将不同的分类器组合起来的方法被称为集成方法(ensemble method)或者元算法(meta-algorithm)。
使用集成方法时会有多种形式:可以是不同算法的集成,也可以是同一种算法在不同设置下的集成,还可以是数据集不同部分分配给不同分类器之后的集成。
7.1 集成方法
集成方法(ensemble method)通过组合多个基分类器(base classifier)来完成学习任务,基分类器一般采用的是弱可学习(weakly learnable)分类器,通过集成方法,组合成一个强可学习(strongly learnable)分类器。所谓弱可学习,是指学习的正确率仅略优于随机猜测的多项式学习算法;强可学习指正确率较高的多项式学习算法。集成学习的泛化能力一般比单一的基分类器要好,这是因为大部分基分类器都分类错误的概率远低于单一基分类器的。
集成方法主要包括Bagging和Boosting两种方法,Bagging和Boosting都是将已有的分类或回归算法通过一定方式组合起来,形成一个性能更加强大的分类器,更准确的说这是一种分类算法的组装方法,即将弱分类器组装成强分类器的方法。
7.1.1 bagging(自举汇聚法)
自举汇聚法(bootstrap aggregating),也称为bagging方法,是在从原始数据集选择S次后得到S个新数据集的一种技术,新数据集和原始数据集大小相等,每个数据集都是通过在原始数据集中随机选择一个样本来进行替换而得到的。替换就意味着可以多次选择同一个样本,即新数据集可以出现重复的值,而原始数据集中的某些值在新集合中则不再出现。
S个数据集建好之后,将某个学习算法分别作用于每个数据集就得到了S个分类器,当对新数据进行分类时,就可以应用这S个分类器进行分类。与此同时,选择分类器投票结果中最多的类别作为最后的分类结果。
Bagging对训练数据采用自举采样(boostrap sampling),即有放回地采样数据。
主要思想:
- 从原始样本集中抽取训练集。每轮从原始样本集中使用Bootstraping的方法抽取n个训练样本(在训练集中,有些样本可能被多次抽取到,而有些样本可能一次都没有被抽中)。共进行k轮抽取,得到k个训练集。(k个训练集之间是相互独立的)
- 每次使用一个训练集得到一个模型,k个训练集共得到k个模型。(注:这里并没有具体的分类算法或回归方法,我们可以根据具体问题采用不同的分类或回归方法,如决策树、感知器等)
- 对分类问题:将上步得到的k个模型采用投票的方式得到分类结果;对回归问题,计算上述模型的均值作为最后的结果。(所有模型的重要性相同)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-izYK0VyL-1663158003766)(//img-blog.csdn.net/2018031921472037?)]
7.1.2 随机森林(Random Forest,RF)
随机森林是Bagging的一个变体,在以决策树为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入了随机属性选择,具体来说就是传统决策树在选择划分属性时是在当前节点的属性集合(假设有d个属性),中选择一个最优属性,而在RF中,对基决策树的每个节点,先从该节点的属性集合中随机选择一个包含k个属性的子集,然后在从这个子集中选择一个最优属性用于划分。
参数k控制了随机性的引入程度,若令k=d,则基决策树的构建与传统的决策树相同,若令k=1,则是随机选择一个属性用于划分,一般情况下,推荐值
k
=
l
o
g
2
d
k=log_2d
k=log2d


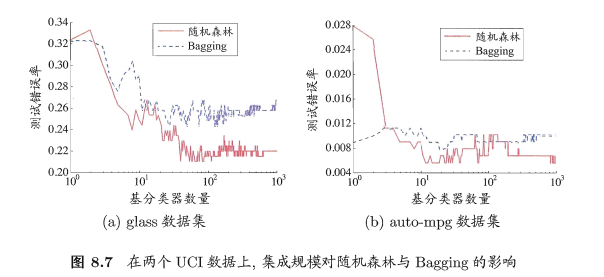
随机森林就是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,而它的本质属于机器学习的一大分支——集成学习(Ensemble Learning)方法。
随机:先从该节点的属性集合中随机选择一个包含k个属性的子集,然后在从这个子集中选择一个最优属性用于划分。
森林:成百上千棵决策树就可以叫做森林
直观解释:每棵决策树都是一个分类器(假设现在针对的是分类问题),那么对于一个输入样本,N棵树会有N个分类结果。而随机森林集成了所有的分类投票结果,将投票次数最多的类别指定为最终的输出,这就是一种最简单的 Bagging 思想。
随机森林的特点:
- 在当前所有算法中,具有极好的准确率/It is unexcelled in accuracy among current algorithms;
- 能够有效地运行在大数据集上/It runs efficiently on large data bases;
能够处理具有高维特征的输入样本,而且不需要降维/It can handle thousands of input variables without variable deletion;
- 能够评估各个特征在分类问题上的重要性/It gives estimates of what variables are important in the classification;
- 在生成过程中,能够获取到内部生成误差的一种无偏估计/It generates an internal unbiased estimate of the generalization error as the forest building progresses;
- 对于缺省值问题也能够获得很好得结果/It has an effective method for estimating missing data and maintains accuracy when a large proportion of the data are missing
随机森林是一种集成学习+决策树的分类模型,它可以利用集成的思想(投票选择的策略)来提升单颗决策树的分类性能(通俗来讲就是“三个臭皮匠,顶一个诸葛亮”)。
集集成学习和决策树于一身,随机森林算法具有众多的优点,其中最为重要的就是在随机森林算法中每棵树都尽最大程度的生长,并且没有剪枝过程。
随机森林引入了两个随机性——随机选择样本(bootstrap sample)和随机选择特征进行训练。两个随机性的引入对随机森林的分类性能至关重要。由于它们的引入,使得随机森林不容易陷入过拟合,并且具有很好得抗噪能力(比如:对缺省值不敏感)。
7.1.3 boosting(提升方法)
提升(boosting)方法是一种与bagging很类似的技术,是常用的统计学习方法,应用广泛且有效。Boosting的思路则是采用重赋权(re-weighting)法迭代地训练基分类器,主要思想:
- 每一轮的训练数据样本赋予一个权重,并且每一轮样本的权值分布依赖上一轮的分类结果。
- 基分类器之间采用序列式的线性加权方式进行组合。
分类问题中,它通过改变训练样本的权重,学习多个分类器,并将这些分类器进行线性组合,提高分类性能。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9PubhvLF-1663158003767)(//img-blog.csdn.net/20180319214903291?)]
7.1.4 Bagging、Boosting二者之间的区别
样本选择上:
- Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
- Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
样例权重:
- Bagging:使用均匀取样,每个样例的权重相等。
- Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
预测函数:
- Bagging:所有预测函数的权重相等。
- Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
并行计算:
- Bagging:各个预测函数可以并行生成。
- Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
7.1.5 总结
这两种方法都是把若干个分类器整合为一个分类器的方法,只是整合的方式不一样,最终得到不一样的效果,将不同的分类算法套入到此类算法框架中一定程度上会提高了原单一分类器的分类效果,但是也增大了计算量。
下面是将决策树与这些算法框架进行结合所得到的新的算法:
- Bagging + 决策树 = 随机森林
- AdaBoost + 决策树 = 提升树
- Gradient Boosting + 决策树 = GBDT
集成方法众多,本文主要关注Boosting方法中的一种最流行的版本,即AdaBoost。
7.2 AdaBoost

7.2.1 AdaBoost训练方法:基于错误提示分类器的性能


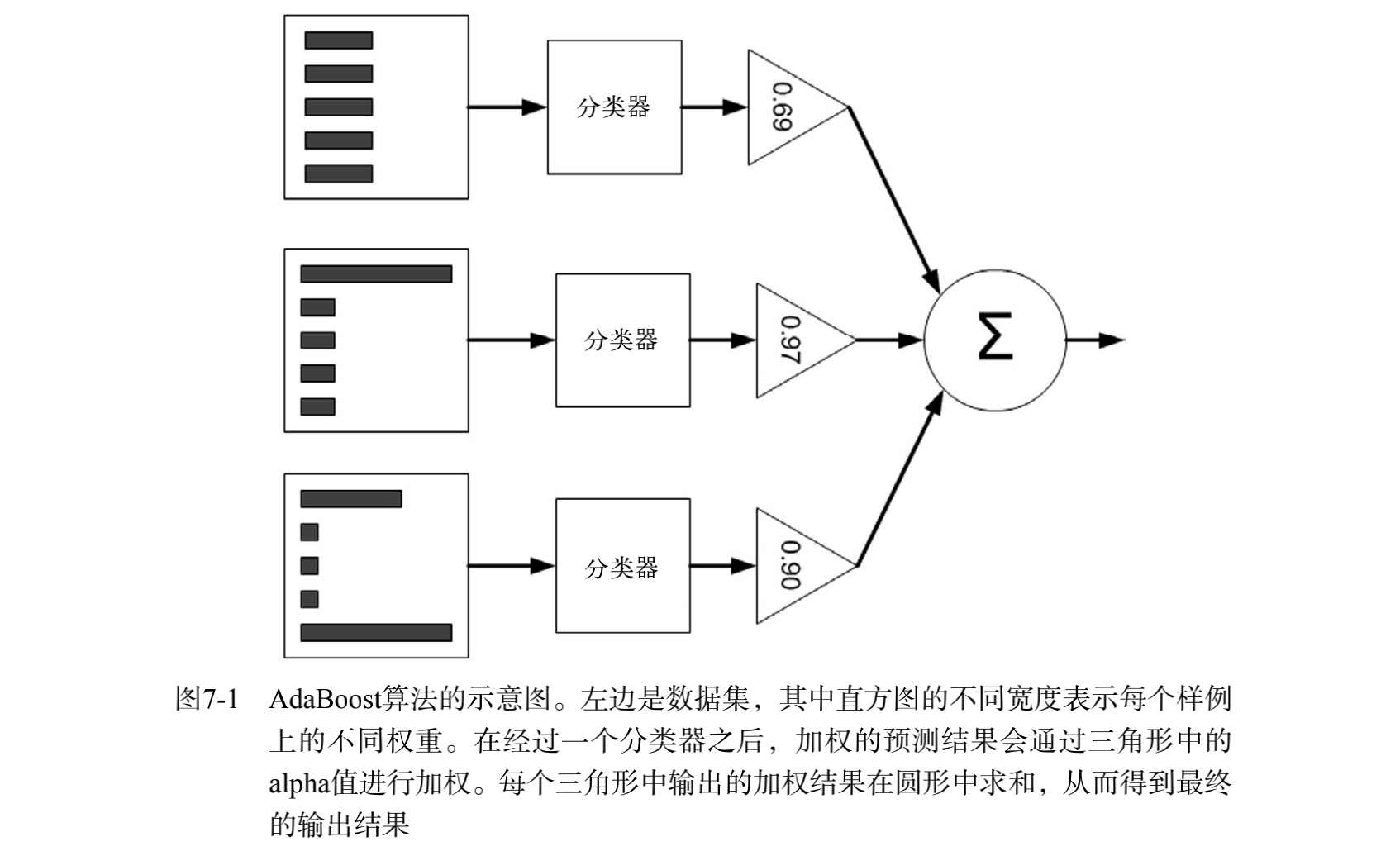
步骤如下:
1)计算样本权重
训练数据中的每个样本,赋予其权重,即样本权重,用向量D表示,这些权重都初始化成相等值。假设有n个样本的训练集:
$\{(x_1,y_1),(x_2,y_2),...,(x_n,y_n)\}$
2)计算错误率
利用第一个弱学习算法h1对其进行学习,学习完成后进行错误率ε的统计:
$\epsilon =\frac{未正确分类的样本数目}{所有样本数目} $
3)计算弱学习算法权重
弱学习算法也有一个权重,用向量α表示,利用错误率计算权重α:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-U4HJ0JTd-1663158003768)(//img-blog.csdn.net/20180319220219543?watermark/2/text/Ly9ibG9nLmNzZG4ubmV0L2ppYW95YW5nd20=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)]
4)更新样本权重
在第一次学习完成后,需要重新调整样本的权重,以使得在第一分类中被错分的样本的权重,在接下来的学习中可以重点对其进行学习:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Q9wcqVMJ-1663158003768)(//img-blog.csdn.net/20180319220321313?)]
其中,h_t(x_i) = y_i表示对第i个样本训练正确,不等于则表示分类错误。Z_t是一个归一化因子:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VSVAXNuK-1663158003768)(//img-blog.csdn.net/20180319220351289?)]
这个公式我们可以继续化简,将两个公式进行合并,化简如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-33zx3ATt-1663158003768)(//img-blog.csdn.net/2018031922044115?)]
5)重复进行学习
重复进行学习,这样经过t轮的学习后,就会得到t个弱学习算法、权重、弱分类器的输出以及最终的AdaBoost算法的输出,分别如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bWcZlmPt-1663158003769)(//img-blog.csdn.net/2018031922054992?)]
7.2.2 使用sklearn的AdaBoost
官方文档
class sklearn.ensemble.AdaBoostClassifier(base_estimator=None, n_estimators=50, learning_rate=1.0, algorithm=’SAMME.R’, random_state=None)
参数说明如下:
- base_estimator:可选参数,默认为DecisionTreeClassifier。理论上可以选择任何一个分类或者回归学习器,不过需要支持样本权重。我们常用的一般是CART决策树或者神经网络MLP。默认是决策树,即AdaBoostClassifier默认使用CART分类树DecisionTreeClassifier,而AdaBoostRegressor默认使用CART回归树DecisionTreeRegressor。另外有一个要注意的点是,如果我们选择的AdaBoostClassifier算法是SAMME.R,则我们的弱分类学习器还需要支持概率预测,也就是在scikit-learn中弱分类学习器对应的预测方法除了predict还需要有predict_proba。
- algorithm:可选参数,默认为SAMME.R。scikit-learn实现了两种Adaboost分类算法,SAMME和SAMME.R。两者的主要区别是弱学习器权重的度量,SAMME使用对样本集分类效果作为弱学习器权重,而SAMME.R使用了对样本集分类的预测概率大小来作为弱学习器权重。由于SAMME.R使用了概率度量的连续值,迭代一般比SAMME快,因此AdaBoostClassifier的默认算法algorithm的值也是SAMME.R。我们一般使用默认的SAMME.R就够了,但是要注意的是使用了SAMME.R, 则弱分类学习器参数base_estimator必须限制使用支持概率预测的分类器。SAMME算法则没有这个限制。
- n_estimators:整数型,可选参数,默认为50。弱学习器的最大迭代次数,或者说最大的弱学习器的个数。一般来说n_estimators太小,容易欠拟合,n_estimators太大,又容易过拟合,一般选择一个适中的数值。默认是50。在实际调参的过程中,我们常常将n_estimators和下面介绍的参数learning_rate一起考虑。
- learning_rate:浮点型,可选参数,默认为1.0。每个弱学习器的权重缩减系数,取值范围为0到1,对于同样的训练集拟合效果,较小的v意味着我们需要更多的弱学习器的迭代次数。通常我们用步长和迭代最大次数一起来决定算法的拟合效果。所以这两个参数n_estimators和learning_rate要一起调参。一般来说,可以从一个小一点的v开始调参,默认是1。
- random_state:整数型,可选参数,默认为None。如果RandomState的实例,random_state是随机数生成器; 如果None,则随机数生成器是由np.random使用的RandomState实例。
数据集:病马数据集,将标签变为+1/-1
import numpy as np
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
#
def loadDataSet(fileName):
numFeat = len((open(fileName).readline().split('\t')))
dataMat = []
labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = []
curLine = line.strip().split('\t')
for i in range(numFeat - 1):
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)
labelMat.append(float(curLine[-1]))
return dataMat, labelMat
if __name__ == '__main__':
dataArr, classLabels = loadDataSet('horseColicTraining2.txt')
testArr, testLabelArr = loadDataSet('horseColicTest2.txt')
bdt = AdaBoostClassifier(DecisionTreeClassifier(max_depth=2), algorithm='SAMME', n_estimators=10)
bdt.fit(dataArr, classLabels)
predictions = bdt.predict(dataArr)
errArr = np.mat(np.ones((len(dataArr), 1)))
print('训练集错误率:%.3f%%' % float(errArr[predictions != classLabels].sum() / len(dataArr) * 100))
predictions = bdt.predict(testArr)
errArr = np.mat(np.ones((len(testArr), 1)))
print('测试集错误率:%.3f%%' % float(errArr[predictions != testLabelArr].sum() / len(testArr) * 100))
结果:
训练集错误率:16.054%
测试集错误率:17.910%
我们使用DecisionTreeClassifier作为使用的弱分类器,使用AdaBoost算法训练分类器。可以看到训练集的错误率为16.054%,测试集的错误率为:17.910%。
更改n_estimators参数,你会发现跟我们自己写的代码,更改迭代次数的效果是一样的。n_enstimators参数过大,会导致过拟合。
7.3 分类器性能评价
非均衡分类问题:
前六章的所有分类介绍中,我们都假设所有类别的分类代价是一样的。比如在第五章中,我们构建了一个用于检测患疝病的马匹是否存活的系统。在那里,我们构建了分类器,但是并没有对分类后的情形加以讨论。假如某人给我们牵来一匹马,他希望我们能预测这匹马能否生存。我们说马会死,那么他们就可能会对马实施安乐死,而不是通过给马喂药来延缓其不可避免的死亡过程。我们的预测也许是错误的,马本来是可以继续活着的。毕竟,我们的分类器只有80%的精确率(accuracy)。如果我们预测错误,那么我们将会错杀一个如此昂贵的动物,更不要说人对马还存在情感上的依恋了。
如何过滤垃圾邮件呢?如果收件箱中会出现某些垃圾邮件,但合法邮件永远不会扔进垃圾邮件夹中,人们会是否会满意呢?癌症检测又如何呢?只要患病的人不会得不到治疗,那么再找一个医生会不会更好呢,宁愿误判也不漏判。
很多时候,不同类别的分类代价并不相等,这就是非均衡分类问题。我们将会考察一种新的分类器性能度量方法,而不再是简单的通过错误率进行评价,并且通过图像技术来对上述非均衡问题下不同分类器性能进行可视化处理。
7.3.1 分类器性能度量指标
到现在为止,本书都是基于错误率来衡量分类器任务的成功程度的。错误率指的是在所有测试样本中错分的样本比例。实际上,这样的度量错误掩盖了样例如何被错分的事实。在机器学习中,有一个普遍适用的称为混淆矩阵(confusion matrix)的工具,它可以帮助人们更好地了解分类中的错误。有这样一个关于在房子周围可能发现的动物类型的预测,这个预测的三个类问题的混淆矩阵如下图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tz48qRMP-1663158003769)(//img-blog.csdn.net/20180320094114372?watermark/2/text/Ly9ibG9nLmNzZG4ubmV0L2ppYW95YW5nd20=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)]
利用混淆矩阵就可以更好地理解分类中的错误了。如果矩阵中的飞对角元素均为0,就会得到一个完美的分类器。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UE15uMJL-1663158003769)(//img-blog.csdn.net/20180320094249312?watermark/2/text/Ly9ibG9nLmNzZG4ubmV0L2ppYW95YW5nd20=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)]
wiki解释
一、各个指标定义如下:
1)Accuracy
模型的精度,即模型预测正确的个数/样本的总个数,一般情况下,模型的精度越高,说明模型的效果越好。
$Accuracy=\frac {TP+TN}{TP+FN+FP+TN}$
2)Precision(正确率Positive predictive value——PPV)
正确率,阳性预测值,在模型预测为正类的样本中,真正的正样本所占的比例,一般情况下,正确率越高,说明模型的效果越好。
$Precision=\frac {TP}{TP+FP}$
3)False discovery rate(FDR)
伪发现率,也是错误发现率,表示在模型预测为正类的样本中,真正的负类的样本所占的比例,一般情况下,错误发现率越小,说明模型的效果越好。
$FDR=\frac {FP}{TP+FP}$
4)False omission rate(FOR)
错误遗漏率,表示在模型预测为负类的样本中,真正的正类所占的比例。即评价模型”遗漏”掉的正类的多少。
$FOR=\frac {FN}{FN+TN}$
5)Negative predictive value(NPV)
阴性预测值,在模型预测为负类的样本中,真正为负类的样本所占的比例。
$NPV=\frac {TN}{FN+TN}$
一般情况下,NPV越高,说明的模型的效果越好。
6)True positive rate(Recall)
召回率,真正类率,表示的是,模型预测为正类的样本的数量,占总的正类样本数量的比值。
$Recall=\frac {TP}{TP+FN}$
一般情况下,Recall越高,说明有更多的正类样本被模型预测正确,模型的效果越好。
7)False positive rate(FPR),Fall-out
假正率,表示的是,模型预测为正类的样本中,占模型负类样本数量的比值。
$Fall-out=\frac {FP}{FP+TN}$
一般情况下,假正类率越低,说明模型的效果越好。
8)False negative rate(FNR),Miss rate
假负类率,缺失率,模型预测为负类的样本中,是正类的数量,占真实正类样本的比值。
$FNR=\frac {FN}{FN+TN}$
缺失值越小,说明模型的效果越好。
构建一个同时使正确率和召回率最大的分类器是具有挑战性的。
二、ROC曲线
另一个用于度量分类中的非均衡的工具是ROC曲线(ROC curve),ROC代表接收者操作特征(receiver operating characteristic),它最早在二战期间由电气工程师构建雷达系统时使用过。
代码:
# -*-coding:utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
def loadDataSet(fileName):
numFeat = len((open(fileName).readline().split('\t')))
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = []
curLine = line.strip().split('\t')
for i in range(numFeat - 1):
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)
labelMat.append(float(curLine[-1]))
return dataMat, labelMat
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):
"""
单层决策树分类函数
Parameters:
dataMatrix - 数据矩阵
dimen - 第dimen列,也就是第几个特征
threshVal - 阈值
threshIneq - 标志
Returns:
retArray - 分类结果
"""
retArray = np.ones((np.shape(dataMatrix)[0],1)) #初始化retArray为1
if threshIneq == 'lt':
retArray[dataMatrix[:,dimen] <= threshVal] = -1.0 #如果小于阈值,则赋值为-1
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0 #如果大于阈值,则赋值为-1
return retArray
def buildStump(dataArr,classLabels,D):
"""
找到数据集上最佳的单层决策树
Parameters:
dataArr - 数据矩阵
classLabels - 数据标签
D - 样本权重
Returns:
bestStump - 最佳单层决策树信息
minError - 最小误差
bestClasEst - 最佳的分类结果
"""
dataMatrix = np.mat(dataArr); labelMat = np.mat(classLabels).T
m,n = np.shape(dataMatrix)
numSteps = 10.0; bestStump = {}; bestClasEst = np.mat(np.zeros((m,1)))
minError = float('inf') #最小误差初始化为正无穷大
for i in range(n): #遍历所有特征
rangeMin = dataMatrix[:,i].min(); rangeMax = dataMatrix[:,i].max() #找到特征中最小的值和最大值
stepSize = (rangeMax - rangeMin) / numSteps #计算步长
for j in range(-1, int(numSteps) + 1):
for inequal in ['lt', 'gt']: #大于和小于的情况,均遍历。lt:less than,gt:greater than
threshVal = (rangeMin + float(j) * stepSize) #计算阈值
predictedVals = stumpClassify(dataMatrix, i, threshVal, inequal)#计算分类结果
errArr = np.mat(np.ones((m,1))) #初始化误差矩阵
errArr[predictedVals == labelMat] = 0 #分类正确的,赋值为0
weightedError = D.T * errArr #计算误差
# print("split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshVal, inequal, weightedError))
if weightedError < minError: #找到误差最小的分类方式
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump, minError, bestClasEst
def adaBoostTrainDS(dataArr, classLabels, numIt = 40):
"""
使用AdaBoost算法训练分类器
Parameters:
dataArr - 数据矩阵
classLabels - 数据标签
numIt - 最大迭代次数
Returns:
weakClassArr - 训练好的分类器
aggClassEst - 类别估计累计值
"""
weakClassArr = []
m = np.shape(dataArr)[0]
D = np.mat(np.ones((m, 1)) / m) #初始化权重
aggClassEst = np.mat(np.zeros((m,1)))
for i in range(numIt):
bestStump, error, classEst = buildStump(dataArr, classLabels, D) #构建单层决策树
# print("D:",D.T)
alpha = float(0.5 * np.log((1.0 - error) / max(error, 1e-16))) #计算弱学习算法权重alpha,使error不等于0,因为分母不能为0
bestStump['alpha'] = alpha #存储弱学习算法权重
weakClassArr.append(bestStump) #存储单层决策树
# print("classEst: ", classEst.T)
expon = np.multiply(-1 * alpha * np.mat(classLabels).T, classEst) #计算e的指数项
D = np.multiply(D, np.exp(expon))
D = D / D.sum() #根据样本权重公式,更新样本权重
#计算AdaBoost误差,当误差为0的时候,退出循环
aggClassEst += alpha * classEst #计算类别估计累计值
# print("aggClassEst: ", aggClassEst.T)
aggErrors = np.multiply(np.sign(aggClassEst) != np.mat(classLabels).T, np.ones((m,1))) #计算误差
errorRate = aggErrors.sum() / m
# print("total error: ", errorRate)
if errorRate == 0.0: break #误差为0,退出循环
return weakClassArr, aggClassEst
def plotROC(predStrengths, classLabels):
"""
绘制ROC
Parameters:
predStrengths - 分类器的预测强度
classLabels - 类别
Returns:
无
"""
font = FontProperties(fname=r"c:\windows\fonts\simsun.ttc", size=14)
cur = (1.0, 1.0) #绘制光标的位置
ySum = 0.0 #用于计算AUC
numPosClas = np.sum(np.array(classLabels) == 1.0) #统计正类的数量
yStep = 1 / float(numPosClas) #y轴步长
xStep = 1 / float(len(classLabels) - numPosClas) #x轴步长
sortedIndicies = predStrengths.argsort() #预测强度排序,从低到高
fig = plt.figure()
fig.clf()
ax = plt.subplot(111)
for index in sortedIndicies.tolist()[0]:
if classLabels[index] == 1.0:
delX = 0; delY = yStep
else:
delX = xStep; delY = 0
ySum += cur[1] #高度累加
ax.plot([cur[0], cur[0] - delX], [cur[1], cur[1] - delY], c = 'b') #绘制ROC
cur = (cur[0] - delX, cur[1] - delY) #更新绘制光标的位置
ax.plot([0,1], [0,1], 'b--')
plt.title('AdaBoost马疝病检测系统的ROC曲线', FontProperties = font)
plt.xlabel('假阳率', FontProperties = font)
plt.ylabel('真阳率', FontProperties = font)
ax.axis([0, 1, 0, 1])
print('AUC面积为:', ySum * xStep) #计算AUC
plt.show()
if __name__ == '__main__':
dataArr, LabelArr = loadDataSet('horseColicTraining2.txt')
weakClassArr, aggClassEst = adaBoostTrainDS(dataArr, LabelArr, 50)
plotROC(aggClassEst.T, LabelArr)
结果:
AUC面积为: 0.8953941870182941
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kps9Z1YU-1663158003769)(//img-blog.csdn.net/20180320100321432?watermark/2/text/Ly9ibG9nLmNzZG4ubmV0L2ppYW95YW5nd20=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)]
ROC曲线介绍:
-
横纵坐标:横坐标为伪正例(假阳率=FP/(FP+TN)),纵坐标为真正例的比例(真阳率=TP/(TP+FN))
-
意义:当阈值变化时假阳率和真阳率的变化情况,左下角的点对应的将所有样例判断为反例的情况,右上角的点对应将所有样例判断为正例的情况,虚线是随机猜测的结果曲线。
-
应用场合:ROC曲线不但可以用于比较分类器,还可以基于成本效益(cost-versus-benefit)分析来做出决策。由于在不同的阈值下,不用的分类器的表现情况是可能各不相同,因此以某种方式将它们组合起来或许更有意义。如果只是简单地观察分类器的错误率,那么我们就难以得到这种更深入的洞察效果了。
-
理想情况:在理想的情况下,最佳的分类器应该尽可能地处于左上角,这就意味着分类器在假阳率很低的同时获得了很高的真阳率。例如在垃圾邮件的过滤中,就相当于过滤了所有的垃圾邮件,但没有将任何合法邮件误识别为垃圾邮件而放入垃圾邮件额文件夹中。
-
AUC:对不同的ROC曲线进行比较的一个指标是曲线下的面积(Area Unser the Curve,AUC)。AUC给出的是分类器的平均性能值,当然它并不能完全代替对整条曲线的观察。一个完美分类器的ACU为1.0,而随机猜测的AUC则为0.5。计算:这些小矩形的宽度都是固定的xStep,因此先对所有矩形的高度进行累加,即ySum,最后面积就是ySum*xStep。
上面的ROC曲线绘制结果是在10个弱分类器下,AdaBoost算法性能的结果。我们将迭代次数改为50,也就是训练50个弱分类器,看下ROC曲线和AUC的变化:
AUC面积为: 0.9133624291949113
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OHorQpFf-1663158003770)(//img-blog.csdn.net/20180320102003368?watermark/2/text/Ly9ibG9nLmNzZG4ubmV0L2ppYW95YW5nd20=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)]
你会发现,ROC曲线往左上角更靠拢了,并且AUC值增加了。也就表明,分类器效果更佳。
这就是ROC和AUC对与分类器评价指标,ROC越靠拢于左上角,分类器性能越好。同理AUC越接近于1,分类器性能越好
7.4 AdaBoost的优缺点
- 优点:泛化错误率低,易编码,可以应用在大部分分类器上,无参数调整。
- 缺点:对离群点敏感。
7.5 xgboost
Xgboost是GB算法的高效实现,xgboost中的基学习器除了可以是CART(gbtree)也可以是线性分类器(gblinear)。
- xgboost在目标函数中显示的加上了正则化项,基学习为CART时,正则化项与树的叶子节点的数量T和叶子节点的值有关
2)GB中使用Loss Function对f(x)的一阶导数计算出伪残差用于学习生成fm(x),xgboost不仅使用到了一阶导数,还使用二阶导数。
3)上面提到CART回归树中寻找最佳分割点的衡量标准是最小化均方差,xgboost寻找分割点的标准是最大化,lamda,gama与正则化项相关
xgboost相比传统gbdt有何不同:
传统GBDT以CART作为基分类器,xgboost还支持线性分类器,这个时候xgboost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)。
传统GBDT在优化时只用到一阶导数信息,xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。顺便提一下,xgboost工具支持自定义代价函数,只要函数可一阶和二阶求导。
xgboost在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。从Bias-variance tradeoff角度来讲,正则项降低了模型的variance,使学习出来的模型更加简单,防止过拟合,这也是xgboost优于传统GBDT的一个特性。
Shrinkage(缩减),相当于学习速率(xgboost中的eta)。xgboost在进行完一次迭代后,会将叶子节点的权重乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间。实际应用中,一般把eta设置得小一点,然后迭代次数设置得大一点。(补充:传统GBDT的实现也有学习速率)
列抽样(column subsampling)。xgboost借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算,这也是xgboost异于传统gbdt的一个特性。
对缺失值的处理。对于特征的值有缺失的样本,xgboost可以自动学习出它的分裂方向。
xgboost工具支持并行。
xgboost代价函数里加入正则项,是否优于cart的剪枝?
决策树的学习过程就是为了找出最优的决策树,然而从函数空间里所有的决策树中找出最优的决策树是NP-C问题,所以常采用启发式(Heuristic)的方法,如CART里面的优化GINI指数、剪枝、控制树的深度。这些启发式方法的背后往往隐含了一个目标函数,这也是大部分人经常忽视掉的。
xgboost的目标函数如下:
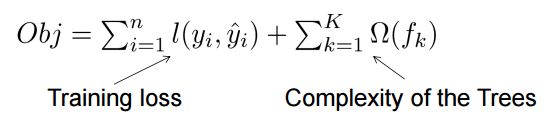
其中正则项控制着模型的复杂度,包括了叶子节点数目T和leaf score的L2模的平方:
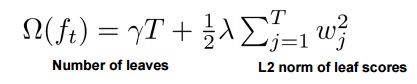
那这个跟剪枝有什么关系呢???
跳过一系列推导,我们直接来看xgboost中树节点分裂时所采用的公式:

这个公式形式上跟ID3算法(采用entropy计算增益) 、CART算法(采用gini指数计算增益) 是一致的,都是用分裂后的某种值 减去 分裂前的某种值,从而得到增益。为了限制树的生长,我们可以加入阈值,当增益大于阈值时才让节点分裂,上式中的gamma即阈值,它是正则项里叶子节点数T的系数,所以xgboost在优化目标函数的同时相当于做了预剪枝。另外,上式中还有一个系数lambda,是正则项里leaf score的L2模平方的系数,对leaf score做了平滑,也起到了防止过拟合的作用,这个是传统GBDT里不具备的特性。