
作者 | luanhz
来源 | 小数志
导读
机器学习中的一个经典理论是:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限。也正因如此,特征工程在机器学习流程中占有着重要地位。广义的特征工程一般可分为三个环节:特征提取、特征选择、特征衍生,三个环节并无明确的先手顺序之分。本文主要介绍三种常用的特征选择方法。

机器学习中的特征需要选择,人生又何尝不是如此?
特征选择是指从众多可用的特征中选择一个子集的过程,其目的和预期效果一般有如下三方面考虑:
改善模型效果,主要是通过过滤无效特征或者噪声特征来实现;
加速模型训练,更为精简的特征空间自然可以实现模型训练速度的提升
增强特征可解释性,这方面的作用一般不是特别明显,比如存在共线性较高的一组特征时,通过合理的特征选择可仅保留高效特征,从而提升模型的可解释性
另一方面,理解特征选择方法的不同,首先需要按照特征对训练任务的价值高低而对特征作出如下分类:
高价值特征,这些特征对于模型训练非常有帮助,特征选择的目的就是尽可能精准的保留这些特征
低价值特征,这些特征对模型训练帮助不大,但也属于正相关特征,在特征选择比例较低时,这些特征可以被舍弃;
高相关性特征,这些特征对模型训练也非常有帮助,但特征与特征之间往往相关性较高,换言之一组特征可由另一组特征替代,所以是存在冗余的特征,在特征选择中应当将其过滤掉;
噪声特征,这些特征对模型训练不但没有正向作用,反而会干扰模型的训练效果。有效的特征选择方法应当优先将其滤除。
在实际应用中,特征选择方法主要可分为如下三类:
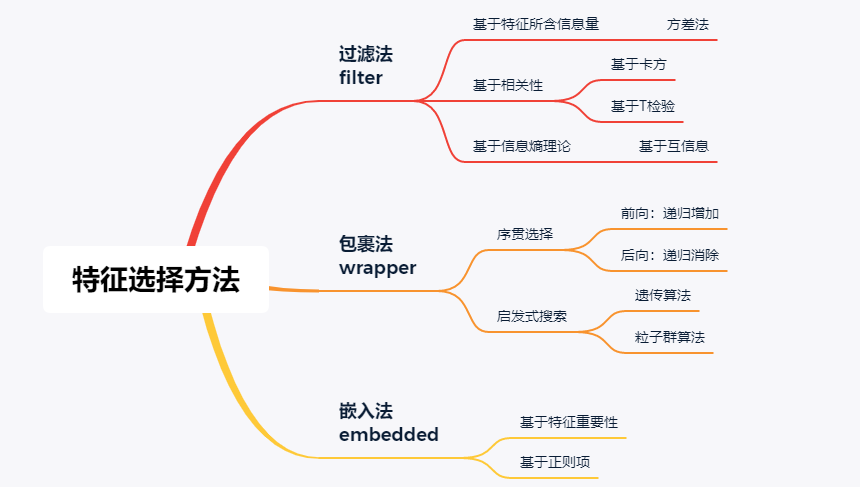
本文将围绕这三种方法分别介绍,最后以sklearn中自带的数据集为例给出简单的应用和效果对比。
01 过滤法
基于过滤法(Filter)实现特征选择是最为简单和常用的一种方法,其最大优势是不依赖于模型,仅从特征的角度来挖掘其价值高低,从而实现特征排序及选择。实际上,基于过滤法的特征选择方案,其核心在于对特征进行排序——按照特征价值高低排序后,即可实现任意比例/数量的特征选择或剔除。显然,如何评估特征的价值高低从而实现排序是这里的关键环节。
为了评估特征的价值高低,大体可分为如下3类评估标准:
基于特征所含信息量的高低:这种一般就是特征基于方差法实现的特征选择,即认为方差越大对于标签的可区分性越高;否则,即低方差的特征认为其具有较低的区分度,极端情况下当一列特征所有取值均相同时,方差为0,对于模型训练也不具有任何价值。当然,实际上这里倘若直接以方差大小来度量特征所含信息量是不严谨的,例如对于[100, 110, 120]和[1, 5, 9]两组特征来说,按照方差计算公式前者更大,但从机器学习的角度来看后者可能更具有区分度。所以,在使用方差法进行特征选择前一般需要对特征做归一化
基于相关性:一般是基于统计学理论,逐一计算各列与标签列的相关性系数,当某列特征与标签相关性较高时认为其对于模型训练价值更大。而度量两列数据相关性的指标则有很多,典型的包括欧式距离、卡方检验、T检验等等
基于信息熵理论:与源于统计学的相关性方法类似,也可从信息论的角度来度量一列特征与标签列的相关程度,典型的方法就是计算特征列与标签列的互信息。当互信息越大时,意味着提供该列特征时对标签的信息确定程度越高。这与决策树中的分裂准则思想其实是有异曲同工之妙
当然,基于过滤法的特征选择方法其弊端也极为明显:
02 包裹法
过滤法是从特征重要性高低的角度来加以排序,从而完成目标特征选择或者低效特征滤除的过程。如前所述,其最大的弊端之一在于因为不依赖任何模型,所以无法针对性的选择出相应模型最适合的特征体系。同时,其还存在一个隐藏的问题:即特征选择保留比例多少的问题,实际上这往往是一个超参数,一般需要人为定义或者进行超参寻优。
与之不同,包裹法将特征选择看做是一个黑盒问题:即仅需指定目标函数(这个目标函数一般就是特定模型下的评估指标),通过一定方法实现这个目标函数最大化,而不关心其内部实现的问题。进一步地,从具体实现的角度来看,给定一个含有N个特征的特征选择问题,可将其抽象为从中选择最优的K个特征子集从而实现目标函数取值最优。易见,这里的K可能是从1到N之间的任意数值,所以该问题的搜索复杂度是指数次幂:O(2^N)。
当然,对于这样一个具有如此高复杂度的算法,聪明的前辈们是不可能去直接暴力尝试的,尤其是考虑这个目标函数往往还是足够expensive的(即模型在特定的特征子集上的评估过程一般是较为耗时的过程),所以具体的实现方式一般有如下两种:
-
序贯选择。美其名曰序贯选择,其实就是贪心算法。即将含有K个特征的最优子空间搜索问题简化为从1->K的递归式选择(Sequential Feature Selection, SFS)或者从N->K的递归式消除(Sequential Backward Selection, SBS)的过程,其中前者又称为前向选择,后者相应的称作后向选择。
具体而言,以递归式选择为例,初始状态时特征子空间为空,尝试逐一选择每个特征加入到特征子空间中,计算相应的目标函数取值,执行这一过程N次,得到当前最优的第1个特征;如此递归,不断选择得到第2个,第3个,直至完成预期的特征数目K。这一过程的目标函数执行次数为O(K^2),相较于指数次幂的算法复杂度而言已经可以接受。当然,在实际应用过程中还衍生了很多改进算法,例如下面流程图所示:
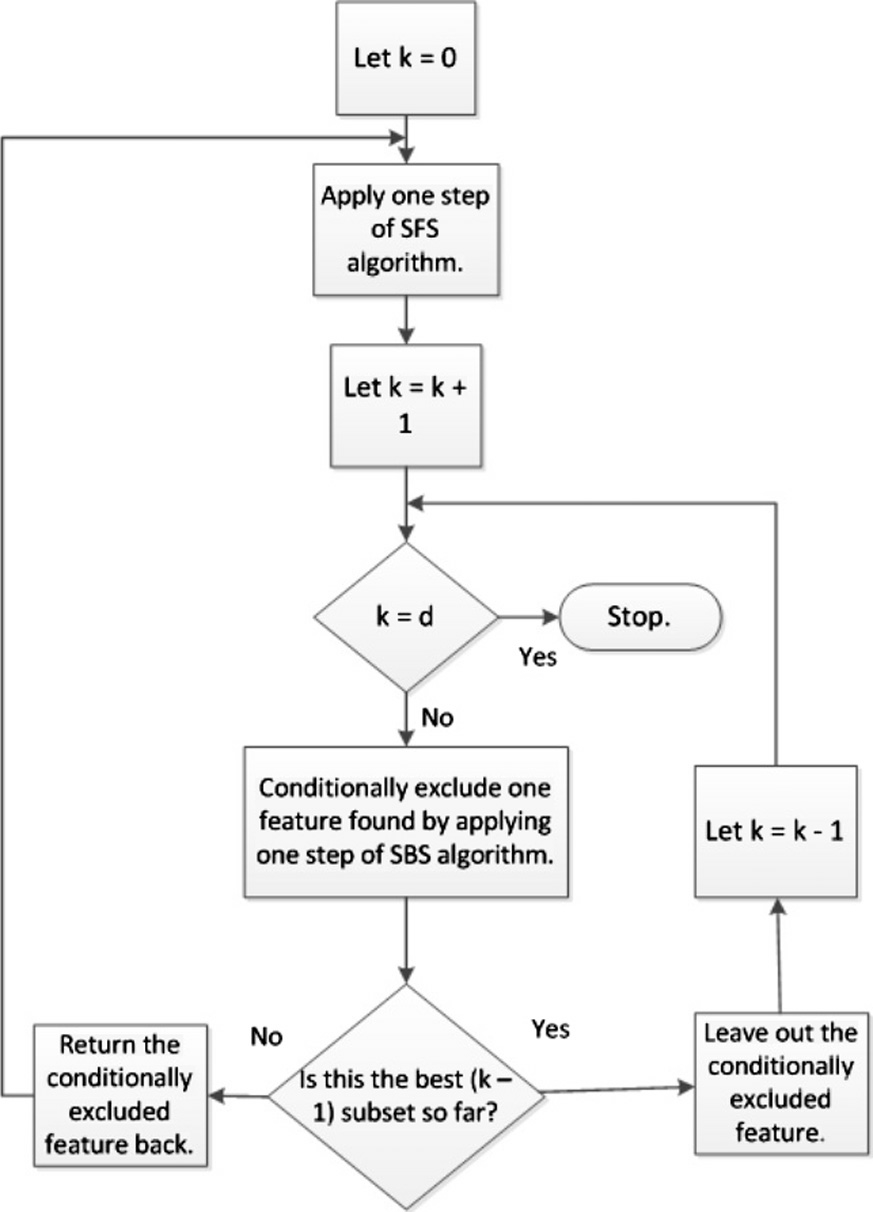
图源:《A survey on feature selection methods》
基于包裹法的特征选择方案是面向模型的实现方案,所以理论而言具有最佳的选择效果。但实际上在上述实现过程中,其实一般也需要预先指定期望保留的特征数量,所以也就涉及到超参的问题。此外,基于包裹法的最大缺陷在于巨大的计算量,虽然序贯选择的实现方案将算法复杂度降低为平方阶,但仍然是一个很大的数字;而以遗传算法和粒子群算法为代表的启发式搜索方案,由于其均是population-based的优化实现,自然也更是涉及大量计算。
03 嵌入法
与包裹法依赖于模型进行选择的思想相似,而又与之涉及巨大的计算量不同:基于嵌入法的特征选择方案,顾名思义,是将特征选择的过程"附着"于一个模型训练任务本身,从而依赖特定算法模型完成特征选择的过程。
个人一直以为,"嵌入"(embedded)一词在机器学习领域是一个很魔性的存在,甚至在刚接触特征选择方法之初,一度将嵌入法和包裹法混淆而不能感性理解。
实际上,行文至此,基于嵌入法的特征选择方案也就呼之欲出了,最为常用的就是树模型和以树模型为基础的系列集成算法,由于模型提供了特征重要性这个重要信息,所以其可天然的实现模型价值的高低,从而根据特征重要性的高低完成特征选择或滤除的过程。另外,除了决策树系列模型外,LR和SVM等广义线性模型也可通过拟合权重系数来评估特征的重要程度。
基于嵌入法的特征选择方案简洁高效,一般被视作是集成了过滤法和包裹法两种方案的优点:既具有包裹法中面向模型特征选择的优势,又具有过滤法的低开销和速度快。但实际上,其也具有相应的短板:不能识别高相关性特征,例如特征A和特征B都具有较高的特征重要性系数,但同时二者相关性较高,甚至说特征A=特征B,此时基于嵌入法的特征选择方案是无能为力的。
04 三种特征选择方案实战对比
本小节以sklearn中的乳腺癌数据集为例,给出三种特征选择方案的基本实现,并简单对比特征选择结果。
加载数据集并引入必备包:
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.feature_selection import SelectFromModel, SelectKBest, RFE
from sklearn.ensemble import RandomForestClassifier
默认数据集训练模型,通过在train_test_split中设置随机数种子确保后续切分一致:
%%time
X, y = load_breast_cancer(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=3)
rf = RandomForestClassifier(max_depth=5, random_state=3)
rf.fit(X_train, y_train)
rf.score(X_test, y_test)
# 输出结果
CPU times: user 237 ms, sys: 17.5 ms, total: 254 ms
Wall time: 238 ms
0.9370629370629371
过滤法的特征选择方案,调用sklearn中的SelectKBest实现,内部默认采用F检验来度量特征与标签间相关性,选择特征维度设置为20个:
%%time
X_skb = SelectKBest(k=20).fit_transform(X, y)
X_skb_train, X_skb_test, y_train, y_test = train_test_split(X_skb, y, random_state=3)
rf = RandomForestClassifier(max_depth=5, random_state=3)
rf.fit(X_skb_train, y_train)
rf.score(X_skb_test, y_test)
# 输出结果
CPU times: user 204 ms, sys: 7.14 ms, total: 211 ms
Wall time: 208 ms
0.9300699300699301
包裹法的特征选择方案,调用sklearn中的RFE实现,传入的目标函数也就是算法模型为随机森林,特征选择维度也设置为20个:
%%time
X_rfe = RFE(RandomForestClassifier(), n_features_to_select=20).fit_transform(X, y)
X_rfe_train, X_rfe_test, y_train, y_test = train_test_split(X_rfe, y, random_state=3)
rf = RandomForestClassifier(max_depth=5, random_state=3)
rf.fit(X_rfe_train, y_train)
rf.score(X_rfe_test, y_test)
# 输出结果
CPU times: user 2.76 s, sys: 4.57 ms, total: 2.76 s
Wall time: 2.76 s
0.9370629370629371
嵌入法的特征选择方案,调用sklearn中的SelectFromModel实现,依赖的算法模型也设置为随机森林,特征选择维度仍然是20个:
%%time
X_sfm = SelectFromModel(RandomForestClassifier(), threshold=-1, max_features=20).fit_transform(X, y)
X_sfm_train, X_sfm_test, y_train, y_test = train_test_split(X_sfm, y, random_state=3)
rf = RandomForestClassifier(max_depth=5, random_state=3)
rf.fit(X_sfm_train, y_train)
rf.score(X_sfm_test, y_test)
# 输出结果
CPU times: user 455 ms, sys: 0 ns, total: 455 ms
Wall time: 453 ms
0.9370629370629371
通过以上简单的对比实验可以发现:相较于原始全量特征的方案,在仅保留20维特征的情况下,过滤法带来了一定的算法性能损失,而包裹法和嵌入法则保持了相同的模型效果,但嵌入法的耗时明显更短。

往
期
回
顾
资讯
Meta开发AI语音助手,助力元宇宙
技术
Pandas重复数据处理大全
技术
5个短小精悍的Python趣味脚本
资讯
M2芯片终于要来了?全线换新

分享

点收藏

点点赞

点在看