前言
YOLOLandmark解决了2D的人脸关键点检测问题,但3D任务仍然是个空白。我们能够在该领域继续突破呢?
一、任务列表
- 3D人脸关键点数据调研
- 3D FLD的评估策略有哪些
- 当前领先的技术方法达到了什么水平?
- 我们的方法实现:
- 数据集转为YOLO格式
- 修改YOLO8Pose的入口和出口
- 初步训练的性能,并对比
- 分析可行性,如何在此基础上取得突破
二、3D人脸关键点数据
主流的数据集
H3WB
github Link: HWWB
全称,H3WB: Human3.6M 3D WholeBody Dataset and Benchmark,它是一个大型的用于3D全身姿态估计的数据集,包含100K张图片标注。它扩展与Human3.6m数据集,共包含133个全身关键点,与COCO-whole body的标记规则一样。
样本标注如下:

2.下载方法
图片可以直接下载: Human3.6m
标记文件下载链接:datasets/json/
也可以通过脚本将Human3.6m视频转为包含图片与标注的对应集,参考 https://github.com/wholebody3d/wholebody3d
其中,json的标注方式如下:
XXX.json --- sample id --- 'image_path'
|
-- 'bbox' --- 'x_min'
| |- 'y_min'
| |- 'x_max'
| |- 'y_max'
|
|- 'keypont_2d' --- joint id --- 'x'
| |- 'y'
|
|- 'keypont_3d' --- joint id --- 'x'
|- 'y'
|- 'z'
3.任务
基于该数据集,提出了三种不同的任务:
-
任务一:2D—>3D
指的是从2D全身姿态提升到3D全身姿态。其主要做法是:
- 使用2Dto3D_train中的数据用于训练和验证。它包含80K的2D和3D关键点
- 使用2Dto3D_test中的数据用于测试。它包含10K的2D关键点
-
任务二:I2D—>3D
指的是不完整的2D全身姿态提升到3D的完整全身姿态。其流程如下:
- 使用2Dto3D_train中的数据用于训练和验证。它包含80K的2D和3D关键点
- 添加有概率的模版去掩盖,官方的策略是:
- 占比40%,每个关键点有25%概率被掩码;
- 占比20%,人脸100%概率被掩码;
- 占比20%,左手100%概率被掩码;
- 占比20%,右手100%概率被掩码;
- 使用2Dto3D_test_2D用于数据榜上的测试。它包含10K的2D关键点,区分于上述的10K数据。
-
任务三:RGB—>3D
指的是从一张图片直接预测3D全身姿态。其主要做法是:
- 使用RGBto3D_train中的数据用于训练和验证。它包含80K的图像路径,边界框和3D关键点
(源文档写成2D,应该有误)
- RGBto3D_train含有与2Dto3D_train相同的样本,因此有必要可以访问2D全关键点。
- 使用RGBto3D_test中的数据用于排行榜的测试。它包含20K的图像路径,边界框。
- 注意的是,测试样本的id和以上两个任务是不一致的。
4.评估
-
验证
作者没有提供validation集,作者提倡报告5-fold的交叉验证结果,并提供平均值和标准值。
-
在测试集上的评估
保存在测试集上的结果为XXXto3D_pred.json,并发送到邮箱: wholebody3d@gmail.com
可以参考官方样例:test set predictions
-
可视化
作者提供了两个可视化工具,一个是可视化3D全人体,另一个是在排行榜上的评估。
5.使用许可
遵从MIT许可,即非常宽泛的协议,只需要在你的源码中注明原作即可。作者不拥有这些图像的版权,它必须遵守Human3.6m的许可。
3DFAW
全称,3D Face Alignment in the Wild (3DFAW)。包含23K图片,带有66个3D人脸标注数据的集合。近期在ICCV workshop比较火,
第一届workshop和挑战赛在ECCV2016年被提出,其数据集可以从论文中发现:自然条件下的图像,或者合成的头像。

这里存在一个问题是:如果要做端到端的人脸和关键点联合检测,那么需要提供人脸边界框,也可以根据人脸关键点找出边界框,但对人脸检测的性能会有负面影响。
可参考github:https://github.com/1adrianb/face-alignment
ICCV2019年举办了第二次workshop和挑战赛。
参考:https://3dfaw.github.io/
3DFAW-Video提供如下的图像信息:

包含不同源的图像,比如iPhone拍摄的视频,以及高分辨率的视频,并采用Di4D成像系统来扫描高分辨率的3D人脸。该数据集的下载需要签署一个协议文件,并获得访问允许。
CVPR2023刚出了一篇,名叫《3D-aware Facial Landmark Detection via Multi-view Consistent Training on Synthetic Data》,提升了3DDFA的性能,但所谓的3D关键点还是二维信息,只不过需要借助3DMM模型来得到3D的顶点。这类方法需要基于大名鼎鼎的3DMM模型,与直接给出Z轴的深度信息还是有差别的。
这篇文章还提到两个数据集:
-
Multiface Dataset

-
DAD-3DHeads
A Large-scale Dense, Accurate and Diverse Dataset for 3D Head Alignment from a Single Image

这个数据集包含了原图,68个2D点,191个2D点,445个密集点;
下排:face mesh, head mesh, head pose, 3D head mesh.
AFLW2000-3D
Face Alignment Across Large Poses: A 3D Solution, 即AFLW2000-3D。它包含2000张图片,每个人脸含有68个3D关键点,主要用于评估作用。这个数据集的3D信息,也是通过3DMM模型得到的,在精度上会存在问题的争议。

三、3D关键点的Z维度信息
3D关键点在三维坐标系中除了XY面上的位置信息,还包括Z轴上的深度信息。对于在RGB图像上估计3D关键点,这本身就是一个难题。那么,当前的数据集以及一些SOTA的方法是如何估计3D姿态的呢?
1.基于3DMM模型的方法
3dffa就是当前流行的基于3dmm的方法。它不是直接的估计Z轴的深度信息,而是根据二维平面上的点坐标与三维的人脸模型之间进行的一个仿射变换,在归一化的三维空间上得到人脸姿态。
类似的数据集,如AFLW2000-3D,300W-LP等数据集。我们参考一些技术文档,可以详细打开这两个数据集的三维坐标。
例如,我们可视化300W-LP中的3D关键点不难发现,所谓的3D点其实也是用二维数据表述的

其中的pts_3d格式为68x2,也就是说该3D关键点实际上空间投影到2维平面上的投影.
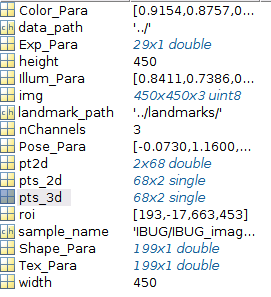
同理,我们也可以可视化AFLW2000-3D数据集

我们可以看到该数据集合是真正包含第三维度的信息,即3D预测是68x3的矩阵.

并且我们可视化3dmm后重构的人脸图

可以看到,通过给定3dmm的参数,可以线性表达人脸的构建.这里参考3dffa的代码,如果在linux平台上运行此matlab code可能需要重新编译linux下的相关函数.例如,
Error in NormDirection (line 17)
N = Tnorm_VnormC(double(n_tri), double(tri), double(size(tri,2)), double(size(vertex,2)));
Error in main_show_with_BFM (line 17)
norm = NormDirection(vertex, tri);
>> compile
Building with 'g++'.
Warning: You are using gcc version '7.5.0'. The version of gcc is not supported. The version currently supported with MEX is
'4.9.x'. For a list of currently supported compilers see: http://www.mathworks.com/support/compilers/current_release.
> In compile (line 1)
MEX completed successfully.
2.H3WB
这是本次调研第二个数据集在标签中包含Z轴信息的数据集。但具体可视化的结果,还在酝酿中。
四、当前SOTA的方法
1.方法1
最好是paper with code. 介绍下方法,从框架、模块、损失函数等方面,并对比性能如何
五、我们的解决方法
1.数据转为YOLO格式
最好是paper with code. 介绍下方法,从框架、模块、损失函数等方面,并对比性能如何
2.修改YOLO8Pose的入口出口
3.开始训练,并记录过程
4.对比分析
5.改进
主要记录如何改进的,并记录结果。与baseline对比,取得的效果是如何?
总结
牢记使命,多发高水平的文章,在AI竞赛中处于上游地位。