HBase由于存储特性和读写性能,在OLAP即时分析中发挥重要作用,Rowkey的设计好坏关乎到HBase的使用情况。
我们知道HBase中定位一条数据需要四个维度的限制:RowKey,Column Family,Column Qualifier,Timestamp。RowKey是其中最容易出错的,不仅需要根据业务和查询需求来设计,还有很多地方需要关注。
RowKey是什么?
HBase中RowKey可以唯一标识一行记录,在HBase查询时会有几种形式:
- 通过get方式,指定RowKey获取唯一一条记录。
- 通过scan方式,设置startRow和stopRow参数进行范围匹配。
- 全表扫描,直接扫描整表所有数据。
RowKey字面上来看,就是行键意思,在增删改查中充当主键,它可以使任意字符串,在HBase内部RowKey保存为字节数组。
HBase中的数据是按照RowKey的ASCII字典顺序进行全局排序的,因此在设计RowKey时,要利用排序存储的特性,将经常读取的行存储到一起,避免做全表扫描。
数据热点?
不合理的RowKey设计产生热点问题,热点发生在大量的客户端直接访问集群的一个或极少数个节点(访问可能为读或写or其他操作)。
大量的访问使热点region所在的单个机器超出自身承受能力,引起性能下降甚至导致region不可用,也将影响到同一个RegionServer上的其他region,由于主机无法服务其他region请求,就造成数据热点的现象。
所以在向HBase中插入数据时,应该优化RowKey的设计,使数据被写入集群的多个region中,尽量将记录均衡的分散到不同的region中,平衡每个region的压力。
怎么避免热点问题?
主要的方法有反转,加盐和哈希。
反转
把固定长度或数字格式的RowKey进行反转,反转分为数据反转和时间戳反转,常用时间戳反转。
-
反转固定格式的数值以手机号为例,手机号的前缀变化比较少(如152、185等),但后半部分变化很多。如果将它反转过来,可以有效地避免热点。不过其缺点就是失去了有序性。
-
反转时间这个操作严格来讲不算“打散”,但可以调整数据的时间排序。如果将时间按照字典序排列,最近产生的数据会排在旧数据后面。如果用一个大值减去时间(比如用99999999减去yyyyMMdd,或者Long.MAX_VALUE减去时间戳),最新的数据就可以排在前面了。
加盐
在RowKey前添加一些前缀,加盐的前缀种类越多,RowKey被打的越散。
需要注意的是分配的随机前缀的种类数量应该和想把数据分散到那些region的数量一致。这样,加盐后的RowKey才会根据随机生成的前缀分散到各个region中,避免热点现象。
哈希
哈希和加盐的适用场景类似,但前缀不可以是随机的,因为必须要让客户端能完整的重构RowKey,所以一般会拿原RowKey或其一部分计算Hash值,然后再对Hash值做运算作为前缀。
RowKey设计原则
HBase提出的设计原则主要有:长度原则,唯一原则,排序原则和散列原则。
长度原则
RowKey是一个二进制码流,可以是任意字符串,最大长度为64kb,实际应用中一般为10-100bytes,以byte[]形式保存,一般设计成定长,建议越短越好,不要超过十六个字节,原因是:
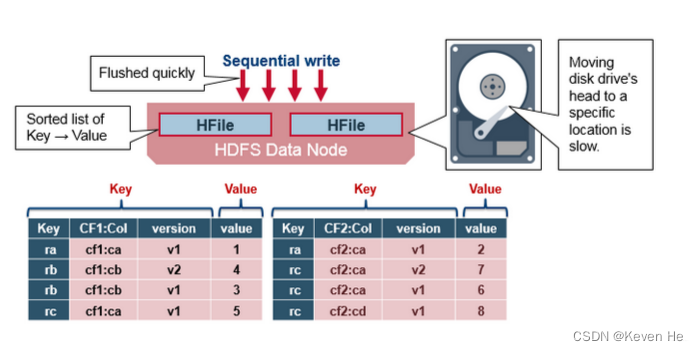
- 在 HBase 的底层存储 HFile 中,RowKey 是 KeyValue 结构中的一个域。假设 RowKey 长度 100B,那么 1000 万条数据中,光 RowKey 就占用掉 100*1000w=10亿个字节 将近 1G 空间,这样会极大影响 HFile 的存储效率。
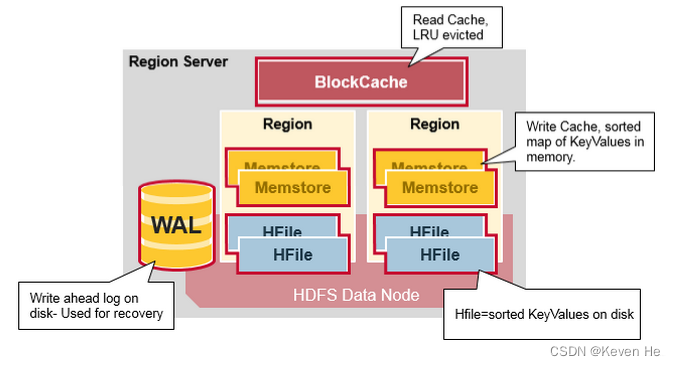
- HBase 中设计有 MemStore 和 BlockCache,分别对应列族/Store 级别的写入缓存,和 RegionServer 级别的读取缓存。如果 RowKey 字段过长,内存的有效利用率就会降低,系统不能缓存更多的数据,这样会降低检索效率。
此外,目前使用的基于64位的操作系统,内存是按照8B对齐的,所以设计RowKey时一般做成8B的整数倍,如16B或者24B,可以提高寻址效率。
同样,列族、列名的命名在保证可读的情况下也应尽量短。value 永远和它的 key 一起传输的。当具体的值在系统间传输时,它的 RowKey,列名,时间戳也会一起传输(因此实际上列族命名几乎都用一个字母,比如‘c’或‘f’)。如果RowKey和列名和值相比较较大,Hfile中的索引最终占据了HBase分配的大量内存。
唯一原则
由于RowKey用来唯一标识一行记录,所以必须在设计上保证RowKey的唯一性。
由于 HBase 中数据存储的格式是 Key-Value 对格式,所以如果向 HBase 中同一张表插入相同 RowKey 的数据,则原先存在的数据会被新的数据给覆盖掉(和 HashMap 效果相同)。
排序原则
RowKey是按照字典顺序排序存储的,所以设计RowKey时,利用排序特性,将经常读取的数据存储到一起,将最近可能访问的数据放到一起。
一个常见的数据处理问题是快速获取数据的最近版本,使用反转的时间戳作为 RowKey 的一部分对这个问题十分有用,可以用 Long.Max_Value-timestamp追加到key的末尾。
例如 [key][reverse_timestamp] , [key]的最新值可以通过scan [key]获得[key]的第一条记录,因为 HBase 中 RowKey 是有序的,第一条记录是最后录入的数据。
散列原则
散列原则就是设计出来的RowKey需要能均匀的分布到各个RegionServer上。
比如设计RowKey时,当RowKey是按时间戳的方式递增,就不要将时间放在二进制码的前面,可以将RowKey的高位作为散列字段,由程序循环生成,可以在低位放时间字段,这样就可以提高数据均衡分布在每个RegionServer实现负载均衡的几率。
如果没有散列字段,首字段只有时间信息,那就会出现所有新数据都在一个 RegionServer 上堆积的热点现象,这样在做数据检索的时候负载将会集中在个别 RegionServer 上,降低查询效率。