一、序言
(一)背景内容
软件应用技术架构中DAO层最常见的选型组件为MyBatis,熟悉MyBatis的朋友都清楚,曾几何时MyBatis是多么的风光,使用XML文件解决了复杂的数据库访问的难题。时至今日,曾经的屠龙者终成恶龙,以XML文件为基础的数据库访问技术变得臃肿、复杂,维护难度直线上升。
MybatisPlus对常见的数据库访问进行了封装,访问数据库大大减少了XML文件的依赖,开发者从臃肿的XML文件中获得了较大限度的解脱。
MybatisPlus官方并没有提供多表 连接查询 的通用解决方案,然而连接查询是相当普遍的需求。解决连接查询有两种需求,一种是继续使用MyBatis提供XML文件解决方式;另一种本文提供的解决方案。
事实上笔者强烈推荐彻底告别通过XML访问数据库,并不断探索新式更加友好、更加自然的解决方式,现分享最新的MybatisPlus技术的研究成果。
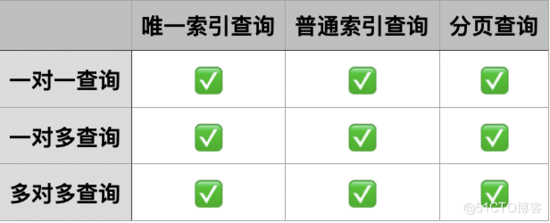
(二)场景说明
为了说明连接查询的关系,这里以学生、课程及其关系为示例。

(三)前期准备
此部分需要读者掌握以下内容:Lambda 表达式、特别是方法引用;函数式接口;流式运算等等,否则理解起来会有些吃力。
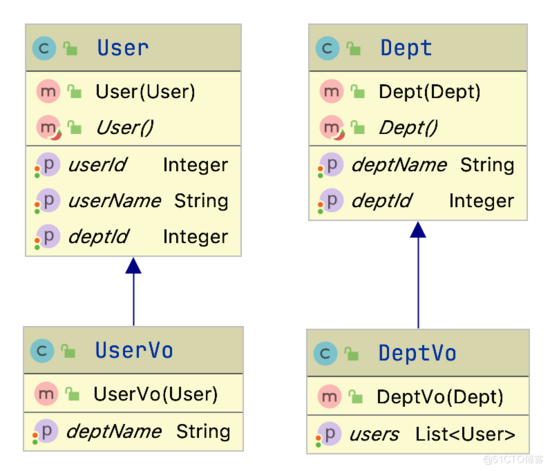
实体类与 Vo 的映射关系,作者创造性的引入特别构造器,合理利用继承关系,极大的方便了开发者完成实体类向 Vo 的转换。
空指针异常忽略不处理,借助 Optional 类实现,详情移步 Java8 新特性 查看。
二、一对一查询
一对一查询最典型的应用场景是将 id 替换成 name ,比如将 userId 替换成 userName 。
(一)查询单条记录
查询单条记录是指返回值仅有一条记录,通常是以唯一索引作为条件的返回查询结果。
1、示例代码
/**
* 查询单个学生信息(一个学生对应一个部门)
*/
public UserVo getOneUser(Integer userId) {
LambdaQueryWrapper<User> wrapper = Wrappers.lambdaQuery(User.class)
.eq(User::getUserId, userId);
// 先查询用户信息
User user = userMapper.selectOne(wrapper);
// 转化为Vo
UserVo userVo = Optional.ofNullable(user).map(UserVo::new).orElse(null);
// 从其它表查询信息再封装到Vo
Optional.ofNullable(userVo).ifPresent(this::addDetpNameInfo);
return userVo;
}
附属表信息补充
/**
* 补充部门名称信息
*/
private void addDetpNameInfo(UserVo userVo) {
LambdaQueryWrapper<Dept> wrapper = Wrappers.lambdaQuery(Dept.class)
.eq(Dept::getDeptId, userVo.getDeptId());
Dept dept = deptMapper.selectOne(wrapper);
Optional.ofNullable(dept).ifPresent(e -> userVo.setDeptName(e.getDeptName()));
}
2、理论分析
查询单个实体共分为两个步骤:根据条件查询主表数据(需处理空指针异常);封装 Vo 并查询附属表数据。
查询结果(VO)只有一条记录,需要查询两次数据库,时间复杂度为 O(1) 。
(二)查询多条记录
查询多条记录是指查询结果为列表,通常是指以普通索引为条件的查询结果。
1、示例代码
/**
* 批量查询学生信息(一个学生对应一个部门)
*/
public List<UserVo> getUserByList() {
// 先查询用户信息(表现形式为列表)
List<User> user = userMapper.selectList(Wrappers.emptyWrapper());
List<UserVo> userVos = user.stream().map(UserVo::new).collect(toList());
// 此步骤可以有多个
addDeptNameInfo(userVos);
return userVos;
}
附属信息补充
private void addDeptNameInfo(List<UserVo> userVos) {
// 提取用户userId,方便批量查询
Set<Integer> deptIds = userVos.stream().map(User::getDeptId).collect(toSet());
// 根据deptId查询deptName(查询前,先做非空判断)
List<Dept> dept = deptMapper.selectList(Wrappers.lambdaQuery(Dept.class).in(Dept::getDeptId, deptIds));
// 构造映射关系,方便匹配deptId与deptName
Map<Integer, String> hashMap = dept.stream().collect(toMap(Dept::getDeptId, Dept::getDeptName));
// 封装Vo,并添加到集合中(关键内容)
userVos.forEach(e -> e.setDeptName(hashMap.get(e.getDeptId())));
}
2、理论分析
先查询包含 id 的列表记录,从结果集中析出 id 并转化成批查询语句再访问数据库,从第二次调用结果集中解析出 name 。
查询结果(VO)有多条记录,但仅调用两次数据库,时间复杂度为 O(1) 。
(三)查询多条记录(分页)
分页查询实体的思路与查询列表的思路相似,额外多处一步分页泛型转换。
1、示例代码
/**
* 分页查询学生信息(一个学生对应一个部门)
*/
public IPage<UserVo> getUserByPage(Page<User> page) {
// 先查询用户信息
IPage<User> xUserPage = userMapper.selectPage(page, Wrappers.emptyWrapper());
// 初始化Vo
IPage<UserVo> userVoPage = xUserPage.convert(UserVo::new);
if (userVoPage.getRecords().size() > 0) {
addDeptNameInfo(userVoPage);
}
return userVoPage;
}
查询补充信息
private void addDeptNameInfo(IPage<UserVo> userVoPage) {
// 提取用户userId,方便批量查询
Set<Integer> deptIds = userVoPage.getRecords().stream().map(User::getDeptId).collect(toSet());
// 根据deptId查询deptName
List<Dept> dept = deptMapper.selectList(Wrappers.lambdaQuery(Dept.class).in(Dept::getDeptId, deptIds));
// 构造映射关系,方便匹配deptId与deptName
Map<Integer, String> hashMap = dept.stream().collect(toMap(Dept::getDeptId, Dept::getDeptName));
// 将查询补充的信息添加到Vo中
userVoPage.convert(e -> e.setDeptName(hashMap.get(e.getDeptId())));
}
IPage 接口中 convert 方法,能够实现在原实例上修改。
2、理论分析
先查询包含 id 的列表记录,从结果集中析出 id 并转化成批查询语句再访问数据库,从第二次调用结果集中解析出 name 。
查询结果(VO)有多条记录,但仅调用两次数据库,时间复杂度为 O(1) 。
三、一对多查询
一对多查询最常见的场景是查询部门所包含的学生信息,由于一个部门对应多个学生,每个学生对应一个部门,因此称为一对多查询。
(一)查询单条记录
1、示例代码
/**
* 查询单个部门(其中一个部门有多个用户)
*/
public DeptVo getOneDept(Integer deptId) {
// 查询部门基础信息
LambdaQueryWrapper<Dept> wrapper = Wrappers.lambdaQuery(Dept.class).eq(Dept::getDeptId, deptId);
DeptVo deptVo = Optional.ofNullable(deptMapper.selectOne(wrapper)).map(DeptVo::new).orElse(null);
Optional.ofNullable(deptVo).ifPresent(this::addUserInfo);
return deptVo;
}
补充附加信息
private void addUserInfo(DeptVo deptVo) {
// 根据部门deptId查询学生列表
LambdaQueryWrapper<User> wrapper = Wrappers.lambdaQuery(User.class).eq(User::getDeptId, deptVo.getDeptId());
List<User> users = userMapper.selectList(wrapper);
deptVo.setUsers(users);
}
2、理论分析
整个过程共分为两个阶段:通过部门表中主键查询指定部门信息,通过学生表中部门ID外键查询学生信息,将结果合并,形成返回值(Vo)。
一对多查询单条记录整个过程至多需要调用2次数据库查询,查询次数为常数,查询时间复杂度为 O(1) 。
(二)查询多条记录
1、示例代码
/**
* 查询多个部门(其中一个部门有多个用户)
*/
public List<DeptVo> getDeptByList() {
// 按条件查询部门信息
List<Dept> deptList = deptMapper.selectList(Wrappers.emptyWrapper());
List<DeptVo> deptVos = deptList.stream().map(DeptVo::new).collect(toList());
if (deptVos.size() > 0) {
addUserInfo(deptVos);
}
return deptVos;
}
补充附加信息
private void addUserInfo(List<DeptVo> deptVos) {
// 准备deptId方便批量查询用户信息
Set<Integer> deptIds = deptVos.stream().map(Dept::getDeptId).collect(toSet());
// 用批量deptId查询用户信息
List<User> users = userMapper.selectList(Wrappers.lambdaQuery(User.class).in(User::getDeptId, deptIds));
// 重点:将用户按照deptId分组
Map<Integer, List<User>> hashMap = users.stream().collect(groupingBy(User::getDeptId));
// 合并结果,构造Vo,添加集合列表
deptVos.forEach(e -> e.setUsers(hashMap.get(e.getDeptId())));
}
2、理论分析
整个过程共分为三个阶段:通过普通索引从部门表中查询若干条记录;将部门ID转化为批查询从学生表中查询学生记录;将学生记录以部门ID为单位进行分组,合并结果,转化为Vo。
一对多查询多条记录需要调用2次数据库查询,查询次数为常数,查询时间复杂度为 O(1) 。
(三)查询多条记录(分页)
1、示例代码
/**
* 分页查询部门信息(其中一个部门有多个用户)
*/
public IPage<DeptVo> getDeptByPage(Page<Dept> page) {
// 按条件查询部门信息
IPage<Dept> xDeptPage = deptMapper.selectPage(page, Wrappers.emptyWrapper());
IPage<DeptVo> deptVoPage = xDeptPage.convert(DeptVo::new);
if (deptVoPage.getRecords().size() > 0) {
addUserInfo(deptVoPage);
}
return deptVoPage;
}
查询补充信息
private void addUserInfo(IPage<DeptVo> deptVoPage) {
// 准备deptId方便批量查询用户信息
Set<Integer> deptIds = deptVoPage.getRecords().stream().map(Dept::getDeptId).collect(toSet());
LambdaQueryWrapper<User> wrapper = Wrappers.lambdaQuery(User.class).in(User::getDeptId, deptIds);
// 用批量deptId查询用户信息
List<User> users = userMapper.selectList(wrapper);
// 重点:将用户按照deptId分组
Map<Integer, List<User>> hashMap = users.stream().collect(groupingBy(User::getDeptId));
// 合并结果,构造Vo,添加集合列表
deptVoPage.convert(e -> e.setUsers(hashMap.get(e.getDeptId())));
}
2、理论分析
整个过程共分为三个阶段:通过普通索引从部门表中查询若干条记录;将部门ID转化为批查询从学生表中查询学生记录;将学生记录以部门ID为单位进行分组,合并结果,转化为Vo。
一对多查询多条记录需要调用2次数据库查询,查询次数为常数,查询时间复杂度为 O(1) 。
四、多对多查询
MybatisPlus 实现多对多查询是一件极富挑战性的任务,也是连接查询中最困难的部分。
以空间置换时间,借助于流式运算,解决多对多查询难题。
多对多查询相对于一对多查询,增加了流式分组运算、批量 HashMap 取值等内容。

(一)查询单条记录
查询单条记录一般是指通过两个查询条件查询出一条匹配表中的记录。
1、示例代码
public StudentVo getStudent(Integer stuId) {
// 通过主键查询学生信息
StudentVo studentVo = ConvertUtils.convertObj(getById(stuId), StudentVo::new);
LambdaQueryWrapper<StuSubRelation> wrapper = Wrappers.lambdaQuery(StuSubRelation.class).eq(StuSubRelation::getStuId, stuId);
// 查询匹配关系
List<StuSubRelation> stuSubRelations = stuSubRelationMapper.selectList(wrapper);
Set<Integer> subIds = stuSubRelations.stream().map(StuSubRelation::getSubId).collect(toSet());
if (studentVo != null && subIds.size() > 0) {
List<Subject> subList = subjectMapper.selectList(Wrappers.lambdaQuery(Subject.class).in(Subject::getId, subIds));
List<SubjectBo> subBoList = ConvertUtils.convertList(subList, SubjectBo::new);
HashBasedTable<Integer, Integer, Integer> table = getHashBasedTable(stuSubRelations);
subBoList.forEach(e -> e.setScore(table.get(stuId, e.getId())));
studentVo.setSubList(subBoList);
}
return studentVo;
}
2、理论分析
多对多单条记录查询最多访问数据库3次,先查询学生信息,然后查询学生与课程匹配信息,最后查询课程分数信息,查询时间复杂度为 O(1) 。
(二)查询多条记录
1、示例代码
public List<StudentVo> getStudentList() {
// 通过主键查询学生信息
List<StudentVo> studentVoList = ConvertUtils.convertList(list(), StudentVo::new);
// 批量查询学生ID
Set<Integer> stuIds = studentVoList.stream().map(Student::getId).collect(toSet());
LambdaQueryWrapper<StuSubRelation> wrapper = Wrappers.lambdaQuery(StuSubRelation.class).in(StuSubRelation::getStuId, stuIds);
List<StuSubRelation> stuSubRelations = stuSubRelationMapper.selectList(wrapper);
// 批量查询课程ID
Set<Integer> subIds = stuSubRelations.stream().map(StuSubRelation::getSubId).collect(toSet());
if (stuIds.size() > 0 && subIds.size() > 0) {
HashBasedTable<Integer, Integer, Integer> table = getHashBasedTable(stuSubRelations);
List<Subject> subList = subjectMapper.selectList(Wrappers.lambdaQuery(Subject.class).in(Subject::getId, subIds));
List<SubjectBo> subjectBoList = ConvertUtils.convertList(subList, SubjectBo::new);
Map<Integer, List<Integer>> map = stuSubRelations.stream().collect(groupingBy(StuSubRelation::getStuId, mapping(StuSubRelation::getSubId, toList())));
for (StudentVo studentVo : studentVoList) {
// 获取课程列表
List<SubjectBo> list = ListUtils.select(subjectBoList, e -> emptyIfNull(map.get(studentVo.getId())).contains(e.getId()));
// 填充分数
list.forEach(e -> e.setScore(table.get(studentVo.getId(), e.getId())));
studentVo.setSubList(list);
}
}
return studentVoList;
}
2、理论分析
多对多N条记录查询由于使用了批查询,因此最多访问数据库也是3次,先查询学生信息,然后查询学生与课程匹配信息,最后查询课程分数信息,查询时间复杂度为 O(1) 。
(三)查询多条记录(分页)
1、示例代码
public IPage<StudentVo> getStudentPage(IPage<Student> page) {
// 通过主键查询学生信息
IPage<StudentVo> studentVoPage = ConvertUtils.convertPage(page(page), StudentVo::new);
// 批量查询学生ID
Set<Integer> stuIds = studentVoPage.getRecords().stream().map(Student::getId).collect(toSet());
LambdaQueryWrapper<StuSubRelation> wrapper = Wrappers.lambdaQuery(StuSubRelation.class).in(StuSubRelation::getStuId, stuIds);
// 通过学生ID查询课程分数
List<StuSubRelation> stuSubRelations = stuSubRelationMapper.selectList(wrapper);
// 批量查询课程ID
Set<Integer> subIds = stuSubRelations.stream().map(StuSubRelation::getSubId).collect(toSet());
if (stuIds.size() > 0 && subIds.size() > 0) {
HashBasedTable<Integer, Integer, Integer> table = getHashBasedTable(stuSubRelations);
// 学生ID查询课程ID组
Map<Integer, List<Integer>> map = stuSubRelations.stream().collect(groupingBy(StuSubRelation::getStuId, mapping(StuSubRelation::getSubId, toList())));
List<Subject> subList = subjectMapper.selectList(Wrappers.lambdaQuery(Subject.class).in(Subject::getId, subIds));
List<SubjectBo> subBoList = ConvertUtils.convertList(subList, SubjectBo::new);
for (StudentVo studentVo : studentVoPage.getRecords()) {
List<SubjectBo> list = ListUtils.select(subBoList, e -> emptyIfNull(map.get(studentVo.getId())).contains(e.getId()));
list.forEach(e -> e.setScore(table.get(studentVo.getId(), e.getId())));
studentVo.setSubList(list);
}
}
return studentVoPage;
}
2、理论分析
多对多N条记录分页查询由于使用了批查询,因此最多访问数据库也是3次,先查询学生信息,然后查询学生与课程匹配信息,最后查询课程分数信息,查询时间复杂度为 O(1) 。
五、总结与拓展
(一)总结
通过上述分析,能够用 MybatisPlus 解决多表连接查询中的 一对一 、 一对多 、 多对多 查询。
o(1)
(二)拓展
MybatisPlus能很好的解决单表查询问题,同时借助在单表查询的封装能很好地解决连接查询问题。
本方案不仅解决了连接查询问题,同时具备如下内容拓展:
当数据量达到百万级别时,传统的单表通过索引查询已经面临挑战,普通的多表连接查询性能随着数据量的递增呈现指数级下降。
本方案通过将连接查询转化为主键(索引)查询,查询性能等效于单表查询。
当所有的查询均转化为以单表为基础的查询后,方能安全的引入二级缓存。二级缓存的单表增删改查操作自适应联动,解决了二级缓存的脏数据问题。
原文地址: https://blog.51cto.com/u_15495434/4955709