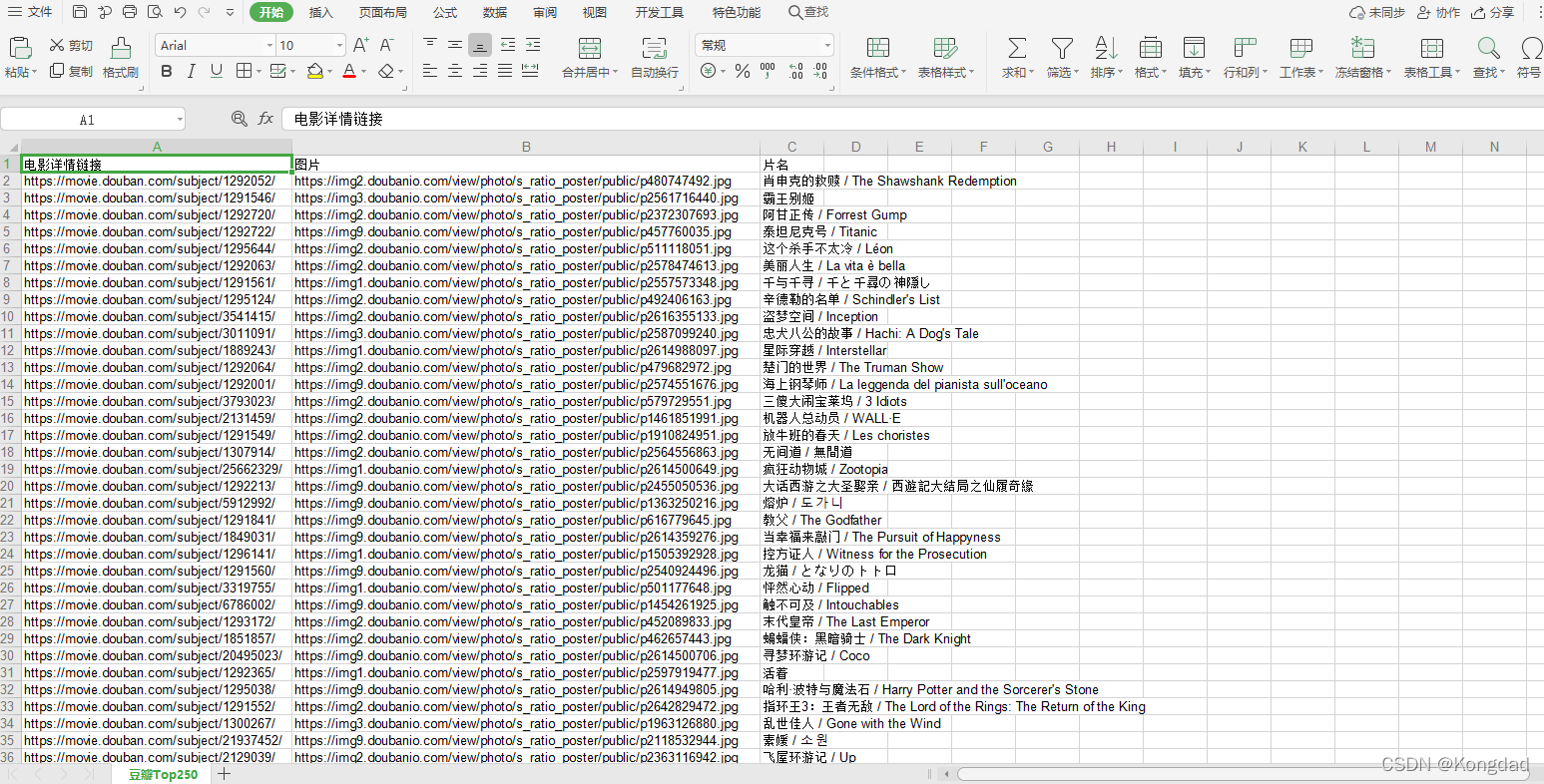
接下来我将会对数据进行可视化,欲知如何,还听下回分解。
本文只是对思路进行了梳理,具体的学术性问题没有遍及,还请谅解。