
目录
一,new
1.malloc,realloc,calloc的使用不便之处
2.new的好处
3.opreator new
二,delete
1.为什么要有delete?
2.为什么要匹配使用?
一,new
1.malloc,realloc,calloc的使用不便之处
在C语言中,为了申请堆上的空间我们便有了malloc ,realloc,calloc三个函数。malloc函数是最基本的动态内存申请函数。realloc在第一个指针型参数为NULL时是和malloc一样的,但是在第一个参数不为NULL时realloc函数开辟空间的方式有两种:1.原地扩容,2.异地扩容。
calloc函数与malloc函数开辟空间的方式都是一样的,但是calloc函数在开辟int*类型的空间时会有将空间内的数据初始化为0的行为。
但是不管如何,这三个函数的使用方法都是差不多的。而且还有点麻烦:
1.因为这三个函数在使用时返回的都是void*类型的数据,所以在使用这三个函数开辟内存时都要有强转的操作。
2.使用时要计算类型的大小。
3.不能随意初始化。
2.new的好处
为了搞定上面的问题,祖师爷便搞出了new这个操作符。记住,new是一个操作符。new该怎么用呢?
1.new一个对象:new+类型。
2.如果要初始化:new+类型+(要初始化的值)。
3.new多个对象:new+类型+[个数]。
4.初始化多个对象:new +类型+[个数]+{初始化的值1,初始化的值2,……},若是整型则未被初始化的剩余空间的数据被初始化为0。
如:
int* p1 = new int;
cout << "p1:"<<p1 << endl;
int* p2 = new int(10);
cout << "p2:" << *p2 << endl;
int* p3 = new int[6];
cout << "p3:" << p3 << endl;
int* p4 = new int[6]{ 1,2,3,4,5 };
cout << "p4:";
for (int i = 0;i < 6;i++)
{
cout << p4[i] << " ";
}
cout << endl;
结果:

但是new的好处其实主要体现在对自定义类型的空间开辟上,比如说以前定义的栈。如果用malloc开辟空间并初始化的话就是这样的:
class Stack {
public:
Stack()
{
cout << "Stack" << endl;
}
Stack(Stack& stack)
{
}
~Stack()
{
cout << "~Stack" << endl;
}
void Init(int size = 4)
{
_arr = nullptr;
_top = 0;
_size = 0;
}
private:
int* _arr;
int _top;
int _size;
};
int main()
{
Stack* st = (Stack*)malloc(sizeof(Stack));
st->Init();
return 0;
}
为了初始化那就得多写一个初始化函数。但是用new该怎么写呢?用new的话就不用再多写一个init初始化函数了,直接在构造函数里初始化便可以了。这也是用new开辟一个自定义类型的对象的特点——对自动调用构造函数初始化象。用new申请空间代码如下:
class Stack
{
public:
Stack()
{
_arr = (int*)malloc(sizeof(Stack)*4);
_top = 0;
_size = 0;
}
Stack(Stack& st)
{
}
~Stack()
{
}
private:
int* _arr;
int _top;
int _size ;
};
int main()
{
//Stack* st = (Stack*)malloc(sizeof(Stack));
//st->Init();
Stack* st = new Stack;
return 0;
}
这样就比malloc函数申请空间的做法简洁多了。总结一下,使用new的最方便的一点就是在申请一个类对象时能够自动调用构造函数初始化,从而不用我们来重新写一个初始化函数来初始化。
3.opreator new
operator new可不是一个函数重载。这个operator new其实可以理解为一个封装。什么的封装呢?其实就是malloc与try……catch的封装。这个operator new 其实也就是new这个操作符实现的一个关键的组成部分。进一步说new其实就是operator new和构造函数的封装。现在可以来看看new的底层:

operator new的底层:

这东西我暂时还讲解不清,了解一下operator new便可以了。
二,delete
和new一样delete是Cpp中定义的一个操作符。这个操作符便是和new配合着使用的。和free一样,这个操作符是可以用来释放空间的防止内存泄漏的。delete的用法如下:
1.delete+变量:释放一个申请的一个变量的大小。
2.delete+[ ]:释放申请的多个空间的大小。
在这里一定要注意的是要匹配使用,不然会发生错误的。
1.为什么要有delete?
其实这里的原因和new一样,delete出现的最大价值是针对于自定义类型的。delete也可以看作是free+析构函数的封装。再剖析一下,其实delete就是operator delete+析构函数的封装,其实就是try……catch+free+析构函数的封装。因为delete能够调用析构函数,所以delete便可以很好的释放自定义类型的空间。
2.为什么要匹配使用?
其实对于一般的类型其实不匹配使用也没多大问题(会有内存泄漏但是不报错),但是对于有析构函数的自定义类型不匹配使用便会报错。如对有析构函数的栈:
class Stack
{
public:
Stack()
{
_arr = (int*)malloc(sizeof(Stack)*4);
_top = 0;
_size = 0;
}
Stack(Stack& st)
{
}
~Stack()
{
cout<<"~Stack"<<endl;
}
private:
int* _arr;
int _top;
int _size ;
};
int main()
{
Stack* p = new Stack[10];
delete p;//没有匹配调用delete
return 0;
}
就会出错:
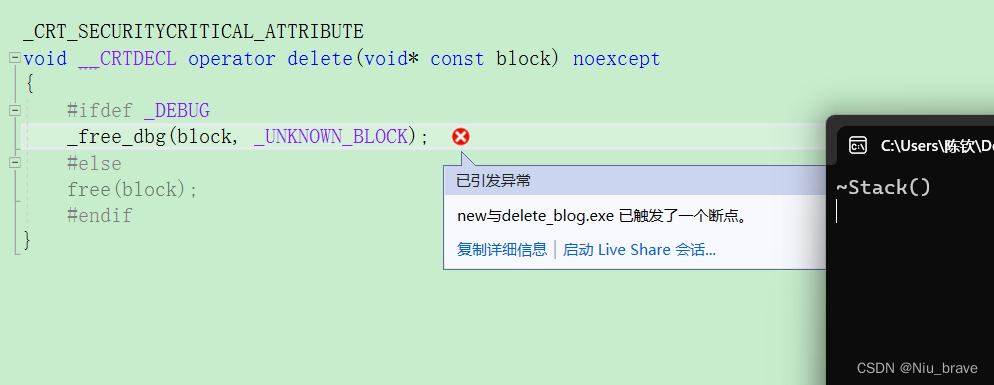
匹配调用后:
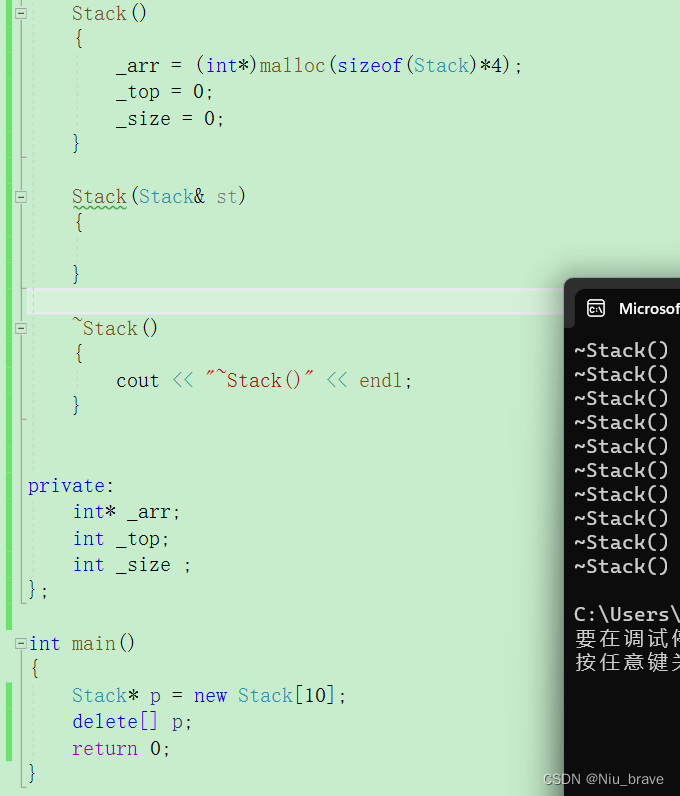
便是可运行的。
但是,在我屏蔽掉析构函数后再不匹配调用:
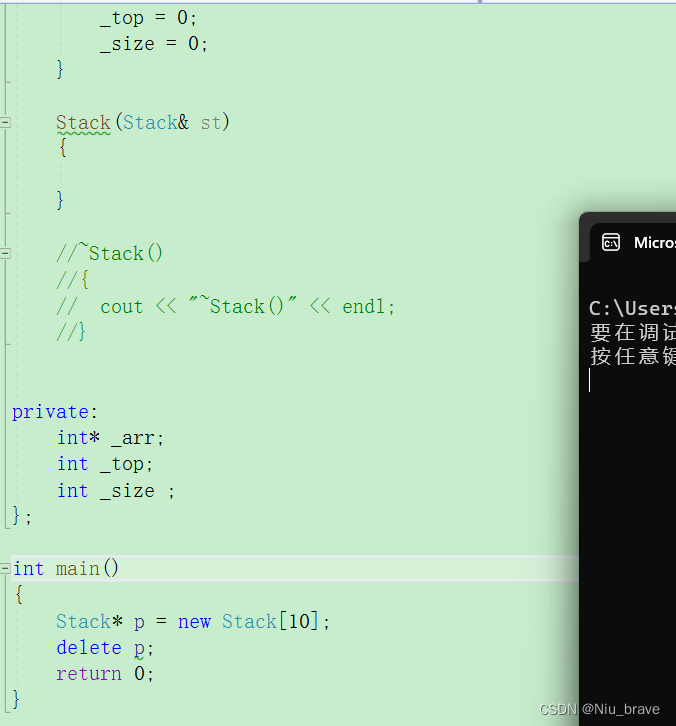
便又是可运行的了(有内存泄露问题)。这到底是为什么呢? 解答如下:
其实这就是因为释放内存空间的位置不对。假如我new出来的对象是n个有析构函数的对象,那Cpp底层就会在原来的地址伤向前偏移四个字节用来存放n这个整型。
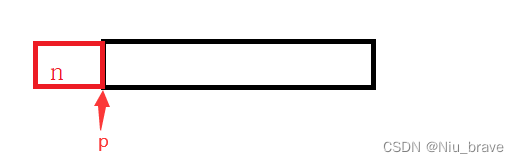
即使开多了四个字节的空间,但是我的p还是在原来的位置上。此时用delete与delete[ ]就决定了我是否要向前偏移四个字节。若用delete[ ]就会向前偏移四个字节取到前面四个字节储存的数据再释放,这样释放的位置便是对的便可以正常运行。但是用的是delete就不会发生偏移,释放的位置错了便会报错程序便会运行不下去。
但是,假如我new出来的对象是没有析构函数的话就不会在p的前面申请四个字节的空间。此时释放的话虽然有内存泄漏的问题但是却不会因为报错而运行不下去。总结一句,就是释放内存的位置不对。