内容来源:饺子博士and饭老师
目录
一、概率统计基础工具
二、图模型
三、结构因果模型
四、辛普森悖论
五、D-分隔
六、模型检验和等价类
七、乘积分解法则
八、混淆变量
九、A/B test
十、总结
一、概率统计基础工具
1. 随机事件A,则对应概率为P(A);
2. 条件概率:
如果 ,则
,则 ;
;
如果 ,则
,则 ;
;
3. 独立事件的条件概率:
 (A、B独立);
(A、B独立);
4. 条件独立的条件概率:
 (在C的条件下,A、B独立);
(在C的条件下,A、B独立);
5. 随机变量的条件概率:
P(X = x | Y = y) = P(X = x);
6. 如果 ,
,
7. 贝叶斯定理:

8. 期望:



9. 条件期望:

10. 方差:


11. 协方差:
![Cov(X, Y) = E[(X-E(X))(Y - E(Y))]](https://latex.csdn.net/eq?Cov%28X%2C%20Y%29%20%3D%20E%5B%28X-E%28X%29%29%28Y%20-%20E%28Y%29%29%5D)

12. 相关系数:


13. 回归方程:

 liner regression
liner regression
 addtive model
addtive model
 kernel SVM
kernel SVM
 regression tree
regression tree
 random forest
random forest
14. 独立可以推出不相关,不相关无法推出独立
蒙提霍尔问题
令X代表玩家选择门号,即X = {1, 2, 3}
令Y代表汽车所在门号,即Y = {1, 2, 3}
令Z代表主持人所展示门号,即Z = {1, 2, 3}
在玩家选定1号门后主持人选定3号门的概率:





在Z = 3 ,X = 1的情况下,Y = 1的概率:




在Z = 3 ,X = 1的情况下,Y = 2的概率:




二、图模型
1. 相邻节点:

Y与X,Z相邻
2. 完全图:

3. 路径:
无向路径:
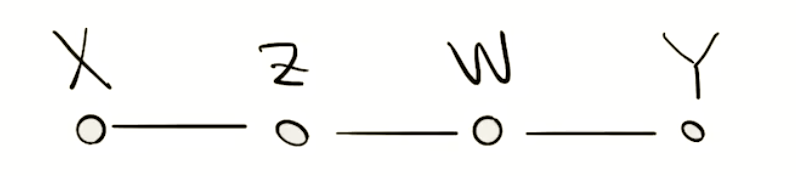
有向路径:

4. 父子节点:

5. 闭环:

6. 有向无环图:

三、结构因果模型
事件X通过方法导致事件Y的发生,可以描述为 。因为因果关系存在时间上线性关系,故
。因为因果关系存在时间上线性关系,故 。有时不仅仅只有一个“因”,即:
。有时不仅仅只有一个“因”,即: 。
。
因素也有可能是其他事件产生的现象,即因素可能不是直接因素。
 ,
, ,
,
图模型表示:
因果模型:

 因果模型:
因果模型:

 ,
, ,
, 因果模型:
因果模型:

, 因果模型:
因果模型:

其中X、W节点不由其他事件生成,称为外生变量,Z、Y 节点称为内生变量。
如果X、Y是统计相关,也不能证明X、Y之间存在因果性。如果X、Y是存在因果性,X、Y之间绝大多数是统计相关。
链状结构(Chain)

路径X->Y->Z构成链状结构。
相关性:
1. X与Y大多数是相关的;
2. Y与Z大多数是相关的;
3. Z与X大多数是相关的;
4. 在给定Y的情况下,Z与X是独立的,即X ⫫ Z | Y;
eg:
 ,
, ,
,
当 ,得
,得 ,Z只与
,Z只与 相关。
相关。
叉状结构(Fork)

其中X、Y、Z构成叉状结构。
相关性:
1. X与Y大多数是相关的;
2. X与Z大多数是相关的;
3. Z与Y大多数是相关的;
4. 在给定X的情况下,Z与Y是独立的,即Y ⫫ Z | X;
eg:
,,
当 ,得
,得 ,,Y只与
,,Y只与 相关,Z只与相关。
相关,Z只与相关。
对撞结构(Collider)

其中X、Y、Z构成对撞结构。
相关性:
1. X与Z大多数是相关的;
2. Y与Z大多数是相关的;
3. X与Y是独立的;
4. 在给定Z的情况下,X与Y是相关的,X ≡ Y | Z;
5. 在给定W的情况下,且W是Z的子孙节点,X与Y也是相关的,X ≡ Y | W;
四、辛普森悖论
当人们尝试探究两种变量(比如新生录取率与性别)是否具有相关性的时候,会分别对之进行分组研究。然而,在分组比较中都占优势的一方,在总评中有时反而是失势的一方。
分组与群体不同例子1(药物影响性):
分组数据:
男性
|
没恢复 |
恢复 |
总数 |
| 吃药 |
6 |
81 |
87 |
| 没吃药 |
36 |
234 |
270 |
女性
|
没恢复 |
恢复 |
总数 |
| 吃药 |
71 |
192 |
263 |
| 没吃药 |
25 |
55 |
80 |
群体数据:
|
没恢复 |
恢复 |
总数 |
| 吃药 |
77 |
273 |
350 |
| 没吃药 |
61 |
289 |
350 |
由上得:
|
X |
Y |
Z |
| 0 |
女性 |
没恢复 |
没吃药 |
| 1 |
男性 |
恢复 |
吃药 |






在分组中:


从数据上看吃药是对恢复有益的。
在群体中:

从数据上看吃药是对恢复有害的。

从图上看,性别也治疗效果是存在影响的。故存在因果模型如下所示:

性别、吃药和恢复构成叉状结构,因此要研究吃药和恢复之间是否有相关性,应该阻塞性别使得吃药和恢复独立。故应看分组数据进行分析。
分组与群体不同例子2(多种影响性):
|
没吃药 |
吃药 |
| 低血压 |
81/87(93%) |
234/270(87%) |
| 高血压 |
192/263(73%) |
55/80(69%) |
| 合并数据 |
270/350(78%) |
289/350(83%) |
显然,分组数据的效果是负向的,而群体数据的效果是正向的。血压对治疗效果有影响,同时,药物对血压也有影响。

血压、吃药和恢复构成链状结构,因此要研究吃药和恢复之间是否有相关性,不能阻塞血压的影响,这本身就是所研究的部分相关性,故应看群体数据进行分析。
五、D-分隔
D-分隔是一种用来判断变量是否条件独立的图形化方法。相比于非图形化方法,D-分隔更加直观,且计算简单。对于一个DAG图,D-分隔方法可以快速的判断出E中两个节点之间是否是条件独立的。
X、Y是D-分隔的 <=> X、Y独立
X、Y在条件Z下D-分隔 <=> X、Y独立 | Z
链状结构中:

X、Y是D-连通的,当阻塞Z可使得X、Y是D-分隔,X ⫫ Y | Z。
叉状结构中:

X、Y是D-连通的,当阻塞Z可使得X、Y是D-分隔,X ⫫ Y | Z。
对撞结构中:

X、Y是D-分隔的,因为Z阻塞了X、Y。当给定Z时,可使得X、Y具有相关性,X ≡ Y | Z
例子:

因为W属于对撞结构使得X、Y是D-分隔的。
六、模型检验和等价类
模型检验

图可以推出任意两个节点的统计相关性。数据可以进行统计分析,估计变量的统计相关性。若二者出现不一致问题,则可以认为模型假设错误。
eg:

从上图中可以推出: W ⫫  | X。若数据可以分析回归方程:
| X。若数据可以分析回归方程: ,则说明 W ≡ | X 。因此模型是错误的。
,则说明 W ≡ | X 。因此模型是错误的。
等价类

| 相关性 |
叉状结构 |
链状结构 |
| X ≡ Y |
✔︎ |
✔︎ |
| X ≡ Z |
✔︎ |
✔︎ |
| Y ≡ Z |
✔︎ |
✔︎ |
| X ≡ Y | Z |
✔︎ |
✔︎ |
| X ⫫ Z | Y |
✔︎ |
✔︎ |
| Y ≡ Z | X |
✔︎ |
✔︎ |

| 相关性 |
叉状结构 |
对撞结构 |
| X ≡ Y |
✔︎ |
✔︎ |
| X ≡ Z |
✔︎ |
✘ |
| Y ≡ Z |
✔︎ |
✔︎ |
| X ≡ Y | Z |
✔︎ |
✔︎ |
| X ⫫ Z | Y |
✔︎ |
✘ |
| Y ≡ Z | X |
✔︎ |
✔︎ |

| 相关性 |
G1 |
G2 |
| X ≡ Y |
✔︎ |
✔︎ |
| X ≡ Z |
✔︎ |
✔︎ |
| Y ≡ Z |
✔︎ |
✔︎ |
| X ≡ Y | Z |
✔︎ |
✔︎ |
| X ⫫ Z | Y |
✔︎ |
✔︎ |
| Y ≡ Z | X |
✔︎ |
✔︎ |
1. 链状结构与叉状结构是无法区分的,即等价;
2. 链状结构和叉状结构与对撞结构是可以区分的,即不等价;
3. 对状结构的相邻父节点存在有向边是无法区分的,即等价;
eg:

七、乘积分解法则
结构因果模型的相应图模型不是循环图时,变量的联合分布表示为:

其中 为节点
为节点 的所有父节点。
的所有父节点。
eg:



八、混淆变量
同时影响原因变量与结果变量的变量,称为混淆变量。例如分组与群体不同例子1中,性别为混淆变量;分组与群体不同例子2中,血压不是混淆变量,因为其是原因变量导致而影响结果变量。
剔除混淆变量
数据获取方式:
1. 观测数据,只是记录数据,不会数据的产生进行干涉;
2. 试验数据,对试验对象进行干涉,例如对照试验;
观测数据难以使用因果推断,试验数据易于使用因果推断。因此在随机试验中对试验对象进行干预,使得变量单一,便可剔除混淆变量。但是并不是所有的试验都可以通过随机试验来获得试验数据,而是通过观测数据。
九、A/B test
A/B test一般使用于互联网公司对新功能上线效果分析。其实现方式为:将线上流量进行分流,使得流量从服务器获得的数据不同,并在客户端观察并记录线上用户对此反应,后根据分析数据进行评价新功能的影响,从而做出决策。以网页为例,通过负载均衡等将线上流量分成A、B(可以更多,即AA/B test、AAA/B test,但都是A/B test),A流量获得新设计的页面,B流量依然获得旧页面。同时,在两个页面上进行点击统计(可以是留存等),分析两个页面之间的差异,从而决定是否进一步推流。
十、总结
事物普遍存在因果性,同时存在相关性混淆因果关系,因果推断就是有效“武器”。例如,张三是电商,他想发放优惠卷从而提高营业额,结果也如同他所想。但恰巧此时存在双十一活动,那提高营业额是因为优惠卷还是双十一便存在争议。如果对其做随机试验便可以清晰了解双方差异。
因果推断可以使用概率统计工具对试验数据进行分析,从而总结或者论证一个结构因果模型去阐述事物的因果性。也可以通过结构因果模型去生成数据或者对数据进行优化后分析,从而使得展示效果更加明显。
在机器学习中,特征之间是存在相关性和因果性的。在做决策和判断时,我们往往需要因果性,因此识别特征之间的因果性是必要的,而因果推断是重要武器。因果推断与机器学习的结合,是有双向促进作用的。